For technology leaders and developers, the process of integrating rich, proprietary data into generative AI applications is often filled with challenges. Vector similarity search and retrieval augmented generation are powerful tools to help with this, but one mistake extracting, chunking, or vectorizing your data can mean the difference between an AI agent that performs well and one that frustrates users with poor responses and hallucinations. Today we are excited to announce that building highly optimized vector indexes on Capella just got a lot easier!
That’s because the teams at Couchbase and Vectorize have been working hard to bring the power of Vectorize experiments to Couchbase Capella, a DBaaS platform to get you quickly started with your RAG-powered GenAI application. Leveraging this integration, you can quickly find the best text embedding model, chunking strategies, and retrieval parameters to maximize the relevancy of your search results without writing a single line of code.
For anyone building LLM-powered applications using Capella as a knowledge base for RAG, this is a game changer that will allow you to build better, more accurate generative AI applications in a fraction of the time, without the need for trial and error to figure out the best vectorization strategy for your data.
Features and Capabilities
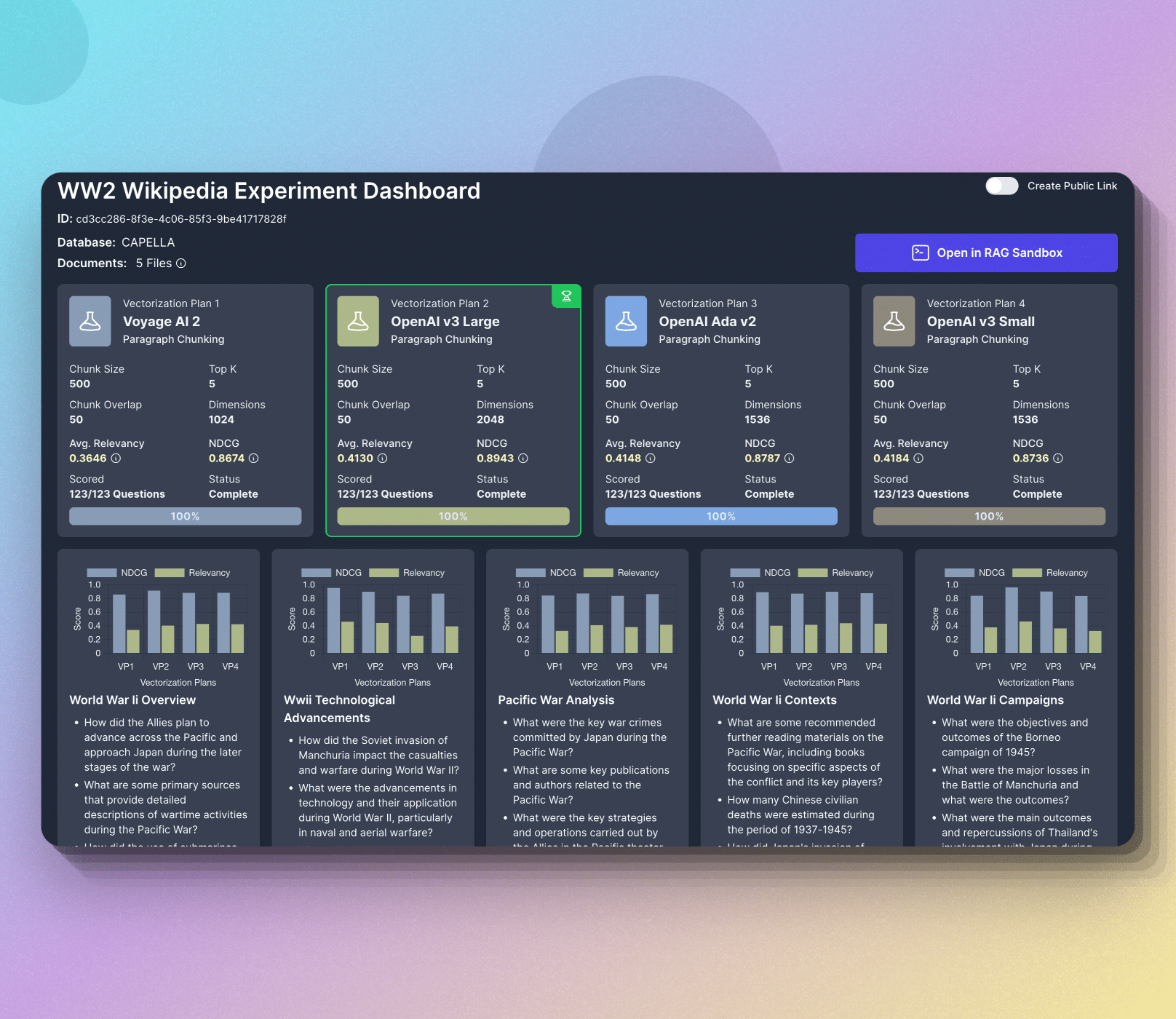
When you run an experiment on Vectorize, you will build up to 4 different vector search indexes in Couchbase Capella simultaneously. These indexes are populated from a set of documents that you upload and each search index is populated using the embedding models and chunking strategies that you specify.
Based on your documents, Vectorize will generate a set of synthetic questions which allow you to predict the types of questions your users might ask about your data. Vectorize then retrieves the most relevant context for each question. scoring the results that are returned from Capella using a relevancy algorithm and normalized discounted cumulative gain.

The net result is concrete data that shows you precisely how well different vectorization strategies perform on your data. However, the journey does not end there.
Using the Vectorize RAG Sandbox, you can further explore your data in a live interactive interface that provides an end-to-end interface to test out your Retrieval Augmented Generation flows. You can use one of the synthetic questions from the experiment, or enter your own prompt to see exactly what was returned from Capella, and inspect how different large language models respond to your query.

With Vectorize and Capella as the knowledge base, you can build a performant RAG pipeline to ensure that your Gen AI applications and AI agents will always have the most relevant context. This means happier users and fewer hallucinations from your LLMs!
Sign up and start experimenting for free!
To get started, sign up for a free Vectorize account and a 30-day trial account for Capella to run your first experiment today!
Leave a comment
You must be logged in to post a comment.