
Overview: NoSQL Structure & Key Concepts
To better understand how NoSQL databases work, this page covers:
What is a NoSQL database?
A NoSQL database, short for “not only SQL (Structured Query Language),” is a non-relational database designed to handle diverse and flexible data structures. The NoSQL definition refers to databases that support multiple models—including document, graph, key-value, wide-column, and vector stores—offering greater scalability and adaptability compared to traditional SQL databases, which rely on structured tables and fixed schemas.
The meaning of NoSQL has evolved with advancements in CPUs, RAM, cloud computing, and AI interactions, enabling modern databases to efficiently manage large, real-time datasets. By prioritizing horizontal scaling and performance, NoSQL databases ensure seamless data distribution across multiple nodes, making them the preferred choice for AI, big data, and real-time analytics, where traditional databases often struggle to keep up.
NoSQL refers to databases that store data in flexible formats using models such as documents, key-value stores, and vector stores. Their scalability and performance make them ideal for modern applications that require real-time access and handle large dynamic workloads.
What is the difference between SQL and NoSQL?
SQL and NoSQL databases differ in how they store and query data. SQL databases rely on tables with columns and rows to retrieve and write structured data, while NoSQL databases use flexible data models better suited for unstructured and semi-structured data.
SQL, first introduced in the 1970s, is now used by developers and data analysts worldwide to find and report on data stored in relational systems. SQL databases are ideal for applications that require data integrity and use structured relationships and standardized queries (e.g., enterprise resource planning software). Although NoSQL has been around since the 1960s, the term was first coined in the early 2000s as it became crucial for developers to use databases capable of storing and retrieving data for real-time applications.
It’s worth noting that SQL has been expanding to support NoSQL access patterns. For example, many relational databases now support JSON (JavaScript Object Notation) as a data type. Some databases have even extended SQL to directly query JSON structures, including Couchbase, which supports SQL++ (SQL for JSON).
The difference between SQL and NoSQL databases lies in their structure and use cases. SQL databases use tables, making them ideal for applications that require a rigid structure and normalized data. In contrast, NoSQL databases use flexible models, making them better suited for handling unstructured and semi-structured data while enabling real-time access.
Types of NoSQL databases
These are the most popular types of NoSQL database access patterns:
- Key-value stores group associated data in independent tables where records are identified by unique keys for easy retrieval. They have just enough structure to mirror the value of relational databases while adding the performance and accessibility benefits of a NoSQL data access structure. Key-value data is easily stored in a cache where frequently accessed data is kept in memory for fast reads. Writes, updates, and new read requests are programmatically routed to persistent storage. Key-value stores prioritize atomic access speeds above consistency, isolation, and durability.
- Document databases primarily store information as logical documents, including JSON documents. For example, these systems can also store XML documents or binary objects. Due to the flexible nature of the format and the degree of control it provides developers, document databases are preferred when building data-driven applications.
- Wide-column and columnar databases store data by columns rather than rows, which optimizes query performance for analytical workloads and large-scale data processing. Like key-value stores, wide-column databases have some basic NoSQL structure while preserving flexibility, data handling, and aggregation abilities.
- Search databases allow users to query semi-structured and unstructured data such as web pages, documents, maps, JSON, and XML documents. They use specialized inverted indexes to locate keywords within bodies of text to find relevant data, similar to “googling” something online.
- Graph databases use graph structures like nodes, edges, and properties to define the relationships between stored data elements. Graph databases are useful for identifying relationship patterns in unstructured and semi-structured information, creating social networks, parts assemblies, organizational structures, and ontologies. Graph databases are heavily used in recommendation engines, fraud pattern recognition, predictive AI functions, and linking social networks.
- Time series databases allow users to track data changes over time and detect anomalies in stock price charts, machine logs, health monitors, and alert systems. Because time series data changes rapidly, these databases generate massive amounts of information, potentially introducing scaling issues.
- Vector databases help improve the accuracy of generative AI models by providing hints (vectors) that help them find the “correct” answers within their training data. Vector databases operate within retrieval-augmented generation (RAG) processes to store vector embeddings that help reduce generative AI hallucinations and maintain model progress.
Popular NoSQL data access patterns include key-value stores, document databases, wide-column and columnar databases, search databases, graph databases, time series databases, and vector databases. These NoSQL types each have unique characteristics, such as scalability, schema flexibility, and query efficiency. You should explore them in depth to decide which NoSQL database to use.
Why use NoSQL?
Enterprises favor NoSQL databases for their ability to handle large volumes of diverse and growing data. Specific advantages of NoSQL databases include:
- Scalability: NoSQL databases scale horizontally by distributing data across multiple servers, making them ideal for large workloads.
- Flexibility: Unlike relational databases, NoSQL allows schemaless data storage, making it easier to store and manage unstructured or semi-structured data.
- High performance: Optimized for fast reads and writes, NoSQL databases reduce query complexity and improve response times for real-time applications.
- Various data models: NoSQL databases favor key-value, document, wide-column, search, and time series data models, making them ideal for multiple use cases.
- Big data and real-time processing: NoSQL is designed to handle massive amounts of data, making it ideal for big data analytics, IoT, and caching and session management.
- Cloud and distributed computing: NoSQL databases work well in cloud environments by ensuring high availability and fault tolerance across distributed systems.
- Easier development and iteration: With NoSQL, developers can leverage existing SQL skills and use a database that integrates with familiar tools, integrated development environments (IDEs), and frameworks.
Couchbase’s multipurpose NoSQL database is especially well suited for AI applications because it offers:
1. High performance and low latency
- Memory-first architecture: Uses a distributed memory-first design for fast reads and writes, reducing AI model inference latency.
- Sub-millisecond response times: Ensures real-time data access, which is crucial for use cases like recommendation engines, fraud detection, and predictive analytics.
2. Scalability and distributed architecture
- Multi-dimensional scaling: Can scale horizontally or vertically to handle massive AI datasets and growing workloads.
- Cross data center replication (XDCR): Supports multi-region and multicloud AI deployments with high availability.
3. Multi-model and flexible data storage
- JSON-based NoSQL database: Stores unstructured and semi-structured data, which is essential for AI applications processing diverse datasets.
- Support for vector search: Helps developers build apps using vector search and integrates with LangChain and LlamaIndex.
4. Built-in AI and analytics capabilities
- SQL for JSON (SQL++): SQL-like querying with indexing, full-text search, and analytics for AI model training and inferencing.
- Eventing and stream processing: Enables real-time AI insights using built-in functions and event-driven architecture.
- Integration with AI/ML frameworks: Works with TensorFlow, PyTorch, and Apache Spark for AI model training and deployment.
5. Multicloud and edge AI deployment
- Multicloud environment: Runs on Amazon Web Services (AWS), Microsoft Azure, and Google Cloud, so developers can develop and deploy AI applications to the cloud of their choice.
- Edge computing support: Ideal for real-time AI applications on mobile and IoT devices, reducing cloud dependency and improving response times.
6. Security and compliance
- Enterprise-grade security: Provides built-in encryption, role-based access control (RBAC), and compliance with regulations like GDPR, HIPAA, and SOC 2.
- Data isolation and governance: Supports AI-driven compliance monitoring and fraud detection.
7. Cost efficiency
- High performance at a lower cost: Reduces cloud infrastructure costs by efficiently managing resources and minimizing data transfer.
- Multimodal database: Allows developers to store and query multiple data types, reducing the need for additional databases and saving on potential integration costs, licensing fees, and cloud spend.
Specific use cases for AI applications with Couchbase include:
- Personalized recommendations: E-commerce and streaming services
- Fraud detection and risk analysis: Banking and cybersecurity
- Chatbots and agentic AI: Customer support and virtual assistants
- IoT and edge AI: Smart devices and autonomous systems
Enterprises favor NoSQL databases for their flexibility, scalability, and high performance in handling large volumes of diverse and growing data. Additionally, NoSQL databases use horizontal scaling, distributing data across multiple servers to maintain performance as workloads grow. These capabilities make them well suited for AI applications, IoT systems, adaptive field services, and caching and session management.
Global 2000 enterprises are rapidly embracing NoSQL databases to power their mission-critical applications:

“We found that the replication technology across data centers for Couchbase was superior, especially for large workloads.”

“With less than half the servers, we can increase performance and gain a much better scalable architecture.”

“Couchbase is a highly scalable distributed data store that plays a critical role in our caching systems.”

“Enterprise-class boxes cost lots of money. We can scale and be highly available with commodity hardware.”
NoSQL tutorial
How does NoSQL compare to relational databases? Let’s take a closer look. The following tutorial illustrates a NoSQL application used for managing resumes. It interacts with resumes as an object (i.e., the user object), contains an array for skills, and has a collection for positions. Alternatively, writing a resume to a relational database requires the application to “shred” (normalize) the user object.
Storing this resume would require the application to insert six rows into three tables, as illustrated in Figure 1.
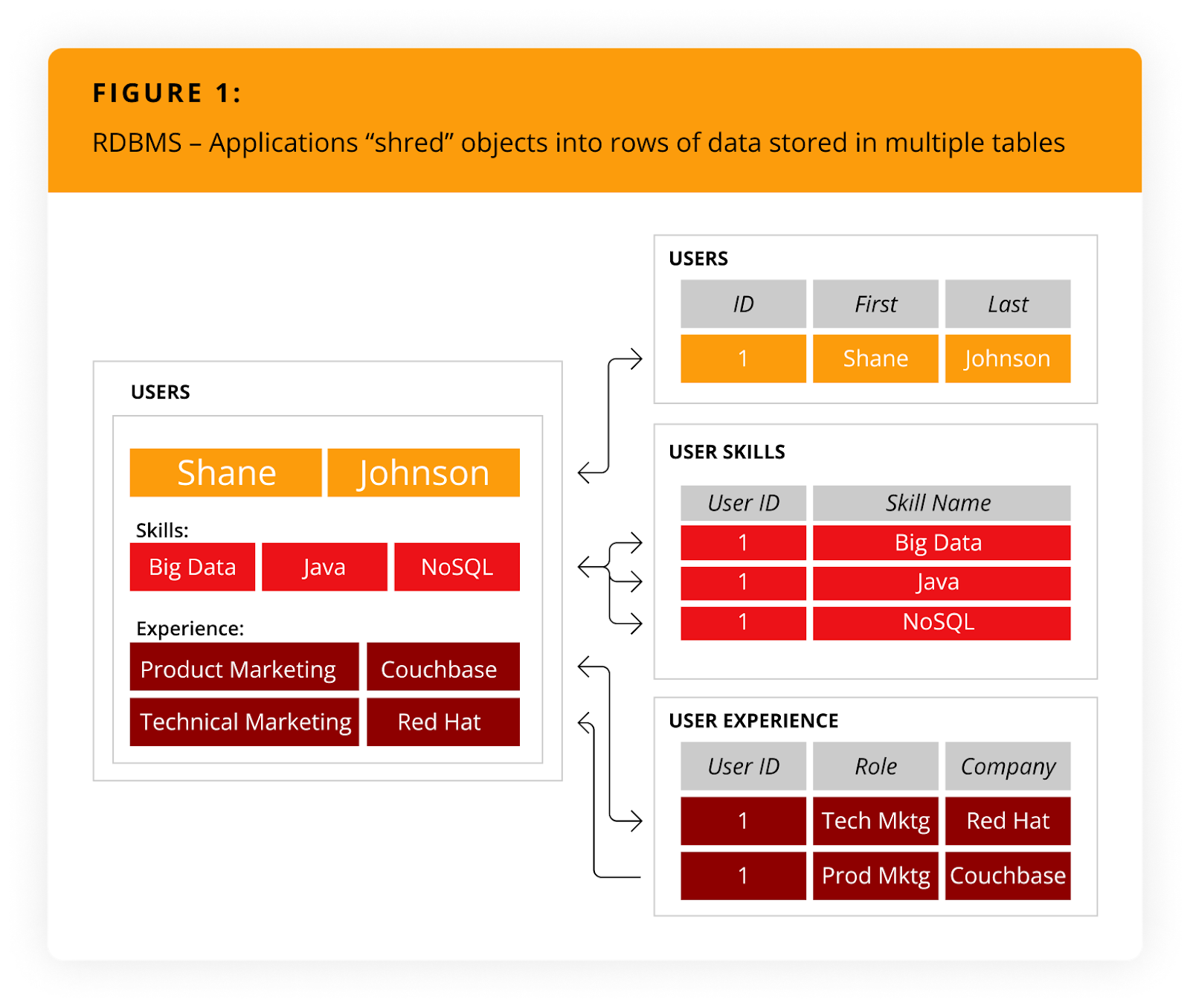
Click to Expand
And, reading this profile would require the application to read six rows from three tables, as illustrated in Figure 2.

Click to Expand
JSON not only eliminates the object-relational impedance mismatch but also the overhead of object-relational mapping (ORM) frameworks. It simplifies application development because objects can be read and written without normalizing them (i.e., a single object can be read or written as a single document), as illustrated in Figure 3.
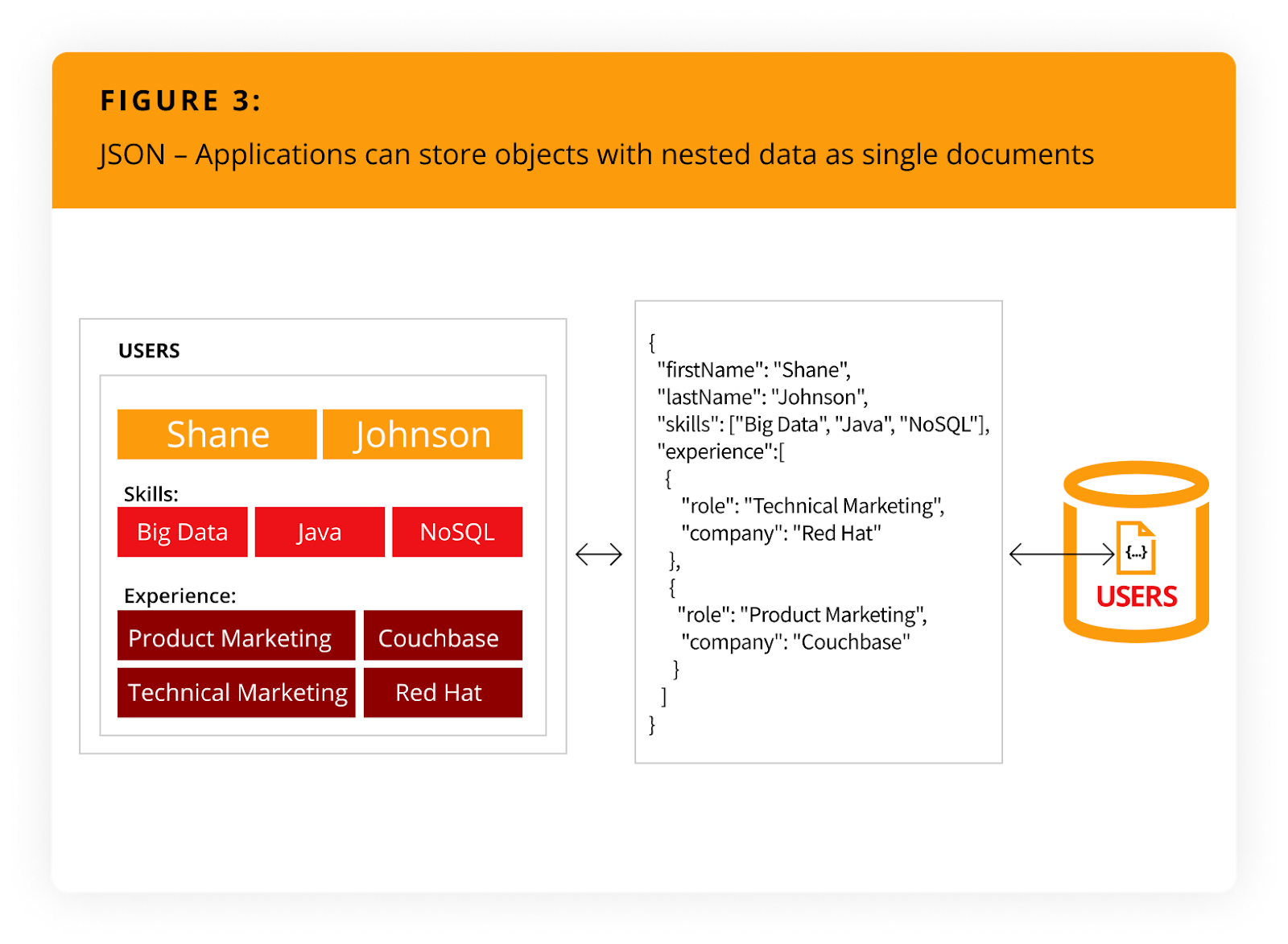
Click to Expand
What about querying and SQL?
Some may argue that querying NoSQL databases is tougher, but this is a common misconception. The inherent flexibility of document-oriented NoSQL databases allows them to handle structured and unstructured data equally well, and new tools allow for faster querying than ever before.
Couchbase supports SQL++, which enables developers to leverage the power of SQL and the flexibility of JSON. It not only supports standard SELECT / FROM / WHERE statements but also aggregation (GROUP BY), sorting (SORT BY), joins (LEFT OUTER / INNER), and querying nested arrays and collections. Additionally, query performance can be improved with composite, partial, and covering indexes.
SELECT RTRIM(p.FirstName) + ' ' + LTRIM(p.LastName) AS Name, d.City
FROM AdventureWorks2025.Person.Person AS p
INNER JOIN AdventureWorks2025.HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN
(SELECT bea.BusinessEntityID, a.City
FROM AdventureWorks2025.Person.Address AS a
INNER JOIN AdventureWorks2025.Person.BusinessEntityAddress AS bea
ON a.AddressID = bea.AddressID) AS d
ON p.BusinessEntityID = d.BusinessEntityID
ORDER BY p.LastName, p.FirstName;
SELECT RTRIM(p.FirstName) || ' ' || LTRIM(p.LastName) AS Name, d.City
FROM AdventureWorks2025.Person.Person AS p
INNER JOIN AdventureWorks2025.HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN
(SELECT bea.BusinessEntityID, a.City
FROM AdventureWorks2025.Person.Address AS a
INNER JOIN AdventureWorks2025.Person.BusinessEntityAddress AS bea
ON a.AddressID = bea.AddressID) AS d
ON p.BusinessEntityID = d.BusinessEntityID
ORDER BY p.LastName, p.FirstName;
NoSQL databases store data in flexible JSON documents, eliminating the need for complex object-relational mapping (ORM) and making it easier to manage structured and unstructured data. This approach simplifies application development by storing and retrieving objects as a single document rather than splitting them into multiple tables. Couchbase further enhances querying capabilities with SQL++, which supports familiar SQL syntax.
Why relational databases fall short
Relational database management systems were born in the era of mainframes and business applications – long before the internet, the cloud, big data, mobile, artificial intelligence, and today’s massively interactive enterprises. These databases were engineered to run on a single server – the bigger the better, and their design was intended to optimize the usage of scarce resources for storage, RAM, and processing. The only way to increase the capacity of these databases was to upgrade the servers (processors, memory, and storage) to scale up. Over the decades, most of their original design restrictions, including normalization, strong data typing, and referential integrity, have been eased or eliminated.
NoSQL database management systems emerged due to the exponential growth of the internet and the rise of web applications. Google released the Bigtable research paper in 2006, and Amazon released the Dynamo research paper in 2007 – these papers detailed how the two companies designed their databases to meet the evolving needs of enterprises. Ultimately, modern databases focused on developing with agility, meeting changing requirements, and eliminating data transformation.
Relational databases were originally designed for single-server environments to optimize limited resources, but as data needs grew, they faced scalability challenges. Driven by the rise of the internet and web applications, NoSQL databases emerged to address these limitations, focusing on agility, scalability, and reducing data transformation complexities.
Conclusion
So, what are NoSQL databases used for and why do they matter? As enterprises shift to artificial intelligence – enabled by cloud, mobile, social media, machine learning, and GenAI technologies – developers and operations teams must build and maintain web, mobile, and IoT applications faster and at greater scale. Flexible, high-performance NoSQL is increasingly the database technology they choose.
Thousands of Global 2000 enterprise developers and millions of developers working in smaller businesses and startups have adopted NoSQL. For many, the use of NoSQL started with a cache, proof of concept, or a small application, then expanded to targeted mission-critical applications before becoming the foundation for all application development.
With NoSQL databases, enterprises can develop with greater agility, operate at any scale, and deliver the performance and availability required to meet the demands of digital economy businesses.



Start building
Check out our developer portal to explore NoSQL, browse resources, and get started with tutorials.
Use Capella free
Get hands-on with Couchbase in just a few clicks. Capella DBaaS is the easiest and fastest way to get started.
Get in touch
Want to learn more about Couchbase offerings? Let us help.