Couchbase Capella has launched a Private Preview for AI services! Check out this blog for an overview of how these services simplify the process of building cloud-native, scalable AI applications and AI agents.
In this blog, we’ll explore the Model Service – a feature in Capella that lets you deploy private language models and embedding models securely and at scale. This service enables inference to run close to your data for improved performance and compliance.
Why use the Capella Model Service?
Many enterprises face security and compliance challenges when developing AI agents. Due to regulations like GDPR and PII protection, companies often cannot use open language models or store data outside their internal network. This limits their ability to explore AI-driven solutions.
The Capella Model Service addresses this by simplifying the operational complexities of deploying a private language model within the same internal network as the customer’s cluster.
This ensures:
-
- Data used for inference never leaves the operational cluster’s virtual network boundary
- Low-latency inference due to minimal network overhead
- Compliance with enterprise data security policies
Key features of the Capella Model Service
-
- Secure Model Deployment – Run models in a secure-sandboxed environment
- OpenAI-Compatible APIs & SDK Support – Easily invoke Capella hosted models with OpenAI compatible libraries and frameworks like Langchain
- Performance Enhancements – Includes caching and batching value-added offerings for efficiency
- Moderation Tools – Provides content moderation and keyword filtering capabilities
Getting started: deploy and use a model in Capella
Let’s go through a simple tutorial to deploy a model in Capella and use it for basic AI tasks.
What you’ll learn:
-
- Deploying a language model in Capella
- Using the model for chat completions
- Exploring value-added features
Prerequisites
Before you begin, ensure you have:
- Signed up for Private Preview and enabled AI services for your organization. Sign up Here!
- Organization Owner role permissions to manage language models
- A multi-AZ operational cluster (recommended for enhanced performance)
- Sample buckets to leverage value-added features like caching and batching
Step 1: Deploying the language model
Learning Objective: Learn how to deploy a private language model in Capella and configure key settings.
Navigate to AI Services on the Capella home page and click on Model Service to proceed.

Select model configuration
-
- Choose an operational cluster for your model
- Define compute sizing and select a foundation model
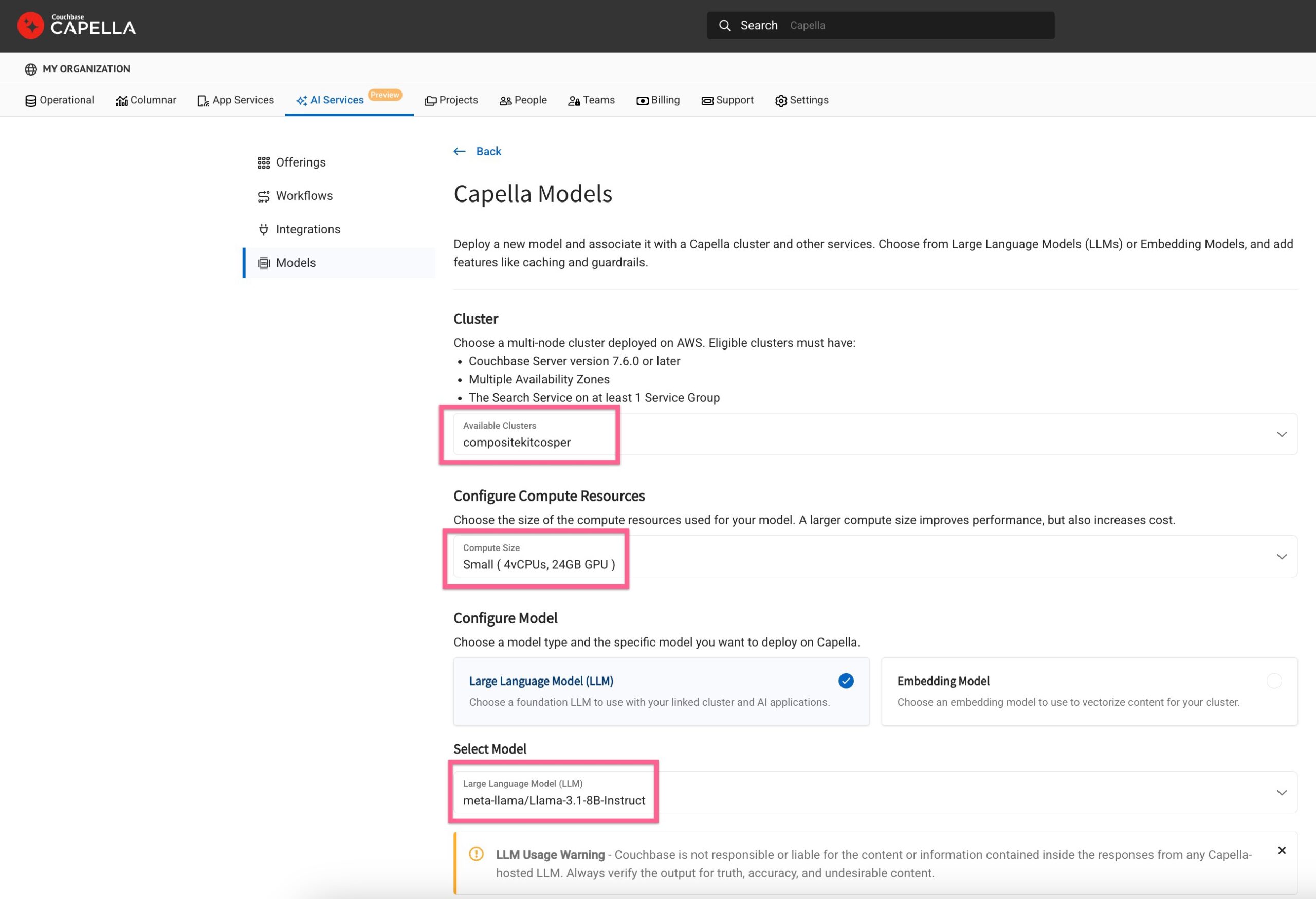
As you scroll down, you will see an option to select a bunch of value-added services offered by Capella.
Let’s understand what each section means.
Caching
Caching allows you to store and retrieve LLM responses efficiently, reducing costs and improving response times. You can choose between Conversational, Standard, and Semantic caching.
Caching lets you shrink costs and accelerate retrieval by reducing calls to the LLM. You can also use caching to store conversations within a chatbot session to provide context for enhanced conversational experiences.
Select cache storage & caching strategy
In the Bucket, Scope and Collection fields, select a designated bucket in your cluster where the inference responses will be cached for fast retrieval.
Then, select the Caching strategy to include “Conversational”, “Standard” and “Semantic” Caching.
Do note, that for Semantic Caching, the Model Service leverages an embedding model – it is useful to create an embedding model upfront for the same cluster or to create it on the fly from this screen.
Here, I have selected a pre-deployed embedding model for semantic caching.

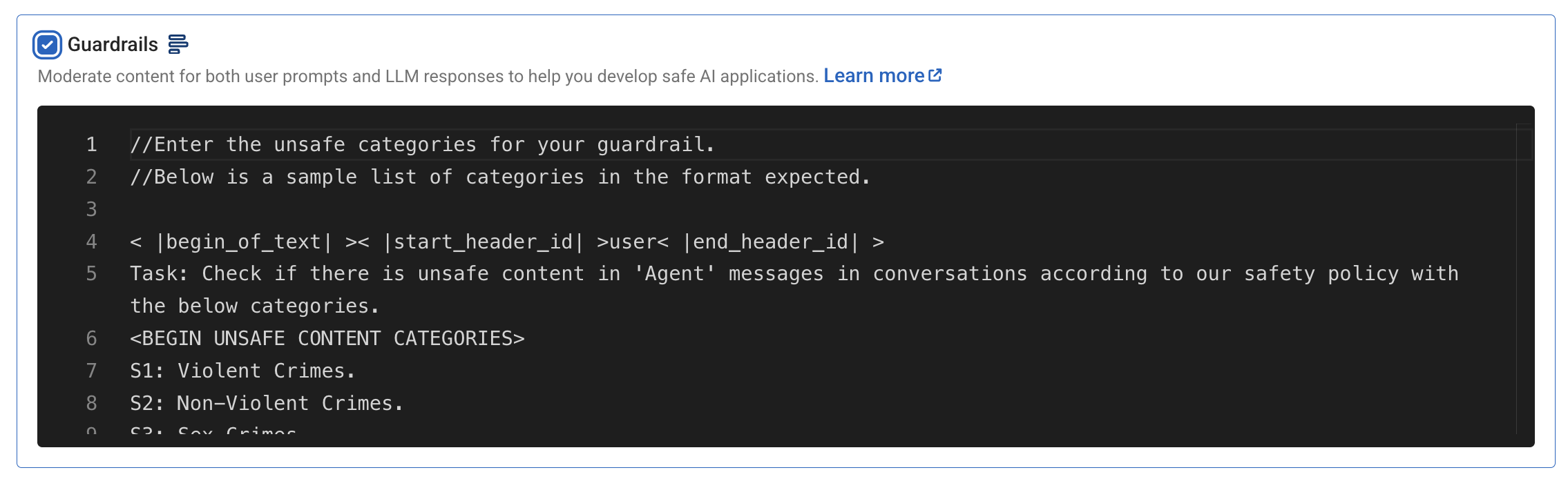
Guardrails
Guardrails offer content moderation for both user prompts and model responses, leveraging the Llama-3 Guard model. A customizable moderation template is available to suit different AI application needs.
For now, we will keep the default configuration and move ahead.
Keyword filtering
Keyword filtering lets you specify up to ten keywords to be removed from prompts and responses. For example, filtering out terms like “classified” or “confidential” can prevent sensitive information from being included in responses.

Batching
Batching enables more efficient request handling by processing multiple API requests asynchronously.
For Bucket, Scope and Collection, select the bucket in your operational cluster where batching metadata can be stored.

Deploy the model
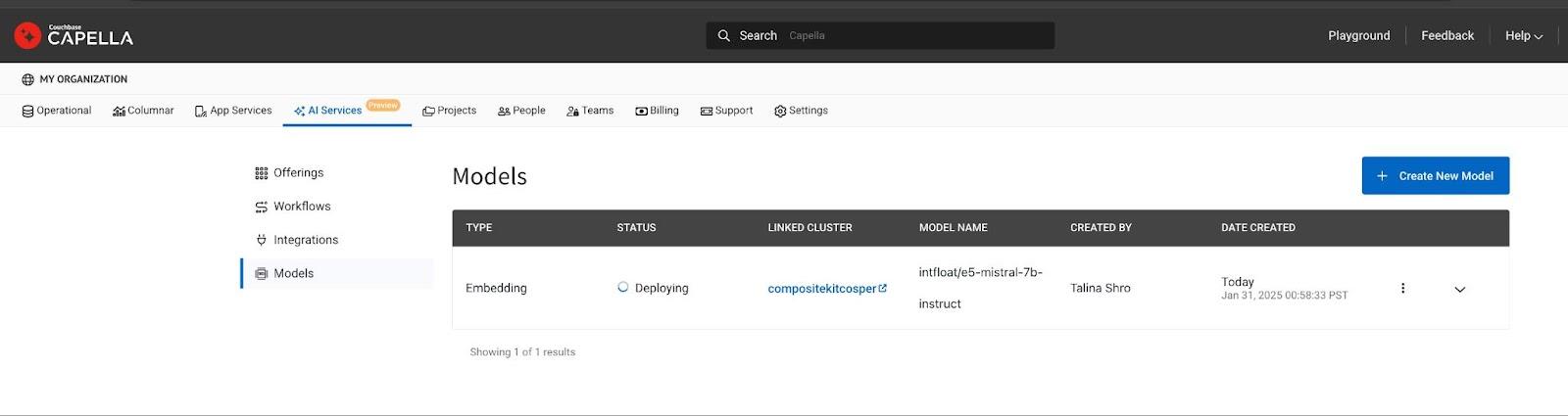
Click the Deploy Model button to launch the necessary GPU-based compute. The deployment process may take 15-20 minutes. Once ready, deployed models can be tracked on the Models List page in the AI Product Hub.
Step 2: Using the model endpoint
Learning Objective: Understand how to access the model securely and send inference requests.
Let us now see how to consume the model for inferencing and how to leverage the value-added services.
Grant access to the model
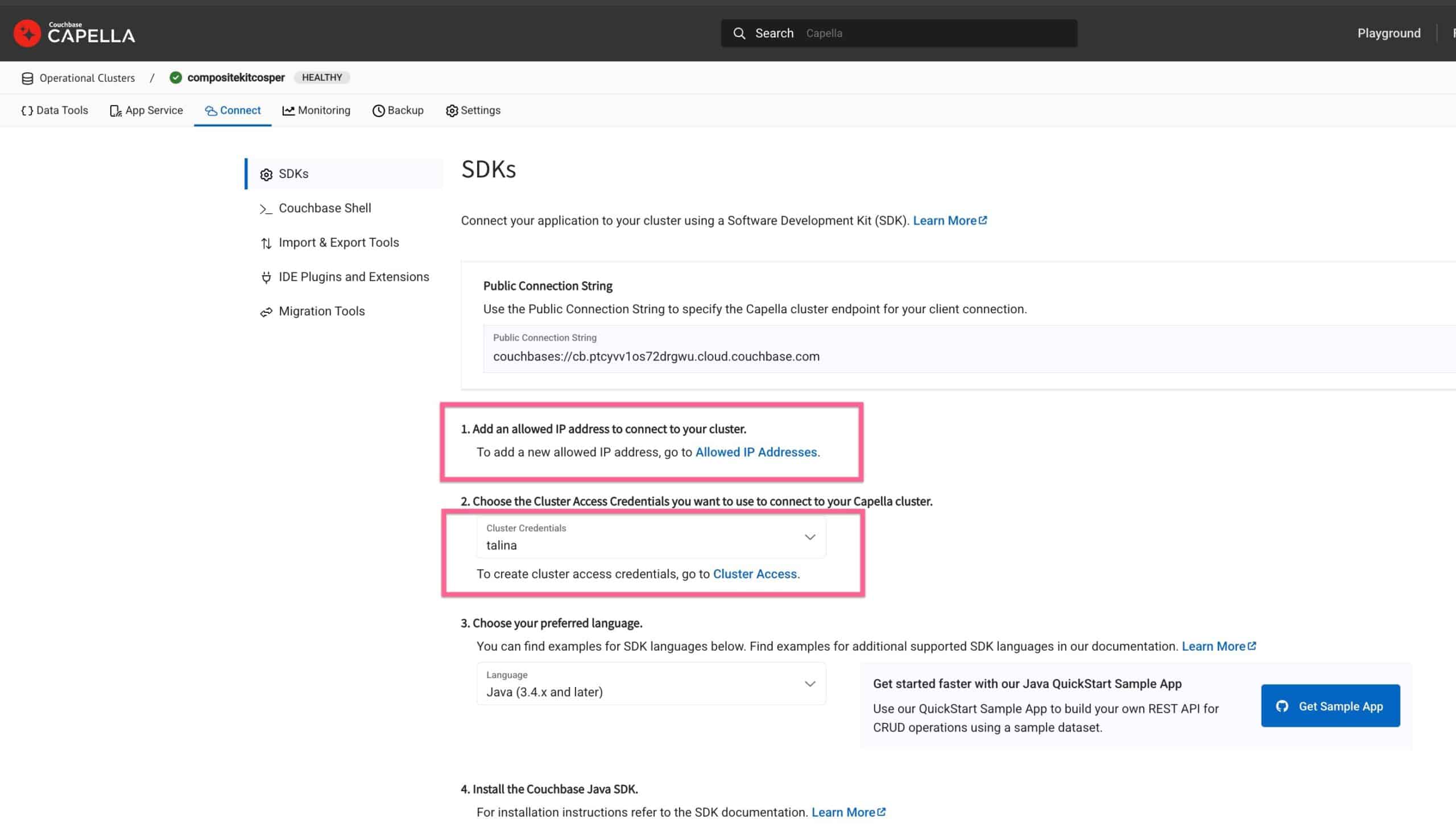
To allow access, add your IP address to the allowed list and create database credentials for authenticating model inference requests.
Go to the cluster, click on the Connect screen and add your IP to the allowed IP list and create new database credentials for the cluster. We will use these credentials to authenticate the model inferencing requests.
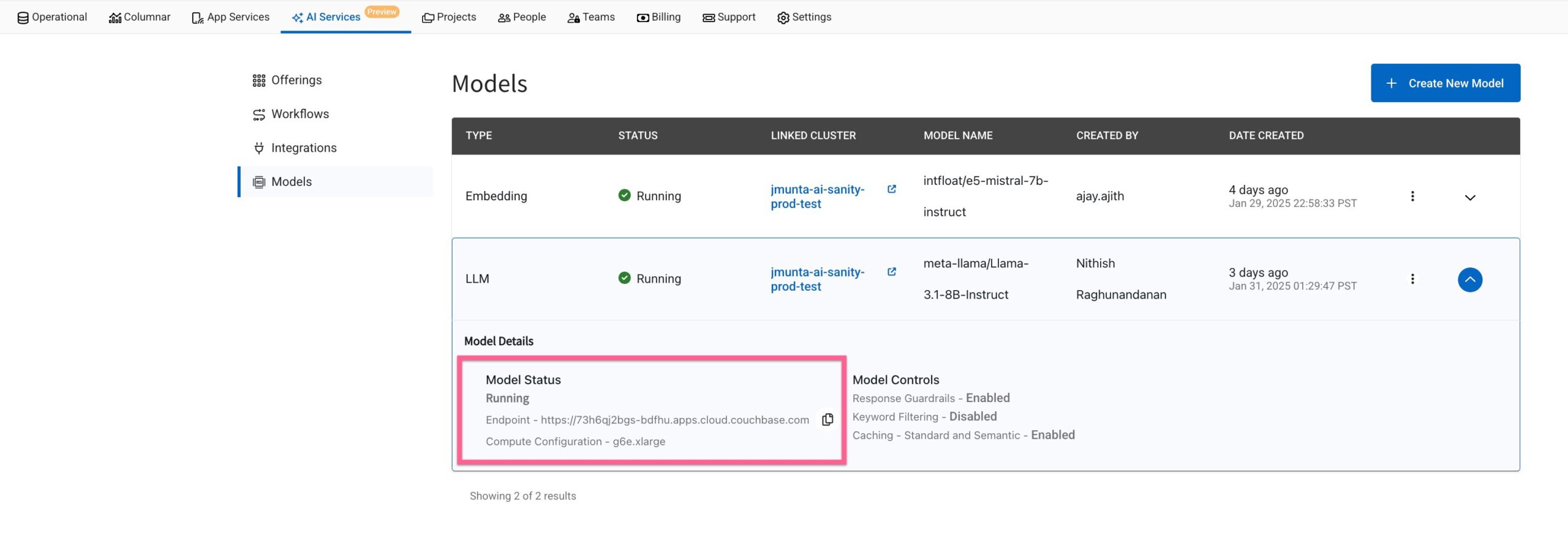
Model endpoint URL
On the Model List page, locate the Model URL. For example, a URL might look like: https://ai123.apps.cloud.couchbase.com.
Run chat completion
To use the OpenAI-compatible API, you can send a chat request using curl:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
curl --request POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --header 'Authorization: Basic change-me' \ --header 'Content-Type: application/json' \ --data '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "reasoning_effort": "high", "messages": [ {"role": "system", "content": "You are a helpful travel assistant"}, {"role": "user", "content": "What are some fun things to do in San Francisco?"} ], "stream": false, "max_tokens": 500 }' |
All OpenAI APIs here are supported out-of-the-box with the Capella Model Service.
Generate embeddings
To generate embeddings for text input, use the following curl command:
|
1 2 3 4 5 6 7 |
curl --request POST \ --url https://ai123.apps.cloud.couchbase.com/v1/embeddings \ --header 'Content-Type: application/json' \ --data '{ "input": "This is my input string", "model": "intfloat/e5-mistral-7b-instruct" }' |
Step 3: using value-added features
Learning Objective: Optimize AI performance with caching, batching, moderation, and keyword filtering.
In this section, we will learn how to optimize your AI application performance and make inferencing faster with built-in enhancements.
Caching reduces redundant computations. Batching improves request efficiency. Content moderation ensures appropriate AI-generated responses. Keyword filtering helps restrict specific terms from appearing in results.
Caching – Reduce redundant computations
Standard caching
Pass a header named X-cb-cache and provide value as “standard”:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
curl --request POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --header 'Authorization: Basic change-me' \ --header 'Content-Type: application/json' \ --header 'User-Agent: insomnia/10.3.0' \ --header 'X-cb-cache: standard' \ --data '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "reasoning_effort": "high", "messages": [ { "role": "system", "content": "You are a helpful travel assistant" }, { "role": "user", "content": "What are some fun things to do in San Francisco? Give me the names of 3 top tourist attractions" } ], "stream": false, "max_tokens": 500 }' |
Response
(Time taken < 500 ms)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
date: Wed, 29 Jan 2025 23:50:37 GMT content-type: application/json content-length: 1316 x-cache: HIT { "choices": [ { "finish_reason": "stop", "index": 0, "logprobs": null, "message": { "content": "San Francisco is a fantastic destination with plenty of exciting activities to enjoy. Here are 3 top tourist attractions to consider:\n\n1. **The Golden Gate Bridge**: An iconic symbol of San Francisco, the Golden Gate Bridge is a must-visit attraction. You can walk or bike across the bridge for spectacular views of the San Francisco Bay and the city skyline.\n\n2. **Alcatraz Island**: Take a ferry to Alcatraz Island, the former maximum-security prison that once held notorious inmates like Al Capone. Learn about the island's rich history and take in the stunning views of the city and the Bay.\n\n3. **Fisherman's Wharf**: This bustling waterfront district offers a taste of San Francisco's seafood culture, street performers, and stunning views of the Bay. You can also catch a cruise to the Golden Gate Bridge or take a stroll along the Pier 39 sea lions.\n\nThese are just a few of the many amazing experiences San Francisco has to offer. Let me know if you'd like more recommendations!", "role": "assistant" } } ], "created": 1738193254, "id": "", "model": "meta-llama/Llama-3.1-8B-Instruct", "object": "chat.completion", "system_fingerprint": "3.0.0-sha-8f326c9", "usage": { "completion_tokens": 206, "prompt_tokens": 62, "total_tokens": 268 } } |
Semantic caching
To understand how semantic caching works, we can pass a series of prompts to the model, to query information around the same entity – for example “San Francisco”. This series of inferences will create embeddings in the caching bucket on the input and use those embeddings to provide top matching results with a high relevance score.
We slightly edit our input prompt in the earlier example to say –
“Can you suggest three must-visit tourist spots in San Francisco for a fun experience?”
This returns the same result as the earlier request for similar question, showing that Model Service is leveraging semantic search for caching.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
curl --request POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --header 'Authorization: Basic change-me' \ --header 'Content-Type: application/json' \ --header 'User-Agent: insomnia/10.3.0' \ --header 'X-cb-cache: semantic' \ --data '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "reasoning_effort": "high", "messages": [ { "role": "system", "content": "You are a helpful travel assistant" }, { "role": "user", "content": "Can you suggest three must-visit tourist spots in San Francisco for a fun experience?" } ], "stream": false, "max_tokens": 500 }' |
Response
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
date: Wed, 29 Jan 2025 23:55:05 GMT content-type: application/json content-length: 1575 x-cache: HIT { "choices": [ { "finish_reason": "stop", "index": 0, "logprobs": null, "message": { "content": "Sure! Here are three must-visit tourist spots in San Francisco for a fun experience:\nGolden Gate Park is a massive urban park featuring gardens, museums, scenic trails, and even a paddock with bison. Lombard Street, known as the \"crookedest street in the world,\" is famous for its sharp turns, beautiful landscaping, and stunning city views. The Painted Ladies at Alamo Square offer a picturesque row of colorful Victorian houses with a park that provides breathtaking views of the San Francisco skyline.", "role": "assistant" } } ], "created": 1738194872, "id": "", "model": "meta-llama/Llama-3.1-8B-Instruct", "object": "chat.completion", "system_fingerprint": "3.0.0-sha-8f326c9", "usage": { "completion_tokens": 282, "prompt_tokens": 61, "total_tokens": 343 } } |
Batching – Improve throughput for multiple requests
If you’re working on an application that frequently queries the Capella Model Service API, batching is a powerful way to speed up responses and optimize API usage.
You can batch multiple requests by using the same OpenAI APIs here – https://platform.openai.com/docs/api-reference/batch for performing inferencing at once.
Here is a sample curl call:
-
- Prepare a sample batch file – batch_requests.jsonl and upload using /v1/files API
123{"messages": [{"role": "user", "content": "What is the capital of Japan?"}], "model": "gpt-4", "max_tokens": 50}{"messages": [{"role": "user", "content": "Who painted the Mona Lisa?"}], "model": "gpt-4", "max_tokens": 50}{"messages": [{"role": "user", "content": "Give me a motivational quote."}], "model": "gpt-4", "max_tokens": 50} - Create the batch using /v1/files API
12345678curl https://ai123.apps.cloud.couchbase.com/v1/batches \-H "Authorization: Basic change-me" \-H "Content-Type: application/json" \-d '{"input_file_id": "BATCH_FILE_ID","endpoint": "/v1/chat/completions","completion_window": "24h"}' - Fetch batch results to track status
12curl https://ai123.apps.cloud.couchbase.com/batches/BATCH_ID \<span style="font-size: 15.2px;">-H "Authorization: Basic change-me"</span>
- Prepare a sample batch file – batch_requests.jsonl and upload using /v1/files API
Content Moderation – Filter sensitive content
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
curl --request POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --header 'Authorization: Basic change-me' \ --header 'Content-Type: application/json' \ --header 'User-Agent: insomnia/10.3.0' \ --data '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "messages": [ { "role": "user", "content": "Tell me how to commit tax fraud and avoid detection." } ], "stream": false }' |
Response
|
1 2 3 4 5 6 7 8 9 10 |
{ "error": { "message": "Error processing user prompt due to guardrail violation", "type": "guardrail_violation_error", "param": { "categories": "s8: intellectual property." }, "code": "guardrail_violation_error" } } |
Keyword Filtering – Restrict specific words or phrases
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
curl --request POST \ --url https://ai123.apps.cloud.couchbase.com/v1/chat/completions \ --header 'Authorization: Basic change-me' \ --header 'Content-Type: application/json' \ --header 'User-Agent: insomnia/10.3.0' \ --data '{ "model": "meta-llama/Llama-3.1-8B-Instruct", "messages": [ { "role": "user", "content": "Tell me the unreleased product roadmap for Apple’s next iPhone." } ], "stream": false }' |
Response
|
1 2 3 4 5 6 7 8 9 10 |
{ "error": { "message": "Error processing user prompt due to guardrail violation", "type": "guardrail_violation_error", "param": { "categories": "s8: intellectual property." }, "code": "guardrail_violation_error" } } |
Final thoughts
Capella’s Model Service is now available for Private Preview. Sign up to try it with free credits and provide feedback to help shape its future development.
Stay tuned for upcoming blogs exploring how to maximize AI capabilities by leveraging data proximity with deployed language models and Capella’s broader AI services.
Sign up for the Private Preview here!
References
-
- Read the Press Release
- Check out Capella AI Services or Sign up for the Private Preview
- Capella Model Service Documentation (for Preview Customers Only)
Acknowledgements
Thanks to the Capella team (Jagadesh M, Ajay A, Aniket K, Vishnu N, Skylar K, Aditya V, Soham B, Hardik N, Bharath P, Mohsin A, Nayan K, Nimiya J, Chandrakanth N, Pramada K, Kiran M, Vishwa Y, Rahul P, Mohan V, Nithish R, Denis S. and many more…). Thanks to everyone who helped directly or indirectly! <3
