Replicação entre centros de dados (XDCR) é um banco de dados essencial.
O XDCR garante a alta disponibilidade (HA), a recuperação de desastres e a geolocalização do banco de dados. Com o a versão 7.0 do Couchbase Server, XDCR também oferece suporte a novos namespaces individuais chamados Scopes e Collections em cada Bucket do banco de dados. O suporte a escopos e coleções também inclui grandes aprimoramentos arquitetônicos para a replicação entre data centers.
Com Scopes e Collections, agora você pode usar o XDCR para replicação de dados para microsserviços específicos ou replicação de dados específicos de locatários para aplicativos multilocatários. Este artigo apresenta um novo recurso de gerenciamento de replicação Collections e descreve um aprimoramento arquitetônico do XDCR nos bastidores.
Esses aprimoramentos no XDCR permitem uma dimensão totalmente nova de casos de uso de replicação. Posições do XDCR Servidor Couchbase 7.0 para oferecer suporte a muitos outros casos de uso de aplicativos de microsserviços ou multilocatários, hoje e no futuro.
Antes de entrarmos em detalhes, aqui estão algumas leituras importantes se você não estiver familiarizado com o Cross Data Center Replication ou com os recursos relacionados:
-
- Uma rápida atualização sobre Noções básicas da arquitetura do XDCR
- Um mergulho profundo em Filtragem avançada de XDCR que abordarei a seguir
- Um artigo informativo sobre Prioridade de replicação do XDCR - um recurso do 6.5 que mencionarei brevemente a seguir
Muito bem, vamos nos aprofundar.
Mapeamento da replicação de dados entre escopos e coleções para XDCR
Se você tiver apenas um único cluster, o gerenciamento de escopos e coleções é relativamente simples. Entretanto, como o XDCR envolve dimensionamento multidimensional, o mapeamento e o gerenciamento desses novos namespaces se tornam mais complexos.
Uma única replicação exclusiva ainda pode existir entre um Bucket de origem e um de destino. Esse requisito não está mudando.
Porém, com a introdução de escopos e coleções, há dois tipos de mapeamentos a serem suportados
gerenciar coleções em uma replicação de Bucket para Bucket. Esses dois tipos são mapeamento implícito e mapeamento explícito.
Um mapeamento é um link entre dois namespaces do mesmo nível e existe no contexto de uma replicação de Bucket para Bucket. Um mapeamento pode ser feito entre Escopos ou entre Coleções.
Cada replicação de Bucket para Bucket usa mapeamento implícito ou explícito para executar a replicação entre as Coleções de origem e de destino. As replicações usam mapeamento implícito, a menos que seja explicitamente especificado de outra forma.
Mapeamento implícito entre coleções
O mapeamento implícito é o conceito de que uma ligação deve ser estabelecida se o mesmo namespace nomeado existir nos Buckets de origem e de destino.
Se tanto o Bucket de origem quanto o de destino contiverem de forma idêntica denominados Escopos e/ou Coleções, então eles são implicitamente mapeados. Por exemplo, no mapeamento implícito, se um Bucket de origem contiver um namespace Escopo1.Coleção1a replicação ocorrerá se o Bucket de destino também contiver Escopo1.Coleção1.
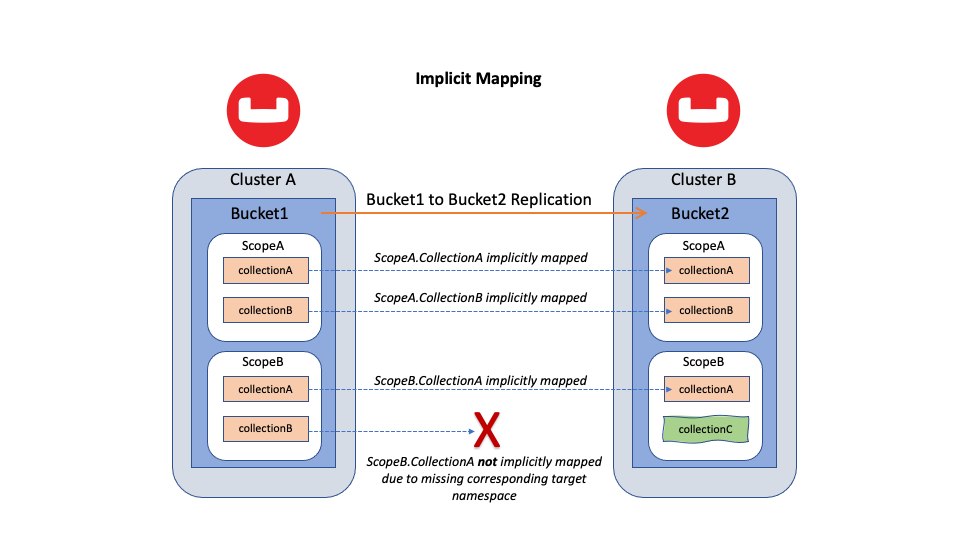
Figura 1: Replicação cruzada de data center (XDCR) entre dois buckets com mapeamento implícito
A Figura 1 acima mostra uma replicação de Bucket para Bucket usando mapeamento implícito. Observe que as coleções padrão de origem e as coleções padrão de destino são mapeadas juntas (não mostradas na figura).
Todos os namespaces não mapeados serão não ser replicado. Se os namespaces não mapeados forem criados posteriormente, o XDCR recuperará os dados ausentes usando uma replicação de backfill. (Explicarei o pipeline de backfill em uma seção posterior).
Mapeamento explícito entre coleções
Se precisar de um controle mais granular sobre a replicação de dados, experimente o mapeamento explícito.
O mapeamento explícito exige que os usuários explicitamente definem relações de namespace. O mapeamento de um escopo para outro escopo significa que todas as coleções dentro desse escopo são implicitamente mapeadas. Entretanto, o mapeamento de uma Collection para outra Collection não afeta nenhum outro namespace.
O mapeamento explícito é realizado por meio do uso de regras de mapeamento por meio da interface de linha de comando (CLI). A interface do usuário do console XDCR oferece uma abstração para que você não precise inserir regras de mapeamento manualmente.
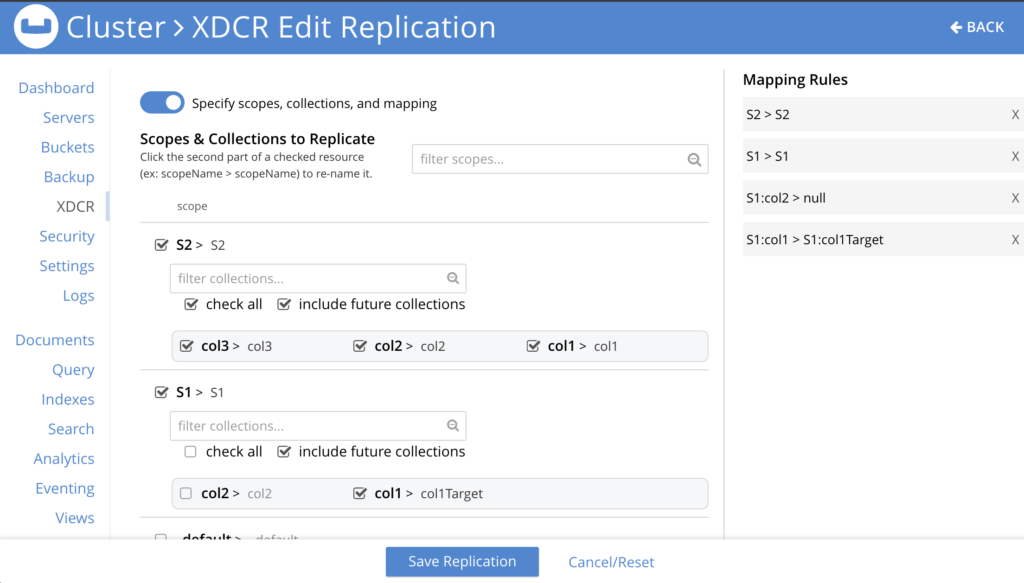
Figura 3: A interface do usuário do XDCR oferece uma experiência fácil de usar para configurar o mapeamento explícito e oculta a necessidade de inserir manualmente as regras de mapeamento
A documentação do Couchbase Server inclui uma explicação detalhada das regras de mapeamento e como usá-las. As regras de mapeamento informam programaticamente ao XDCR como fazer a correspondência dos namespaces por nome.
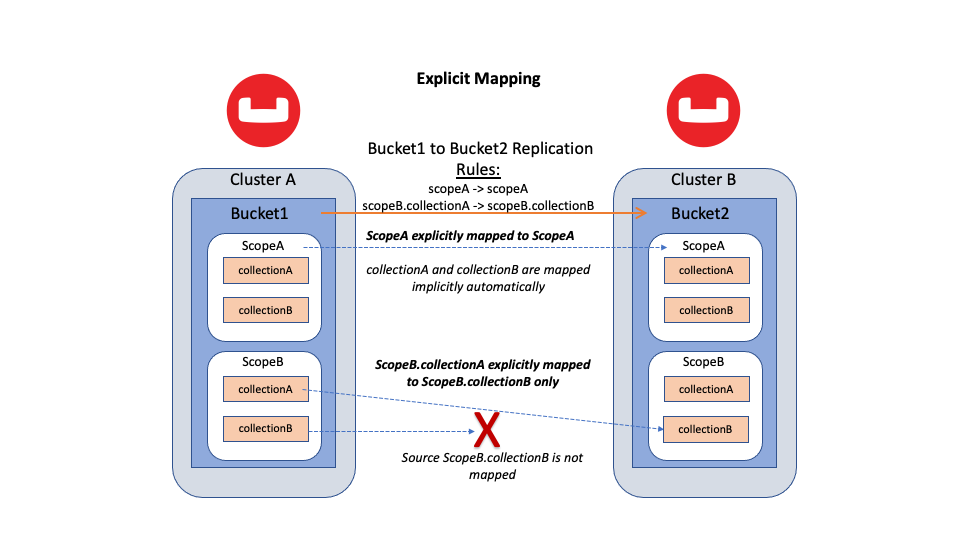
Figura 2: Replicação entre dois Buckets usando mapeamento explícito com duas regras especificadas: uma regra de mapeamento de escopo para escopo e uma regra de mapeamento de coleção para coleção
As regras explícitas de mapeamento oferecem a você um novo nível de flexibilidade no mapeamento de coleções. Você também pode alterar as regras em tempo real. O XDCR aceita todas as novas regras e, em seguida, garante de forma inteligente que todos os dados sejam replicados. Nós
Uso do modo de migração para migrar para coleções
Quando você faz upgrade para o Couchbase Server 7.0, todos os seus dados residem na (nova) coleção padrão dentro dos seus Buckets existentes.
Usando modo de migração Na replicação entre data centers (XDCR), você pode migrar dados para coleções individuais em um bucket de destino sem qualquer tempo de inatividade do aplicativo. O modo de migração é uma versão especializada do mapeamento explícito. Ele utiliza o mecanismo de filtragem avançada do XDCR para realizar a filtragem baseada em fluxo à medida que os documentos são transmitidos do Bucket de origem. Dependendo das regras de migração que você especificar, o documento será replicado para a coleção de destino especificada.
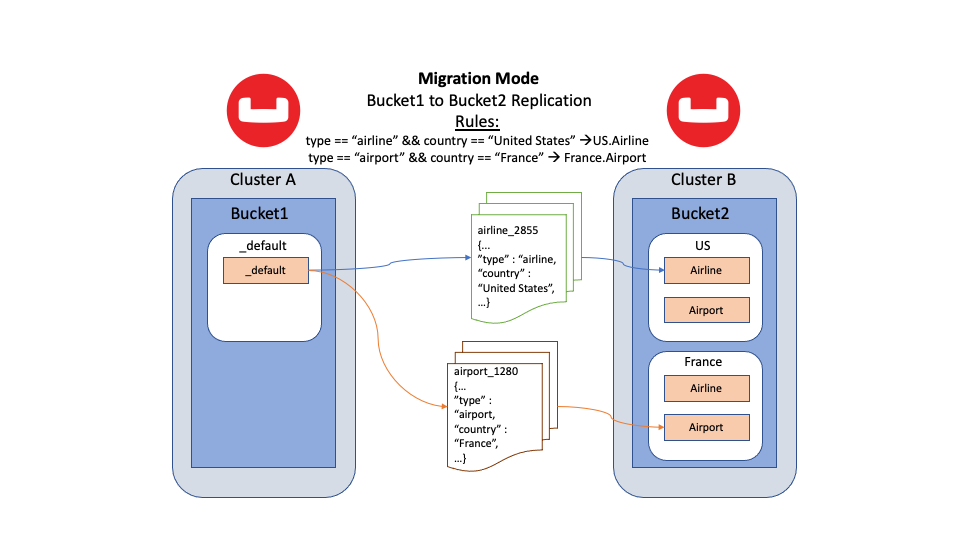
Figura 4: Modo de migração usando diferentes regras de migração para encaminhar documentos para seus respectivos locais
A documentação do Couchbase Server tem Mais detalhes e exemplos sobre o modo de migração.
Bastidores do XDCR com escopos e coleções
Tubulação principal
Quando uma replicação é criada, ela é convertida em uma especificação de replicação e armazenado internamente. Em seguida, o XDCR lê a especificação de replicação (e suas configurações) e cria um tubulação que solicita dados do Bucket de origem. O pipeline replica fielmente cada documento para o bucket de destino (exceto qualquer filtragem avançada em vigor).
O processo acima permanece o mesmo no Couchbase Server 7.0. Portanto, se um de seus Buckets de origem contiver várias Coleções de origem, o XDCR solicitará todas elas. Esse comportamento é chamado de tubulação principal. O pipeline principal replica um documento de origem para o destino usando mapeamento implícito ou explícito. Se o cluster de destino não contiver o namespace mapeado, o XDCR descartará o documento "no chão". Em seguida, ele continua a replicar a próxima mutação.
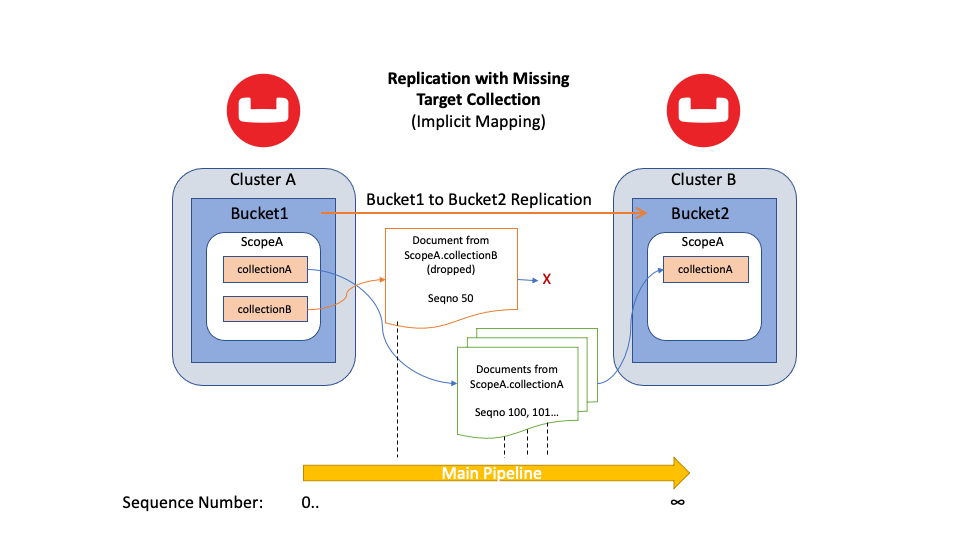
Figura 5: Replicação de todos os documentos do Bucket de origem com uma coleção de destino ausente
Durante a replicação, o XDCR observa continuamente se há coleções de destino novas ou removidas. Quando o XDCR detecta uma nova coleção de destino, ele verifica se um novo mapeamento pode ser estabelecido. Se um novo mapeamento for possível, o pipeline principal replicará com êxito os dados para o namespace de destino.
É importante entender que um fluxo de replicação é sequencial. Se o XDCR tiver descartado um documento anteriormente, um fluxo de sequência não poderá "retroceder" para um ponto anterior do documento perdido. O XDCR precisa replicar todas as mutações perdidas; caso contrário, haverá dados ausentes.
Uma observação: essa incapacidade de retroceder (sem Coleções) é exatamente o motivo pelo qual existe uma opção chamada "Salvar e reiniciar a replicação" ao editar a Expressão de filtragem avançada no Couchbase Server 6.5. Quando você usa a opção "Save and Restart Replication" (Salvar e reiniciar a replicação), o pipeline recomeça e faz o streaming a partir da sequência 0 para garantir que todos os documentos sejam replicados. Essa solução não funcionará para Coleções.
Tubulação de aterro
No Couchbase Server 7.0, o XDCR agora inclui o conceito de um pipeline de backfill.
O objetivo do pipeline de backfill é transmitir os dados que o pipeline principal descartou anteriormente. Essa abordagem garante que todos os dados de um namespace sejam replicados.
Quando uma nova coleção de destino é detectada, o XDCR cria automaticamente um pipeline de preenchimento e transmite os dados ausentes. Enquanto isso, o pipeline principal continua responsável por transmitir quaisquer mutações em andamento para a nova coleção de destino.
Os pipelines de backfill sempre começam no modo de baixa prioridade para minimizar o impacto no desempenho dos pipelines principais. Quando o pipeline de backfill termina de transmitir os dados ausentes - com base em um número de sequência final definido -, o pipeline de backfill é automaticamente desativado.
Todo o processo de construção e desmontagem da replicação de backfill é totalmente automatizado, portanto, acontece nos bastidores sem alertar os usuários. No entanto, é importante que você entenda a arquitetura, pois seus usuários podem perceber que alguns documentos criados posteriormente nos Buckets de origem chegam antes das mutações anteriores.
A Figura 6 abaixo ilustra como funciona o pipeline de replicação de backfill.
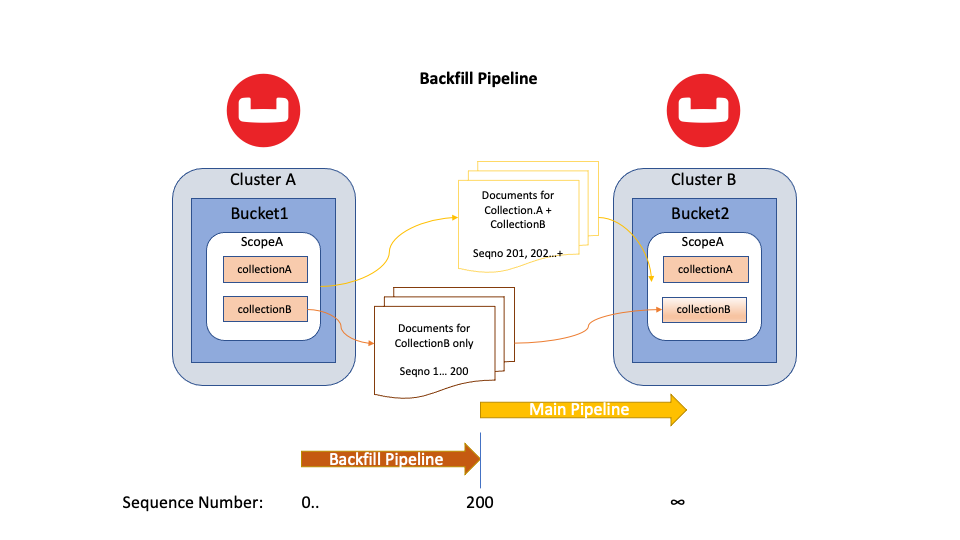
Figura 6: Dados de streaming do backfill pipeline para coleçãoB somente para números de sequência perdidos anteriormente
No diagrama acima, um novo coleçãoB foi criado no Bucket de destino. O XDCR no Cluster A detectou a nova coleção quando seu pipeline principal estava transmitindo mutações no número de sequência 200. Em seguida, ele criou um pipeline de backfill, que é responsável por coleçãoB mutações do número de sequência 0 a 200. Todas as mutações em andamento coleçãoB As mutações (201+) passarão pelo pipeline principal.
Em resumo, o pipeline principal permite que o XDCR continue a replicar as mutações mais recentes continuamente; o pipeline de backfill permite que um fluxo de replicação de prioridade mais baixa replique quaisquer dados perdidos anteriormente.
Conclusão
Em resumo, a replicação de coleções do XDCR monitora de forma inteligente as alterações no gerenciamento de coleções de origem e de destino. Ele pode replicar de forma dinâmica (por meio de mapeamento implícito) ou programática (por meio de mapeamento explícito). O XDCR Collections permite que você altere dinamicamente os modos entre mapeamento implícito e explícito, bem como modifique as regras de mapeamento explícito em tempo real, sem a necessidade de reiniciar a replicação a partir da sequência 0.
Os escopos e as coleções no Couchbase Server 7.0 abrem um mundo totalmente novo de casos de uso para os usuários e clientes do Couchbase. Com o suporte do XDCR a escopos e coleções - e a flexibilidade que ele oferece - o Couchbase Server atende a ainda mais necessidades dos clientes do que qualquer versão anterior.