Introdução
Nas últimas duas semanas, o Spark tem estado em meu cérebro. É compreensível, na verdade, já que estou preparando um webinar da O'Reilly "Como aproveitar o Spark e o NoSQL para aplicativos orientados por dados" com Michael Nitschinger e uma palestra diferente, "Spark and Couchbase: Aumentando o banco de dados operacional com o Spark" para Spark Summit 2016 com Matt Ingenthron. Em outro lugar, você pode aprender sobre o Conector do Couchbase SparkO que há em nossa nova versão e como usá-la. Neste blog, quero falar sobre por que a melhor combinação de banco de dados é o Apache Spark e um Banco de dados NoSQL formam uma boa combinação.
Faísca 101
Se você não estiver familiarizado com ele, Faísca é uma estrutura de processamento de Big Data que faz análises, aprendizado de máquina, processamento de gráficos e muito mais sobre grandes volumes de dados. É semelhante ao Map Reduce, Hive, Impala, Mahout e outras camadas de processamento de dados criadas sobre o HDFS no Hadoop. Assim como o Hadoop, seu foco é a otimização, mas é melhor em muitos aspectos: em geral, é mais rápido, muito mais fácil de programar e tem bons conectores para quase tudo. Diferentemente do Hadoop, é fácil começar a escrever e executar o Spark a partir da linha de comando em seu laptop e, em seguida, implantá-lo em um cluster para executar em um conjunto de dados completo.
O que eu disse até agora pode dar a impressão de que o Spark é um banco de dados, mas ele é enfaticamente não um banco de dados. Na verdade, ele é um mecanismo de processamento de dados. O Spark lê dados em massa que está armazenado em algum lugar como HDFS, Amazon S3 ou Couchbase Server, realiza algum processamento nesses dados e grava os resultados para que possam ser usados posteriormente. É um sistema baseado em trabalho, como o Hadoop, em vez de um sistema on-line, como o Couchbase ou o Oracle. Isso significa que o Spark sempre paga um custo de inicialização que o exclui de cargas de trabalho rápidas do tipo leitura/gravação aleatória. Assim como o Hadoop, o Spark é excelente quando se trata da taxa de transferência geral do sistema, mas isso ocorre às custas da latência.
Em resumo, o Couchbase Server e o Spark resolvem problemas diferentes, mas ambos são bons para resolver. Vamos falar sobre por que as pessoas os usam juntos.
Caso de uso #1 de NoSQL e Spark: Operacionalização da análise/aprendizagem de máquina
Não há dúvida sobre isso: os dados são um ótimo material. Os grandes aplicativos on-line que são executados no Couchbase tendem a ter uma grande quantidade deles. As pessoas criam mais dados todos os dias quando fazem compras on-line, reservam viagens ou enviam mensagens umas às outras. Quando procuro um catálogo de produtos e coloco uma nova lente de câmera no carrinho, algumas informações precisam ser armazenadas no Couchbase para que eu possa concluir minha compra e receber meus novos produtos pelo correio.
Muito mais pode ser feito com os dados da minha viagem de compras que são invisíveis para mim: eles são analisados para ver quais produtos são comumente comprados juntos, para que a próxima pessoa que colocar essa lente em seu carrinho de compras receba melhores recomendações de produtos para que tenha maior probabilidade de comprar. Ele pode ser verificado quanto a sinais de fraude para ajudar a proteger a mim e ao varejista contra bandidos. Ela pode ser rastreada para descobrir se eu preciso de um cupom ou de algum outro incentivo para concluir uma compra sobre a qual estou indeciso. Todos esses são exemplos de aprendizado de máquina e mineração de dados que as empresas podem fazer usando o Spark.
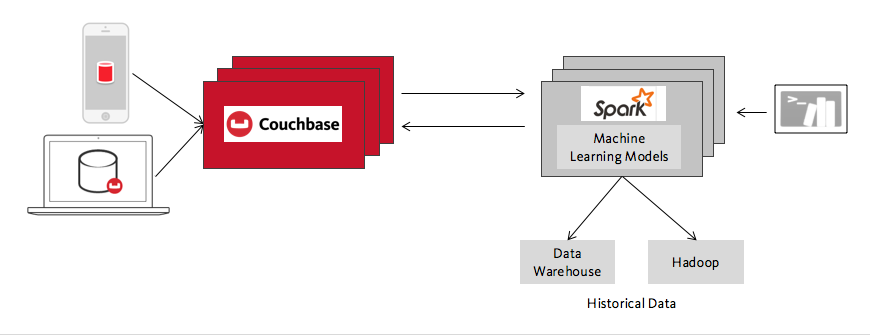
Nessa ampla família de casos de uso, o Spark fornece modelos de aprendizado de máquina, previsões, os resultados de grandes trabalhos de análise e assim por diante, e o Couchbase os torna interativos e os dimensiona para um grande número de usuários. Alguns outros exemplos disso, além das recomendações de compras on-line, incluem classificadores de spam para aplicativos de comunicação em tempo real, análise preditiva que personaliza listas de reprodução para usuários de um aplicativo de música on-line e modelos de detecção de fraude para aplicativos móveis que precisam tomar decisões instantâneas para aceitar ou rejeitar um pagamento. Eu também incluiria nessa categoria um amplo grupo de aplicativos que são, na verdade, armazenamento de dados de "última geração", em que grandes quantidades de dados precisam ser processadas de forma barata e, em seguida, fornecidas de forma interativa a muitos e muitos usuários. Por fim, os cenários da Internet das coisas também se enquadram aqui, com a diferença óbvia de que os dados representam as ações de máquinas em vez de pessoas.
Tecnicamente, o que todos esses casos de uso têm em comum é a divisão em um banco de dados operacional e um cluster de processamento analítico, cada um otimizado para sua carga de trabalho. Essa divisão é como a divisão entre sistemas OLTP e OLAP, atualizada para a era do Big Data. Já falamos sobre o Spark do lado analítico, agora vamos falar sobre o Couchbase e o lado operacional.
Couchbase: Acesso rápido a dados operacionais em escala
O Couchbase Server foi criado para executar aplicativos rápidos, dimensionáveis, fáceis de gerenciar e ágeis o suficiente para evoluir junto com os requisitos de negócios. Os tipos de aplicativos que tendem a usar o aprendizado de máquina e a análise do Spark também tendem a precisar dos recursos oferecidos pelo Couchbase:
- Modelo de dados flexível, esquemas dinâmicos
- Linguagem de consulta avançada (N1QL)
- SDKs nativos
- Latências de menos de um milissegundo para operações de valor-chave em escala
- Dimensionamento elástico
- Facilidade de administração
- XDCR (Replicação entre data centers)
- Alta disponibilidade e distribuição geográfica
Sua camada de processamento de dados operacionais precisa ser distribuída para fins de resiliência, alta disponibilidade e por motivos de desempenho, pois a proximidade da localização geográfica do usuário é importante. O mecanismo de distribuição deve ser transparente para os desenvolvedores e deve ser simples de operar. Todas essas propriedades, que são verdadeiras independentemente de você estar ou não usando o Spark, foram abordado extensivamente em outro lugar.
O Couchbase Spark Connector oferece uma integração de código aberto entre as duas tecnologias e tem alguns benefícios próprios:
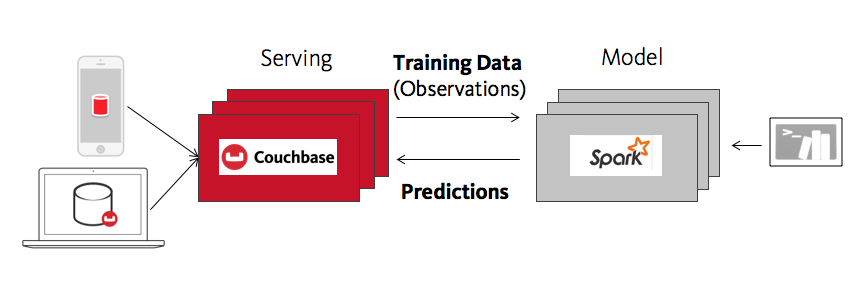
- Centrado na memória. Tanto o Spark quanto o Couchbase são centrados na memória. Isso pode reduzir significativamente o tempo de processamento de dados da primeira viagem de ida e volta, ou também reduzir o tempo de insight/tempo de ação de ponta a ponta. O tempo para o insight refere-se à viagem de ida e volta entre "fazer uma observação" (armazenar alguns dados sobre o que um usuário ou máquina está fazendo) e analisar esses dados, geralmente no contexto da criação ou atualização de um modelo de aprendizado de máquina e, em seguida, devolvê-los ao usuário de uma forma que ele possa usar, como uma previsão nova e aprimorada.
- Rápido. Além do fato de que tanto o Spark quanto o Couchbase são centrados na memória, o Couchbase Spark Connector inclui uma série de aprimoramentos de desempenho, incluindo predicado push down, localidade de dados / reconhecimento de topologia, API de subdocumento e loteamento implícito.
- Funcionalidade. O Couchbase Spark Connector permite que você use toda a gama de métodos de acesso a dados para trabalhar com dados no Spark e no Couchbase Server: RDDs, DataFrames, Datasets, DStreams, operações KV, consultas N1QL, Map Reduce e Visualizações espaciais, e até mesmo DCP são todos compatíveis com Scala e Java.
Caso de uso do NoSQL e do Spark #2: kit de ferramentas de integração de dados
A ampla gama de funcionalidades suportadas pelo Couchbase Spark Connector nos leva ao outro grande caso de uso do Spark e do Couchbase: Integração de dados.
O interesse pelo Spark explodiu nos últimos anos, o que fez com que o Spark se conectasse a quase tudo, de bancos de dados a Elasticsearch, Kafka, HDFS, Amazon S3 e muito mais. Ele também pode ler dados em praticamente qualquer formato, como Parquet, Avro, CSV, Apache Arrow, etc. Toda essa conectividade faz do Spark um excelente kit de ferramentas para resolver desafios de integração de dados.
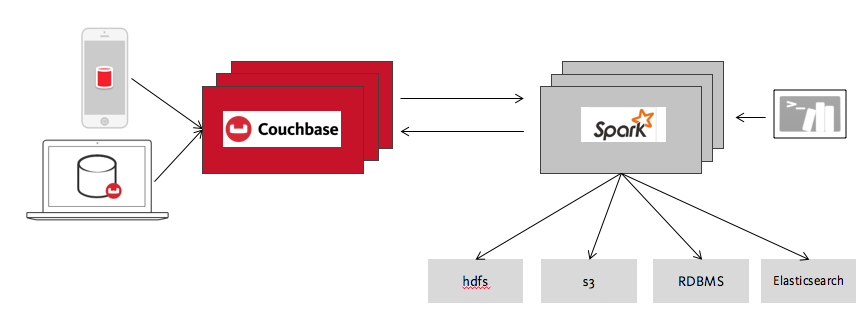
Por exemplo, imagine que você é um engenheiro de dados. Você precisa carregar informações sobre os interesses dos seus usuários nos perfis deles para dar suporte a um novo recurso premium que está adicionando ao seu aplicativo móvel. Digamos que seus perfis de usuário estejam no Couchbase Server, seus interesses de usuário venham do HDFS e sua lista de usuários premium seja baseada em informações de pagamento em seu Armazém de dados.
Isso parece uma tarefa relativamente simples, mas tediosa, em que você vai a cada sistema para extrair as informações de que precisa e depois as importa para o sistema seguinte. O Spark oferece uma alternativa prática. Depois de se familiarizar com o Spark, você poderá executar essa tarefa usando algumas consultas simples na linha de comando. Usando os recursos nativos de cada um dos sistemas, você pode unir as tabelas no Spark e gravar os resultados no Couchbase em uma única etapa. Não há nada mais conveniente. As mesmas etapas podem ser ampliadas para criar pipelines de dados que combinam dados de várias fontes e os alimentam em aplicativos ou outros consumidores.
Experimente
Não importa se você está desenvolvendo um grande aplicativo com aprendizado de máquina sofisticado como parte de uma grande equipe de engenharia ou se é um desenvolvedor solitário, o Spark e o Couchbase têm algo a oferecer. Experimente e nos diga o que você achou. Como sempre, gostamos de ouvir sua opinião. Boa codificação!
[...] Ainda está se perguntando Por que Spark e NoSQL? [...]