O que são modelos de linguagem de visão?
Os modelos de linguagem de visão são sistemas de IA projetados para compreender e raciocinar em dados visuais e textuais. Diferentemente dos modelos tradicionais de visão computacional (CV), que analisam apenas imagens, ou dos modelos de linguagem ampla (LLMs), que processam apenas texto, os VLMs conectam essas duas modalidades para formar um entendimento compartilhado.
Em geral, os VLMs são treinados em grandes conjuntos de dados que contêm imagens e textos emparelhados, como fotos com legendas ou documentos que misturam visual e linguagem. Por meio desse treinamento, os VLMs aprendem como os recursos visuais (por exemplo, objetos, cenas e relações espaciais) são mapeados para palavras e significados. Isso permite que os modelos descrevam imagens, respondam a perguntas sobre elas e raciocinem sobre o conteúdo visual usando a linguagem.
Como funcionam os modelos de linguagem de visão
Os modelos de linguagem visual combinam o entendimento visual e a compreensão da linguagem em um único sistema. Embora as arquiteturas variem, a maioria dos VLMs segue o mesmo fluxo de trabalho principal descrito abaixo.
1. Codificação de imagens e extração de recursos visuais
- As imagens são processadas por um codificador de visão, geralmente uma rede neural convolucional (CNN) ou um transformador de visão (ViT).
- O codificador extrai recursos visuais significativos, como objetos, formas, texturas e relações espaciais.
- Esses recursos são convertidos em representações numéricas sobre as quais o modelo pode raciocinar.
2. Codificação de texto e compreensão da linguagem
- As entradas de texto são processadas por um codificador de linguagem, normalmente baseado em arquiteturas de transformadores.
- O codificador captura o significado semântico, o contexto e as relações entre as palavras.
- O resultado é uma representação estruturada da linguagem que se alinha aos conceitos visuais.
3. Alinhamento transmodal entre visão e linguagem
- O modelo aprende a mapear representações de imagem e texto em um espaço de incorporação compartilhado.
- Nesse espaço, as imagens e os textos relacionados são posicionados mais próximos uns dos outros, enquanto os pares não relacionados são afastados.
- Esse alinhamento permite tarefas como legendagem de imagens, resposta a perguntas visuais (VQA) e recuperação de texto-imagem.
- Modelos como o CLIP são bem conhecidos por aprenderem um forte alinhamento imagem-texto em escala.
4. Treinamento vs. inferência em VLMs
- Treinamento:
- O modelo é treinado em grandes conjuntos de dados de imagens e textos emparelhados (por exemplo, legendas, descrições ou documentos).
- Os objetivos incentivam o modelo a associar corretamente as imagens à linguagem relevante.
- Inferência:
- Depois de treinado, o modelo aplica o que aprendeu a novas entradas.
- Ele pode interpretar imagens, responder a perguntas, gerar descrições ou recuperar conteúdo relevante sem treinamento adicional.
Modelos de linguagem de visão vs. modelos tradicionais de visão computacional vs. modelos de linguagem grandes
Embora os três tipos de modelos se enquadrem na categoria mais ampla de IA, eles foram projetados para finalidades muito diferentes. As principais diferenças estão nos dados que eles podem processar, na forma como raciocinam e nos tipos de tarefas para as quais são mais adequados. Compreender essas distinções ajuda as equipes a escolher o modelo certo para o problema certo. Aqui está uma comparação rápida que descreve as principais diferenças:
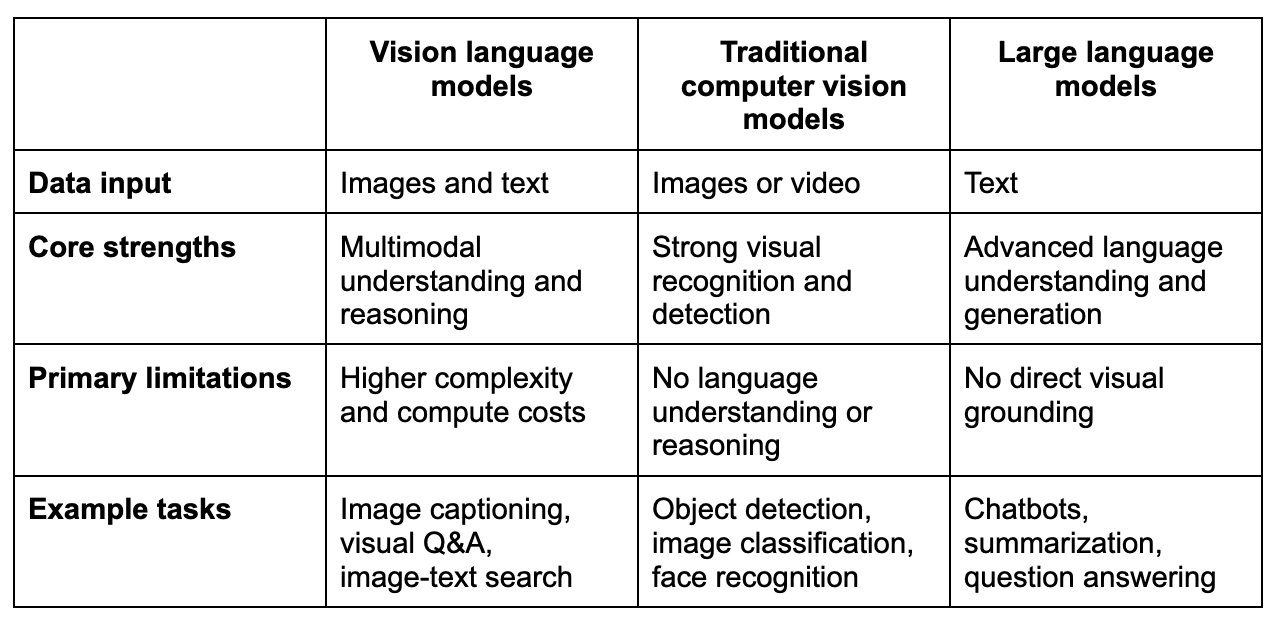
Principais diferenças explicadas
- Os modelos tradicionais de CV concentram-se exclusivamente em sinais visuais e são otimizados para identificar o que há em uma imagem, mas não para explicá-la em linguagem natural.
- Os LLMs são excelentes em raciocinar com texto, mas não têm consciência do contexto visual, a menos que ele seja descrito para eles.
- Os VLMs preenchem a lacuna entre os modelos CV e os LLMs, permitindo o raciocínio fundamentado nas modalidades de imagem e texto.
VLMs bem conhecidos, como o CLIP, aprendem a alinhar imagens e linguagem, enquanto as versões multimodais do GPT-5 estendem esse recurso para raciocínio e interação mais gerais.
Quando usar um modelo de linguagem de visão em vez de um modelo de modalidade única
Use um modelo de linguagem de visão quando:
- A tarefa exige a compreensão conjunta de imagens e textos
- Os usuários precisam de explicações, respostas ou raciocínio com base em conteúdo visual
- Os aplicativos envolvem pesquisa multimodal, compreensão de documentos ou assistência visual
Use um modelo tradicional de visão computacional quando:
- A tarefa é puramente visual (por exemplo, detecção de defeitos, contagem de objetos)
- Velocidade, eficiência ou implantação de borda são essenciais
- Não é necessário nenhum raciocínio ou explicação baseada em linguagem
Use um modelo de linguagem grande quando:
- O problema envolve apenas texto (por exemplo, resumo, geração de conteúdo)
- O contexto visual é desnecessário ou já está codificado no texto
- Você precisa de um raciocínio flexível em linguagem natural
Principais recursos e tarefas
A capacidade de entender conjuntamente o conteúdo visual e a linguagem natural permite que os VLMs interpretem, raciocinem e interajam com as imagens de maneiras mais flexíveis e semelhantes às humanas, como, por exemplo:
Legenda da imagem
Os VLMs podem gerar descrições de linguagem natural de imagens, identificando objetos, ações e relacionamentos em uma cena. Esse recurso é comumente usado para ferramentas de acessibilidade, moderação de conteúdo e gerenciamento de mídia.
Resposta visual a perguntas
A resposta a perguntas visuais permite que os usuários façam perguntas sobre uma imagem e recebam respostas relevantes e contextualizadas. O modelo deve entender tanto o conteúdo visual quanto a intenção por trás da pergunta para responder com precisão.
Recuperação de imagem-texto
Os VLMs oferecem suporte à pesquisa multimodal, combinando imagens com texto e vice-versa. Isso permite casos de uso, como encontrar produtos com base em descrições ou recuperar imagens relevantes usando consultas em linguagem natural.
Raciocínio multimodal
Os VLMs podem raciocinar com base em entradas visuais e textuais para tirar conclusões, comparar elementos ou seguir instruções baseadas em imagens. Esse recurso é essencial para tarefas complexas, como assistência visual e suporte a decisões.
Compreensão de documentos e cenas
Os VLMs podem interpretar documentos e cenas do mundo real que combinam texto e recursos visuais, como formulários, diagramas, capturas de tela ou imagens de ruas. Isso possibilita aplicativos como análise de documentos, automação de fluxo de trabalho e sistemas com reconhecimento de ambiente.
Casos de uso para modelos de linguagem de visão
Ao combinar modalidades, os VLMs permitem interações mais ricas, melhor automação e insights mais precisos em muitos setores em que a compreensão do conteúdo visual e da linguagem é essencial. Os casos de uso comuns incluem:
- Pesquisa e descoberta visual: Permita que os usuários pesquisem produtos, imagens ou conteúdo usando descrições em linguagem natural em vez de palavras-chave.
- Suporte ao cliente e solução de problemas: Interpretar capturas de tela ou fotos enviadas pelos usuários para fornecer assistência mais rápida e precisa.
- Processamento e análise de documentos: Extrair significado de documentos que combinam texto, tabelas, gráficos e imagens, como faturas, contratos e relatórios.
- Ferramentas de acessibilidade: Gere descrições de imagens e responda a perguntas visuais para dar suporte a usuários com deficiências visuais.
- Cuidados com a saúde e imagens médicas: Analisar imagens médicas juntamente com anotações clínicas para apoiar o diagnóstico, a documentação e a pesquisa.
- Varejo e comércio eletrônico: Potencialize as recomendações visuais de produtos, a pesquisa baseada em imagens e a marcação automática de catálogos.
- Sistemas autônomos e robótica: Ajude as máquinas a entender seu ambiente e a seguir instruções baseadas em linguagem fundamentadas no contexto visual.
- Moderação de conteúdo e segurança: Identifique e interprete o conteúdo visual junto com o texto para aplicar políticas com mais precisão.
Dados e arquiteturas de treinamento
Os modelos de linguagem visual dependem de dados multimodais em grande escala e arquiteturas especializadas para aprender as relações entre imagens e linguagem. A qualidade dos dados e o design da arquitetura do modelo desempenham um papel fundamental no desempenho de um VLM em várias tarefas.
Dados de treinamento para modelos de linguagem de visão
Os modelos de linguagem visual exigem diversos dados de treinamento para capturar tanto o amplo conhecimento multimodal quanto as relações específicas da tarefa ou do domínio entre imagens e texto. Esses dados incluem:
- Pares imagem-texto: O formato de dados de treinamento mais comum, em que as imagens são combinadas com legendas, descrições ou texto ao redor
- Conjuntos de dados em escala da Web: Grandes coleções de imagens e textos disponíveis publicamente, usadas para aprender conceitos visuais e linguísticos amplos
- Conjuntos de dados anotados: Dados cuidadosamente rotulados para tarefas como resposta a perguntas visuais, compreensão de documentos ou interpretação de cenas
- Dados específicos do domínio: Conjuntos de dados especializados (por exemplo, imagens médicas com anotações clínicas ou imagens de produtos com metadados) usados para melhorar o desempenho em setores específicos
Arquiteturas comuns de VLM
Surgiram vários paradigmas arquitetônicos para modelos de linguagem de visão, cada um equilibrando eficiência, flexibilidade e capacidade de raciocínio de maneiras diferentes:
- Modelos de codificador duplo:
- Use codificadores separados para imagens e texto
- Aprenda a alinhar as representações visuais e linguísticas em um espaço de incorporação compartilhado
- Adequado para tarefas de recuperação e treinamento em escala (por exemplo, CLIP)
- Modelos de codificador-decodificador:
- Codifique entradas visuais e gere saídas de texto diretamente
- Comumente usado para legendas de imagens e respostas a perguntas visuais (por exemplo, BLIP)
- Modelos multimodais unificados:
- Processe imagens e textos juntos em uma única arquitetura baseada em transformadores
- Permitir o raciocínio multimodal avançado e o manuseio flexível de tarefas
Função dos transformadores e mecanismos de atenção
- As arquiteturas de transformação permitem que os modelos atendam a partes relevantes de imagens e textos.
- Os mecanismos de atenção ajudam o modelo a entender as relações entre regiões visuais e palavras ou frases.
- Esse design é fundamental para permitir o raciocínio complexo entre modalidades.
Limitações dos modelos de linguagem de visão
Embora os modelos de linguagem de visão ofereçam recursos multimodais avançados, eles também vêm com limitações importantes que as equipes devem entender antes de implantá-los em aplicativos do mundo real.
- Qualidade e viés dos dados: Os VLMs são treinados em grandes conjuntos de dados de imagem-texto que podem conter ruído, imprecisões ou vieses sociais, o que pode afetar os resultados do modelo e a imparcialidade.
- Alto custo computacional: O treinamento e a execução de VLMs requerem recursos de computação significativos, o que torna sua criação, implantação e dimensionamento dispendiosos.
- Base visual limitada: Os modelos podem gerar respostas confiantes, mas incorretas, se os detalhes visuais forem sutis, ambíguos ou estiverem fora da distribuição de treinamento.
- Desafios de generalização: O desempenho pode cair quando os modelos encontram domínios desconhecidos, estilos de imagem ou cenários do mundo real que não estão bem representados nos dados de treinamento.
- Problemas de interpretabilidade: Muitas vezes é difícil entender por que um VLM produziu um resultado específico, o que pode ser problemático em ambientes regulamentados ou de alto risco.
- Restrições de latência: A complexidade do processamento multimodal pode introduzir atrasos, limitando a adequação para processamento em tempo real ou em tempo real. aplicativos de borda.
- Preocupações éticas e de privacidade: O uso de imagens que incluem pessoas, espaços privados ou informações confidenciais aumenta os riscos de privacidade, consentimento e uso indevido.
O reconhecimento dessas limitações é essencial para a aplicação responsável de modelos de linguagem de visão e para a seleção de proteções, métodos de avaliação e casos de uso adequados.
Avaliação e métricas de desempenho
A avaliação dos modelos de linguagem visual requer a medição da compreensão visual e do desempenho da linguagem, geralmente em várias tarefas. Como muitos resultados do VLM são abertos, a avaliação eficaz geralmente combina métricas automatizadas com julgamento humano.
Métricas específicas da tarefa
Dependendo da formulação específica da tarefa, as métricas de desempenho preditivo padrão incluem:
- Precisão: Comumente usado para tarefas de estilo de classificação, como resposta a perguntas visuais com conjuntos de respostas fixas
- Precisão, recuperação e pontuação F1: Medir a qualidade com que o modelo identifica os resultados relevantes, especialmente em tarefas de recuperação ou detecção
- Precisão top-k: Avalia se a resposta correta aparece entre as principais previsões do modelo
Métricas de qualidade de geração
Para tarefas em que o modelo gera texto de forma livre, as métricas especializadas incluem:
- BLEU: Mede a sobreposição entre o texto gerado e as legendas ou respostas de referência, geralmente usadas para legendas de imagens e tarefas de tradução
- ROUGE: Concentra-se na recuperação e é comumente aplicado a resultados no estilo de resumo
- CIDEr e METEOR: Projetado especificamente para avaliar legendas de imagens, comparando-as com várias referências humanas
Métricas de recuperação e alinhamento
Quando o objetivo é avaliar como os modelos associam bem imagens e textos, as métricas incluem:
- Recall@K: Avalia a frequência com que a imagem ou o texto correto é recuperado nos K principais resultados
- Classificação recíproca média (MRR): Avalia a qualidade da classificação em tarefas de recuperação de texto e imagem
- Modal cruzado similaridade pontuações: Meça a qualidade do alinhamento das incorporações de imagem e texto em espaços de representação compartilhados
Avaliação humana
Como as métricas automatizadas podem não ter nuances, o julgamento humano é frequentemente incorporado para fornecer uma avaliação mais holística do comportamento do modelo.
- Os revisores humanos avaliam qualidades que as métricas automatizadas têm dificuldade de capturar, como correção, relevância, raciocínio e fluência.
- A avaliação humana é especialmente importante para o raciocínio multimodal e para as tarefas de geração abertas.
Métricas de desempenho operacional
Além da qualidade dos resultados, a implementação prática também exige a avaliação da eficiência do desempenho dos modelos sob restrições do sistema no mundo realcomo, por exemplo:
- Latência: Tempo necessário para processar entradas de imagem-texto e gerar saídas
- Taxa de transferência: Número de solicitações tratadas em um determinado período de tempo
- Utilização de recursos: Requisitos de memória e computação durante a inferência
Uma estratégia de avaliação equilibrada garante que os modelos de linguagem de visão sejam precisos, confiáveis e práticos de implantar.
Tendências futuras em modelos de linguagem de visão
Os modelos de visão de linguagem continuam a evoluir à medida que as pesquisas vão além do alinhamento básico entre imagem e texto, chegando a uma compreensão mais profunda, raciocínio e interação no mundo real. Várias tendências importantes estão moldando a próxima geração de recursos de VLM. Algumas delas incluem:
- Raciocínio multimodal mais sólido: Os modelos irão além da mera descrição de imagens e passarão a executar o raciocínio passo a passo com base em evidências visuais, permitindo a tomada de decisões e análises mais confiáveis.
- Arquiteturas multimodais unificadas: É provável que os futuros VLMs lidem com imagens, texto, vídeo, áudio e outras modalidades em um único modelo coeso, e não em componentes separados.
- Melhor aterramento e confiabilidade: A pesquisa está cada vez mais focada em reduzir as alucinações e melhorar a forma como os modelos vinculam seus resultados diretamente às entradas visuais.
- Treinamento e inferência mais eficientes: Os avanços na compactação de modelos, destilação e otimização de hardware reduzirão os custos e tornarão os VLMs mais práticos em escala e em dispositivos de ponta.
- VLMs especializados em domínio: Espere mais modelos treinados ou ajustados para setores específicos, como saúde, finanças, manufatura e pesquisa científica.
- Integração com agentes e ferramentas: Os VLMs serão cada vez mais combinados com agentes autônomos, permitindo que os sistemas percebam ambientes, planejem ações e interajam com o mundo usando tanto a visão quanto a linguagem.
- Maior ênfase na ética e na governança: À medida que a adoção cresce, a transparência, a proteção da privacidade e a mitigação de preconceitos se tornarão fundamentais para o desenvolvimento e a implantação do VLM.
Juntas, essas tendências apontam para que os modelos de linguagem de visão se tornem um camada de base para sistemas de IA multimodais que possam ver, entender, raciocinar e agir mais como os humanos em ambientes complexos.
Principais conclusões e recursos relacionados
Os modelos de linguagem visual representam um grande avanço na IA ao unificar a compreensão visual e o raciocínio de linguagem natural em um único sistema. Ao aprender com dados de texto-imagem emparelhados e alinhar a visão e a linguagem em representações compartilhadas, os VLMs permitem interações mais flexíveis, conscientes do contexto e semelhantes às humanas em uma ampla gama de aplicações.
Principais conclusões
- Os modelos de linguagem visual são projetados para compreender conjuntamente imagens e textos, diferentemente dos modelos tradicionais de visão computacional ou dos modelos de linguagem de grande porte que operam em uma única modalidade.
- Os VLMs aprendem as relações entre os recursos visuais e a linguagem treinando em grandes conjuntos de dados de imagens e textos emparelhados.
- A maioria dos modelos de linguagem de visão depende de codificadores separados de visão e linguagem que são alinhados em um espaço de representação compartilhado.
- Modelos como o CLIP demonstram que o alinhamento imagem-texto em larga escala permite uma forte recuperação e raciocínio multimodal.
- Os modelos de linguagem visual são especialmente eficazes para tarefas que exigem compreensão multimodal, incluindo legendas de imagens, respostas a perguntas visuais e interpretação de documentos ou cenas.
- Apesar de seus recursos, os VLMs enfrentam limitações significativas em termos de qualidade de dados, viés, custo computacional, generalização e interpretabilidade.
- Os avanços contínuos em arquiteturas, eficiência e fundamentação estão posicionando os modelos de linguagem de visão como um componente fundamental dos futuros sistemas multimodais de IA.
Para saber mais sobre tópicos relacionados aos avanços da IA, você pode visitar os recursos relacionados abaixo:
Recursos relacionados
- Um guia completo para o processo de desenvolvimento de aplicativos de IA - Blog
- Crie seu primeiro agente de IA de código aberto com o Couchbase - Blog
- Custos de desenvolvimento de aplicativos (um detalhamento) - Blog
- Um guia para o gerenciamento de dados de IA - Blog
- Uma visão geral da análise de dados não estruturados - Blog
Perguntas frequentes
Como os modelos de linguagem de visão são treinados e avaliados? Os modelos de linguagem visual são treinados em conjuntos de dados de texto-imagem emparelhados em grande escala e são avaliados em tarefas de referência, como recuperação de texto-imagem, resposta a perguntas visuais, legendas e raciocínio multimodal.
Como os modelos de linguagem de visão entendem a relação entre imagens e texto? Eles aprendem a mapear entradas visuais e textuais em um incorporação espaço em que imagens e textos relacionados são posicionados próximos uns dos outros, permitindo o alinhamento e o raciocínio entre as modalidades.
Como os modelos de linguagem de visão lidam com entradas multimodais? Os VLMs processam imagens e textos por meio de codificadores separados e, em seguida, combinam suas representações usando mecanismos de atenção ou arquiteturas compartilhadas para raciocinar conjuntamente sobre ambas as entradas.
Os modelos de linguagem de visão são adequados para em tempo real ou aplicativos de borda? Eles podem ser usados em tempo real para alguns aplicativos, mas os altos custos computacionais e a latência geralmente exigem otimização, modelos menores ou implantação baseada em nuvem em vez de dispositivos de borda.
Quais preocupações éticas ou de privacidade estão associadas aos modelos de linguagem visual? As principais preocupações incluem o viés herdado dos dados de treinamento, o uso indevido de imagens contendo pessoas ou informações confidenciais e os desafios relacionados ao consentimento, à vigilância e à privacidade dos dados.
Como as empresas podem começar a usar modelos de linguagem de visão? As empresas podem começar experimentando modelos pré-treinados ou APIs, identificando casos de uso multimodais de alto impacto e ajustando ou integrando gradualmente os VLMs com base em seus dados, infraestrutura e necessidades de conformidade.