Recentemente, estava trabalhando em um projeto que usava o N1QL para fazer consultas Servidor Couchbase dados. Esse era um aplicativo Java interno que eu estava hospedando em uma instância de baixo orçamento do Amazon EC2. Meu problema era que minhas consultas estavam sendo executadas de forma incrivelmente lenta. O motivo disso é que eu só tinha um índice primário que era muito genérico.
Vamos dar uma olhada no que fiz para acelerar minhas consultas e em alguns aspectos que tive de considerar durante o processo.
Em primeiro lugar, é provavelmente uma boa ideia compartilhar a versão do Couchbase Server que estou usando. Estou usando o Couchbase Server 4.1 em minha máquina de baixa potência. O bucket com o qual estou trabalhando tem cerca de 100.000 documentos de tipos variados. Não que isso seja importante para este artigo, mas o aplicativo que acessa esses dados foi criado em Java usando o Couchbase Java SDK.
Com minha configuração fora do caminho, deixe-me compartilhar uma das consultas que eu estava executando:
|
1 2 3 4 5 6 7 8 9 |
SELECIONAR MILLIS_TO_UTC(data, '2006-01-12') AS tweetDate, CONTAGEM(*) AS contagem DE `padrão` ONDE tipo='tweet' GRUPO BY MILLIS_TO_UTC(data, '2006-01-12') ORDEM BY tweetDate ASC |
Essa consulta retornaria o número total de Tweets que eu havia salvo em uma data específica. As informações de tempo não eram importantes para mim. Observe que, no início, eu tinha apenas um único índice, que era o meu índice primário. A consulta acima levaria um bom tempo para ser executada.
Foi aí que comecei a reavaliar minha estratégia.
Decidi aproveitar os índices de cobertura que foram disponibilizados no Couchbase 4.1. Isso ocorre quando criamos um índice que abrange todas as propriedades que serão usadas em uma consulta. Meu criação de índices para a consulta anterior tinha a seguinte aparência:
|
1 2 3 4 5 |
CRIAR ÍNDICE twitter_por_data ON `padrão` (data, tipo) ONDE tipo = 'tweet' USO GSI; |
Sim, estou fazendo agregações, mas, no final das contas, estou apenas consultando com base no data e tipo propriedades. Então, executei a consulta novamente com o índice de cobertura, mas não vi nenhuma alteração no desempenho.
Isso me levou a executar um EXPLICAR na própria consulta para solucionar o que estava acontecendo.
|
1 2 3 4 5 6 7 8 9 |
EXPLICAR SELECIONAR MILLIS_TO_UTC(data, '2006-01-12') AS tweetDate, CONTAGEM(*) AS contagem DE `padrão` ONDE tipo='tweet' GRUPO BY MILLIS_TO_UTC(data, '2006-01-12') ORDEM BY tweetDate ASC |
Quando vi o detalhamento da consulta que EXPLICAR me forneceu, pude ver que ele ainda estava tentando usar o #primário que eu havia criado originalmente. Isso ocorre mesmo depois de eu ter validado que o índice de cobertura agora existia no Couchbase.
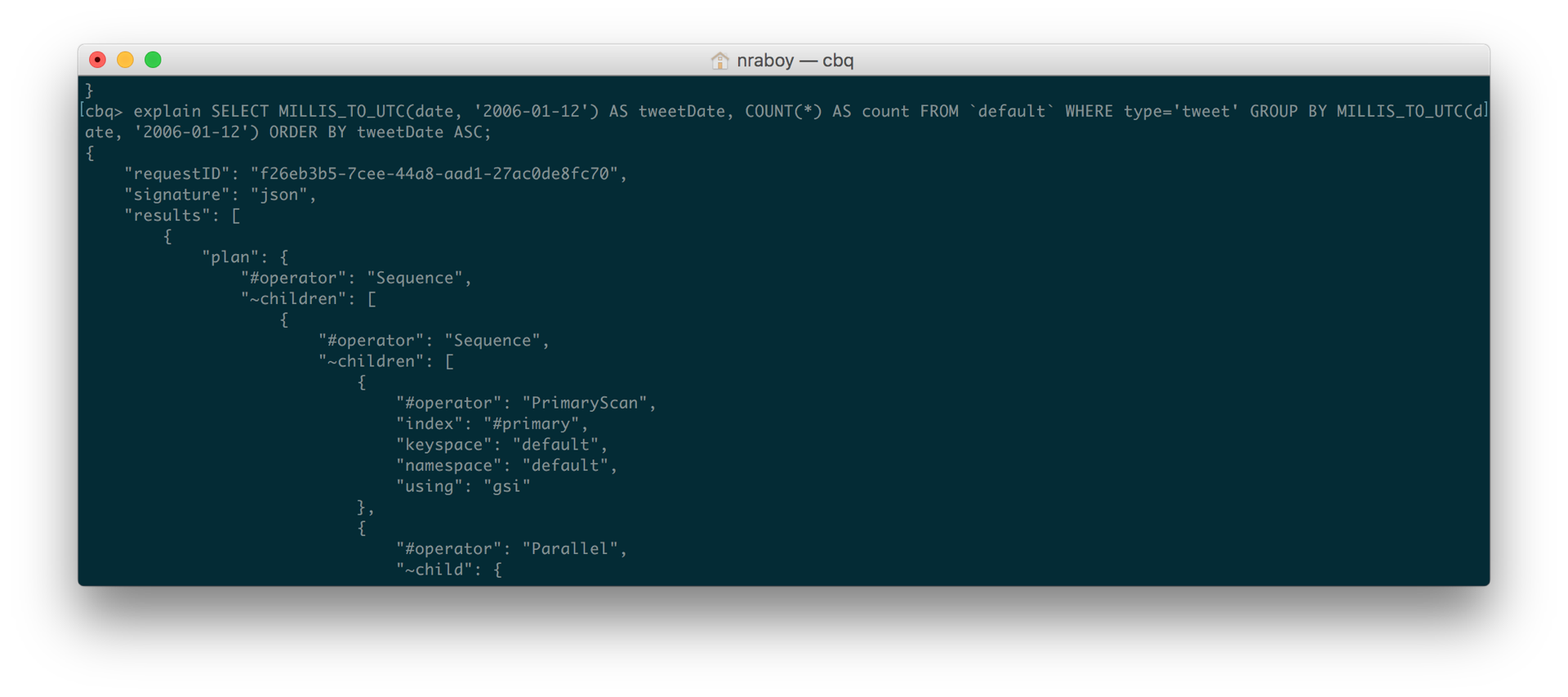
Então, lembrei que os documentos do Twitter não eram os únicos tipos de dados que existiam em meu bucket. Em outras palavras, nem todos os documentos tinham uma propriedade chamada data e nem todos os documentos tinham uma propriedade tipo que correspondiam tuíte. Agora tive que revisar a consulta que eu queria executar para verificar esses cenários.
|
1 2 3 4 5 6 7 8 9 |
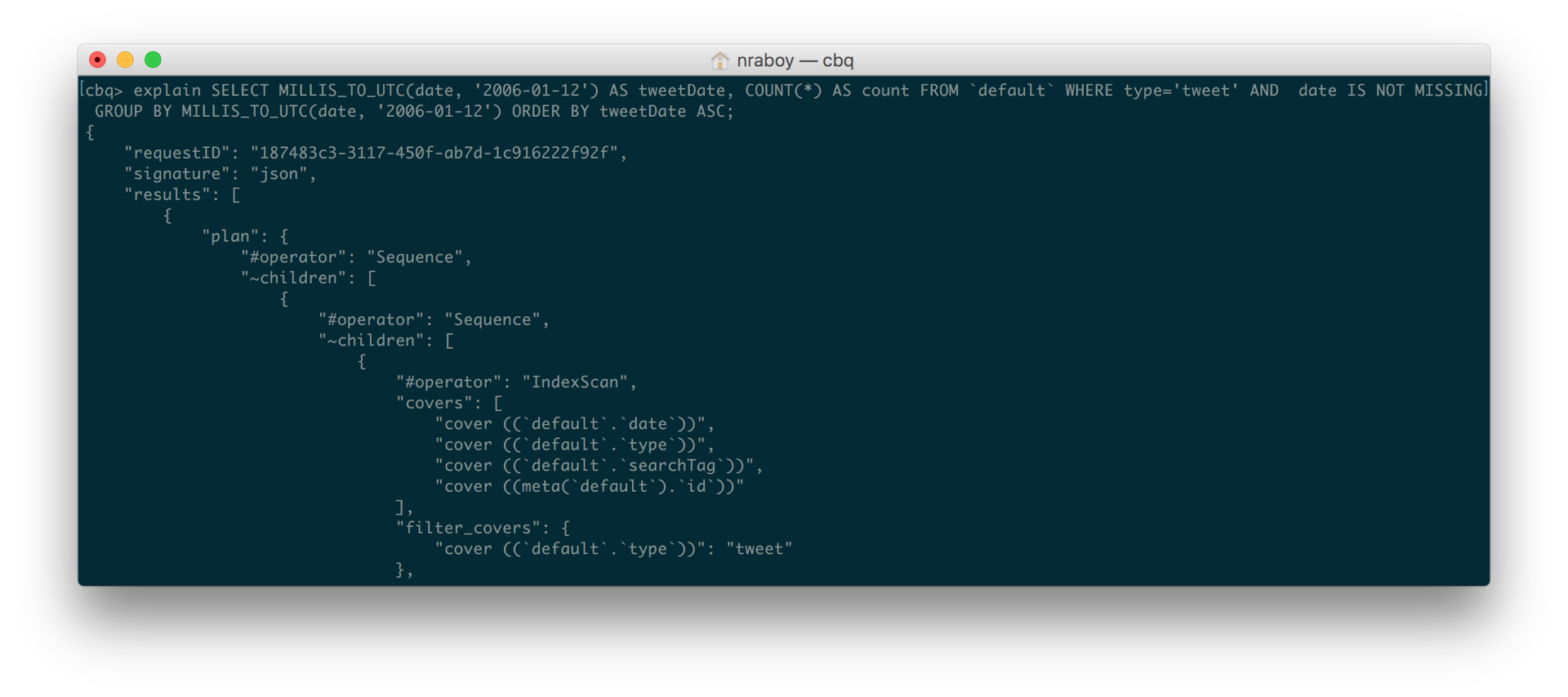
SELECIONAR MILLIS_TO_UTC(data, '2006-01-12') AS tweetDate, CONTAGEM(*) AS contagem DE `padrão` ONDE tipo='tweet' E data IS NÃO FALTANDO GRUPO BY MILLIS_TO_UTC(data, '2006-01-12') ORDEM BY tweetDate ASC |
Na consulta acima, observe em particular como adicionei E a data NÃO ESTÁ FALTANDO. Primeiro, estou verificando se o data existe. Já estávamos verificando essa propriedade tipo combinados tuítemas estava faltando a outra peça.
Depois de executar a consulta novamente, ela ficou significativamente mais rápida. Quando incluí EXPLICAR Pude ver imediatamente que a consulta agora estava usando o índice de cobertura em vez do índice primário.
Para saber mais sobre a cobertura de índices, visite o site Portal do desenvolvedor do Couchbase.