Os aplicativos modernos são implementados como um conjunto de um grande número de microsserviços. Cada um desses microsserviços pode ser executado independentemente de muitos outros microsserviços. Esses aplicativos esperam que os bancos de dados subjacentes ofereçam suporte a multilocação. O Couchbase Server 7.0 introduziu Escopos e coleções para dar suporte a multilocação e para facilitar a modelagem de dados para aplicativos modernos. Os escopos e as coleções oferecem aos usuários uma separação lógica dos dados em um bucket.
Agora, cada microsserviço de um aplicativo pode criar independentemente os índices secundários globais necessários para esse microsserviço. Nas versões anteriores do Couchbase Server, apenas uma solicitação de criação de índice era permitida no cluster. Para reforçar o suporte a multilocação, no Couchbase Server 7.0, o fluxo de trabalho de criação de índices foi aprimorado para permitir várias solicitações simultâneas de criação de índices. Neste blog, discutiremos como a experiência do usuário na criação simultânea de vários índices foi aprimorada.
Fluxo de trabalho aprimorado de criação de índices
Primeiro, vamos entender o fluxo de trabalho de criação de índices em um cluster do Couchbase. Criação de índices acontece em duas fases (1) Criação de metadados de índice e (2) Construção do índice. Na primeira fase, o serviço de índice do Couchbase determina o melhor posicionamento possível para o novo índice, com a ajuda de planejador de índicese os metadados do índice são mantidos. Na segunda fase, os nós de host determinados na primeira fase iniciarão um fluxo com o serviço de dados para a "criação do índice". Os usuários podem especificar o defer_build durante a criação do índice para executar somente a primeira fase e a segunda fase pode ser acionada posteriormente usando o sinalizador índice de construção comando.
Nas seções a seguir, o significado de criação de índices é limitado apenas à primeira fase.
Para obter o melhor posicionamento possível do índice, apenas uma instância do planejador de índice deve ser executada por vez. Portanto, o serviço de índice - que executa versões mais antigas do servidor Couchbase - rejeita qualquer nova solicitação de criação de índice recebida se houver uma solicitação de criação de índice em andamento. 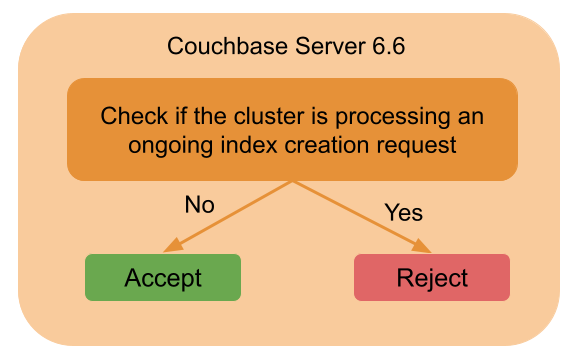
Esse comportamento foi aprimorado no Couchbase Server 7.0, onde o serviço de índice aceita todas as solicitações de criação de índice recebidas, mesmo que haja uma criação de índice em andamento. O serviço de índice enfileira a solicitação de criação de índice, processa as solicitações enfileiradas em segundo plano e, somente depois que o índice é criado, a resposta é retornada ao chamador.
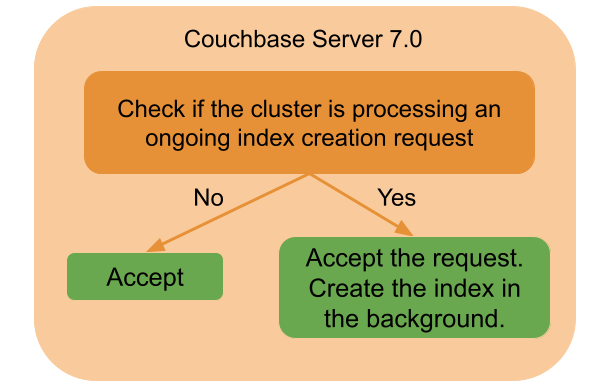
Observe que a criação do índice era uma solicitação de bloqueio antes do Couchbase Server 7.0 e permanece bloqueada também nas novas versões.
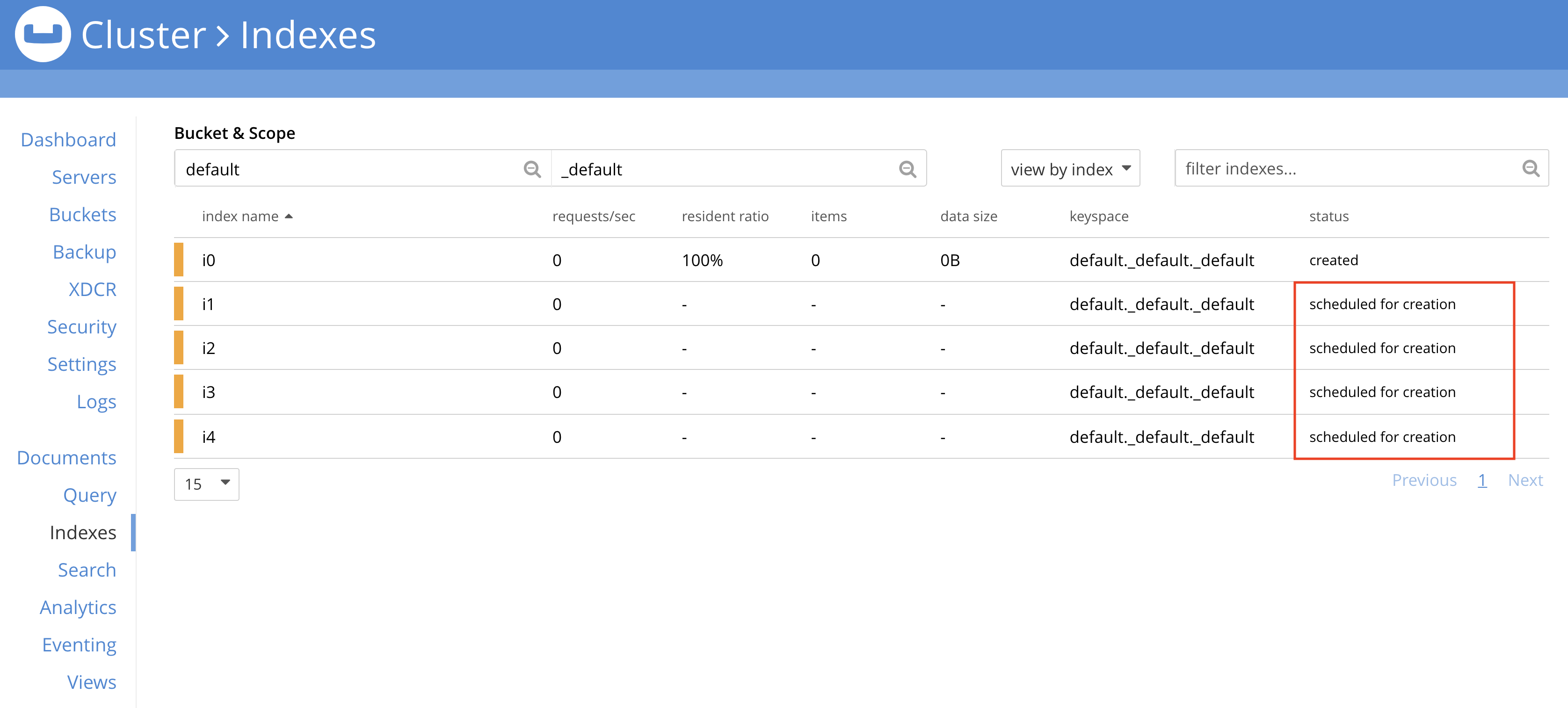
Os usuários podem monitorar os índices que estão na fila para criação em segundo plano por meio da interface do usuário da Web, conforme mostrado na captura de tela abaixo. Observe que o índice status é programado para criação.
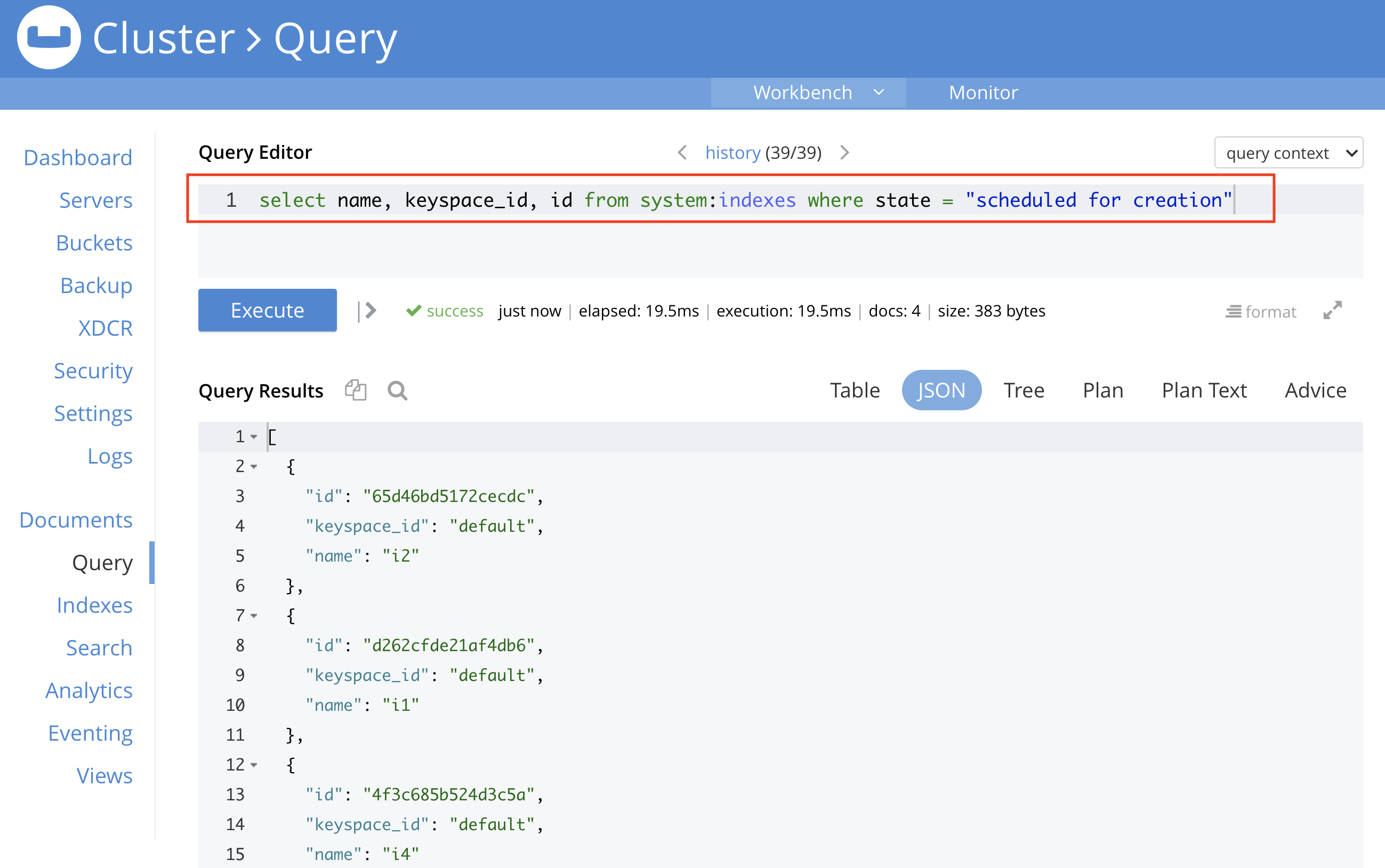
Os usuários também podem monitorar o status do índice de forma programática usando o N1QL, conforme mostrado na captura de tela abaixo.
Melhoria da experiência do usuário
Nas versões anteriores, os usuários tinham que tentar novamente a criação do índice quando havia outro índice em andamento sendo criado. Se a criação do índice estiver ocorrendo de forma programática, o programa precisará de um mecanismo de repetição. Com o servidor Couchbase 7.0, o programa do usuário não precisa contar com o mecanismo de repetição ao criar um índice, pois o serviço de índice executará as tentativas necessárias em segundo plano. Observe que o serviço de índice não executa apenas "tentativas simples". Ele prioriza internamente as solicitações com base no registro de data e hora da solicitação, de modo que a convergência das solicitações de criação de índices seja mais rápida e muito mais confiável.
O serviço de índice serializa as criações de índice no cluster com a ajuda de um mecanismo de bloqueio distribuído globalmente. Portanto, para a criação de um índice, todos os nós do serviço de índice precisam chegar a um consenso antes de permitir a criação do índice.
Agora, vamos dar uma olhada no cenário/exemplo a seguir para entender como a convergência é aprimorada com o envolvimento do serviço de índice.
Digamos que dois aplicativos de usuário (ou microsserviços) estejam tentando criar índices simultaneamente. Os dois aplicativos podem se conectar a dois nós de serviço de consulta diferentes para a criação de índices. O nó de serviço de consulta executa um cliente de serviço de índice que é responsável por adquirir o bloqueio distribuído globalmente e determinar o posicionamento do índice executando o planejador de índices.
Linha do tempo de criação do índice na versão pré-7.0 do Couchbase
Vamos considerar uma possível linha do tempo dos eventos que ocorrem no cluster (com a versão < 7.0 do Couchbase Server), conforme mostrado no diagrama abaixo.
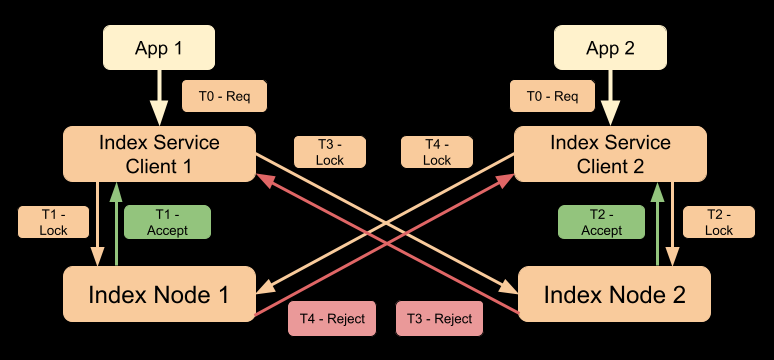
Linha do tempo:
T0: Ambos os aplicativos acionam solicitações de criação de índices simultaneamente e as solicitações são recebidas pelos clientes do serviço de índice.
T1: O cliente de serviço de índice 1 envia o Trava para o nó de índice 1. Nó de índice 1 aceita a solicitação.
T2: O cliente de serviço de índice 2 envia o Trava para o nó de índice 2. Nó de índice 2 aceita a solicitação.
T3: O cliente de serviço de índice 1 envia o Trava para o nó de índice 2. Nó de índice 2 rejeita a solicitação, pois já aceitou a solicitação do cliente 2.
T4: O cliente de serviço de índice 2 envia o Trava para o nó de índice 1. Nó de índice 1 rejeita a solicitação, pois já aceitou a solicitação do cliente 1.
Observe que, neste exemplo, na versão do Couchbase Server < 7.0, ambas as solicitações serão rejeitadas pelo Couchbase e os scripts do usuário precisarão tentar novamente. Se os scripts do usuário tentarem novamente imediatamente ou depois de algum período de espera determinístico, a próxima tentativa ainda poderá levar a um cenário/linha do tempo semelhante e ambas as solicitações ainda poderão ser rejeitadas na próxima tentativa.
Fila de criação de índice com o Couchbase 7.0
Com o Couchbase Server 7.0, o comportamento aprimorado e uma linha do tempo semelhante ao nosso exemplo são mostrados no diagrama abaixo. Observe que a responsabilidade de criar um índice é assumida pelos criadores de índices em segundo plano, enquanto o thread do aplicativo do usuário ainda está aguardando a conclusão da criação do índice. O thread do usuário receberá uma resposta somente quando o índice for criado.
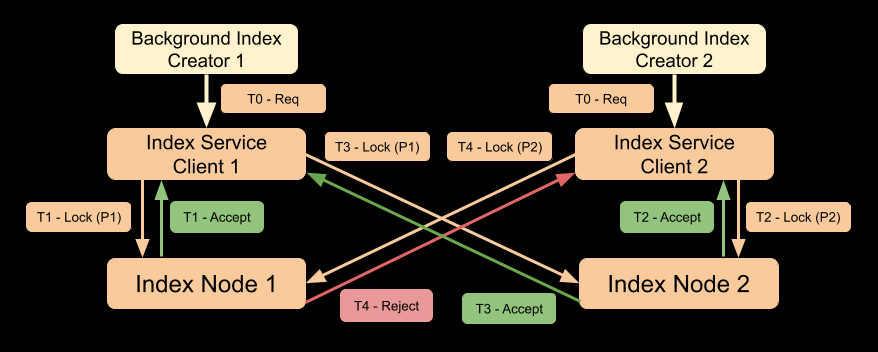
Linha do tempo:
T0: Dois threads de criação de índice em segundo plano acionam a criação de índice simultaneamente e as solicitações são recebidas pelos clientes do serviço de índice.
T1: O cliente de serviço de índice 1 envia o Trava (com prioridade P1) para o nó de índice 1. Nó de índice 1 aceita a solicitação.
T2: O cliente de serviço de índice 2 envia o Trava (com prioridade P2) para o nó de índice 2. Nó de índice 2 aceita a solicitação.
T3: O cliente de serviço de índice 1 envia o Trava (com prioridade P1) para o nó de índice 2. Nó de índice 2 aceita a solicitação, pois ela tem prioridade mais alta do que a solicitação aceita anteriormente.
T4: O cliente de serviço de índice 2 envia o Trava (com prioridade P2) para o nó de índice 1. Nó de índice 1 rejeita a solicitação, pois já aceitou a solicitação com prioridade mais alta do cliente 2.
Observe que o mecanismo de bloqueio distribuído usa um protocolo de confirmação em duas fases de modo que a solicitação aceita anteriormente (com prioridade P2) no nó de índice 2 falhará durante a fase de confirmação e será tentada novamente pelo criador do índice em segundo plano.
Observe também que as prioridades de solicitação são baseadas em registros de data e hora de solicitação gerados com granularidade de nanossegundos. Isso elimina a maior parte da contenção de bloqueio distribuído. Mas há uma possibilidade de duas solicitações terem exatamente os mesmos registros de data e hora. Para lidar com esse caso, o serviço de índice usa backoff aleatório para reduzir ainda mais a contenção de bloqueio distribuído.