Modern applications are implemented as a set of a large number of microservices. Each such microservice may run independently of many other microservices. Such applications expect underlying databases to support multi-tenancy. Couchbase Server 7.0 has introduced Scopes and Collections to support multi-tenancy and to ease data modeling for modern-day applications. The scopes and the collections provide users a logical separation of the data within a bucket.
Each microservice for an application can now independently create Global Secondary Indexes needed by that microservice. In previous releases of Couchbase Server only one index creation request was allowed in the cluster. For strengthening the support for multi-tenancy, in Couchbase Server 7.0, the index creation workflow has been improved to allow multiple concurrent index creation requests. In this blog, we will discuss how the user experience of creating multiple indexes concurrently has been improved.
Improved Index Creation Workflow
Let’s first understand the index creation workflow in a Couchbase cluster. Index creation happens in two phases (1) Index metadata creation and (2) Index build. In the first phase, the Couchbase index service determines the best possible placement for the new index, with the help of index planner, and index metadata is persisted. In the second phase, the host nodes determined in the first phase will start a stream with the data service for the “index build”. Users can specify the defer_build flag during index creation to execute only the first phase and the second phase can be triggered later using the build index command.
In the following sections, the meaning of index creation is limited only to the first phase.
To achieve the best possible index placement, only one instance of index planner should run at a time. Hence index service – running older versions of Couchbase server – rejects any new incoming index creation requests if there is an ongoing index creation request. 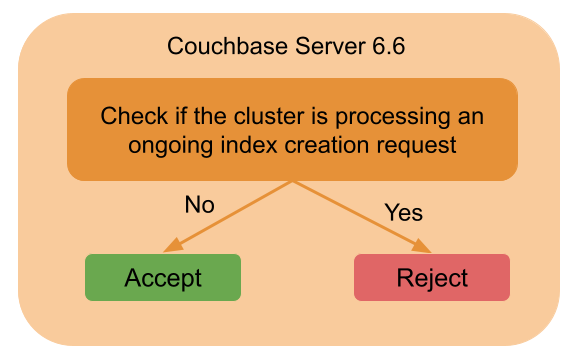
This behavior has been improved in Couchbase Server 7.0, where the index service accepts all incoming index creation requests, even if there is an ongoing index creation. The index service queues up the index creation request, processes the queued requests in the background and only after the index is created is the response returned to the caller.
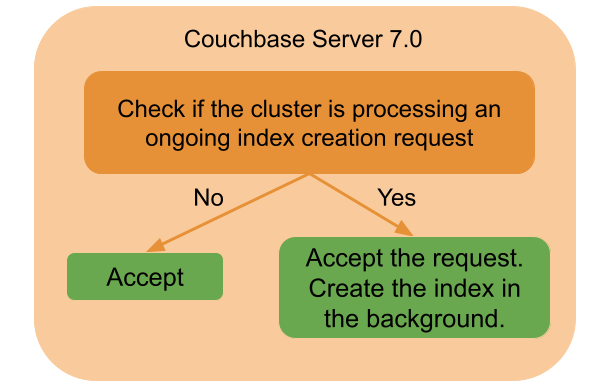
Please note that the index creation was a blocking request prior to Couchbase Server 7.0 and it remains blocking in the new releases as well.
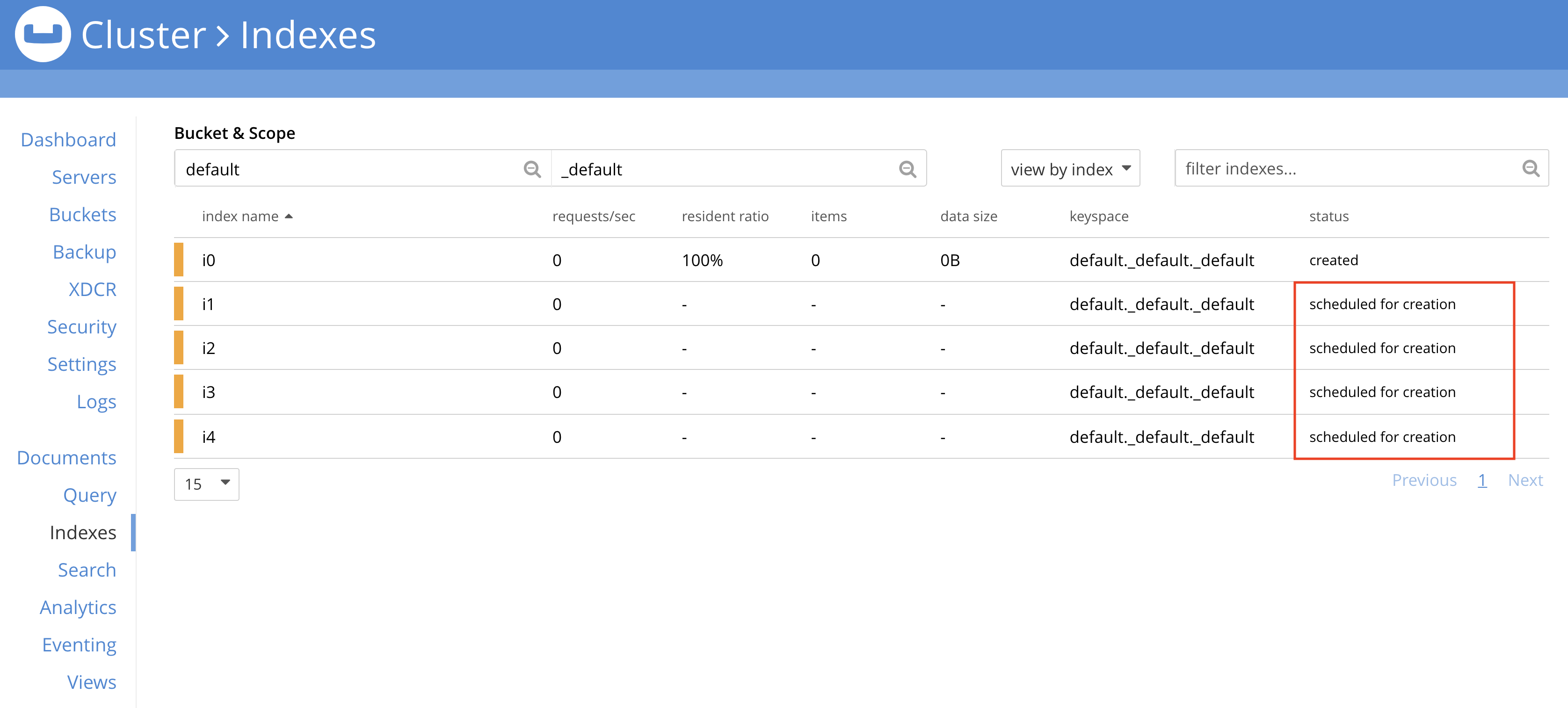
Users can monitor the indexes that are queued for background creation via Web UI as shown in the screenshot below. Note that the index status is scheduled for creation.
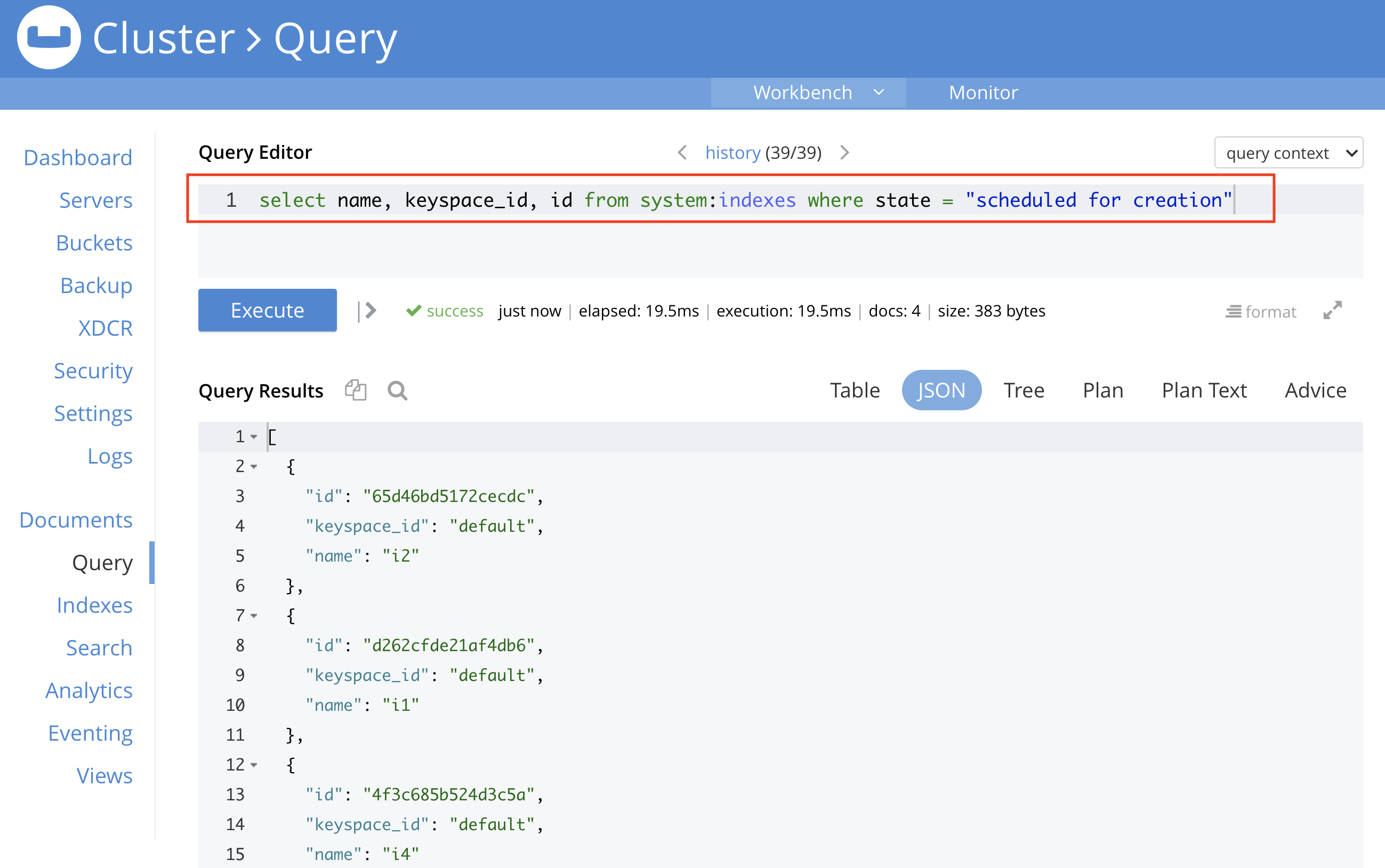
Users can also monitor index status programmatically using N1QL, as shown in the screenshot below.
Improved User Experience
In the previous releases, users had to retry the index creation when there was another ongoing index being created. If the index creation is happening programmatically, then the program needs a retry mechanism. With Couchbase server 7.0, the user program does not need to rely on the retry mechanism while creating an index as the index service will perform the required retries in the background. Note that the index service doesn’t just perform “simple retries”. It internally prioritizes the requests based on the request’s timestamp so that the convergence of index creation requests is faster and much more reliable.
The index service serializes the index creations in the cluster with the help of a globally distributed lock mechanism. So, for the creation of an index, all index service nodes need to reach a consensus before allowing the index creation.
Now, let’s take a look at the following scenario/example to understand how convergence is improved with the involvement of the index service.
Let’s say two user applications (or microservices) are trying to create indexes concurrently. The two applications can connect to two different query service nodes for the creation of indexes. The query service node runs an index service client which is responsible for acquiring the globally distributed lock and determining the index placement by running the index planner.
Index creation timeline in pre-7.0 version of Couchbase
Let’s consider one possible timeline of events happening in the cluster (with Couchbase Server version < 7.0) as shown in the diagram below.
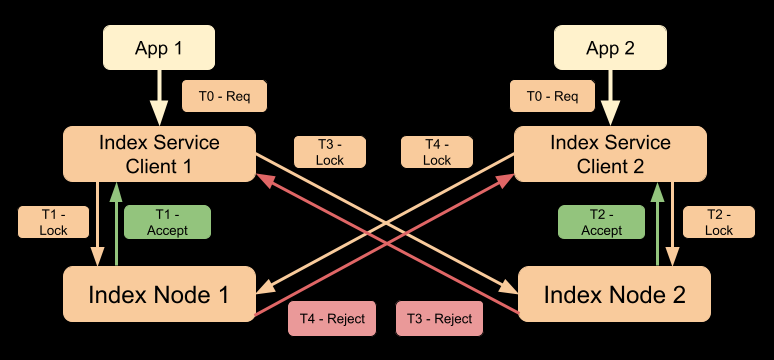
Timeline:
T0: Both applications trigger index creation requests simultaneously and the requests are received by index service clients.
T1: Index service client 1 sends the Lock request to index node 1. Index node 1 accepts the request.
T2: Index service client 2 sends the Lock request to index node 2. Index node 2 accepts the request.
T3: Index service client 1 sends the Lock request to index node 2. Index node 2 rejects the request as it has already accepted the request from client 2.
T4: Index service client 2 sends the Lock request to index node 1. Index node 1 rejects the request as it has already accepted the request from client 1.
Note that in this example, in Couchbase Server version < 7.0, both the requests will be rejected by Couchbase and the user scripts will need to retry. If user scripts retry immediately or after some deterministic back-off period, the next attempt may still lead to a similar scenario/timeline and both requests can still be rejected in the next attempt.
Index creation queuing with Couchbase 7.0
With Couchbase Server 7.0 the improved behavior, and a timeline similar to our example, is shown in the diagram below. Note that the responsibility of creating an index is taken over by background index creators, while the user application thread is still waiting for index creation to finish. The user thread will get a response only when the index is created.
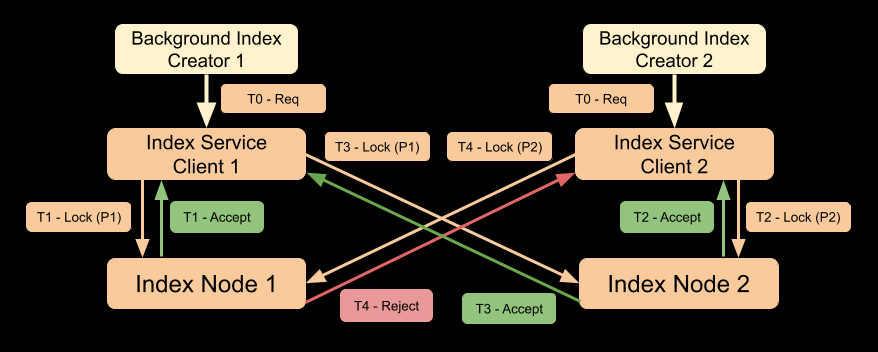
Timeline:
T0: Two background index creator threads trigger index creation simultaneously and the requests are received by index service clients.
T1: Index service client 1 sends the Lock request (with priority P1) to index node 1. Index node 1 accepts the request.
T2: Index service client 2 sends the Lock request (with priority P2) to index node 2. Index node 2 accepts the request.
T3: Index service client 1 sends the Lock request (with priority P1) to index node 2. Index node 2 accepts the request as it has higher priority than the previously accepted request.
T4: Index service client 2 sends the Lock request (with priority P2) to index node 1. Index node 1 rejects the request as it has already accepted the request with higher priority from client 2.
Note that the distributed lock mechanism uses a two-phase commit protocol so that the previously accepted request (with priority P2) on index node 2 will fail during the commit phase and will be retried by the background index creator.
Also, note that the request priorities are based on request timestamps generated at nanosecond granularity. This eliminates most of the distributed lock contention. But there is a corner case possibility of two requests having exactly the same request timestamps. To handle this case index service uses random backoff to further reduce the distributed lock contention.