
Large language models have changed how we interact with information, but they have one fundamental limitation: their knowledge is frozen in time. They can’t access real-time data or information from private, proprietary documents because they only know what they’ve been trained on. This is where RAG comes in. By connecting LLMs to external knowledge sources, RAG makes them smarter, more accurate, and more useful.
What is RAG?
RAG is an AI technique that improves large language models by allowing them to retrieve relevant external information before generating a response. Instead of relying solely on pre-trained knowledge, RAG searches connected data sources, such as documents or databases, to provide more accurate, up-to-date, and context-aware answers.
Think of it like an open-book exam. An LLM on its own is like a student trying to answer questions from memory. A RAG-powered LLM is like that same student having a curated set of textbooks and notes to consult before writing their answer. This process improves the accuracy and relevance of the LLM’s output, reduces the risk of generating incorrect or fabricated information (known as “hallucinations”), and allows it to answer questions about data it wasn’t trained on.
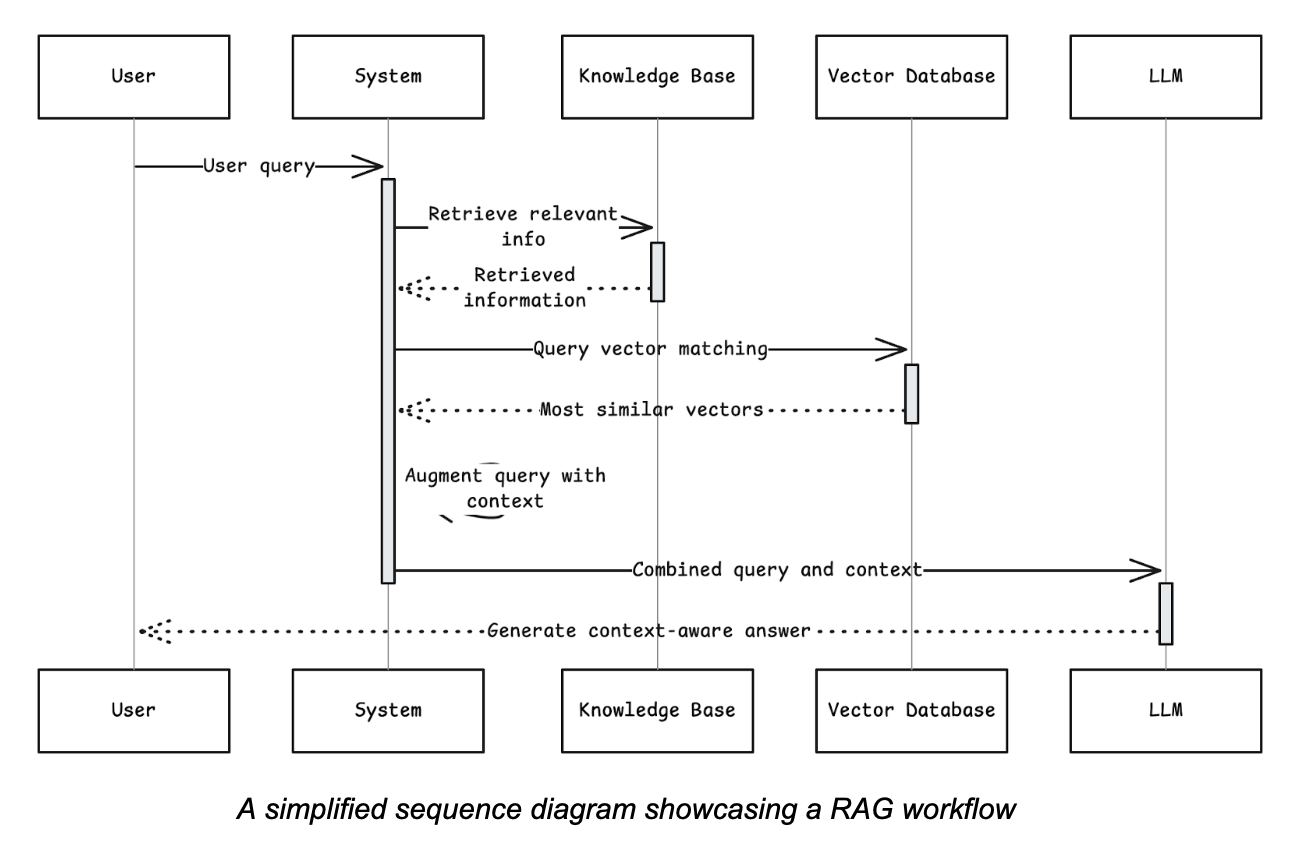
The RAG process generally follows these steps:
- User query: A user asks a question.
- Retrieval: The system searches an external knowledge base (e.g., a collection of documents, a database, or a website) for information relevant to the query.
- Augmentation: The retrieved information is added to the user’s original query as context.
- Generation: The combined prompt (original query plus retrieved context) is sent to the LLM, which then generates a comprehensive, context-aware answer.
What is graph RAG?
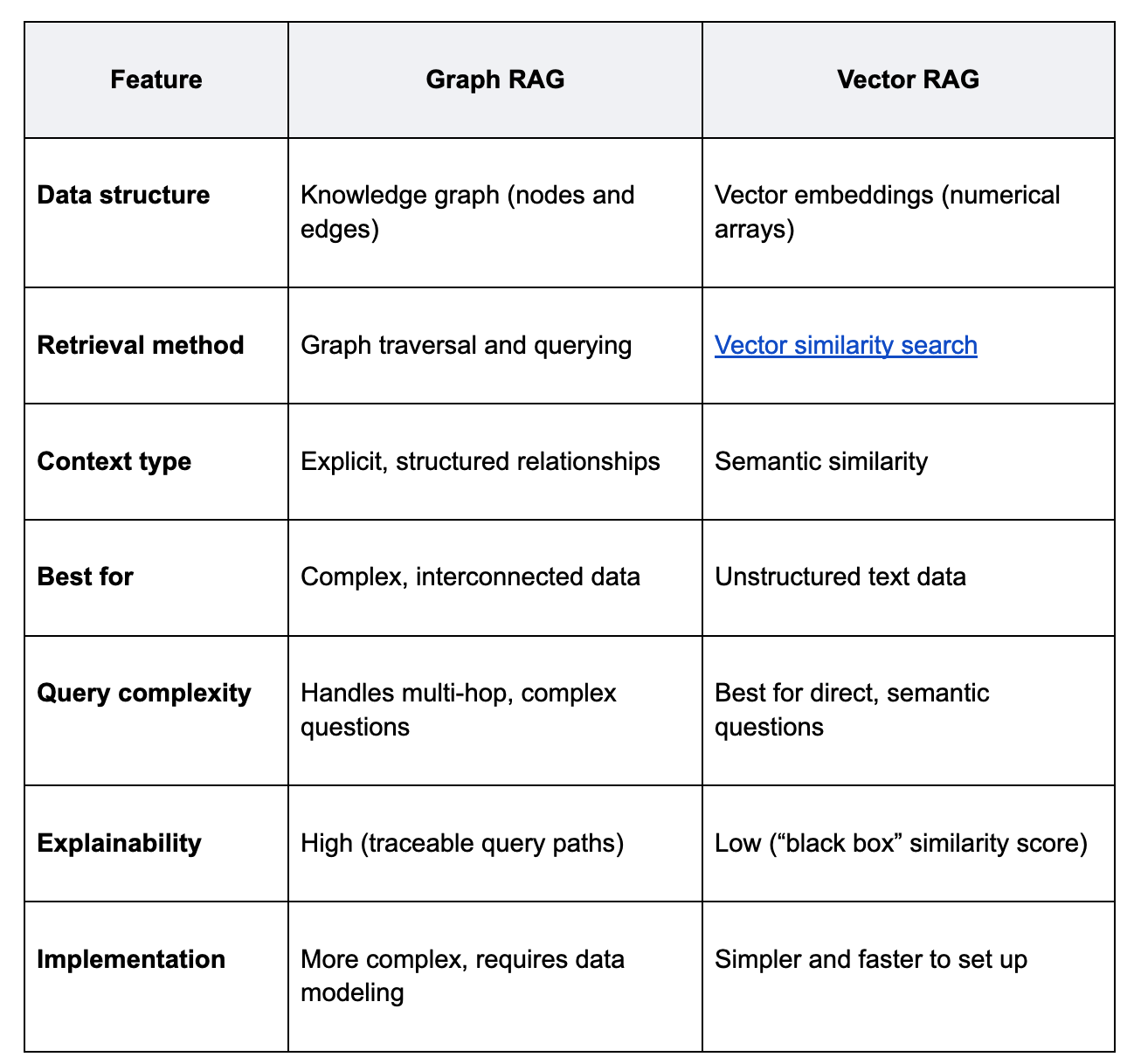
Graph RAG is a more sophisticated approach that uses a knowledge graph as its external data source. A knowledge graph organizes information as a network of entities (nodes) and their relationships (edges). For example, a node could be a person, a company, or a product, while an edge could represent a relationship like “works for,” “acquired,” or “is a component of.”
Instead of just searching for text chunks that are semantically similar to a query, graph RAG traverses the network of relationships to find highly contextual, interconnected information. It understands not just what things are but also how they relate to each other. This allows it to answer complex questions that require understanding relationships, patterns, and hierarchies within the data.
Benefits
- Explicit relationships: Graphs excel at representing explicit connections between data points, providing deep, structured context that vector searches might miss.
- Complex query handling: Graph RAG can answer multi-hop questions that require piecing together information from different parts of the knowledge base (e.g., “Which customers in Germany use a product made by a company that we acquired last year?”).
- Reduced hallucinations: By grounding the LLM in a structured, factual graph, the risk of generating inaccurate information is significantly lowered. The context is based on defined relationships, not just semantic similarity.
- Explainability: The path taken through the graph to find an answer can be traced, making the LLM’s reasoning process more transparent and explainable.
Challenges
- Complex data modeling: Building and maintaining a knowledge graph requires significant upfront effort in data modeling and extraction, transformation, and loading (ETL) processes.
- Scalability: While modern graph databases are highly scalable, managing massive, highly interconnected graphs can present performance challenges.
- Niche expertise: Implementing graph RAG requires expertise in graph databases, query languages such as Cypher and SPARQL, and graph data science.
Use cases
- Fraud detection: Identifying complex, hidden relationships between accounts, transactions, and individuals to uncover fraudulent rings.
- Supply chain management: Answering questions about supplier dependencies, logistical risks, and the impact of a disruption in one part of the chain on the entire network.
- Drug discovery: Exploring relationships between genes, proteins, and diseases to identify potential targets for new therapies.
- Advanced recommendation engines: Suggesting products or content based on intricate user behaviors and item relationships, not just on what’s popular.
What is vector RAG?
Vector RAG is currently the most common implementation of the RAG framework. It uses a vector database to store and retrieve information. In this approach, text data (e.g., documents, articles, web pages) is broken down into smaller chunks, and each chunk is converted into a numerical representation called a vector embedding using an embedding model.
When a user submits a query, the query itself is also converted into a vector. The system then performs a similarity search within the vector database to find the text chunks whose vectors are closest to the query vector. These semantically similar chunks are then passed to the LLM as context.
Benefits
- Simplicity and speed: Setting up a vector RAG pipeline is relatively straightforward. The process of embedding and searching is computationally efficient and fast, even with large datasets.
- Handles unstructured data: It works exceptionally well with large volumes of unstructured text, such as PDFs, articles, and support tickets, without needing a predefined schema.
- Broad applicability: Because it focuses on semantic meaning, it’s a versatile solution for a wide range of general-purpose Q&A and summarization tasks.
- Mature ecosystem: There is a robust, growing ecosystem of vector databases, embedding models, and frameworks (such as LangChain and LlamaIndex) that simplify development.
Challenges
- Lack of contextual relationships: Vector search can miss the nuanced relationships between pieces of information. It might retrieve facts that are semantically similar but not directly related, leading to less precise answers.
- “Lost in the middle” problem: When too many documents are retrieved, the LLM may struggle to identify the most critical information, especially if it’s buried in the middle of the provided context.
- Difficulty with granular data: For highly structured or tabular data, converting everything into text chunks can lead to precision loss and an inability to answer questions that depend on specific data points.
Use cases
- Customer support chatbots: Quickly finding answers to user questions from a knowledge base of help articles, FAQs, and product manuals.
- Document Q&A: Allowing users to “chat” with their documents, asking specific questions about a research paper, legal contract, or financial report.
- Content discovery: Recommending articles, videos, or products based on the semantic meaning of a user’s search.
- Enterprise search: Enhancing internal search engines to provide more relevant results from company-wide documents and resources.
Key differences between graph RAG vs. vector RAG
When to use graph RAG vs. vector RAG
Choosing between graph RAG and vector RAG depends entirely on your data and the types of questions you need to answer.
Use graph RAG when:
- Relationships are key: Your data is highly connected, and the value lies in understanding those connections (e.g., social networks, supply chains, financial systems).
- You need to answer complex, multi-hop questions: Users need to ask questions that require synthesizing information from multiple, related data points.
- Explainability is critical: You need to be able to show exactly how the system arrived at an answer, which is crucial in highly regulated industries like finance and healthcare.
Use vector RAG when:
- Your data is mostly unstructured text: You have a large corpus of documents, articles, or other text-based information.
- You need a solution quickly: You want to build a proof-of-concept or a production system without heavy investment in data modeling.
- The primary goal is semantic search and summarization: Your users need to find relevant passages in documents and get summarized answers.
The future of RAG systems
The debate isn’t about which RAG method will “win.” The future of RAG is hybrid. The most powerful AI systems will combine the strengths of both graph RAG and vector RAG.
Imagine a system that performs a vector search to quickly identify a relevant set of documents. Then, it uses a knowledge graph constructed from those documents to explore the specific relationships between entities mentioned. This multi-layered approach provides both the speed and scale of vector search and the depth and precision of graph traversal. This hybrid model allows an LLM to answer a broader range of questions with greater accuracy and context than either system could alone.
Key takeaways and additional resources
- RAG enhances LLMs by connecting them to external knowledge, improving accuracy, and reducing hallucinations.
- Vector RAG is ideal for searching large volumes of unstructured text based on semantic meaning. It’s fast, scalable, and relatively simple to implement.
- Graph RAG excels at navigating highly connected data to answer complex questions that depend on understanding relationships. It offers greater precision and explainability.
- The right choice depends on your data’s structure and your application’s requirements.
- Hybrid systems that combine both approaches represent the future of building sophisticated, context-aware AI applications.
To continue learning about retrieval-augmented generation, you can review the resources below:
- Vector Database vs. Graph Database: Differences & Similarities – Blog
- From Concept to Code: LLM + RAG with Couchbase – Blog
- Extending RAG Capabilities to Excel with Couchbase, LLamaIndex, and Amazon Bedrock – Blog
- A Step-by-Step Guide to Preparing Data for Retrieval-Augmented Generation (RAG) – Blog
- How I Built a Plant RAG Application with Couchbase Vector Search on iOS – Blog
FAQ
What are the main advantages of graph RAG over vector RAG? The main advantages are its ability to understand and utilize explicit relationships within data, answer complex multi-hop questions, and provide greater explainability for its answers by tracing the query path through the graph.
Can you combine graph RAG and vector RAG into a single system? Yes, and this is becoming a powerful pattern. A hybrid approach can use vector search for initial, broad retrieval, then use a knowledge graph to refine context and explore specific relationships, leveraging the strengths of both methods.
Is graph RAG or vector RAG better for large-scale enterprise data? It depends on the type of data. If the enterprise data is a massive collection of unstructured documents (reports, emails, etc.), vector RAG is a great starting point. If the data involves complex relationships (e.g., organizational charts, customer interaction histories, product dependencies), graph RAG will deliver more value and deeper insights.
How do graph databases differ from vector databases in RAG applications? Graph databases store data as nodes and edges, optimized for querying relationships. Vector databases store data as high-dimensional vectors and are optimized to find the nearest neighbors of a query vector using a distance metric. One stores explicit connections, while the other stores semantic similarity.
Does graph RAG require more computational resources than vector RAG? The upfront resource requirement for graph RAG can be higher, particularly in the data modeling and ingestion phase. However, for certain complex queries, traversing a well-structured graph can be more efficient than sifting through thousands of semantically similar but potentially irrelevant text chunks retrieved by a vector search. Query performance depends heavily on the specific use case and database optimization.
Deixe um comentário
Você precisa fazer o login para publicar um comentário.