Vemos que um número significativo de clientes aproveita a integração do Couchbase com Apache KafkaPara obter mais informações sobre o Couchbase Kafka, use o plug-in do conector do Couchbase Kafka, que oferece a capacidade de transmitir dados de forma confiável de e para o Apache Kafka em escala.
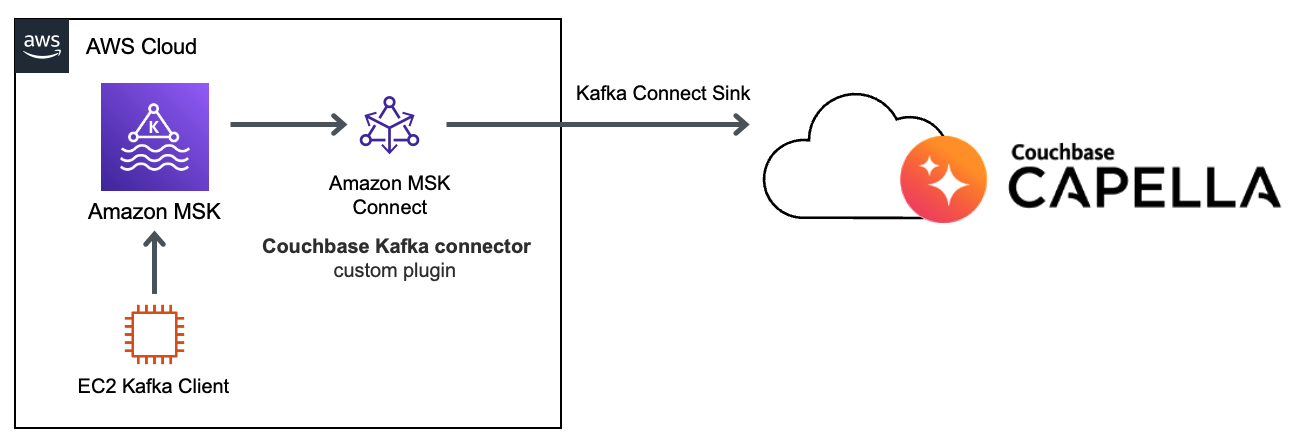
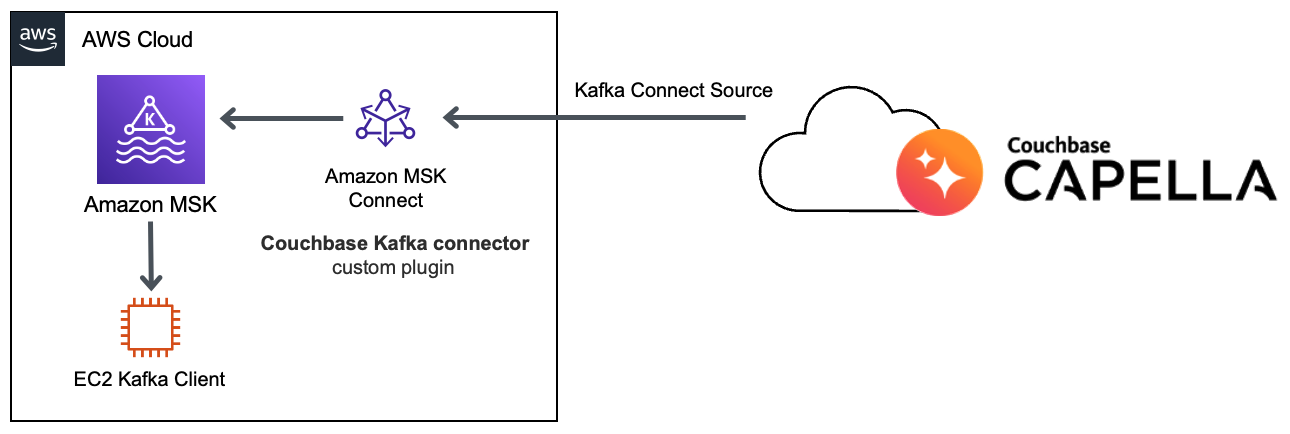
O Apache Kafka é uma plataforma de código aberto para a criação de pipelines e aplicativos de dados de streaming em tempo real. No entanto, é necessário ter experiência em gerenciamento de infraestrutura do Apache Kafka para arquitetar, operar e gerenciar por conta própria. O Amazon Managed Streaming for Apache Kafka (Amazon MSK) é um serviço totalmente gerenciado e altamente disponível que facilita a criação e a execução de aplicativos que usam o Apache Kafka.
O Amazon MSK oferece suporte à integração com o Couchbase com o recurso Amazon MSK Connect e o plug-in do conector Couchbase Kafka. Com esse recurso, você pode implantar facilmente o conector do Couchbase e dimensioná-lo para se ajustar às mudanças na carga.
Nesta postagem do blog, examinaremos a configuração do cluster do Amazon MSK e usaremos o Couchbase Kafka Connector como "pia" e "fonte". Usaremos o Couchbase Capella para começarmos em minutos.
Etapa 1: cluster do Couchbase Capella
-
- Comece a usar Avaliação gratuita do Couchbase Capella.
- Selecione a região do AWS de sua preferência e comece a usar o cluster do Couchbase Capella em minutos.
- Próximo, Configurar credenciais do banco de dados.
- Configure a rede privada usando Emparelhamento de VPC ou AWS PrivateLink para conectividade de rede com sua conta do AWS. Você pode permitir o acesso de qualquer lugar, mas isso não é recomendado.
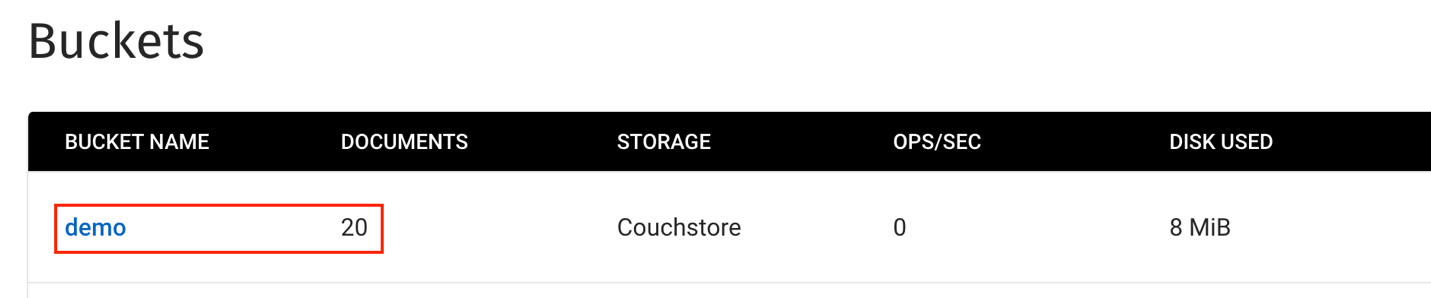
- Em seguida, acesse a seção Data Tools para criar um novo demonstração Bucket no cluster.
Etapa 2: cluster do Amazon MSK e cliente Apache Kafka
É recomendável que você tenha o cluster do Amazon MSK e os conectores do Amazon MSK Connect na sub-rede privada do seu VPC. Caso não esteja usando o VPC Peering ou o AWS PrivateLink para se conectar ao cluster do Couchbase Capella, você precisará do gateway NAT para iniciar a conexão a partir das sub-redes privadas.
Para começar facilmente, podemos usar Modelo CloudFormation para soluções de dados de streaming para MSK que implementa um cluster do Amazon MSK e o cliente Apache Kafka na instância do Amazon EC2.
![]()
Primeiro, vamos criar os tópicos de fonte e coletor de amostra no cluster MSK:

Em seguida, instalaremos alguns pacotes do Cliente Kafka para que possamos executar um código de amostra que publicará algumas mensagens na instância couchbase-sink-example tópico

Seguiremos o Guia de início rápido do conector do Couchbase Sink para publicar mensagens no cluster MSK.

Abra o arquivo src/main/java/com/couchbase/connect/kafka/example/JsonProducerExample.java e atualize a string de conexão do Kafka Cluster Bootstrap.
Agora você pode criar o projeto maven:
|
1 |
mvn compile exec:java |
O produtor de amostra enviará algumas mensagens para o tópico do kafka couchbase-sink-example e depois encerrar.
Etapa 3: Configurar o plug-in MSK Connect
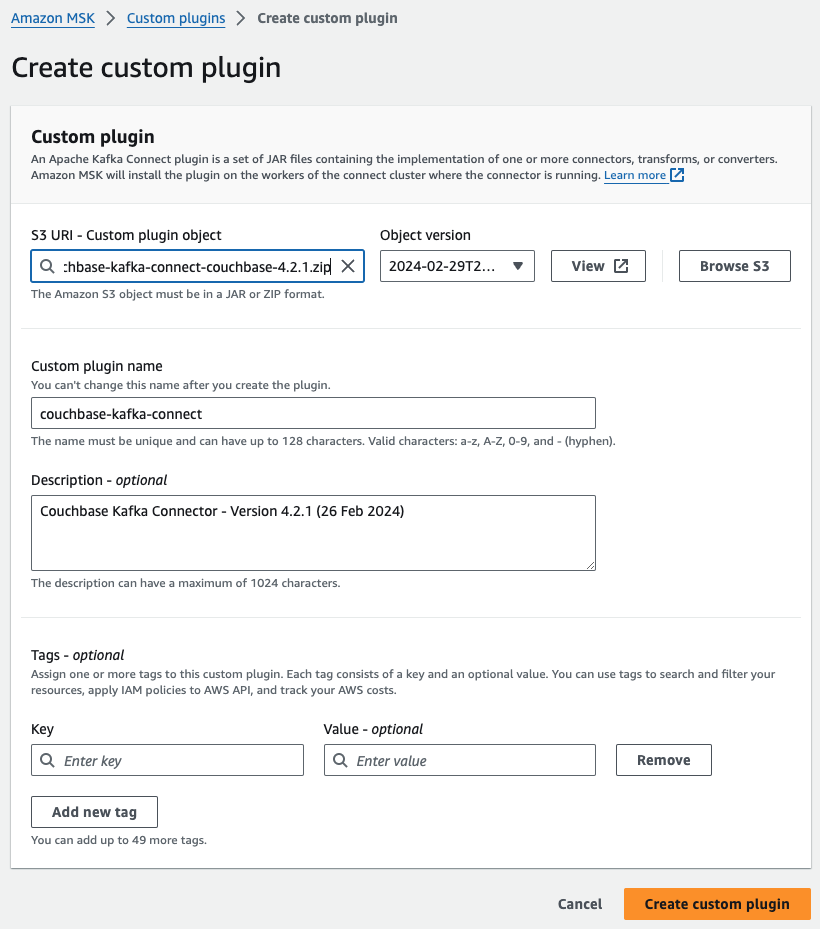
-
- Faça o download do Plug-in do Couchbase Kafka Connect ZIP.
- Carregue o arquivo ZIP em um bucket S3 ao qual você tenha acesso.
- Abra o Console MSK da Amazon. No painel esquerdo, expanda Conexão MSKe, em seguida, escolha Plug-ins personalizados.
- Escolha Criar um plug-in personalizado
- Escolha Procurar S3. Na lista de compartimentos, localize o compartimento em que você carregou o arquivo ZIP e, em seguida, na lista de objetos, selecione o arquivo ZIP.
- Entrar conexão couchbase-kafka como nome do plugin personalizado e, em seguida, selecione Criar plugin personalizado.
Etapa 4: Criar conector MSK para o coletor
-
- Usando o plug-in personalizado, agora podemos criar um conector de pia. Abra o Console MSK da Amazon. No painel esquerdo, em Conexão MSK, escolha Conectores. Escolha Criar conector.
- Escolha o plug-in personalizado conexão couchbase-kafka e selecione Next.
- Entrar couchbase-sink-example como Conector nome.
- Selecione o cluster MSK criado na Etapa 2.
- Insira a configuração do conector mostrada abaixo:

- Selecione Provisionado ou Escala automática capacidade com base em suas necessidades.
- Crie e selecione uma função de IAM com a função política de confiança exigida para conexão MSK.
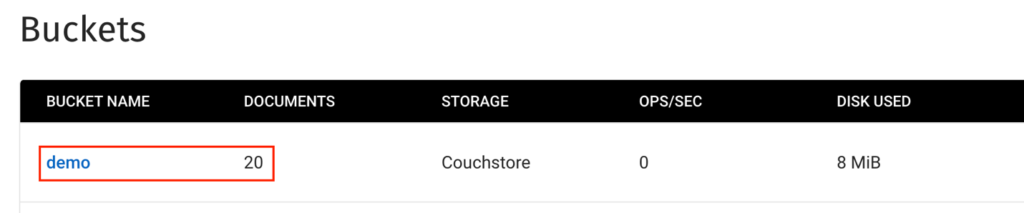
- Uma vez que o couchbase-sink-example você verá as mensagens do tópico do Kafka adicionadas ao bucket do Couchbase como novos documentos.

Etapa 5: Criar conector MSK para a origem
-
- Usando o plug-in personalizado, agora podemos criar um conector de origem. Abra o Console MSK da Amazon. No painel esquerdo, em Conexão MSK, escolha Conectores. Escolha Criar conector.
- Escolha o plug-in personalizado conexão couchbase-kafka e escolha A seguir.
- Entrar couchbase-source-example como Conector nome
- Selecione o cluster MSK criado na Etapa 2.
- Insira a configuração do conector mostrada abaixo:

- Selecione a capacidade Provisionada ou Autoscalonada com base em suas necessidades.
- Crie e selecione uma função de IAM com a função política de confiança exigida para conexão MSK.
- Uma vez que o couchbase-source-example será iniciado e estará ouvindo o protocolo de alteração de banco de dados (DCP) do Couchbase.
- Vamos iniciar um consumidor de console no Cliente Kafka para ouvir o tópico do Kafka couchbase-source-example onde as mensagens de atualização serão publicadas. Para isso, vou me conectar novamente à instância do KafkaClient usando a opção Session Manager e executar o seguinte código:

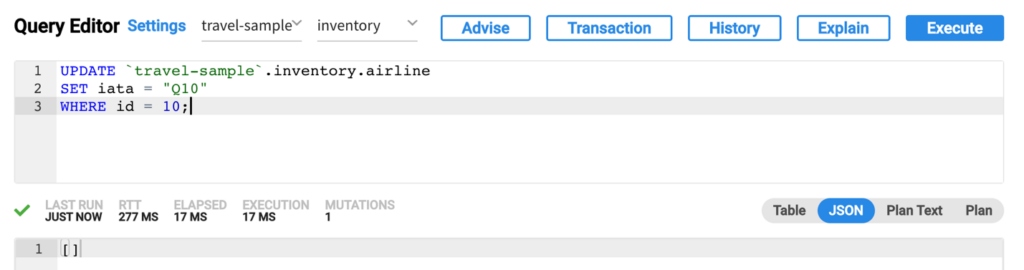
- Agora, quando executamos consultas UPDATE no amostra de viagem no Couchbase Capella usando a opção Data Tools - Query (Ferramentas de dados - Consulta):

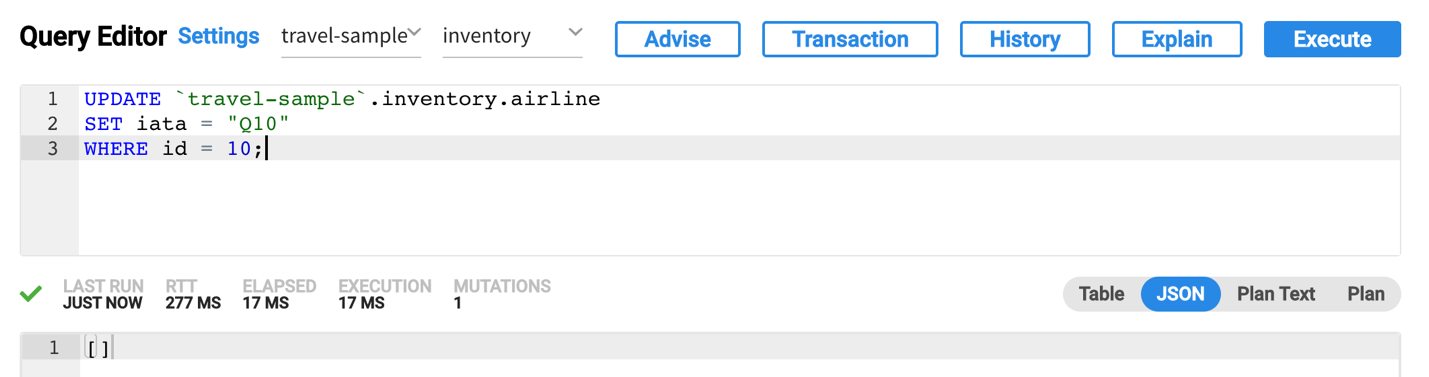
- Podemos ver que o documento atualizado é recebido pelo consumidor Kafka em execução na instância do cliente Kafka:





Conclusão
Esta postagem ilustra como você pode usar o Couchbase conector de fonte para publicar notificações de alteração de documentos do Couchbase Capella em um tópico do Kafka, bem como um conector do dissipador que se inscreve em um ou mais tópicos do Kafka e grava as mensagens no Couchbase Capella.

Segui o tutorial e não consegui fazê-lo funcionar.
Talvez alguma informação esteja faltando?