Com o Lançamento do Couchbase Server 5.5introduzimos compactação de ponta a ponta que permite que os dados permaneçam compactados: cliente para o cache, para o armazenamento em disco e para a replicação de dados entre os data centers. Como a maioria dos dados de nossos clientes está em texto JSON, que é facilmente compactável, acreditamos que isso levaria a uma conservação inestimável do armazenamento e da largura de banda.
Vou lhe dar uma visão geral rápida do fluxo de dados no Couchbase para preparar o terreno para um mergulho profundo na compactação de dados.
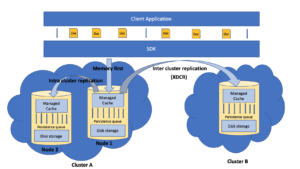
Figura 1. Fluxo de dados na plataforma de dados Couchbase
Os dados do aplicativo cliente primeiro fluem para o cache gerenciado por meio de SDKs, uma vez que o Couchbase oferece suporte e defende uma arquitetura que prioriza a memória. Esses dados no cache são então persistidos no disco por meio da fila de persistência. Todas as operações de valor-chave são executadas nos dados do cache, a menos que haja uma falha no cache, em que os dados são recuperados do disco e mantidos no cache para acesso futuro. Esses dados do cache também são replicados em outros nós de réplica por meio da fila de replicação intracluster para alta disponibilidade. Em seguida, é feita a replicação entre clusters (se aplicável), em que os dados da memória são replicados para outros clusters do Couchbase, em sua maioria distribuídos em centros de dados em diversas regiões geográficas, usando a tecnologia XDCR (Cross Datacenter Replication) do próprio Couchbase.
Todas as formas de replicação no Couchbase, seja a persistência local, a replicação intracluster ou a replicação intercluster, dependem de um único protocolo chamado DCP (Database Change Protocol), que se caracteriza pela recuperação sem perdas em caso de interrupção, streaming de RAM para RAM e processamento paralelo multithread.
A figura abaixo indica os vários estágios desse fluxo de dados, desde o aplicativo do cliente até o armazenamento, onde os dados são compactados na plataforma de dados couchbase.
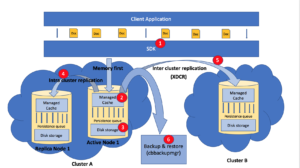
Figura 2. Compressão de dados na plataforma de dados Couchbase
- O SDK pode optar por receber os dados no modo compactado ou descompactado, dependendo da escolha do usuário do aplicativo. O SDK indica esse status por meio de sinalizadores para o cache gerenciado.
- O Cache gerenciado que também é um armazenamento de valores-chave, agora oferece suporte à compactação, podendo receber dados compactados e descompactados.Ele opera em três modos:
Desligado: Sem compressão
Passivo : (Padrão) Se o cache receber documentos compactados, ele será armazenado na forma compactada, mas não será feito nenhum esforço para compactar os documentos não compactados.
Ativo: Até mesmo documentos não compactados são compactados e armazenados.
- No DiscoOs dados são sempre armazenados no formato compactado.
- O Replicação entre data centers (XDCR) suporta a compactação. Mas o usuário precisa escolher se deseja ativar a compactação durante a replicação de seus dados entre os data centers.
- Cbbackupmgr é a tecnologia de backup e restauração nativa do Couchbase. Desde a versão 5.0, o cbbackupmgr oferece suporte à compactação, em que os dados podem ser armazenados compactados quando o backup é feito.
Todas as replicações são tratadas pelo protocolo de alteração de banco de dados e ele suporta a compactação de documentos. Mas os clientes do DCP, como XDCR, backup e restauração, etc., recebem dados compactados ou não compactados do DCP, dependendo das entradas fornecidas pelo cliente específico.
Acreditamos que a compactação é um valor agregado significativo para os clientes da plataforma de dados Couchbase, pois minimiza o custo de armazenamento, rede e memória, mesmo para as implantações existentes. Para as empresas que implantam o Couchbase em nuvens públicas, como AWS, Azure ou GCP, a conservação da largura de banda durante a replicação de grandes quantidades de dados (TBs) entre os data centers seria diretamente atribuída à economia de custos, pois os provedores de nuvem cobram com base na utilização da largura de banda.
Observe: Não existe uma regra geral que determine se os dados são sempre compactados ou descompactados no fluxo, pois a eficiência final está sujeita a vários fatores, como tipo de dados, largura de banda disponível, impacto na taxa de transferência, utilização da CPU etc. O sistema é projetado para optar pela rota com a máxima eficiência, dependendo de todos os fatores.
Compartilhe seus comentários e experiências aqui ou entre em contato conosco em nosso fórum. Veja Documentação relacionada à compactação do Couchbase aqui.
Obrigado, Chaitra, por essa postagem.
Existe uma maneira de medir a compactação obtida (no disco)? Digamos que um bucket seja preenchido com 100 milhões de documentos. Uma vez feito isso, veremos que há de 3 a 4 tipos diferentes. Portanto, não podemos multiplicar o número de documentos pelo tamanho de cada documento porque não sabemos o tamanho de cada documento. E mesmo que identifiquemos um documento (amostra) de cada tipo, não é necessário que todos os documentos desse tipo tenham o mesmo tamanho. E parece não haver uma maneira de encontrar o tamanho médio de todos os 100 milhões de documentos (ou existe uma maneira?)
Então, se observarmos o tamanho dos dados no disco, esse é o tamanho após a compactação.
Se soubéssemos o tamanho antes da compactação e se isso fosse comparado com o tamanho no disco (dados compactados), a taxa de compactação poderia ter sido determinada.
Agradecimentos