A realidade é que os bancos de dados estão convergindo e, nos últimos anos, está se tornando cada vez mais difícil apontar quais são os melhores cenários para cada armazenamento de dados sem uma compreensão profunda de como as coisas funcionam nos bastidores.
O Postgres tem sido meu RDBMS favorito há anos, e estou entusiasmado com a crescente popularidade de seu suporte a JSONB. Na minha opinião, isso ajudará os desenvolvedores a se familiarizarem mais com todas as vantagens de armazenar dados como JSON em vez de tabelas antigas.
No entanto, já vi muitas pessoas apresentarem inadvertidamente o Postgres 11 como "O novo NoSQL" ou que não precisam de nenhum Banco de dados NoSQL pois já estão usando o Postgres. Neste artigo, gostaria de abordar as principais diferenças e os casos de uso.
Se você não tiver tempo para ler o artigo inteiro, resumirei as descobertas mais importantes na conclusão.
Modelagem de dados: RDBMS e bancos de dados de documentos
Todos nós conhecemos o custo de uma operação JOIN em um RDBMS em escala: Se você tiver 1 milhão de usuários com 10 preferências cada, então, para trazer esse usuário de volta à memória, supondo que você esteja usando uma estrutura ORM (Mapeamento objeto-relacional), você precisará fazer uma junção com uma tabela de USER_PREFERENCES com 10 milhões de linhas.
Em um cenário do mundo real, os usuários geralmente também estão associados a muitas outras entidades, o que tornará esse cenário ainda pior e forçará os desenvolvedores a decidir quais relacionamentos devem ser preguiçosos ou ansiosos. Atualmente, todos os RDBMS já têm muitas otimizações para o cenário acima, mas modelar os dados da forma como temos feito nos últimos 30 anos definitivamente não é o ideal.
Um dos motivos pelos quais o RDBMS se tornou tão bom em lidar com transações é exatamente a limitação de seu modelo de dados: Faz sentido armazenar um pedido se não houver itens nele? Ainda assim, sou obrigado a criar uma transação para salvar essa "unidade única" espalhada entre pelo menos duas tabelas: ORDEM e ORDER_ITEM.
Vejamos um cenário ainda mais comum: como um usuário pode ser armazenado em um banco de dados de documentos em comparação com um RDBMS:
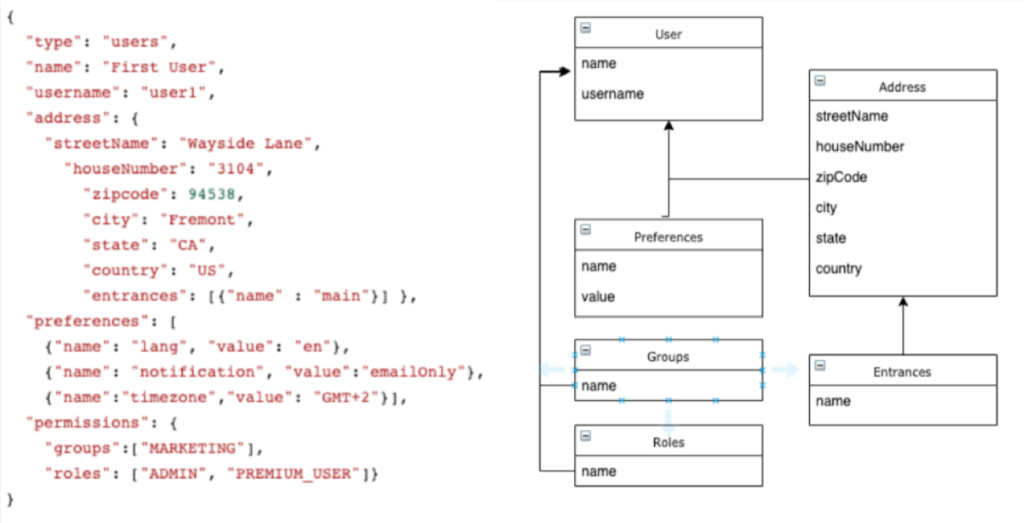
Em um banco de dados de documentos, as entidades com relacionamentos fortes geralmente são armazenadas em uma única estrutura. Nessa abordagem, quase não há custo adicional para carregar itens como preferências e permissões, enquanto em um modelo relacional isso exigiria pelo menos duas uniões.
Agora, vamos expandir esse exemplo para um caso de uso simples de comércio eletrônico:

No exemplo acima, um banco de dados de documentos não precisaria de nenhum JOIN para listar usuários e produtos. No entanto, para os pedidos, ele pode precisar de um ou dois, o que é totalmente aceitável. O mesmo modelo em um RDBMS exigiria pelo menos cerca de 12 tabelas:
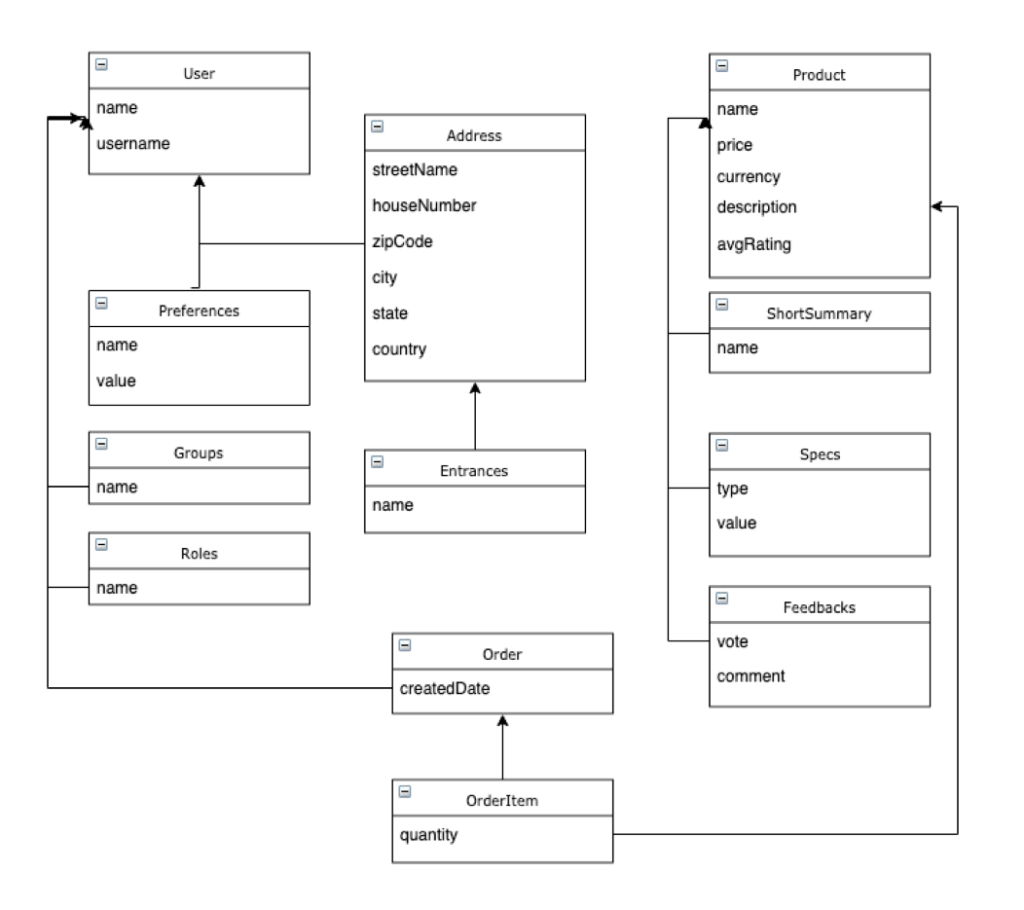
Usando nosso exemplo acima, você pode notar que os JOINs são essenciais para um RDBMS, enquanto no banco de dados de documentos eles são usados com menos frequência. O mesmo se aplica a transações ou operações em cascata, pois a maioria das entidades relacionadas é armazenada em um único documento.
Alguns dos bancos de dados NoSQL mais famosos do mercado ainda não oferecem suporte adequado a JOINs. Felizmente, esse não é o caso aqui. O Couchbase suporta até mesmo ANSI JOINs:
|
1 2 3 4 5 6 |
SELECT DISTINCT route.destinationairportFROM `travel-sample` airport JOIN `travel-sample` route ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "San Francisco" AND airport.country = "United States"; |
Sei que você já deve ter visto essa explicação sobre a modelagem de dados para RDBMS e a modelagem de dados para NoSQL, mas preciso enfatizar isso, pois cada banco de dados é otimizado para um modelo de dados específico, e isso terá um papel importante durante os testes de desempenho.
O mito do silo
Como o usuário e o nome do produto raramente serão alterados, você poderia simplesmente armazená-los na entidade Orders para evitar alguns JOINS. Bancos de dados NoSQLmas isso não é rigorosamente aplicado:

O armazenamento em cache de dados em outras entidades pode melhorar significativamente o desempenho da consulta em escala, mas há algumas compensações: Se você tiver que armazenar em cache esses dados em várias partes do sistema, sempre que esses dados forem alterados, será necessário executar algumas atualizações para "manter os dados sincronizados".
Já vi muitos desenvolvedores experientes usarem isso como uma desvantagem dos bancos de dados de documentos, e sempre tenho que lembrá-los de que você poderia ter exatamente o mesmo problema em um RDBMS.
Tipo de coluna JSONB do Postgres
No Postgres, JSONB é um tipo especial de coluna que pode armazenar JSON em um formato otimizado para leituras:
|
1 |
CREATE TABLE my_table ( id integer NOT NULL, data jsonb); |
Conforme declarado neste vídeoEmbora haja algumas penalidades de desempenho ao armazenar dados em uma coluna JSONB, o banco de dados precisa analisar o JSON para armazená-lo em um formato otimizado para leituras, o que parece ser uma compensação justa.
OBSERVAÇÃO: Vamos ignorar a coluna JSON do Postgres por enquanto, pois até mesmo o documento do Postgres afirma que você deve, em geral, escolher JSONB em vez do tipo de coluna JSON.
Em teoria, você pode até emular um banco de dados de documentos no Postgres usando uma coluna JSONB para todas as entidades aninhadas:
|
1 2 3 4 5 6 7 |
CREATE TABLE users ( id integer NOT NULL, name varchar, username varchar, address jsonb, preferences jsonb, permissions jsonb ); |
Manipulação de dados
É aqui que as coisas começam a ficar realmente interessantes: Em primeiro lugar, o Postgres não está seguindo exatamente o padrão Padrões SQL:2016 (ISO/IEC 9075:2016). Isso não é necessariamente uma coisa ruim, pois as consultas nessa especificação podem facilmente ficar muito grandes, mas ainda assim é algo a se ter em mente.
Eu sempre gosto de destacar os padrões porque os bancos de dados NoSQL já passaram por esse caminho antes, e hoje temos dezenas de linguagens diferentes e um investimento significativo em refatoração se você quiser migrar de um NoSQL para outro.
Espero que sim, SQL++ veio em seu socorro, o pai do próprio SQL, Don Chamberlin, escreveu um livro sobre isso no ano passado. Nesta sessão, compararei as funções e os operadores JSON do Postgress com uma implementação do SQL++ chamada N1QL, que é a linguagem de consulta que usamos no Couchbase.
Inserções
As inserções são o que você espera, a principal diferença entre a sintaxe do Postgres e a do N1QL é que, no primeiro, apenas algumas colunas de uma linha conterão strings codificadas em JSON, enquanto no segundo, todo o documento é um JSON:
Postgres:
|
1 2 3 4 |
INSERT INTO users VALUES (1, 'First User', 'user1', '{"streetName": "Wayside Lane", "houseNumber": 3104, "zipcode": "94538", "city": "Fremont", "state": "CA", "country": "US", "entrances": [{"name" : "main"}] }', '[{"name": "lang", "value": "en"},{"name": "notification", "value":"emailOnly"}, {{"name":"timezone","value": "GMT+2"}]', '{"groups":["MARKETING"], "roles": ["ADMIN", "PREMIUM_USER"]}'); |
Couchbase:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
INSERT INTO `test` ( KEY, VALUE ) VALUES ( "1", { "type": "users", "name": "First User", "username": "user1", "address": { "streetName": "Wayside Lane", "houseNumber": 3104, "zipcode": 94538, "city": "Fremont", "state": "CA", "country": "US", "entrances": [{"name" : "main"}] }, "preferences": [ {"name": "lang", "value": "en"}, {"name": "notification", "value":"emailOnly"}, {"name":"timezone","value": "GMT+2"}], "permissions": { "groups":["MARKETING"], "roles": ["ADMIN", "PREMIUM_USER"]} }); |
Atualizações
Vamos começar com uma atualização muito simples
Postgres:
|
1 |
update users set address = jsonb_set(address, '{state}', '"California"') WHERE address->'state' = '"CA"'; |
Na sintaxe do Postgres, as cadeias de caracteres devem ser especificadas entre aspas duplas e simples ('"CA"'), enquanto os literais devem estar entre aspas simples ("false" ou "123").
Couchbase:
|
1 |
update `test` set address.state = 'California' where address.state = 'CA' and type = 'users' |
No Couchbase, não há um conceito semelhante a uma tabela, portanto, diferenciamos os documentos de acordo com um "tipo", que, nesse caso, deve ser igual a "usuários". Todo o restante da consulta é semelhante ao SQL padrão ou, se você veio do mundo Java, é quase a mesma sintaxe do JPA JPQL.
Vamos tentar um exemplo mais complexo em que adicionamos uma nova entrada à casa, atualizamos o código postal e removemos a função ADMIN do usuário de destino:
Postgres:
|
1 2 3 4 5 6 7 |
UPDATE users SET address = jsonb_set( jsonb_set( address::jsonb, array['entrances'], (address->'entrances')::jsonb || '{"name": "backyard"}'::jsonb), '{zipcode}', '94537'), permissions = jsonb_set(permissions, '{roles}', (permissions->'roles') - 'ADMIN') |
As consultas do Postgres podem facilmente se tornar muito complexas se você precisar manipular o JSON. Em alguns casos, você pode até mesmo precisam criar funções apenas para executar algumas atualizações básicas. Para mim, isso é um sinal de que ainda precisamos de alguns aprimoramentos na linguagem de consulta.
Couchbase:
|
1 2 3 |
update `test` set address.zipcode = 94537, address.entrances = ARRAY_APPEND(address.entrances, {"name": "backyard"}), permissions.roles = ARRAY_REMOVE(permissions.roles, "ADMIN") |
Mesmo que não esteja familiarizado com o N1QL, você pode entender claramente o que está acontecendo na consulta acima, pois o N1QL tem dezenas de funções apenas para lidar com matrizes.
SELECTs
Como a seleção de dados é um tópico extenso, vamos dividi-lo em sessões menores:
Consulta de dados simples
Postgres:
|
1 2 |
select address->'city' from users where address @> '{"zipcode": "94537"}' select * from users where address @> '{"entrances":[{"name": "backyard"}]}' |
O mágico @> permite que você combine facilmente um par chave-valor ou um objeto dentro do seu JSON. De fato, ele facilita a correspondência de coisas no JSON, embora haja algumas coisas que você deve ter em mente:
- A operadora @> suporta apenas comparações de igualdade
- Na segunda consulta, combinamos quintal na matriz de entradas, mas a matriz real é, na verdade, a seguinte:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ ... "entrances": [ { "name": "main" }, { "name": "backyard" } ], ... } |
Portanto, quando pesquisamos um atributo (CEP, neste primeiro caso), o @> se comportou como iguaismas se usarmos o mesmo operador para pesquisar em uma matriz, ele se comportará como "contém".
Couchbase:
|
1 2 3 |
Select address.city from `test` where address.zipcode = ‘94537’; select * from `test` where ANY entrance IN address.entrances SATISFIES entrance.name = "main" END; select * from `test` as t where "main" within t; //search for the occurence of “main” inside the JSON |
Não há uma correlação direta entre o @> e uma palavra-chave no N1QL. Nas consultas acima, usamos estratégias diferentes para realizar as mesmas coisas. A sintaxe do Postgres é mais curta para consultas muito simples, mas se você filtrar por dois ou três atributos, as consultas em N1QL terão aproximadamente o mesmo tamanho. Nesse caso, você também pode usar qualquer tipo de operador de comparação.
Um aspecto que considero positivo é que as consultas que usam a sintaxe do SQL++ "se parecem mais com o SQL" do que o SQL no próprio Postgres.
Navegando pelos objetos
Postgres:
|
1 |
select * from users where (address->>'houseNumber')::int > 5 |
O Postgres usa o ->> para navegar pelas entidades e o operador -> para converter um atributo em texto. Mas se o atributo for um número inteiro, será necessário converter o id de volta para int.
Couchbase:
|
1 |
Select * from `test` where address.houseNumber > 5 |
No caso acima, você pode simplesmente navegar pelas entidades usando o "." e o tipo adequado é inferido automaticamente.
Tratamento de atributos ausentes/existentes
Postgres:
|
1 |
select * from users where (preferences->'randomAttributeName’') is null |
O Postgres considera os valores ausentes como NULL, o que é semanticamente errado:
- JSON com nulo "randomAttributeName'' :
|
1 2 3 4 5 6 7 8 9 |
[ { "name": "lang", "value": "en", "timezone": "GMT+2", "notification": "emailOnly", “randomAttributeName’': null } ] |
- JSON com "randomAttributeName'' :
|
1 2 3 4 5 6 7 8 |
[ { "name": "lang", "value": "en", "timezone": "GMT+2", "notification": "emailOnly" } ] |
Pode não ser muito importante para você neste momento, mas essa diferenciação ajuda a solucionar possíveis problemas no seu esquema ou quando você precisa atualizar as estruturas do próprio JSON.
O ? pode verificar se um atributo existe, mas só pode ser usado com chaves de nível superior de acordo com o operador documentos.
Couchbase:
No N1QL, já existe uma sintaxe adequada para esse cenário:
|
1 |
Select * from `test` where randomAttributeName is missing |
Além disso, há também um açúcar de sintaxe para verificar se o atributo existe (o mesmo que "is not missing"):
|
1 |
Select * from `test` where randomAttributeName exists |
Índices
Os bancos de dados que permitem o armazenamento de dados como JSON geralmente não impõem nenhum tipo de esquema, mas há um problema inerente quando você adiciona suporte flexível a esquemas: Por padrão, você não sabe antecipadamente quais documentos têm os atributos que você está consultando.
Esse problema pode ser resolvido rapidamente com a criação de índices adequados, pois você pode reduzir significativamente o número de documentos digitalizados e classificá-los de alguma forma para facilitar a localização do valor de destino. No entanto, como estamos lidando com JSON, os índices também precisam lidar com entidades e matrizes aninhadas, o que acrescenta um nível extra significativo de complexidade.
Naturalmente, a criação do índice correto para uma consulta também é uma tarefa que exige alguma reflexão. De fato, ~15% das perguntas nos fóruns do Couchbase são exatamente sobre isso. O Couchbase 6.5 virá até mesmo com um Indexer Recommender que sugerirá um índice de acordo com uma determinada consulta:
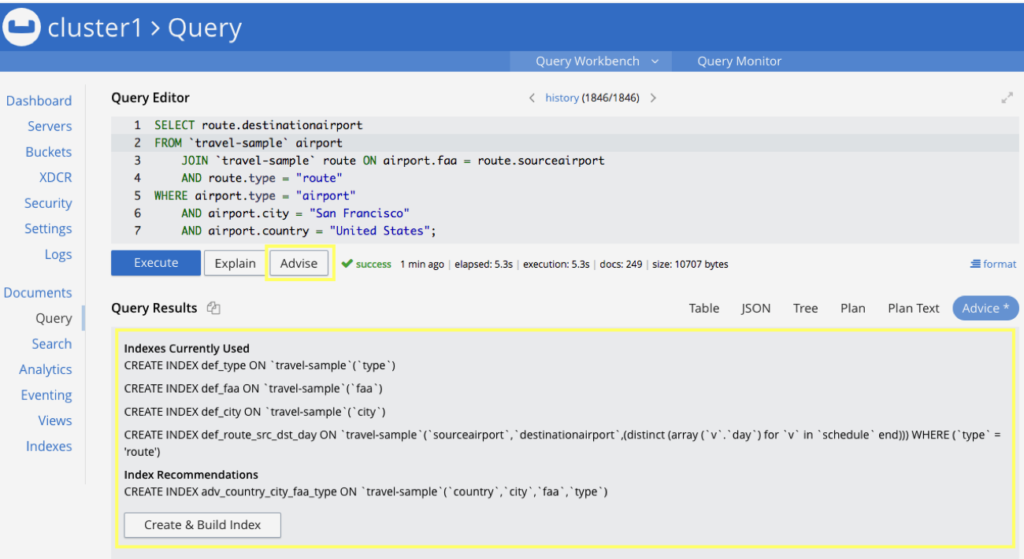
Postgres:
Os índices para dados JSONB são um dos mais novos recursos do Postgres, e os desenvolvedores estão realmente empolgados com isso, pois o desempenho das consultas aumentará significativamente em comparação com as versões anteriores. De acordo com a documentação principal, o Postgres oferece suporte a dois tipos de índices: o padrão e o jsonb_path_ops:
Padrão
|
1 |
CREATE INDEX idxusersall ON users USING GIN (address); |
Esse índice permite que você use consultas com os operadores de nível superior key-exists ?, ?& e ?| e o operador path/value-exists @> . Além disso, você também pode indexar um campo específico:
|
1 |
CREATE INDEX idxusers ON users USING GIN ((address -> 'entrances')); |
Para o GIN Index, você só pode especificar um único campo.
jsonb_path_ops
|
1 |
CREATE INDEX idxginp ON api USING GIN (jdoc jsonb_path_ops); |
A classe do operador GIN não padrão jsonb_path_ops suporta a indexação somente do operador @>. Normalmente, isso resultará em um índice menor e mais rápido. Você pode Leia mais sobre isso aqui.
Atualização do artigo:
Mark (que comentou aqui neste artigo) e @postgresmen no Twitter destacaram que você pode criar índices com vários campos usando BTrees ou GIST:
|
1 2 3 |
// for a JSONB collumn called "data" with the following content: // {"a": %s, "b":2, "c":1, "d":3} create index t1_l2 on users using btree((address->>'a'), (address->>'b'), (address->>'c')); |
Em seguida, você pode usar o índice acima com a seguinte consulta:
|
1 |
select from t1 where address->>'a' = 1::text |
Você também pode usar índices parciais com a sintaxe acima:
|
1 2 |
create index t1_l3 on users using btree((address->>'a'), (address->>'b'), (address->>'c')) where address->'state' = '"CA"'; |
O A documentação oficial tem apenas 2 páginas sobre como indexar campos JSONB, só depois que Mark/@postgresmen me informou, pude descobrir como criar determinados tipos de índices. Indexação JSONB deve receber atualizações interessantes nas próximas versões do Postgres.
Couchbase:
Os índices são, na verdade, o núcleo do Couchbase. Atualmente, oferecemos suporte a 7 tipos diferentes:
- Primário - Indexa todo o compartimento na chave do documento
- Secundário - Indexa um escalar, objeto ou matriz usando um valor-chave
- Composto/Coberto - Vários campos armazenados em um índice
- Funcional - Índice secundário que permite expressões funcionais em vez de um simples valor-chave
- Matriz - Um índice de elementos de matriz que varia de valores escalares simples a matrizes complexas ou objetos JSON aninhados mais profundamente na matriz.
- Adaptativo - Índice de matriz secundária para todos ou alguns campos de um documento sem a necessidade de defini-los antecipadamente.
- Índice parcial - Permite que você indexe apenas um subconjunto de seus dados
Como você pode ver, os índices são algo bastante maduro no Couchbase e muito mais flexíveis do que os suportados pelo Postgres JSONB. Não vou me aprofundar no assunto, pois este artigo já está bem longo. Gostaria apenas de destacar duas coisas que, pessoalmente, acho muito legais: Índices parciais cobertos e Aggregate Pushdowns
Índices parciais cobertos
Com uma combinação de Covered e Partial, você pode criar índices apenas para o subconjunto de dados que lhe interessa.
EX: Digamos que você tenha um jogo on-line e precise mostrar uma tabela de classificação por país, além de ignorar usuários inativos ou com menos de 10 pontos. O desempenho de sua tabela de classificação é bom para todos os países, exceto para a China, que tem 10 vezes mais jogadores. Nesse caso, você poderia criar um índice específico para melhorar a velocidade de sua consulta:
|
1 2 3 4 5 6 |
CREATE INDEX `china_leader_board` ON `user_profiles`( username, points DESC) WHERE active = true and countryCode = "CN" and points > 10 |
Observe que já estamos mantendo os pontos ordenados, portanto, uma consulta como a seguinte deve ser extremamente rápida:
|
1 |
Select username, points from user_profiles where active = true and countryCode = "CN" order by points DESC limit 20 |
Flexões agregadas
A agregação é sempre uma tarefa difícil para armazenamentos sem colunas. No Couchbase, permitimos que você crie índices para tornar a agregação mais rápida. Vejamos o exemplo a seguir:
|
1 2 3 4 5 |
SELECT country, state, city, COUNT(1) AS total FROM `travel-sample` WHERE type = 'hotel' and country is not null GROUP BY country, state, city ORDER BY COUNT(1) DESC; |
Essa consulta levou cerca de 90 ms para ser executada. Aqui está o plano de consulta:

Agora, vamos criar o seguinte índice:
|
1 |
CREATE INDEX ix_hotelregions ON `travel-sample` (country, state, city) WHERE type='hotel'; |
Se executarmos a mesma consulta novamente, ela deverá ser executada em aproximadamente 7 ms. Observe que no novo plano de consulta não há nenhuma etapa de "grupo":

Você pode Leia mais sobre os índices do Couchbase aqui
Observação: travel-sample é um dos bancos de dados de demonstração que você pode carregar ao instalar o Couchbase
Desempenho
Embora ambos os bancos de dados sejam considerados CP (Consistent/Partition Tolerant), o Postgres é um RDBMS mestre/escravo tradicional, enquanto o Couchbase é otimizado para leituras/escritas rápidas em escala e suporte adicional para Visões atômicas monotônicas
Infelizmente, há apenas alguns benchmarks de JSONB publicados on-line e, nos mais recentes, o Postgres foi relatado como sendo mais rápido que o Mongo em uma instância de nó único (aqui também). Os resultados são impressionantes, mas vale a pena destacar que a maioria dessas comparações foi feita com apenas um ou dois nós, o que é um cenário que favorece o RDBMS em geral.
Não quero enfatizar a arquitetura do Couchbase aqui, mas como um banco de dados que prioriza a memória, seu aplicativo recebe a confirmação de uma gravação bem-sucedida assim que o banco de dados recebe a solicitação e, em seguida, seu documento é replicado de forma assíncrona e gravado no disco (sim, você também pode alterar quando deseja receber a confirmação).
Se acrescentarmos a isso o fato de que o Couchbase tem uma arquitetura sem mestre (seu aplicativo envia as gravações/leituras diretamente para o servidor certo), um suporte de indexação muito melhor e a alta escalabilidade (há clientes executando clusters de CB único em produção com mais de 100 nós), fica claro para mim qual deles terá melhor desempenho em escala, a questão é apenas "quanto".
Ainda não há um benchmark entre Postgres e Couchbase. Se você quiser ver um, envie um tweet para @deniswsrosa. Enquanto isso, você pode comparar indiretamente o desempenho de ambos usando o seguinte Referência em Couchbase/Mongo/Cassandra
Conclusão
Estou realmente empolgado com o aumento do suporte a JSON no Postgres, pois isso certamente fará com que os desenvolvedores se familiarizem mais com os benefícios do armazenamento de dados como JSON e, consequentemente, tornará os bancos de dados de documentos também mais populares.
Muitas ferramentas e estruturas no mercado já oferecem suporte a dados JSON e, à medida que a adoção do Postgres JSONB aumenta, ele deve se tornar um recurso padrão, o que é novamente uma coisa boa para todos os usuários. Banco de dados NoSQL.
No entanto, há algumas coisas que devem ser levadas em conta antes de entrar no JSONB do Postgres:
- Linguagem de consulta complexa: A linguagem de consulta atual para JSONB não é intuitiva; mesmo depois de ler os documentos, ainda é um pouco complexo entender o que está acontecendo na consulta. O PG 12 pode resolver alguns desses problemas com o Linguagem de caminho JSONmas ainda parecerá uma mistura de alguma outra linguagem com SQL. Eu preferiria ver o Postgres adicionando suporte ao SQL++.
- Linguagem de consulta limitada: Além de ser complexa, a linguagem de consulta ainda não está pronta. Faltam funções para manipular os dados JSON; por exemplo, você precisa usar algumas soluções alternativas apenas para fazer algumas manipulações básicas de matriz. Se você tiver um JSON muito dinâmico e precisar consultá-lo de várias maneiras, as coisas podem se tornar realmente desafiadoras. Parece que o foco principal até agora foi construir a ponte entre o JSON e os dados relacionais.
- Indexação: Com o novo tipo de índice, as consultas serão executadas muito mais rapidamente do que antes. Além disso, você pode usar o BTree e o Gist para cobrir casos não compatíveis com o GIN.
- Documentação superficial: Há apenas cerca de 6 páginas de documentação falando sobre JSONB. A maioria das coisas que aprendi ao escrever este artigo foi baseada em tentativa e erro, perguntas do StackOverflow, publicações em blogs e apresentações no YouTube.
- Ferramentas: Não mencionei isso durante o artigo, mas como se trata de um recurso bastante novo, é natural que algumas estruturas/SDKs ainda não tenham adicionado suporte total a ele. Vamos pegar o SpringData como exemplo, existem alguns esforços comunitários mas não é uma experiência totalmente tranquila. Você pode esperar alguns contratempos ao longo do caminho.
Alguns dos problemas acima são conhecidos, e algumas palestras/artigos com links neste artigo até os mencionam. Os mais críticos já estão no roadmap para as próximas versões do Postgres.
Ao contrário da maioria das apresentações populares a que assisti, não acho que ele ainda seja adequado para modelos muito dinâmicos, principalmente porque a consulta e a manipulação de dados não são tão fáceis quanto poderiam ser.
Onde o Postgres JSONB é uma boa opção?
Embora eu tenha apontado alguns problemas do meu ponto de vista, acho que esse é um recurso valioso e você deve definitivamente considerar usá-lo. Aqui estão alguns cenários em que acho que ele se encaixa bem:
- CQRS/Sourcing de eventos sistemas que precisam ser altamente transacionais
- Metadados
- Evitar uniões desnecessárias, armazenando algumas entidades relacionadas como JSONBs
- Sempre que você precisar armazenar cadeias de caracteres codificadas em JSON, mas não precisar manipular ou consultar os dados com muita frequência.
Nos casos acima, o Postgres deve funcionar bem, mesmo em grandes implementações. Os índices podem ficar um pouco grandes com o GIN, mas ainda são gerenciáveis.
Onde o Couchbase é uma boa opção?
Tenho trabalhado com sucesso com bancos de dados de documentos há mais de quatro anos e, a essa altura, posso ser um pouco tendencioso, mas acho que os cenários em que ele pode ser usado como substituto de um RDBMS são muito maiores do que você imagina. Alguns dos casos de uso mais famosos são:
- Armazenamento de perfis de usuários;
- Catálogos de produtos/Carrinhos de compras;
- Histórico médico (para o HealthCare);
- Contratos, apólices de seguro;
- Mídia social;
- Jogos;
- Armazenamento em cache;
- ...
De fato, a maioria dos sistemas que não requerem transações fortemente serializáveis entre vários documentos deve ser uma boa opção, o que não significa que as transações não sejam suportadas, é apenas uma versão mais relaxada que não comprometerá a escalabilidade do banco de dados, especialmente com o Couchbase 6.5!
O Couchbase CE e EE realmente brilham quando você precisa de desempenho em escala. Você pode criar facilmente clusters com 3, 5, 10, 50, 100 nós e ainda assim manter um bom desempenho e uma consistência forte, e é por isso que ele é atualmente uma das principais opções para aplicativos de missão crítica. Se você tiver tempo, confira alguns dos casos de uso público.
Todos esses casos de uso críticos ao longo dos anos tornaram o N1QL e a indexação muito sólidos, rápidos e flexíveis. É por isso que considero uma comparação injusta, dado o estado atual do Postgres JSONB, embora seja válida para mostrar aos desenvolvedores as lacunas entre uma implementação inicial e o melhor suporte a JSON até o momento.
Se você tiver alguma dúvida, comentário ou discordar completamente de mim, sinta-se à vontade para me enviar um tweet para @deniswsrosa
Você pode usar índices funcionais btree normais em alguma função que extraia dados de uma coluna JSONB.
Isso é muito útil, por exemplo, se você tiver um valor dentro de um objeto json que deseja indexar para operações de correspondência exata ou outras coisas que funcionem com o btree.
Também é possível usar um índice parcial simultaneamente.
Obrigado pela dica, Mark! Atualizarei a postagem do artigo.
Olá, Mark, atualizei o conteúdo com suas recomendações. Muito obrigado pelo aviso.
boa explicação. Agradecimentos
Estou tentando copiar o arquivo .json (gerado usando o cbexport), mas estou recebendo erros. Existe algum link que tenha uma boa explicação sobre como copiar o bucket do couchbase para a tabela JSON do postgres?
[...] Outras consultas [...]