No ambiente acelerado de hoje, a capacidade de acessar, entender e agir rapidamente com base nos dados não é mais um luxo, é uma necessidade. No entanto, muitas organizações descobrem que, embora sejam ricas em dados, a obtenção de insights oportunos e acionáveis continua sendo um desafio significativo, principalmente para usuários corporativos não técnicos.
Além disso, os usuários técnicos precisam entender seus dados para saber quais consultas construir para obter os resultados, o que exige tempo e esforço significativos e não está a um clique de distância, permitindo que o usuário pergunte o que tem em mente em linguagem natural simples.
Além disso, o usuário ainda precisa dedicar tempo para entender os dados, mesmo com as visualizações implementadas. Muitas vezes, há uma questão de "por que" quando os dados estão sendo apresentados, e os dados sem o "por que" crucial deixam uma lacuna entre a apresentação dos dados e a verdadeira compreensão. Essencialmente, a análise de negócios de autoatendimento continua sendo ilusória.
O que é Polaris?
Polaris é uma interface de conversação baseada em IA de vários agentes criada para analisar dados em nosso banco de dados operacional Couchbase. O Polaris utiliza uma arquitetura multiagente que permite que os usuários interajam com seus dados corporativos por meio de uma interface de conversação intuitiva, transformando a análise de dados complexos em um diálogo simples. Por exemplo, se uma empresa tiver dados de vendas corporativas globais em várias regiões e linhas de produtos, e um analista de negócios quiser entender "Por que as vendas do segundo trimestre diminuíram na região nordeste para o Produto X?"Se o nosso aplicativo for um aplicativo de análise, ele poderá executar de forma autônoma todo o fluxo de trabalho de análise.
Ele recupera e filtra os dados de vendas relevantes por região, produto e período de tempo, compara as tendências de desempenho em regiões ou produtos comparáveis, visualiza os principais padrões e anomalias e gera um relatório narrativo que resume as causas principais, como redução de gastos promocionais, problemas de disponibilidade de estoque ou uma mudança no comportamento do cliente. Para torná-lo ainda mais interessante, o analista de negócios pode fazer uma pergunta de acompanhamento para entender, em detalhes, alguma parte do relatório ou talvez solicitar mais visualizações etc., permitindo assim uma rápida tomada de decisão orientada por dados.
Agora, vamos abordar o elefante na sala: os agentes de IA.
O que são agentes de IA e quais são seus recursos?
Os agentes de IA são sistemas autônomos alimentados por inteligência artificial, geralmente envolvendo Módulos de Linguagem Grandes (LLMs) que podem executar tarefas, tomar decisões e interagir com ambientes do mundo real, muitas vezes sem supervisão humana constante. Diferentemente dos chatbots tradicionais ou dos programas baseados em regras, os agentes de IA também aprendem com sua experiência. O objetivo de um agente é que ele faça tudo o que um operador humano faz de forma autônoma e automática. Ainda é uma meta rebuscada, mas o setor de IA está progredindo em direção a ela. Agora, vamos dar uma olhada nos recursos dos agentes de IA:
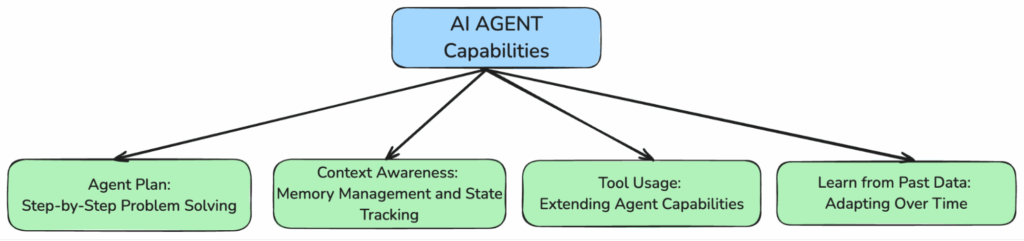
Plano do agente: Solução de problemas passo a passo
Os agentes de IA dividem tarefas complexas em etapas claras e gerenciáveis - identificando o problema, executando cada fase e ajustando conforme necessário. Em sistemas multiagentes, cada agente pode se apropriar de uma tarefa específica, permitindo a solução eficiente e coordenada de problemas.
Conscientização de contexto: Gerenciamento de memória e rastreamento de estado
Os agentes mantêm o contexto entre as interações, lembrando-se de entradas anteriores e adaptando-se aos fluxos de trabalho em andamento. Esse rastreamento de estado cria experiências de usuário mais naturais, consistentes e inteligentes.
Uso da ferramenta: Ampliação dos recursos do agente
Os agentes podem interagir com ferramentas externas - APIs, bancos de dados, scripts - para executar ações reais, e não apenas oferecer sugestões. Isso os transforma de assistentes passivos em executores ativos nos fluxos de trabalho.
Aprenda com os dados anteriores: Adaptação ao longo do tempo
Ao analisar os dados históricos e o comportamento, os agentes melhoram com o tempo - antecipando as necessidades do usuário, refinando as respostas e otimizando os fluxos de trabalho com base nos padrões de uso.
O que é um sistema multiagentes (MAS)?
A arquitetura multiagente é um projeto de sistema em que vários agentes independentes trabalham juntos para resolver problemas ou executar tarefas. Cada agente tem sua própria função, como coletar dados, analisar informações ou tomar decisões. Esses agentes se comunicam e colaboram para atingir um objetivo comum, tornando o sistema mais organizado. É como uma equipe em que cada membro faz um trabalho específico, mas todos trabalham para o mesmo resultado! Usamos a arquitetura multiagente para o Polaris.
Por que a mudança da arquitetura de agente único?
Um único agente de IA opera de forma independente, lidando com tarefas específicas de forma autônoma. Isso funciona bem para aplicações simples, como um sistema RAG (Retrieval-Augmented Generation), em que um agente responde às consultas do usuário com base em um LLM e um conhecimento. Entretanto, em aplicações práticas, as interações com o usuário raramente são simples. Elas geralmente envolvem lógica complexa, raciocínio em várias etapas e a necessidade de trabalhar com modelos de dados dinâmicos e requisitos comerciais em constante evolução. Nesse ponto, os sistemas de agente único começam a atingir os limites de desempenho e escalabilidade. Eles podem falhar ao encadear várias operações, adaptar-se às mudanças de esquema ou coordenar fluxos de trabalho diferenciados.
Por que as arquiteturas multiagentes (MAS) funcionam?
A separação de preocupações inerente ao design do MAS resulta em sistemas mais robustos e de fácil manutenção. Cada agente se concentra em sua tarefa específica, reduzindo a complexidade e facilitando a identificação e a resolução de problemas. Essa abordagem se destaca em cenários como o controle de veículos autônomos, em que agentes separados lidam com a navegação, a detecção de obstáculos e a dinâmica do veículo, permitindo o desenvolvimento e a solução de problemas focados em cada área.
Sistemas Multiagentes Supervisor vs. Rede

Arquitetura multiagente descentralizada (ponto a ponto)

Nós escolhemos: Arquitetura baseada em supervisor
Nosso aplicativo faz uso do Agente supervisor LangGraph:
-
- Raciocínio centralizado, consistência e coerência
- O raciocínio complexo se beneficia de uma visão global dos dados, da intenção do usuário e do contexto. O supervisor pode manter uma lógica coerente em várias etapas.
- Um único ponto de tomada de decisão garante que os resultados estejam alinhados (por exemplo, o gráfico corresponde à explicação, o resumo reflete a análise).
- O controle central permite a alocação dinâmica de tarefas a subagentes especializados (por exemplo, gerador de gráficos, agente de consulta). Evita a duplicação de esforços e otimiza o uso de recursos.
- Tratamento de erros, recuperação e escalabilidade mais fáceis
- Os erros podem ser detectados e gerenciados de forma centralizada. O supervisor pode tentar novamente as tarefas, reatribuir funções ou gerar respostas alternativas.
- O controle central permite a alocação dinâmica de tarefas a subagentes especializados (por exemplo, gerador de gráficos, agente de consulta). Evita a duplicação de esforços e otimiza o uso de recursos.
- É mais fácil adicionar, substituir ou atualizar subagentes sem reprojetar todo o sistema.
- Raciocínio centralizado, consistência e coerência
Núcleo Polaris
Em sua essência, o Polaris utiliza uma rede de agentes de IA especializados, cada um deles otimizado para diferentes aspectos do ciclo de vida da interação de dados. Agora vamos entender quais são os componentes e a arquitetura geral de alto nível de vários agentes do Polaris com a ajuda de um exemplo:
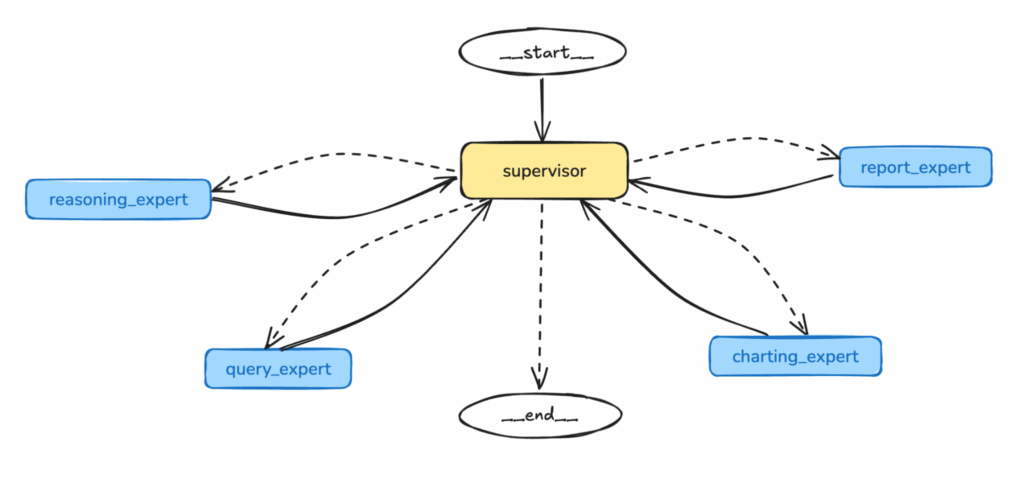
Compreensão e orquestração: Agente supervisor
O Agente supervisor atua como controlador central e orquestrador inteligente do sistema multiagente.
Funções:
-
- Análise de intenção: Analise a entrada do usuário e extraia intenções e parâmetros relacionados à tarefa.
- Exemplo: O usuário pergunta: "Por que o total de vendas de produtos eletrônicos no primeiro trimestre de 2024 caiu na região da APAC?" O Agente Supervisor analisa essa pergunta para identificar a Intenção: "Reason- causal analysis for sales drop" (Razão - análise causal para queda nas vendas), Product Category (Categoria de produto): "Eletrônicos", Período de tempo: "Q1 2024" , Região: "APAC".
- Lógica de roteamento de agentes: Implementa um mecanismo de decisão ou uma camada de orquestração baseada em regras para encaminhar tarefas aos agentes apropriados.
- Exemplo: Com base na intenção analisada "análise causal para queda nas vendas", o Agente Supervisor decide primeiro encaminhar a tarefa para o Especialista em consultas para obter dados de vendas, depois para o Especialista em gráficos para visualização, depois para o agente de raciocínio para identificação causal e, finalmente, para o Especialista em relatórios para resumo.
- Gerenciamento de contexto: Mantém o contexto e o estado da conversa global.
- Tratamento de erros e recuperação: Monitora o sucesso/falha da tarefa e pode reatribuir ou reformular subtarefas com base no feedback do agente.
- Exemplo: Se o Especialista em consultas informar que uma coluna solicitada, Tipo de produto, não existir no esquema, o Agente Supervisor poderá redirecionar a solicitação para o Especialista em Raciocínio para sugerir colunas alternativas relevantes ou informar o usuário sobre os dados ausentes.
- Análise de intenção: Analise a entrada do usuário e extraia intenções e parâmetros relacionados à tarefa.
Extração de dados relevantes: Especialista em consultas
O Query Expert traduz as perguntas em linguagem natural para SQL++, obtendo assim os dados necessários.
Funções:
-
- Inferência de esquema e anotações: Infere o esquema de dados usando o comando INFER do SQL++, que obtém os nomes das colunas, o tipo de dados das colunas e os documentos de amostra; isso, juntamente com a ajuda de anotações, ajuda a entender os dados, as relações entre tabelas, os tipos de dados e as restrições.
- Exemplo: Quando o SQL++ INFER é executado em uma coleção, ele pode identificar um campo simplesmente como "amount": NUMBER. Sem mais contexto, o Especialista em Consultas não saberia se isso se refere a sale_amount, discount_amountou quantidade. No entanto, por meio de anotações, a Polaris é explicitamente informada: "amount" (valor) campo em 'vendas_empresariais' coleção representa 'valor total das vendas' para uma transação. Essa anotação é crucial porque quando o usuário pergunta "vendas totais", o Query Expert agora mapeia com confiança vendas para o quantidade gerando corretamente o campo SUM(montante).
- Canonização de entrada: Transforma a entrada de linguagem natural original do usuário em uma forma mais detalhada, inequívoca e estruturada. Isso ajuda a ferramenta de QI a entender melhor a tarefa.
- Exemplo: Entrada do usuário: "vendas no mês passado." Entrada canonizada: "Recupere o valor total de vendas da categoria "Eletrônicos" para os 30 dias anteriores a partir da data atual.“
- Tradução de NL para SQL++: Chamada para a ferramenta IQ para converter NL em SQL++
- Verificações de qualidade de dados e recuperação de erros: o agente inspeciona se há valores nulos e outros problemas de integridade de dados que possam afetar a interpretação. Se a qualidade dos dados for ruim (por exemplo, todos os NULLs em uma coluna), o agente reformulará a consulta ou retornará um aviso para intervenção do usuário. Com base no diagnóstico de erros, o agente ajusta automaticamente a consulta (por exemplo, corrige os nomes das colunas ou limita o tamanho dos resultados) e tenta novamente a execução de forma inteligente.
- Exemplo: Se o sale_amount pode conter nulos, o Query Expert adiciona automaticamente: E sale_amount IS NOT NULL à consulta gerada para garantir cálculos de soma precisos.
- Inferência de esquema e anotações: Infere o esquema de dados usando o comando INFER do SQL++, que obtém os nomes das colunas, o tipo de dados das colunas e os documentos de amostra; isso, juntamente com a ajuda de anotações, ajuda a entender os dados, as relações entre tabelas, os tipos de dados e as restrições.
Geração de insights: Especialista em gráficos
Responsável pela conversão de resultados de consultas estruturadas em representações visuais significativas, adaptadas à natureza dos dados e à consulta do usuário.
Funções:
-
- Lógica de seleção de gráficos: Usa heurística baseada em regras para selecionar tipos de gráficos apropriados com base nas características dos dados (por exemplo, dimensões, métricas, séries temporais).
- Exemplo: Com base nas regras fornecidas no prompt e no tipo de dados, o especialista escolherá um gráfico apropriado; por exemplo, se forem dados de vendas e séries temporais em que precisamos identificar alguma tendência, ele selecionará um gráfico de linhas.
- Geração de visualização dinâmica: Constrói visualizações usando bibliotecas como Plotly e Seaborn.
- Lógica de seleção de gráficos: Usa heurística baseada em regras para selecionar tipos de gráficos apropriados com base nas características dos dados (por exemplo, dimensões, métricas, séries temporais).
Relatórios e resumos: Especialista em relatórios
Compila insights, visualizações e contexto em relatórios estruturados.
Funções:
-
- Agregação de conteúdo: Resume automaticamente os resultados da consulta, incorpora visualizações, a metodologia e inclui metadados (por exemplo, fontes de dados, parâmetros de consulta).
- Controle de versão e registros de auditoria: Opcionalmente, integra o controle de versão e o registro para conformidade e rastreabilidade dos relatórios gerados.
Explicação e raciocínio: Especialista em raciocínio
Fornece raciocínio causal, análise de tendências e geração de hipóteses, interpretando insights de dados por meio das lentes do conhecimento do domínio e da inferência lógica.
Funções:
-
- Raciocínio baseado em LLM: Aproveita os LLMs para raciocinar sobre os resultados dos dados, descobrir padrões latentes e gerar narrativas explicativas.
- Aumento contextual: Utiliza o conhecimento específico do domínio extraído do banco de dados do usuário para fornecer explicações fundamentadas.
Fluxo de trabalho
A plataforma Polaris foi projetada para transformar perguntas de linguagem natural em insights inteligentes e multimodais, orquestrando uma equipe de agentes especializados. Veja como o fluxo de trabalho se desenvolve:
- Inicialização do sistema Polaris
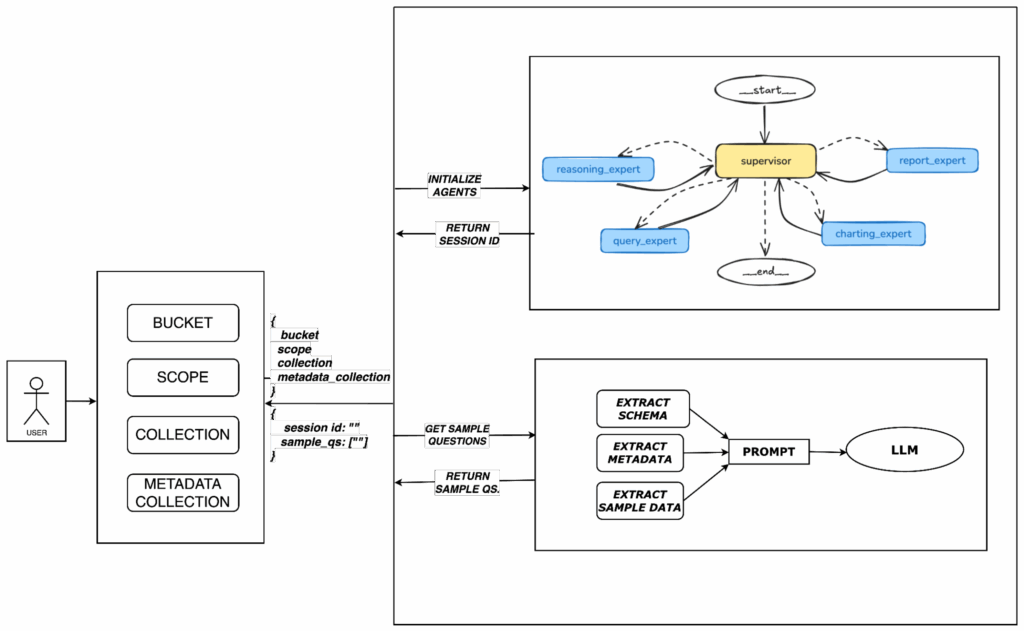 O usuário começa selecionando o balde, escopo, coleta e coleta de metadados. Com base nesse contexto, o Polaris inicializa os agentes especializados e usa o esquema, os metadados e os dados de amostra para solicitar um LLM, que gera exemplos de perguntas para orientar a exploração do usuário.
O usuário começa selecionando o balde, escopo, coleta e coleta de metadados. Com base nesse contexto, o Polaris inicializa os agentes especializados e usa o esquema, os metadados e os dados de amostra para solicitar um LLM, que gera exemplos de perguntas para orientar a exploração do usuário.
- Interação de linguagem natural

- Processamento inteligente de consultas
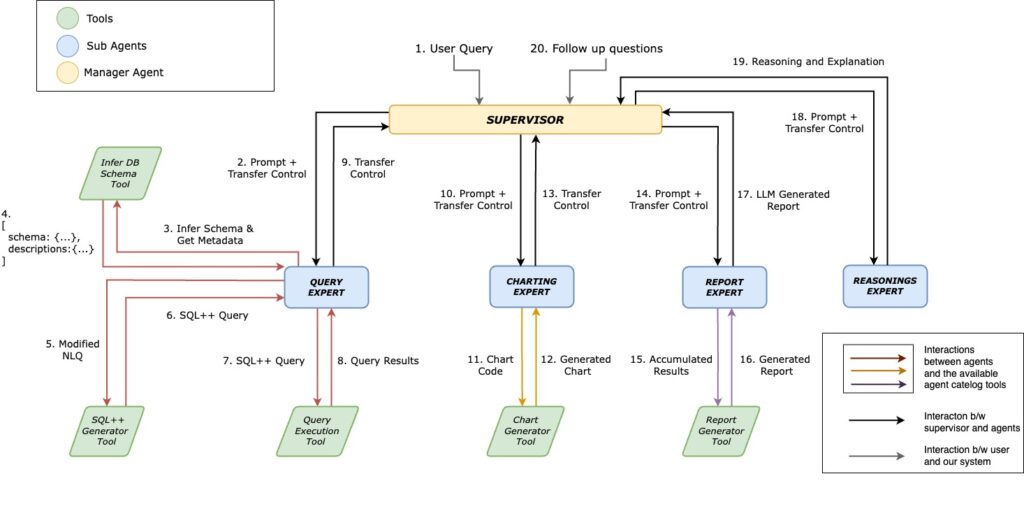
Diagrama de projeto de alto nível
- O Especialista em consultas lida com as principais tarefas de acesso a dados: inferir o esquema, traduzir a consulta em linguagem natural para SQL++ usando uma ferramenta geradora e executar a consulta.
- As ferramentas de suporte do Query Expert incluem Ferramenta de inferência de esquema, Ferramenta geradora de SQL++e Ferramenta de execução de consultas.
- Geração de respostas multifacetadas
Com base nos resultados da consulta inicial, o Supervisor coordena:- O Especialista em gráficosque cria visualizações de dados por meio de um Ferramenta de geração de gráficos.
- O Especialista em relatóriosresponsável por gerar resumos textuais usando um Ferramenta de geração de relatórios.
- O Especialista em raciocínioO que acrescenta contexto, lógica ou explicações adicionais para enriquecer a resposta.
- Fornecimento abrangente de insights
O Polaris sintetiza os resultados estruturados da consulta, os resultados visuais e as explicações narrativas em uma resposta coesa e fácil de usar. Esse insight multimodal é devolvido por meio da interface de bate-papo, combinando clareza, profundidade e interatividade. - Exploração iterativa
Os usuários são incentivados a fazer perguntas de acompanhamento. Como o sistema retém o contexto e o estado durante a sessão, a rede de agentes pode se basear em interações anteriores para dar suporte à exploração profunda e iterativa dos dados.


Uso de agentes ReAct
O que é um agente ReAct?
"Um agente ReAct é um agente de IA que usa a estrutura de "raciocínio e ação" (ReAct) para combinar o raciocínio de cadeia de pensamento (CoT) com o uso de ferramentas externas. A estrutura ReAct melhora a capacidade de um modelo de linguagem grande (LLM) de lidar com tarefas complexas e tomada de decisões em fluxos de trabalho agênticos.Dave Bergmann, IBM
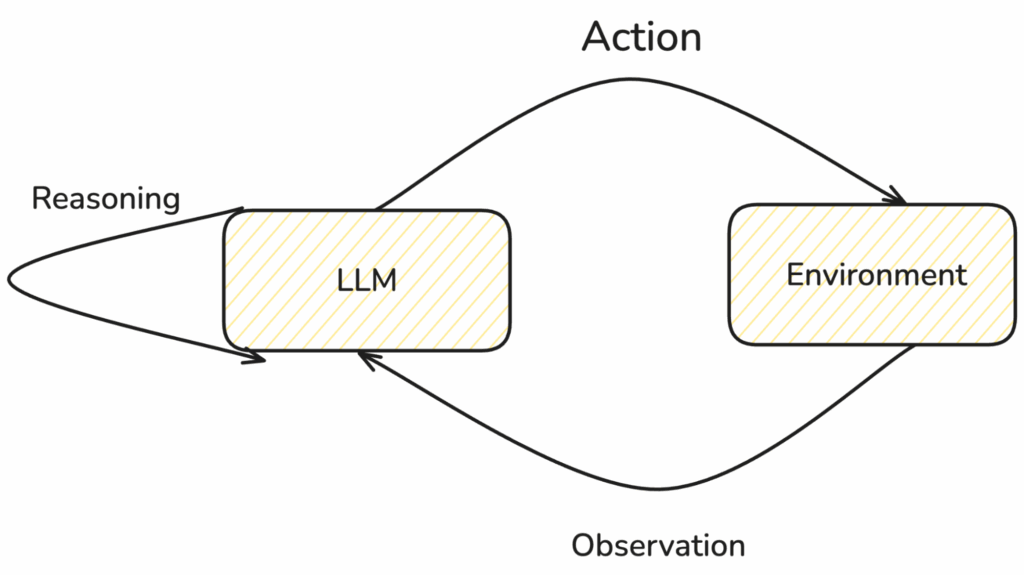
Funcionamento de um agente ReAct
Ao contrário dos sistemas tradicionais de Inteligência Artificial (IA), os agentes ReAct não separam a tomada de decisões da execução de tarefas. Essa estrutura cria inerentemente um loop de feedback no qual o modelo resolve o problema repetindo iterativamente esse processo intercalado pensamento-ação-observação processo. Usamos o LangGraph ReAct embutido em nosso aplicativo, e cada um dos especialistas é modelado como um agente ReAct.
Os arquitetos invisíveis: o poder de prompts eficientes na análise de dados orientada por IA
No campo da análise de dados, os holofotes geralmente se voltam para algoritmos, modelos estatísticos e técnicas de visualização. Entretanto, por trás de cada gráfico perspicaz, de cada relatório bem estruturado e de cada conclusão baseada em dados, há um aspecto crucial e invisível: o prompt.
Prompting de lista de tarefas
A solicitação de lista de tarefas fornece ao modelo uma lista de tarefas persistente e estruturada à qual ele se refere em cada etapa. Em vez de depender da memória ou de mensagens anteriores, o plano completo é injetado em cada solicitação. Portanto, o agente tem uma compreensão clara de todas as tarefas que precisa verificar. Isso evita desvios, repetições ou pulos de etapas.
Prompting de identidade
O prompt de identidade informa ao modelo o que ée não apenas o que ele deve fazer. Isso estabelece uma função ou persona consistente que influencia a maneira como o modelo se comporta e responde. Prompts como "Você é muito proficiente em tarefas de visualização de dados". pode acionar instantaneamente o comportamento específico do domínio - respostas claras, confiantes e focadas.
Prompting de autorreflexão
O prompt de autorreflexão instrui o modelo a avaliar seu próprio resultado após a conclusão de uma tarefa. Isso permite que o modelo faça uma introspecção e verifique se atingiu a meta do usuário e faça correções, se necessário. Em nosso aplicativo, implementamos a solicitação de autorreflexão na função Agente especialista em consultas. Depois que a consulta SQL é gerada e executada, o agente verifica se todos os pontos de dados necessários estão presentes.
O prompting é mais uma arte do que uma ciência - não existe uma fórmula única para todos. No entanto, ao aplicarmos heurísticas comprovadas e um enquadramento claro da tarefa, podemos orientar os modelos para obter resultados mais precisos, úteis e conscientes do contexto. O segredo é a experimentação, a iteração e o aprendizado do que funciona melhor em seu aplicativo específico.
Demonstração do Polaris, a interface de conversação com vários agentes
Desafios e trabalhos futuros
O Polaris representa uma mudança de paradigma na forma como as organizações podem aproveitar seus ativos de dados, especialmente por meio de interações de linguagem natural, permitindo a descoberta intuitiva de dados e acelerando significativamente a tomada de decisões. Um grande avanço foi o nosso desenvolvimento de uma arquitetura dinâmica de vários agentes que adapta sua abordagem com base no contexto e pode trabalhar com diversos conjuntos de dados.
No entanto, ainda há vários desafios. Uma das principais áreas tem sido o gerenciamento de anotações de dados. Garantir anotações consistentes e significativas em colunas variadas é fundamental para manter a qualidade dos insights gerados pelos agentes de IA. Poderíamos explorar a integração com um catálogo de dados global para facilitar esse processo. Outro desafio significativo é a limpeza de dados. Embora atenuemos alguns desses problemas no nível da consulta por meio de cláusulas condicionais e limpeza básica de dados, ainda há espaço para melhorias na validação e no pré-processamento de dados upstream.
Além disso, lidar com a recuperação de dados em grande escala tem sido um obstáculo técnico. Em cenários do mundo real, os conjuntos de dados recuperados geralmente excedem os limites da janela de contexto dos atuais modelos de linguagem de grande porte. Para resolver isso, realizamos operações de agregação e geramos resumos visuais, como gráficos, para fornecer percepções de alto nível sem sobrecarregar o modelo.
No futuro, o trabalho se concentrará no aprimoramento dos pipelines de anotação, na melhoria do gerenciamento da qualidade dos dados e na exploração de métodos mais eficientes de sumarização e colaboração de agentes de várias voltas para ampliar ainda mais o Polaris.
Conclusão: inaugurando uma nova era de interação de dados
Ao combinar o poder de um sistema de IA multiagente com a simplicidade da conversação em linguagem natural, o Polaris democratiza o acesso aos dados, capacita os usuários corporativos e acelera a jornada dos dados à decisão. Acreditamos que o Polaris agregará um valor significativo para nossos clientes, promovendo uma empresa mais ágil, informada por dados e competitiva.
