O que é o PatientIQ e por que criá-lo?
O PatientIQ é um paciente agêntico 360 desenvolvido com o Couchbase Capella AI Services. É um exemplo de uma solução para um problema que estamos tentando resolver. Para o PatientIQ, tudo começou com uma única pergunta. Quantos de nós já tiveram uma experiência de saúde ruim com um ente querido?
A resposta a essa pergunta, quando feita em uma sala cheia de pessoas, foi assustadora. A maioria das mãos se levantou. As conversas posteriores confirmaram que, para aqueles que não levantaram a mão, geralmente estavam a um amigo próximo de uma experiência ruim. No entanto, os médicos dos Estados Unidos são excepcionais e muitos dos melhores do mundo trabalham aqui. Isso nos ajudou a reformular a pergunta. Se não há um problema de qualidade profissional, por que as experiências ruins são tão comuns?
O atendimento ao paciente é um problema de gerenciamento de dados
Nossas experiências pessoais e pesquisas nos levaram a acreditar que os médicos de hoje estão sobrecarregados. Quando estão em seu terceiro café e no quinto paciente antes do almoço, pode ser difícil oferecer um excelente atendimento personalizado de forma consistente. À medida que nos aprofundamos no problema, nossa pesquisa revelou que os médicos de hoje gastam duas vezes mais tempo com registros eletrônicos de saúde (EHRs) do que com o atendimento ao paciente. Estima-se também que entre 30-40% dos EHRs estejam faltando metade dos valores de dados esperados.
Os médicos passam muito tempo pesquisando dados que, muitas vezes, são incompletos. Esse não é um problema de qualidade do médico. É um problema de gerenciamento de dados. Os médicos são inteligentes, mas não se pode esperar que se lembrem de todos os detalhes de todos os seus pacientes. Entretanto, para uma medicina realmente personalizada, todos esses dados são essenciais. Os dados merecem tanto cuidado quanto os pacientes e, assim como um excelente médico, o Couchbase é especialmente adequado para resolver esse problema específico de gerenciamento de dados.
O estado atual da IA exige uma camada de dados robusta. Os modelos de uso geral não são treinados em dados da área da saúde, o que aumenta a probabilidade de alucinações que são inaceitáveis em um ambiente de saúde. O ajuste fino de um modelo pode ajudar a treinar um modelo em dados relevantes para tarefas específicas, mas o processo de treinamento pode levar tempo e os resultados podem variar. Fornecer o contexto correto de nosso armazenamento de dados operacionais para nossos modelos e agentes é extremamente importante para reduzir o risco de alucinações e desenvolver uma camada de inteligência eficaz. Vamos agora analisar nossas considerações sobre a criação da base de dados correta para permitir isso.
Trabalhando de trás para frente a partir dos dados. Construindo a base de dados correta
Os dados sobre médicos e pacientes para esta demonstração são artificiais. É o mais realista possível, evitando problemas com o uso de informações confidenciais. A pesquisa médica é real e usou artigos do PubMed. Na prática, os dados do setor de saúde estão principalmente no formato FHIR, semelhante aos modelos de dados JSON que criamos, e não exigem processamento especial para serem ingeridos e fornecidos aos nossos agentes.
O conjunto completo de dados e o esquema com separação em escopos e coleções para organização de dados podem ser visualizados no GitHub. Embora este tenha sido um aplicativo de demonstração, com uma revisão independente, o Capella pode ser executado em conformidade com a HIPAA, e nosso objetivo é fazer isso na produção.
Para o PatientIQ, nossa estrutura de dados simples usa três compartimentos:
- Scripps: Nome do nosso hospital, incluindo todos os dados de médicos e pacientes.
- Pesquisa: Contém todos os dados de pesquisas médicas.
- Catálogo de agentes: Todos os dados sobre nossos agentes, ferramentas, prompts e rastros.
Para os nossos dados operacionais, a arquitetura exclusiva do Couchbase que prioriza a memória e o cache integrado nos permitiram obter tempos de resposta de menos de um segundo ao executar operações de criação, leitura, atualização e exclusão tratadas pelo nosso Couchbase Python SDK escolhido. Também usamos índices no nível da coleção, por exemplo Scripps.Pessoas.Pacientes, O PatientIQ tinha um sistema de gerenciamento de dados que permitia evitar varreduras completas de baldes e aproveitar os tempos de resposta rápidos das consultas. Era importante para o PatientIQ retornar dados operacionais sobre um paciente tanto para o painel quanto para nossos agentes. Isso permitiu que um médico com pouco tempo para se preparar para uma consulta recebesse informações oportunas com latência imperceptível.
Para manter o foco da nossa demonstração, o conjunto de dados é limitado a um hospital, um médico (Dr. Mitchell) e cinco pacientes. Aqui está um exemplo de um documento JSON de médico:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "doctor_name": "Tiffany Mitchell", "doctor_id": 1, "doctor_licence_number": "123456", "patients": [ "James Smith", "Maria Garcia", "Robert Chen", "Aisha Khan", "Emily Johnson" ] } |
Cada paciente tem uma condição pulmonar específica para garantir uma base de pesquisa médica direcionada: Asma, DPOC, Fibrose Pulmonar, Fibrose Cística e Bronquiectasia. Aqui está um exemplo de um documento JSON de paciente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ "patient_name": "James Smith", "patient_id": "1", "patient_email": "james.smith@mail.com", "patient_cell": "8583401257", "weight": "82", "height": "178", "medical_conditions": "Asthma", "gender": "male", "age": "32", "smoker": "no", "alcohol_consumption": "moderate", "blood_type": "A-", "admission_date": "2022-09-22", "doctor_name": "Tiffany Mitchell", "registered_hospital": "Scripps", "insurance_provider": "Aetna", "insurance_number": "32431432412" } |
Agora temos nosso hospital (Scripps), médico (Dr. Mitchell) e pacientes (por exemplo, James Smith). Aqui estão outras fontes valiosas de dados de pacientes:
- Vestíveis
- Anotações de visitas feitas por um médico
- Anotações particulares feitas por um paciente sobre sua visita
- Questionários pré-visita preenchidos pelos pacientes
- Detalhes de consultas e próximas visitas de pacientes
Atualmente, esses dados estão presos em um único dispositivo ou sistema e estão em diferentes formatos. Como resultado disso, pode ser muito difícil mover ou extrair insights deles. No entanto, quando reunidos, eles podem criar um perfil de dados exclusivo de um paciente que o médico pode usar para entender sua saúde e sua experiência hospitalar.
Com o Couchbase, podemos armazenar e recuperar nossos dados operacionais de forma otimizada, sem introduzir uma camada de cache separada ou complexidade adicional do sistema. Isso permite que nossa equipe se concentre no desenvolvimento de recursos, que depende do recebimento rápido desses dados operacionais.
Adicionando inteligência a uma base de dados sólida com os serviços de IA da Capella
Atualmente, adicionar inteligência a um aplicativo requer um banco de dados vetorial separado e o envio de dados para fora dos limites confiáveis para a linguagem e a incorporação de modelos em APIs externas. Isso funciona como uma barreira para os dados que podem ser usados e um risco para o desempenho e a segurança do aplicativo existente.
O Couchbase Capella e o AI Services permitem que o desenvolvedor supere essas barreiras, com suporte a banco de dados vetorial otimizado incorporado à plataforma e a capacidade de implantar e executar modelos otimizados da NVIDIA dentro de um limite de rede privada compartilhado com seus dados, sem que o tráfego atravesse a Internet pública. Para o PatientIQ, pudemos usar dois modelos seguros implantados no Capella Model Service.
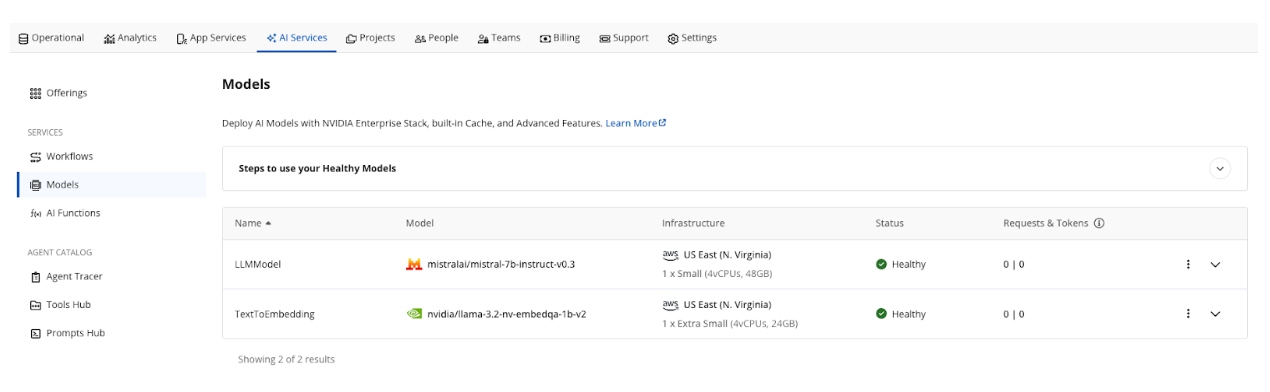
Decidimos que os seguintes dados operacionais seriam enviados ao nosso modelo de incorporação de texto nvidia/llama-3.2-nv-embedqa-1b-v2:
- Notas de visita: Tomada por um médico sobre a visita de um paciente.
- Pesquisa médica: Os artigos se concentraram em condições de saúde pulmonar.
Tradicionalmente, para transformar esses dados em embeddings de texto utilizáveis na pesquisa de similaridade semântica, seria necessário criar um pipeline de dados personalizado. Um processo de limpeza para normalizar o texto em um formato consistente. Uma estratégia de fragmentação para lidar com conteúdo de formato longo, como documentos de pesquisa. Código para chamar um modelo de incorporação e armazenar os vetores resultantes. Isso pode acrescentar várias semanas ao ciclo de desenvolvimento antes que qualquer funcionalidade significativa de IA seja fornecida.
Com o AI Services, o serviço Data Processing foi usado para simplificar o processo. Há opções de pré-processamento de dados que podem ser usadas para controlar como os dados são vetorizados. Vetorizamos campos JSON específicos e retornamos um novo campo dentro do nosso documento JSON contendo nossos embeddings de texto. Como exemplo, a pesquisa médica foi extraída do PubMed usando o BigQuery com a seguinte consulta SQL:
|
1 2 3 4 5 6 |
SELECT author, title, article_text, article_citation, pmc_link FROM `bigquery-public-data.pmc_open_access_commercial.articles` WHERE REGEXP_CONTAINS(LOWER(IFNULL(title, '')), r'asthma|copd|chronic obstructive pulmonary|emphysema|pneumonia|influenza|pulmonary fibrosis|sarcoidosis|pulmonary hypertension|respiratory|pulmonary') LIMIT 50; |
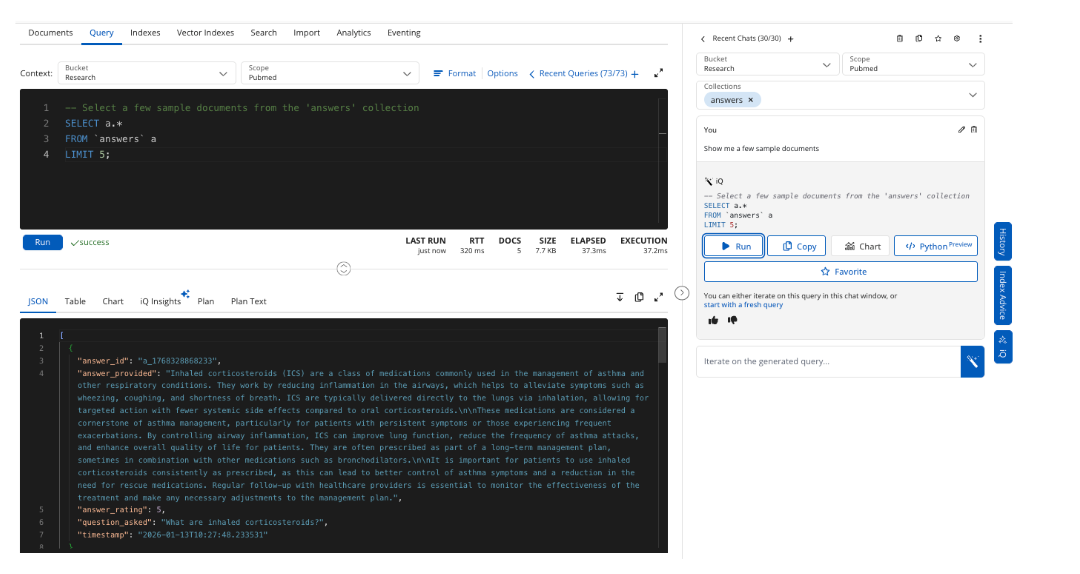
A consulta retornou 50 artigos de pesquisa pulmonar que foram exportados para JSON. O texto no arquivo texto_do_artigo para 50 documentos foi vetorizado e armazenado em um novo campo article_text_vectorized. Podemos recuperar cinco exemplos de documentos usando o Capella iQ para escrever nossa consulta SQL++.

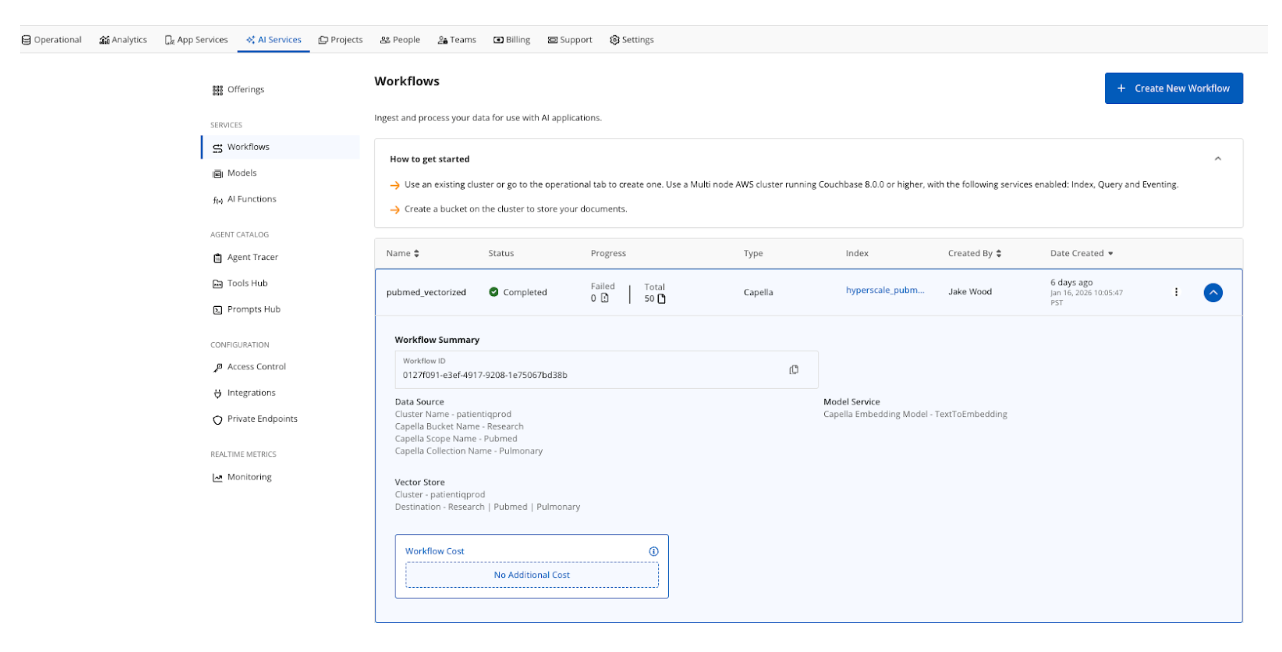
O fluxo de trabalho automatiza o processo do pipeline de incorporação e armazena os resultados no Pesquisa.Pubmed.Pulmonar coleção. Opcionalmente, um índice de hiperescala é criado ao configurar um fluxo de trabalho. Os índices de hiperescala são configurados para o PatientIQ porque o aplicativo realiza pesquisas vetoriais puras e se beneficia das otimizações para indexar uma única coluna vetorial.
Os dados do setor de saúde geralmente não são arquivados rapidamente porque o histórico médico pode remontar a vários anos e há uma grande possibilidade de que o índice cresça para centenas ou até bilhões de documentos em grandes sistemas de saúde. O índice de hiperescala é uma ótima opção para preparar um sistema de recuperação em grande escala para o futuro.
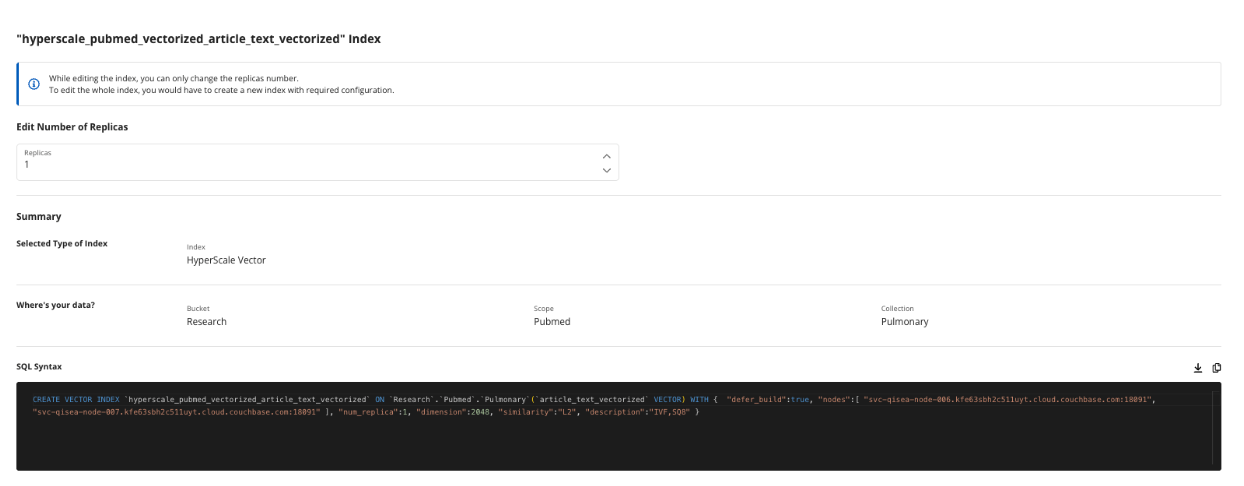
O índice em hiperescala tem uma única réplica, lida com 2048 dimensões geradas pelo modelo de incorporação de texto NVIDIA llama-3.2-nv-embedqa-1b-v2 e usa o algoritmo de pesquisa de similaridade L2, euclidiano ao quadrado. Existem quatro algoritmos de similaridade, dependendo do seu caso de uso, e consideramos mudar de L2 para Cosine na produção porque nos preocupamos principalmente com o significado semântico, já que a magnitude não é tão importante.
Você pode ver referências ao Índice de Arquivo Invertido (IVF) e à Quantização SQ8. Esses são botões de configuração importantes que você pode girar para oferecer o melhor desempenho de pesquisa de vetores. IVF para tornar as pesquisas de vetores mais rápidas, limitando o número de comparações com vetores próximos aos centroides relevantes. A Quantização escalar (SQ) reduz as dimensões para inteiros de 8 bits, reduzindo a memória necessária para a pesquisa e melhorando a velocidade porque essas operações inteiras são computacionalmente menos dispendiosas do que as operações de ponto flutuante.
É importante ressaltar que, para o PatientIQ, os dados vetoriais são criados, armazenados e consultados de forma ideal junto com nossos dados operacionais, sem pipelines complexos, configuração ou um banco de dados vetorial separado.
Além de um modelo de incorporação, implantamos um modelo de linguagem grande mistralai/mistral-7b-instruct-v0.3. O modelo é executado em um ambiente otimizado pela NVIDIA com opções de configuração adicionais para cache, guardrails e proteção contra jailbreak. Na produção, habilitaríamos tudo e usaríamos o cache para reduzir o número de chamadas LLM, os tokens usados e os custos.
Em um ambiente de assistência médica, o envio de dados pela Internet para pontos de extremidade de modelos públicos aumenta o risco de violações de privacidade de dados. A possibilidade de usar o Model Service, onde os dados e a inferência estão localizados, proporciona maior confiança para criar recursos inteligentes e, ao mesmo tempo, proteger os dados subjacentes.
O LLM foi usado de duas maneiras pelo PatientIQ:
- Resumir as informações do paciente no painel.
Usando a API do Model Service e nosso ponto de extremidade para /v1/chat/completions, um resumo dos detalhes gerais de um paciente e suas respostas fornecidas em um questionário pré-visita são transformados em parágrafos sucintos e digeríveis que um médico pode entender rapidamente antes que o paciente chegue para consultá-lo.
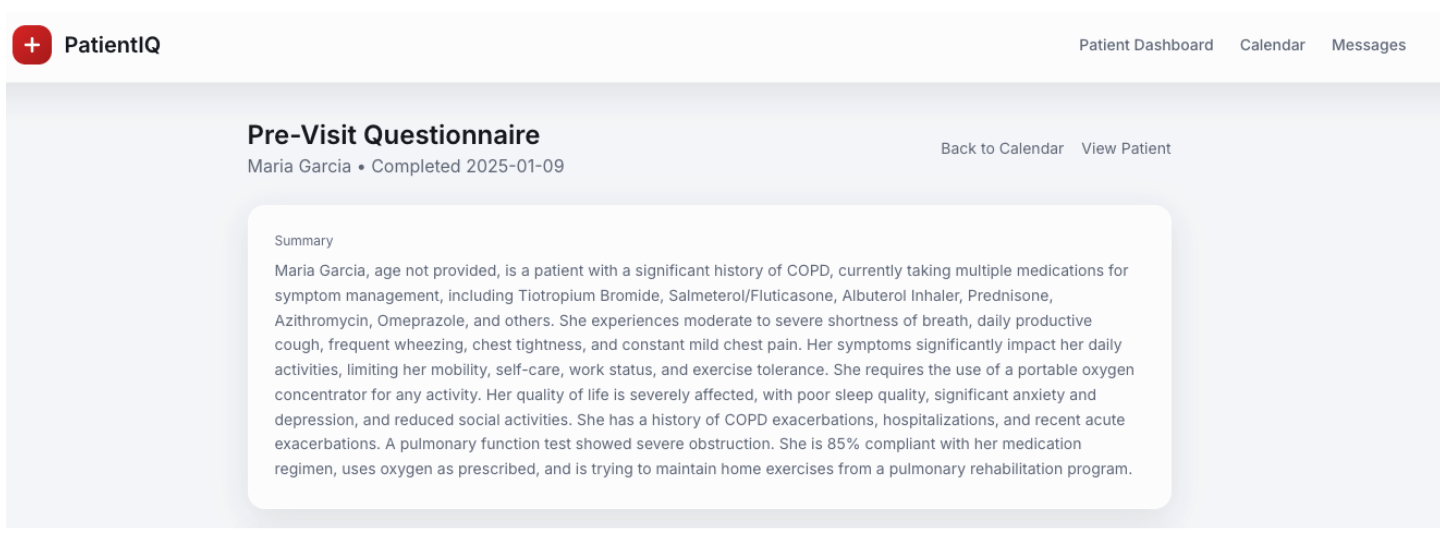
Esse é um exemplo de geração aumentada por recuperação (RAG) e se beneficia de nossos dados operacionais armazenados na plataforma Capella usados como base de conhecimento para fornecer contexto a um prompt. Esse tipo de RAG foi usado para alimentar a sumarização inteligente em toda a plataforma PatientIQ e o LLM que interage com os dados operacionais é capaz de fazê-lo na mesma região AWS do leste dos EUA, fornecendo respostas rápidas ao painel.
2. Vincular-se a uma função de IA para realizar análise de sentimentos em anotações confidenciais de visitas de pacientes.
As anotações de feedback do paciente são sobre as visitas após a consulta com o médico. O conteúdo das anotações deve ser privado e não compartilhado diretamente com o médico. Em vez disso, uma Capella AI Function vinculada ao Mistral LLM é usada com o seguinte SQL++ para realizar a análise de sentimentos sobre o conteúdo das notas.
Há também a opção de usar um modelo especializado no AWS Bedrock que é treinado em dados de saúde. Essa pode ser uma maneira importante de garantir maior precisão com uma associação de modelos personalizados ao executar funções de IA.
O AI Functions permite que você execute operações pré-construídas de IA, como análise de sentimentos, diretamente com uma consulta SQL++ e menos código manual. Aqui está nossa consulta SQL++:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT p.doctor_id, p.doctor_name, p.patient_id, p.visit_date, p.visit_notes, default:ai_sentiment({ "text": p.visit_notes, "temperature": 0, #The temperature hyperparameter is set to 0 for max. determinism. "max_tokens": 500 }) AS visit_sentiment FROM `Patient` AS p LIMIT 100; |
Veja esse resultado de sentimento negativo, por exemplo:
|
1 2 3 4 5 |
"visit_notes": "Energy is low today. Unhappy with my Doctor’s response. Seemed distracted and disinterested.", "visit_sentiment": [ { "response": "negative" } |
O sentimento geral de como o paciente está se sentindo em relação ao seu médico é então preenchido no front-end do PatientIQ.
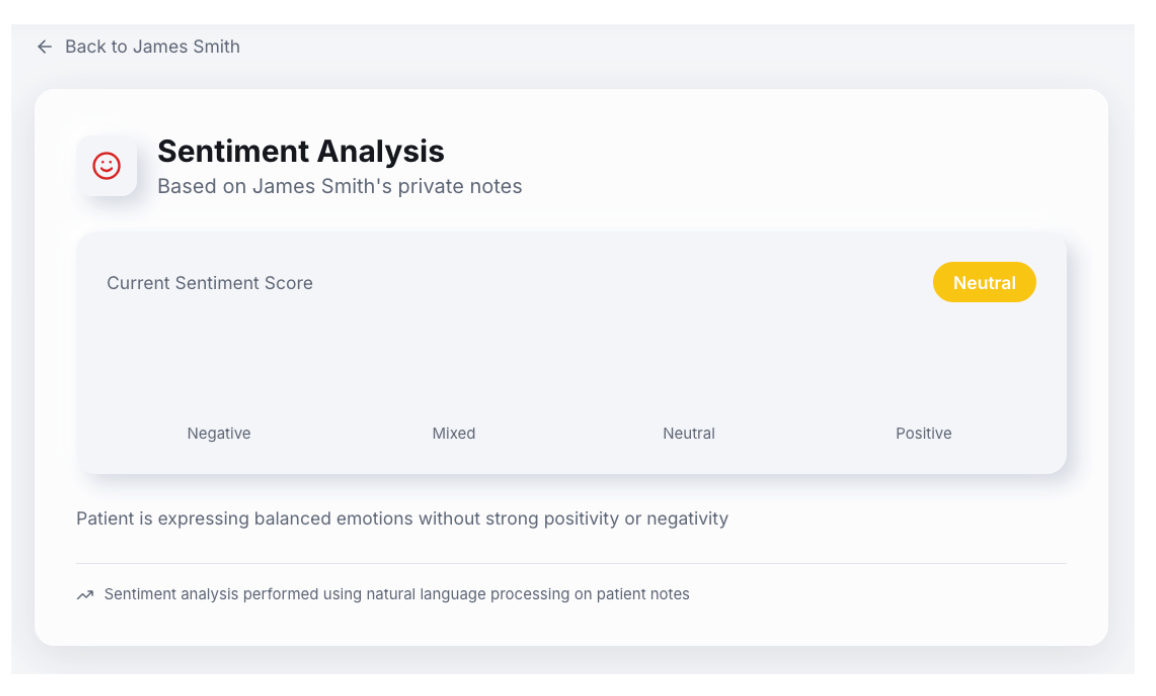
Essa implementação forneceu o feedback da última visita de um paciente para dar ao médico uma ideia de como ele pode estar se sentindo na próxima consulta. Os médicos podem tratar os pacientes que exibem sentimentos negativos com mais cuidado e adaptar-se à próxima consulta de acordo.
Agindo com inteligência. Criando um Paciente Autêntico 360
A próxima era do software será agêntica. O software será capaz de realizar ações nos dados antes que os resultados sejam entregues a nós, usuários. Isso significa que nosso software poderá realizar ações inteligentes sobre os dados, resultando em resultados mais úteis que poderemos usar para realizar nossas próprias ações no mundo físico.
Uma ressalva importante a ser observada em nossa demonstração é que usamos um LLM externo, mas ele seria trocado por um LLM com suporte para chamadas de ferramentas no Model Service da Capella na produção. Não queríamos enviar dados de pacientes para fora de nosso ambiente confiável e observamos problemas de latência ao interagir com uma API externa.
Se pudermos remover pequenas tarefas administrativas para os médicos por meio de ações agênticas, o resultado será um aumento do tempo para que eles possam tomar medidas com seus pacientes. Escolhemos quatro agentes para demonstrar exemplos de ações úteis:
1. Pesquisador pulmonar
Esse agente obtém a condição de um paciente, por exemplo, asma, e executa uma pesquisa de similaridade semântica para retornar artigos de pesquisa relevantes relacionados a essa condição. O prompt usa nosso LLM no Model Service para resumir a pesquisa e exibi-la no painel. Um médico pode então fazer uma pergunta mais específica. A pergunta é vetorizada, permitindo que a pesquisa de similaridade semântica retorne as respostas mais relevantes para a pergunta clínica do médico. As respostas são retornadas com as fontes usadas para gerar a resposta.

Usamos uma ferramenta de busca na Web para encontrar novas pesquisas médicas e retornar artigos relevantes dos três principais resultados da Web. Um médico pode verificar a fonte e optar por adicioná-la à sua base de pesquisa médica confiável. Quando um documento é adicionado, ele é vetorizado. O novo artigo é armazenado na Capella e fica disponível para ajudar a responder a futuras consultas.

Perguntas, respostas e uma pontuação de classificação são armazenadas no Capella para serem usadas na avaliação e no aprimoramento do desempenho futuro dessa funcionalidade.
O agente economiza o tempo do médico na busca de literatura relevante para a condição do paciente, fornecendo um resumo rápido e respostas a perguntas de sua base de pesquisa confiável.
2. Pesquisador do DocNotes
Esse agente pesquisa as anotações feitas por um médico durante e após as consultas com os pacientes. Um médico pode fazer perguntas na pesquisa para recuperar informações de visitas anteriores para ajudar a tomar decisões mais informadas. As anotações são escritas no PatientIQ, vetorizadas e salvas no Capella. Quando um médico faz uma pergunta, resultados semanticamente semelhantes são retornados como contexto para o LLM no Model Service que, em seguida, é fornecido como uma resposta.
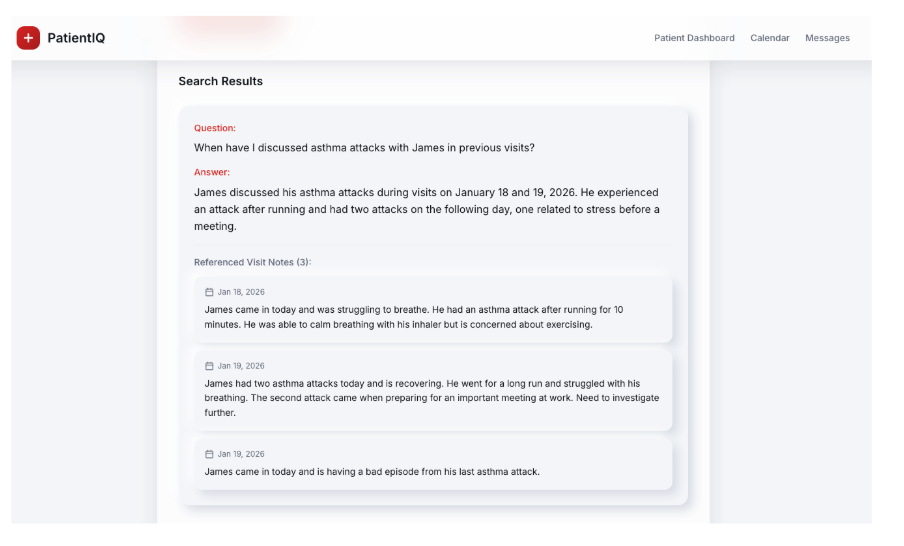
Esse agente economiza o tempo do médico na busca de anotações e na leitura de conteúdo irrelevante, fazendo uma pergunta importante e retornando uma resposta específica diretamente antes da visita ao paciente.
3. Sumarizador de pré-visita
Esse agente analisa o questionário de pré-visita de um paciente e permite que os médicos vejam um resumo antes da próxima consulta com um paciente.

A riqueza de detalhes do questionário é usada como contexto fornecido pela Capella para o LLM em Serviço Modelo e os detalhes essenciais são fornecidos ao médico para consumo simples. Por exemplo, as cinco principais perguntas do paciente para uma próxima consulta são fornecidas juntamente com os medicamentos atuais prescritos para o paciente. Ler um questionário inteiro antes de cada visita do paciente consumiria muito tempo, especialmente à medida que o número de visitas do paciente por dia aumenta.
4. Alertas vestíveis
Esse agente analisa os dados vestíveis de 30 dias de um paciente a partir de um dispositivo como o Apple Watch e alerta o médico se houver alguma tendência preocupante. Ele usa a condição identificada do paciente e fornece orientação sobre o que deve ser observado ao realizar a análise, por exemplo, um paciente asmático.
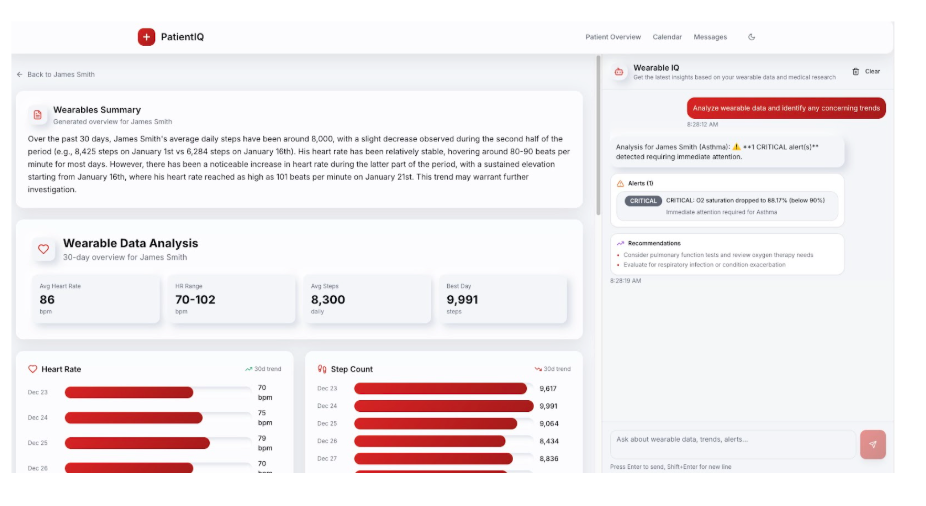
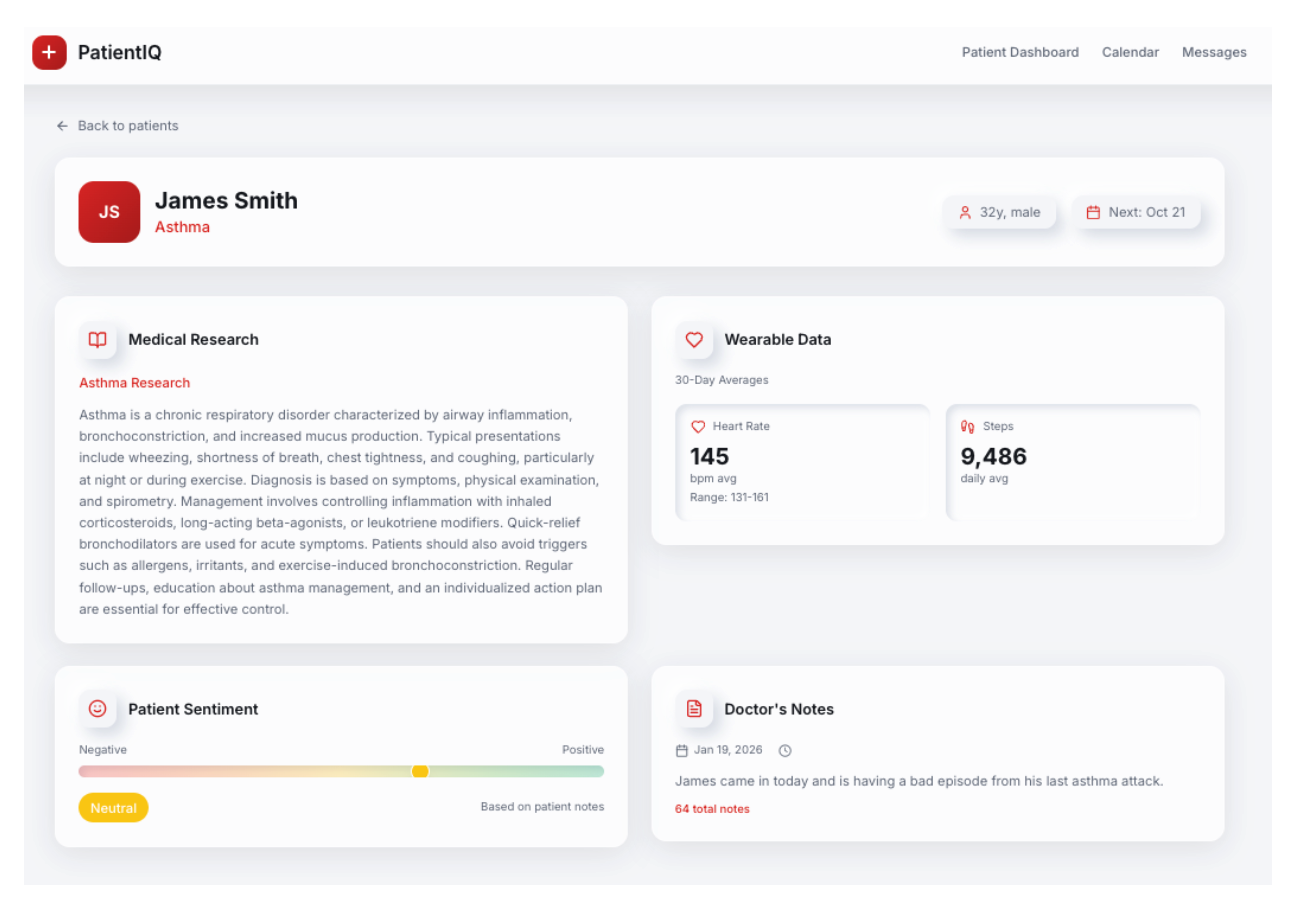
Acima está uma ilustração de um alerta crítico para a queda da saturação de oxigênio de um paciente abaixo de 90%. O médico pode definir os limites a serem observados, e o agente pode realizar o monitoramento consistente dos dados. Os dados vestíveis fornecem um instantâneo recente da saúde do paciente que os médicos podem usar para oferecer um tratamento personalizado.
Agentes do LangGraph ReAct. Prompts, ferramentas e rastreamentos no catálogo de agentes do Couchbase
Todos os agentes usam o LangGraph como uma estrutura de orquestração e são agentes ReAct simples que se comportam dessa maneira.
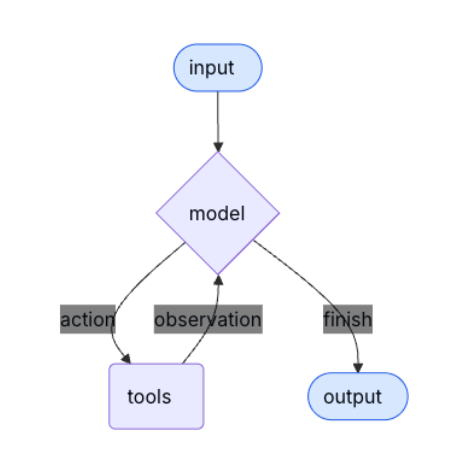
Uma das principais diferenças é que as ferramentas, os prompts e os rastreamentos são gerenciados pelo Catálogo de agentes do Couchbase. Os prompts e as ferramentas podem ser criados usando agente adicionar a partir da CLI. O Agent Catalog converte as consultas SQL++, as pesquisas semânticas e as solicitações HTTP em funções Python que podem ser recuperadas por nossos agentes.
Para o PatientIQ, criamos 28 ferramentas e cinco prompts que são armazenados localmente e no Capella. Foram usados transformadores de frases, bem como o ll-MiniLM-L12-v2 modelo de incorporação local para converter os prompts e as ferramentas em incorporação de texto.
Com o Agent Catalog, nossos agentes podem encontrar ferramentas e prompts relevantes usando similaridade semântica. Isso pode reduzir a confusão de um agente ao lidar com muitos prompts e ferramentas e não conseguir encontrá-los apenas com uma palavra-chave.
A equipe administrativa supervisiona os prompts e as ferramentas que nossos agentes usam, o que reduz o risco de uso não autorizado de ferramentas e garante que não sejam tomadas ações que não sejam visíveis. Há também uma opção para adicionar aprovação humana.
Com ferramentas e prompts criados e integrados aos nossos agentes, o catálogo pode ser indexado e publicado no Capella. Podemos visualizar, verificar o Git e revisar o histórico de versões.

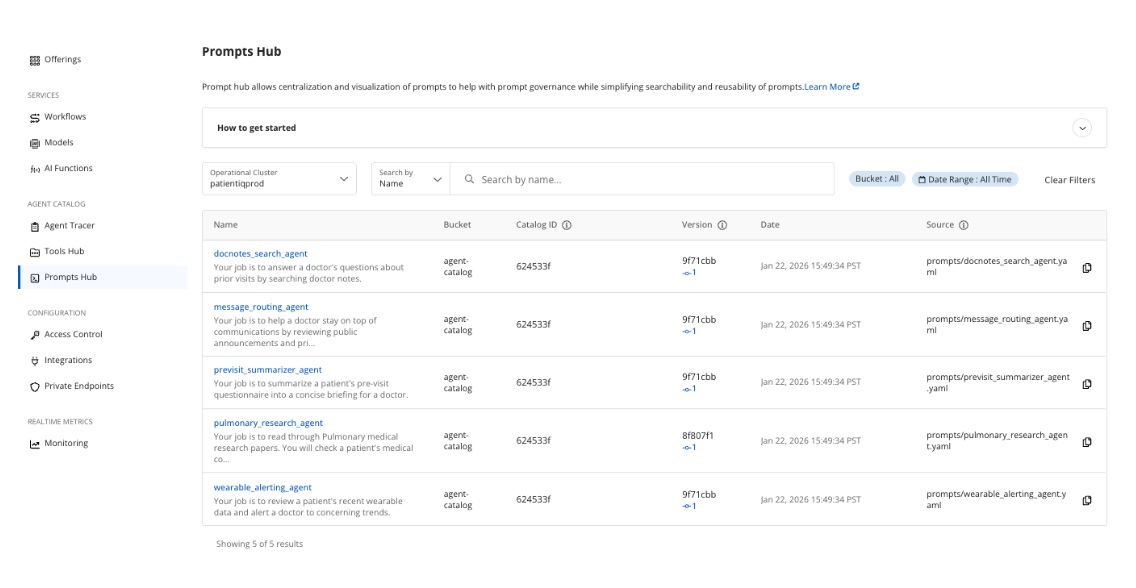
O armazenamento, o controle de versão e a recuperação de prompts e ferramentas da Capella simplificam a operação do processo de desenvolvimento em projetos, equipes e agentes.
Embora os agentes nunca substituam as ações do médico, eles permitem que o PatientIQ atue com base em nossos dados. O resultado é que os médicos têm mais tempo para se concentrar nas ações que realmente importam para os pacientes.
Trabalhando com o não determinismo. Solução de problemas e avaliação de agentes
Um desafio da funcionalidade agêntica é a introdução do não determinismo, em que a mesma entrada pode produzir saídas diferentes ou seguir caminhos diferentes para chegar lá. Isso pode ser benéfico para a experiência do usuário, tornando o software mais parecido com o ser humano, mas também pode resultar em resultados inesperados. Além de usar a geração aumentada por recuperação (RAG) para fornecer contexto aos nossos prompts, tentamos lidar com as desvantagens dos agentes não determinísticos de duas outras maneiras.
- Uso do Agent Tracer e de consultas SQL++ para solucionar problemas de comportamento inesperado do agente.
Um exemplo que nossa equipe experimentou foi o Pulmonary Researcher retornando artigos de pesquisa como referências que não existiam. No início, não entendíamos por que isso estava acontecendo no código do aplicativo. Em seguida, pudemos verificar o Agent Tracer nesse agente específico e restringir o problema às chamadas de ferramentas.
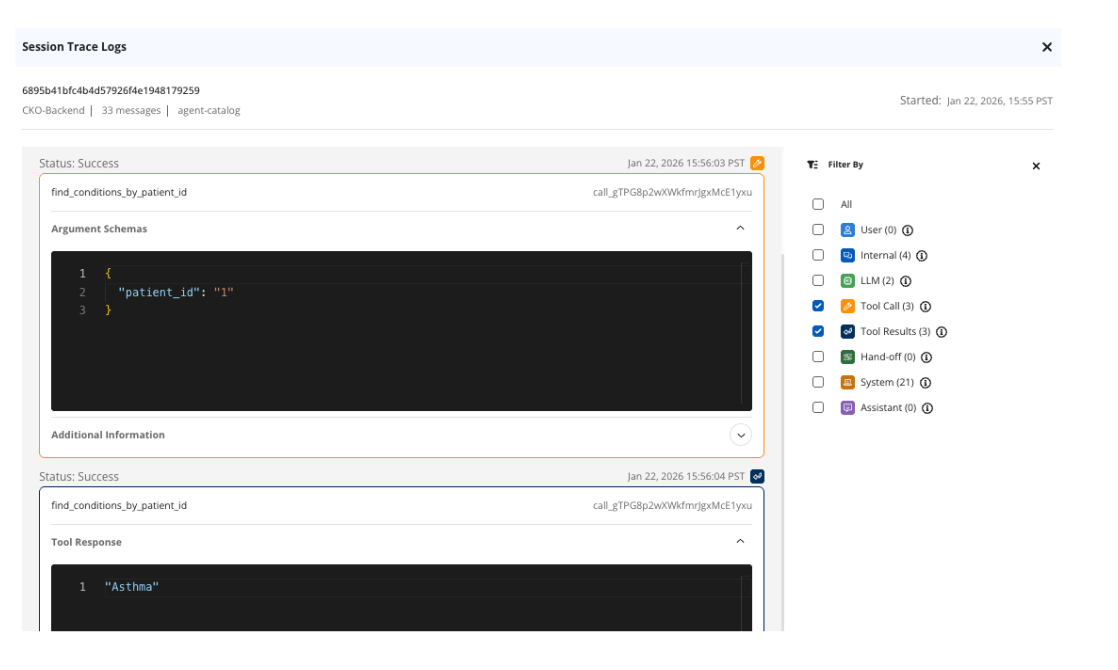
Percebemos que nossa ferramenta de pesquisa de papel não estava retornando nenhum resultado. Voltamos ao código do aplicativo e pudemos ver que, ao usar uma pesquisa por palavra-chave, usamos a palavra-chave errada para identificá-la. Nosso agente não estava usando a ferramenta que havíamos criado e estava alucinando com documentos de pesquisa não existentes.
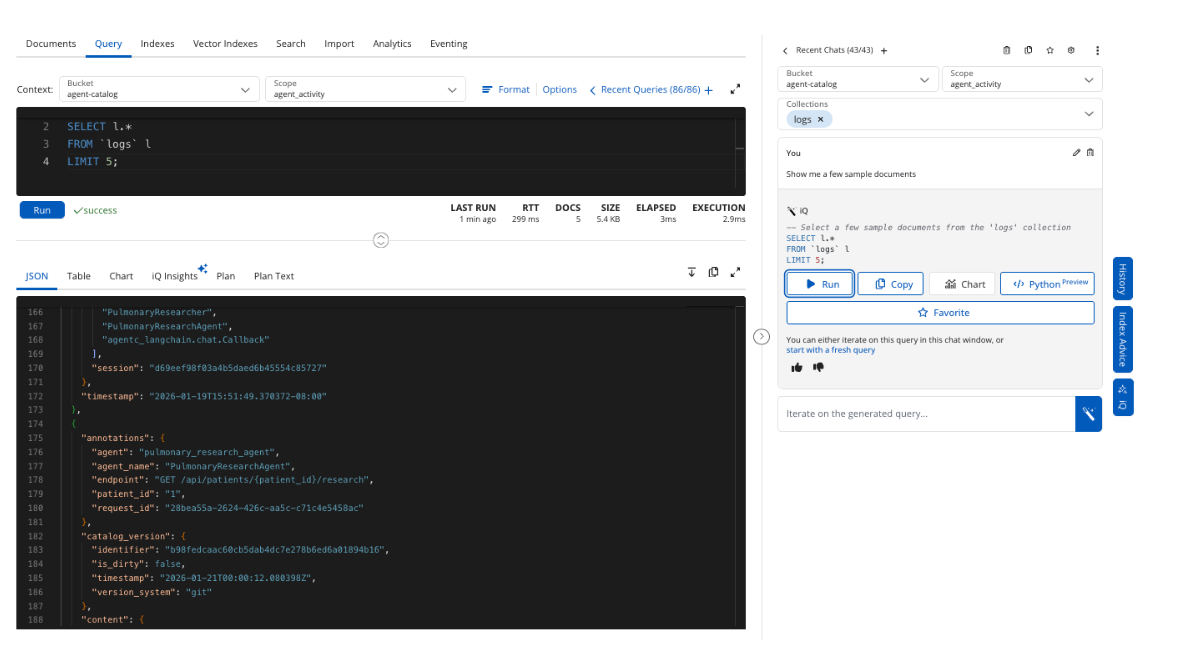
Realizamos uma investigação mais aprofundada com consultas SQL++, verificando nossos logs e sessões de agente quando isso ocorreu. Conseguimos, então, solucionar rapidamente o problema e resolver o agente que estava apresentando mau comportamento.
2. Criar nossas próprias avaliações de agentes usando ragas para criar um sistema de pontuação.
No PatientIQ, executamos avaliações para cada agente usando exemplos de prompts por meio dos mesmos fluxos de agentes e, em seguida, usamos ragas e métricas classificadas pelo LLM para pontuar os resultados em relação às expectativas. Criamos nossas próprias dimensões de pontuação, como qualidade da resposta, fundamentação e relevância, para comparar as mudanças ao longo do tempo à medida que os prompts, as ferramentas e nossa lógica de recuperação evoluíam. Este é um exemplo de métrica para o nosso Pesquisador pulmonar:
- Relevância clínica: Quão clinicamente relevante e responsiva é a resposta à pergunta e ao contexto do paciente.
- Capacidade de ação: Quão acionáveis são as próximas etapas e o raciocínio clínico para um médico.
- Base de evidências: O quanto a resposta está fundamentada em evidências e evita afirmações sem base. Penalidade para citações alucinadas.
A relevância clínica foi introduzida depois que foi identificado um problema com o agente que retornava um artigo de pesquisa inventado como evidência para uma resposta a uma pergunta clínica. Depois que o problema foi corrigido, observamos uma melhoria na pontuação de fundamentação das evidências.
Rumo ao PatientIQ em produção e em escala. Por que criar no Couchbase?
O PatientIQ demonstra o que é possível quando os dados operacionais, a pesquisa de vetores, os modelos e as ferramentas de agentes estão em uma única plataforma. Não há necessidade de unir vários bancos de dados, armazenamentos de vetores externos e chamadas de API públicas que enviam dados privados para fora dos limites de segurança. Modelos e dados podem operar na mesma rede privada. As consultas são executadas na velocidade que prioriza a memória. Os prompts e as ferramentas são versionados de forma centralizada. O sistema pode ser dimensionado horizontalmente para bilhões de documentos e vetores, mantendo o acesso de baixa latência e operando com um custo total de propriedade (TCO) reduzido.
As implicações comerciais são significativas. Os médicos economizam o tempo que antes era perdido navegando em sistemas EHR fragmentados. Os pacientes recebem um atendimento mais atencioso e consciente do contexto. Os hospitais reduzem a sobrecarga administrativa e o risco potencial de negligência. A satisfação melhora em ambos os lados da interação. O mais importante é que os médicos passam mais tempo fazendo o que somente os seres humanos podem fazer: fornecer diagnósticos, proporcionar empatia e oferecer tratamento.
Atualmente, o setor de saúde não sofre com a escassez de profissionais capacitados. Ela sofre com dados fragmentados. A IA não conserta infraestruturas quebradas quando é simplesmente colocada em cima delas. Quando é construída sobre uma base de dados sólida, ela pode ampliar a experiência humana de maneiras poderosas. O futuro do software é agêntico. O futuro do setor de saúde é orientado por dados. O PatientIQ é o que acontece quando essas duas ideias se encontram com o Couchbase, a plataforma de dados operacionais para IA.
Embora os novos participantes do mercado ainda estejam experimentando a persistência de dados, o Couchbase já é a base de dados testada em batalha para a IA de saúde de alto risco. Com a confiança de líderes do setor como Arthrex, BD e Maccabi Healthcare Services, nossa plataforma lida com tudo, desde tempos de resposta inferiores a 1 ms até aplicativos de pacientes com capacidade off-line e dados cirúrgicos ao vivo. Ao preencher a lacuna entre dados fragmentados e cuidados que salvam vidas, o Couchbase oferece a confiabilidade e o desempenho comprovados necessários para a próxima geração de inovação médica.
Referências
Couchbase
- Serviços de IA
- SDK do Python
- Catálogo de agentes
- API de serviço de modelo
- Centro de confiança na nuvem - HIPAA
- Vantagens arquitetônicas exclusivas
- Conexão AWS PrivateLink
- NVIDIA AI Enterprise
- Índice de arquivo invertido
- Quantização SQ8
- Dados do processo para Capella
- Escolhendo o índice vetorial correto
- Comece a usar o Capella iQ
- Ferramentas e prompts de chamada
- Escolha do algoritmo de pesquisa
- Integrar o agente LangGraph
- Use as funções de IA do Capella
LangGraph
PatientIQ
- GitHub do PatientIQ
- PatientIQ DeepWiki
- Artigos de pesquisa do PubMed
- Incompletude dos registros eletrônicos de saúde
- Demonstração no YouTube