
Leia o histórico da paginação em meu artigo anterior: https://www.couchbase.com/blog/optimizing-database-pagination-using-couchbase-n1ql/
A paginação é a tarefa de dividir o resultado potencial em páginas e recuperar as páginas necessárias, uma a uma, sob demanda. Usar OFFSET e LIMIT é a maneira mais fácil de escrever a paginação em consultas de banco de dados. Juntos, OFFSET e LIMIT formam a cláusula de paginação da instrução SELECT. A paginação é um trabalho comum em aplicativos e sua implementação tem um grande impacto na experiência do cliente. Vamos examinar detalhadamente os problemas e as soluções com o Couchbase N1QL.
Markus Winand de https://use-the-index-luke.com/ argumenta que isso pode não ser o mais eficiente. Ele também sugere, quando possível, usar a abordagem de paginação por conjunto de chaves em vez da paginação OFFSET. Para este artigo, usarei as consultas de exemplo modeladas em seu artigo, https://use-the-index-luke.com/no-offset para mostrar as otimizações OFFSET que fizemos, quando e como explorar a paginação do conjunto de chaves no N1QL.
Como o Couchbase vem com um conjunto de dados de amostra de viagens, vamos usá-lo para escrever nossas consultas de paginação.
- OBTER A PRIMEIRA PÁGINA
|
1 2 3 4 5 6 7 8 9 10 |
SELECT * FROM `travel-sample` WHERE type = ‘hotel’ ORDER BY country, city OFFSET 0 LIMIT 10; CREATE INDEX ixtopic ON `travel-sample`(type); |
Para essa consulta, usando o índice ixtopic, o mecanismo de consulta é executado de forma simples. O mecanismo de consulta obtém todas as chaves qualificadas do índice, depois obtém todos os documentos, classifica com base na cláusula ORDER BY e, em seguida, elimina o número de documentos OFFSET (nesse caso, zero) e projeta o número de documentos LIMIT (nesse caso, 10).
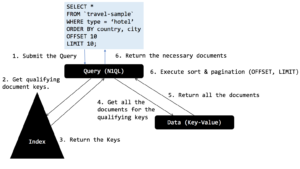
Aqui está o plano que mostra o índice e os vãos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ "index": "ixtype", "index_id": "8630f5f7e05ee113", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"hotel\"", "inclusion": 3, "low": "\"hotel\"" } |
O N1QL escolhe o ixtype do índice e coloca o filtro (type = "hotel") na varredura do índice. Para implementar a cláusula ORDER BY, ele busca todos os documentos. Na fase de classificação, reconhecemos a cláusula LIMIT 10 e tornamos a classificação eficiente, mantendo apenas os 10 principais itens.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "#operator": "Order", "limit": "10", "sort_terms": [ { "expr": "(`travel-sample`.`country`)" }, { "expr": "(`travel-sample`.`city`)" } ] }, |
Vamos dar uma olhada na eficiência do operador de varredura de índice com esse índice:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
"#operator": "IndexScan2", "#stats": { "#itemsOut": 917, "#phaseSwitches": 3671, "execTime": "2.646892ms", "kernTime": "31.095431ms", "servTime": "19.781593ms" }, … "#operator": "Fetch", "#stats": { "#itemsIn": 917, "#itemsOut": 917, "#phaseSwitches": 3787, "execTime": "3.43324ms", "kernTime": "20.847541ms", "servTime": "69.875698ms" }, … "#operator": "Order", "#stats": { "#itemsIn": 917, "#itemsOut": 10, "#phaseSwitches": 1849, "execTime": "6.519061ms", "kernTime": "88.307572ms" }, |
Houve 917 chaves de documentos retornadas pelo indexador. O mecanismo de consulta buscou 917 documentos. Em seguida, o operador de classificação (ordem) os classificou e retornou os 10 itens.
2. OBTER A SEGUNDA PÁGINA
|
1 2 3 4 5 6 7 8 |
SELECT * FROM `travel-sample` WHERE type = ‘hotel’ ORDER BY country, city OFFSET 10 LIMIT 10; |
Nesse caso, tudo é igual à consulta1, exceto:
- O operador Sort (ORDER BY) retornará 20 documentos (deslocamento + limite).
- O novo operador OFFSET será executado após o operador Order e eliminará as primeiras 10 linhas.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
"#operator": "Order", "#stats": { "#itemsIn": 917, "#itemsOut": 20, "#phaseSwitches": 1859, "execTime": "6.485904ms", "kernTime": "65.92484ms" }, { "#operator": "Offset", "#stats": { "#itemsOut": 10, "#phaseSwitches": 32, "execTime": "5.071503ms", "kernTime": "701ns", "state": "running" }, "expr": "10", "#time_normal": "00:00.0050", "#time_absolute": 0.005071503 }, |
À medida que o OFFSET aumenta, o número de documentos digitalizados pela classificação também aumenta, consumindo mais memória e CPU.
- Vamos melhorar o desempenho cobrindo o predicado e as chaves de classificação com um único índice.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE INDEX ixtypectcy ON `travel-sample`(type, country, city); Let’s execute our recent query again: SELECT * FROM `travel-sample` WHERE type = ‘hotel’ ORDER BY country, city OFFSET 10 LIMIT 10; |
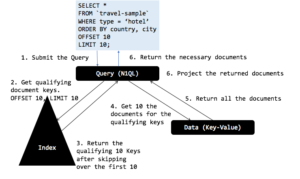
Ele usa o índice correto e cria os filtros (intervalos) corretos para a varredura do índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
{ "#operator": "IndexScan2", "index": "ixtypectcy", "index_id": "2a2ed6573354e21", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "limit": "10", "namespace": "default", "offset": "10", "spans": [ { "exact": true, "range": [ { "high": "\"hotel\"", "inclusion": 3, "low": "\"hotel\"" } ] } ], |
Vamos dar uma olhada na eficiência do operador de varredura de índice com esse índice:
|
1 2 3 4 5 6 7 8 9 10 |
"#operator": "IndexScan2", "#stats": { "#itemsOut": 10, "#phaseSwitches": 43, "execTime": "41.786µs", "kernTime": "11.15µs", "servTime": "855.759µs" }, |
Somente as 10 chaves de documento necessárias são retornadas da varredura do índice! O otimizador N1QL avalia a cláusula WHERE e a cláusula de paginação (OFFSET, LIMIT). O otimizador de consultas decide enviar a cláusula de paginação para o indexador com base na cláusula order by da consulta e na ordem da chave do índice.
Nesse caso, o predicado da consulta é: type = 'hotel'
A cláusula Order by é: ORDER BY country, city
A ordem da chave do índice é: (tipo, país, cidade)
Apenas por comparação simples, a ordem por cláusula não é exatamente igual à ordem da chave do índice. Entretanto, a chave principal do índice (type) tem um predicado de igualdade (type = 'hotel'). Portanto, o otimizador sabe que as chaves do documento projetado estarão na ordem ordenada de (país e cidade).
**e a cláusula ORDER BY para ver se ele pode enviar os parâmetros de paginação para a varredura do índice. Nesse caso, há uma correspondência perfeita.
O otimizador empurra o OFFSET e o LIMIT na paginação para a varredura de índice e a varredura de índice retorna apenas as 10 chaves de documento necessárias, independentemente do OFFSET! Portanto, a busca só precisa buscar os 10 documentos. O indexador precisa passar pela varredura de índice para avaliar as chaves.
Essa consulta foi executada em cerca de 6,81 milissegundos em meu ambiente. Vamos paginar para as páginas subsequentes para ver o desempenho:
| DESLOCAMENTO | LIMITE | Tempo de resposta |
| 10 | 10 | 6,81 ms |
| 20 | 10 | 7,17 ms |
| 100 | 10 | 7,02 ms |
| 400 | 10 | 9,54 ms |
| 800 | 10 | 9,08 ms |
Se você quiser paginar em ordem decrescente, altere a consulta e o índice para o seguinte. O agrupamento da chave no índice deve corresponder ao agrupamento na consulta. Nesse caso, tanto o país quanto a cidade estão em ordem DESCENDENTE.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DROP INDEX `travel-sample`.ixtypectcy; CREATE INDEX ixtypectcy ON `travel-sample`(type, country DESC, city DESC); SELECT country, city FROM `travel-sample` WHERE type = "hotel" ORDER BY country DESC, city DESC OFFSET 10 LIMIT 10; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`type`))", "cover ((`travel-sample`.`country`))", "cover ((`travel-sample`.`city`))", "cover ((meta(`travel-sample`).`id`))" ], "index": "ixtypectcy", "keyspace": "travel-sample", "limit": "10", "namespace": "default", "offset": "10", "spans": [ { "exact": true, "range": [ { "high": "\"hotel\"", "inclusion": 3, "low": "\"hotel\"" } ] } ], |
Vejamos agora uma consulta que não é coberta pelo índice. Na consulta que vimos anteriormente, decidimos recuperar o nome do hotel junto com o país e a cidade. O nome não está no índice.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE INDEX ixtypectcy ON `travel-sample` (type, country DESC, city DESC); SELECT country, city, name FROM `travel-sample` WHERE type = "hotel" ORDER BY country desc, city desc OFFSET 10 LIMIT 10; |
Nesse caso, novamente, o índice tem os dados para cobrir a cláusula WHERE e a cláusula ORDER BY. A varredura do índice aplicará o predicado. A ordem do índice corresponde à ordem da consulta (observação: há apenas um predicado de igualdade na chave principal. Portanto, país e cidade estão em ordem automaticamente). O índice ignora o número OFFSET de chaves qualificadas e retorna o número de chaves especificado pela cláusula LIMIT. O mecanismo recupera os documentos para manter a ordem especificada pela cláusula ORDER BY.
Todas essas pequenas otimizações juntas garantem que o desempenho da consulta seja consistente, independentemente de o OFFSET ser 10, 100 ou 1000. A única sobrecarga entre OFFSETs mais altos é a varredura do índice que ignora os itens adicionais. A avaliação e o pulo da chave do índice são significativamente mais rápidos do que a obtenção de todos os documentos e a classificação.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "#operator": "Sequence", "~children": [ { "#operator": "IndexScan2", "index": "ixtypectcy", "index_id": "b2ab2c276bba7862", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "limit": "10", "namespace": "default", "offset": "10", "spans": [ { "exact": true, "range": [ { "high": "\"hotel\"", "inclusion": 3, "low": "\"hotel\"" } ] } |
Vamos considerar uma consulta de longa duração com a possibilidade de retornar até 24 mil documentos.
create index idxtypeaiaid ON `travel-sample`(type, airline, airlineid)
Mesmo quando os predicados da consulta de paginação e o order by são completamente cobertos pelo índice, há um número limitado de casos em que o LIMIT e o OFFSET da paginação podem ser transferidos para a varredura do índice para que isso seja muito eficiente.
Aqui estão as regras e os requisitos gerais para enviar OFFSET e LIMIT para o indexador. Observe que essas regras não são exaustivas e completas, mas dão uma ideia de quando essa otimização é feita.
- A varredura da consulta deve ser feita em um único espaço-chave (referência única na cláusula FROM sem JOINs).
- DE
amostra de viagemt - DE
amostra de viagemhotel INNER JOINamostra de viagempontos de referência ON KEYS hotel.lmid
- DE
O caso (a) se qualifica, e (b) não.
- Todos os predicados da consulta são transferidos para a varredura do índice (intervalos).
- Não é possível enviar os predicados (col LIKE "%xyz") para a varredura de índice. Portanto, a paginação também não pode ser empurrada para baixo.
- Todos os predicados devem ser representados por um único intervalo. Se tivermos que fazer várias varreduras de índice, pós-processamento de varredura de índice (por exemplo, varredura de união, varredura distinta na explicação), não poderemos fazer com que o indexador avalie a paginação. A consulta será executada sem empurrar a cláusula de paginação para a varredura de índice. Aqui estão exemplos de predicados que geram um único intervalo.
- Por exemplo, (a entre 4 e 8 e a 12)
- (a = 5 OU a = 6)
- (a IN [4, 6, 9])
- Todos os predicados precisam ser exatos.
- Predicados exatos: (a = 5), (a entre 9,8 e 9,99)
- Predicados inexatos: (a > 5 e a > $param)
- A consulta não pode conter cláusulas de agregação, agrupamento e posse. Elas fazem a redução de documentos após a verificação do índice e não devem eliminar nenhum documento após a verificação do índice (nenhuma filtragem/redução pós-verificação do índice).
- As chaves ORDER BY e a ordem das chaves devem corresponder à chave do índice e à ordem da chave do índice.
- CREATE INDEX i1 ON t(a, b, c);
- SELECT * FROM t WHERE a = 1 ORDER BY a, b, c;
- SELECT * FROM t WHERE a = 1 ORDER BY b, c;
- SELECT * FROM t WHERE a > 3 ORDER BY b, c
- SELECT * FROM t WHERE a > 3 ORDER BY a, b, c
- SELECT * FROM t WHERE (a LIKE "%xyz") ORDER BY a, b, c OFFSET 10 LIMIT 5;
O caso (2) é uma correspondência perfeita do pedido.
O caso (3) não corresponde perfeitamente, mas a chave principal tem um filtro de igualdade. Portanto, sabemos que os resultados da varredura estarão na ordem de (b, c). Portanto, o pushdown de paginação para o índice é possível.
Para o caso (4), a chave principal tem um predicado de intervalo (a > 3) e, portanto, o pushdown de paginação não é possível.
Para o caso (5), há uma correspondência perfeita da cláusula ORDER BY com as chaves do índice. Portanto, podemos transferir a paginação para o indexador, mesmo que haja um predicado de intervalo na chave principal.
Para o caso (f), podemos explorar a ordem do índice, mas não podemos reduzir o OFFSET e o LIMIT porque o predicado completo não pode ser avaliado pela varredura do índice. Como obtemos os resultados na ordem exigida, depois que o número de documentos OFFSET e LIMIT é projetado, encerramos a varredura do índice.
Para simplificar, usei uma chave principal. As declarações são generalizadas e aplicáveis a várias chaves principais.
Obviamente, essa lógica do otimizador é complexa! Veja informações adicionais no apêndice sobre os requisitos.
OFFSET sobrecarga:
A amostra inicial de viagens tem cerca de 900 documentos com (type = "hotel"). Para fins de experimentação, simplesmente aumentei a quantidade de dados inserindo os mesmos dados novamente algumas vezes usando a seguinte consulta:
|
1 2 3 4 5 6 7 8 9 10 11 |
insert into `travel-sample`(key UUID(), value t) select t from `travel-sample` t ; select count(*) from `travel-sample` where type = “hotel”; { "$1": 38318 } |
Agora, vamos tentar essa consulta:
|
1 2 3 4 5 6 7 8 |
SELECT * FROM `travel-sample` WHERE type = ‘hotel’ ORDER BY country, city OFFSET 38000 LIMIT 10; |
| DESLOCAMENTO | LIMITE | Tempo de resposta |
| 38000 | 10 | 28,97 ms |
À medida que o OFFSET aumenta, a quantidade de tempo gasto pelo indexador para percorrer os itens do índice aumenta. Isso afeta a latência e a taxa de transferência.
Podemos melhorar isso? A paginação de conjunto de chaves vem em socorro. Todas as regras que mencionamos para a otimização da paginação também se aplicam aqui. Além disso, um dos predicados precisa ser UNIQUE para que possamos navegar claramente de uma página para outra sem que documentos duplicados apareçam em várias páginas. Com o Couchbase, estamos com sorte. Cada documento em um bucket tem uma chave de documento exclusiva. Ela é referenciada por META().id na consulta N1QL.
O insight básico é que os clientes normalmente querem a PRÓXIMA página em vez de uma página aleatória do início do conjunto de resultados. Portanto, quando você buscar cada página em ordem, lembre-se do último conjunto (MAIS ALTO/ MENOS ALTO, dependendo da cláusula ORDER BY). Em seguida, use essas informações para definir os predicados e posicionar o índice para a próxima varredura. Isso evitará o desperdício de processamento de chaves durante o OFFSET.
Vamos dar uma olhada em um exemplo:
CREATE INDEX ixtypectcy ON amostra de viagem (tipo, país, cidade, META().id);
- GET A PRIMEIRA PÁGINA. Observe que adicionei META().id ao índice, à projeção e à cláusula ORDER BY para garantir o valor UNIQUE em cada uma delas.
|
1 2 3 4 5 6 7 8 |
SELECT country, city, META().id FROM `travel-sample` use index (ixtypectcy) WHERE type = "hotel" ORDER BY country, city, META().id OFFSET 0 LIMIT 5; |
Resultados:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "city": "Avignon", "country": "France", "id": "000cb76b-ed85-4f56-9a6e-a6c300902944" }, { "city": "Avignon", "country": "France", "id": "0070d2ac-e411-4aeb-a1e7-4a00635d2d5a" }, { "city": "Avignon", "country": "France", "id": "01e4c1da-3749-43ce-88e3-37a00d0a376f" }, { "city": "Avignon", "country": "France", "id": "0352b5c9-fcbf-48bc-9cf8-f5760cc910a2" }, { "city": "Avignon", "country": "France", "id": "038c8a13-e1e7-4848-80ec-8819ff923602" } |
Essa consulta foi executada em 5,14 milissegundos.
- Agora, construa a consulta para a próxima página SEM usar o OFFSET:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT country, city, META().id FROM `travel-sample` use index (ixtypectcy) WHERE type = "hotel" AND country >= “France” AND city >= “Avignon” AND META().id > "038c8a13-e1e7-4848-80ec-8819ff923602" ORDER BY country, city, META().id LIMIT 5; |
Como construímos essa consulta?
- Reutilize todos os predicados na cláusula WHERE. (type = "hotel").
- Agora, pegue as chaves no ORDER BY e construa os predicados adicionais. Portanto, basta pegar o valor mais alto retornado pela última consulta e adicionar os novos predicados. Não adicione a chave do documento ainda. Nesse caso, estamos classificando em ordem crescente. Portanto, use o operador Greatherthan-OR-Equal-To.
Nesse caso, é: (country >= "France" AND city >= "Avignon").
Agora, para garantir um valor exclusivo, adicionamos o predicado META().id.
(META().id > "038c8a13-e1e7-4848-80ec-8819ff923602")
Isso é executado em 5 milissegundos com o seguinte plano. Ao percorrer as páginas subsequentes, basta repetir as etapas para construir a próxima consulta e evitar o OFFSET. Você pode continuar a percorrer todo o caminho com um tempo de resposta semelhante!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
{ "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`type`))", "cover ((`travel-sample`.`country`))", "cover ((`travel-sample`.`city`))", "cover ((meta(`travel-sample`).`id`))", "cover ((meta(`travel-sample`).`id`))" ], "index": "ixtypectcy", "index_id": "5e43ce0471785942", "index_projection": { "entry_keys": [ 0, 1, 2 ], "primary_key": true }, "keyspace": "travel-sample", "limit": "5", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"hotel\"", "inclusion": 3, "low": "\"hotel\"" }, { "inclusion": 1, "low": "\"France\"" }, { "inclusion": 1, "low": "\"Avignon\"" }, { "inclusion": 0, "low": "\"038c8a13-e1e7-4848-80ec-8819ff923602\"" } ] } ], |
RESUMO:
Você acabou de aprender como funciona a paginação. Você também aprendeu como o otimizador N1QL do Couchbase explora o índice para melhorar a eficiência do desempenho da paginação de consultas. Você pode usar as técnicas de paginação de conjunto de chaves para melhorar ainda mais o desempenho do OFFSET usando a técnica descrita.
Referências:
- https://www.couchbase.com/blog/optimizing-database-pagination-using-couchbase-n1ql/
- https://www.slideshare.net/MarkusWinand/p2d2-pagination-done-the-postgresql-way
- https://use-the-index-luke.com/sql/partial-results/fetch-next-page
- https://blog.jooq.org/2013/10/26/faster-sql-paging-with-jooq-using-the-seek-method/
Apêndice: Otimizar a consulta com ordem, deslocamento, limite para explorar a ordenação do índice
A avaliação da consulta ORDER BY pode explorar a ordem do índice com o indexador retornando os resultados na ordem necessária e a consulta não precisa modificar a ordem (por exemplo, agrupar, juntar). Sempre que a ordem do registro muda, precisamos usar dados de classificação para satisfazer a cláusula ORDER BY.
- A ordem do índice não será usada quando a cláusula from contiver agregados.
- A ordem do índice não será usada quando a cláusula GROUP BY estiver presente.
- A ordem do índice não será usada quando JOINs, NEST ou UNNEST forem usados.
- A ordem do índice não será usada quando DISTINCT estiver presente.
- A ordem do índice não será usada quando os operadores SET forem usados. Isso inclui UNION, UNION ALL, INTERSECT, EXCEPT, EXCEPTALL.
- A ordem do índice não será usada quando a varredura primária estiver envolvida.
- A ordem do índice não será usada quando a varredura de interseção ou união estiver envolvida.
- A ordem do índice não será usada quando houver índices de matriz envolvidos.
- A ordem do índice não será usada quando o agrupamento da ordem (ASC, DESC) não corresponder ao agrupamento do índice.
- A ordem de índice não será usada quando qualquer termo de ordem não corresponder às chaves de índice.
- Se a consulta explorar a ordem do índice, o operador de ordem não estará presente no EXPLAIN da consulta.
O OFFSET e o LIMIT podem ser enviados para o IndexScan
- quando o ORDER BY está presente e é capaz de explorar a ordem do índice
- Quando a consulta ORDER BY não está presente
- Todos os predicados são enviados ao indexador como parte dos intervalos
- Os valores dos intervalos empurrados são exatos
- Com base em intervalos, o Indexador não gera falsos positivos
- A consulta não reduz ainda mais os resultados da varredura de índice.
- Se o OFFSET for pressionado para o indexador, "offset" aparecerá na seção IndexScan do EXPLAIN e o Offset Operator não estará presente no final do EXPLAIN.
- Se o limite for enviado ao indexador, "limit" aparecerá na seção IndexScan do EXPLAIN.
Olá, Keshav, estou implementando a paginação do cursor no couchbase, então pensei em dar uma olhada nesta publicação, mas implementei de forma diferente da sua e gostaria de saber se perdi alguma coisa.
No exemplo que você usou no final:
SELECT país, cidade, META().id
DE
amostra de viagemíndice de uso (ixtypectcy)WHERE type = "hotel"
E país >= "França"
E cidade >= "Avignon"
AND META().id > "038c8a13-e1e7-4848-80ec-8819ff923602"
ORDER BY country, city, META().id
LIMITE 5;
Parece que muitos registros foram ignorados, pois você filtra por META().id > "038c8a13-e1e7-4848-80ec-8819ff923602"; no entanto, é possível ter registros que se aplicam a country >= "France"
AND city >= "Avignon" com id menor que "038c8a13-e1e7-4848-80ec-8819ff923602"