Serviços de IA da Capella junto com a NVIDIA AI Enterprise
O Couchbase está trabalhando com a NVIDIA para ajudar as empresas a acelerar o desenvolvimento de aplicativos de IA agêntica, adicionando suporte para NVIDIA AI Enterprise incluindo suas ferramentas de desenvolvimento, Estrutura de modelos neurais (NeMo) e Microsserviços de inferência da NVIDIA (NIM). A Capella adiciona suporte para NIM em seu Serviços de modelo de IA e adiciona acesso ao NVIDIA NeMo Framework para criar, treinar e ajustar modelos de linguagem personalizados. O framework suporta curadoria de dados, treinamento, personalização de modelos e fluxos de trabalho RAG para empresas.
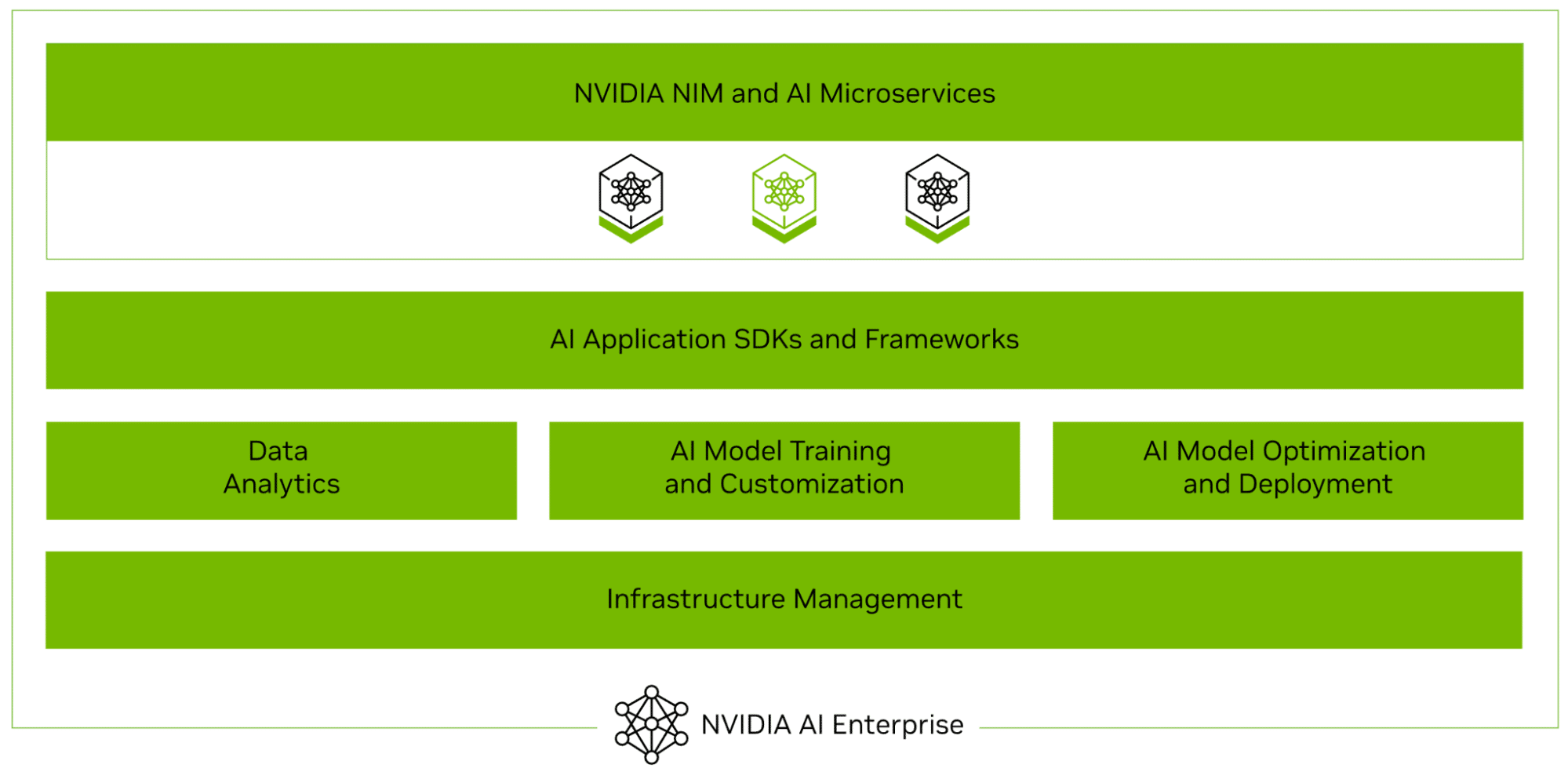
Os Serviços de IA da Capella com o NVIDIA AI Enterprise suportam todo o ciclo de vida da entrega autêntica
Diferentemente dos bancos de dados que suportam exclusivamente a pesquisa de vetores sem fornecer assistência para a criação e a utilização deles, o Couchbase Capella gerencia dados operacionais, analíticos, de IA e móveis, além de simplificar a utilização desses dados para fluxos de trabalho de IA.na mesma plataforma.
Esses fluxos de trabalho de dados de IA são onde a complexidade mudou para os desenvolvedores, pois eles incluem:
-
- preparação de dados
- vetorização
- engenharia imediata e armazenamento em cache
- interações de modelos, incluindo interações no dispositivo
- cache de resposta
- armazenamento de transcrições
- validação de resposta
- gerenciamento de grades de proteção

- governança de agentes

A solução combinada aprimora, mas simplifica os recursos de geração aumentada por recuperação (RAG) da Capella, permitindo que os clientes alimentem com eficiência aplicativos de IA de alto rendimento, mantendo a flexibilidade do modelo. Com o acesso à estrutura NeMo, os desenvolvedores obtêm uma grande variedade de ferramentas e modelos de produtividade em um único ambiente.
Assim, eles têm acesso a mais de 30 modelos do BigCode, Microsoft, NVIDIA, Mistral, Meta e Google via NIM. Com o NVIDIA AI Enterprise, os desenvolvedores podem criar, treinar e ajustar modelos para aplicativos específicos e, em seguida, aproveitar os benefícios da aceleração habilitada para GPU na implantação.
As empresas estão tendo dificuldades para confiar na IA por vários motivos
As organizações que criam e implantam aplicativos de IA de alto rendimento enfrentam desafios para garantir a confiabilidade e a conformidade do agente e evitar que ele se desvie do caminho operacional pretendido. Esse desvio ocorre por vários motivos além dos óbvios, como vazamentos de dados de PII ou alucinações baseadas em modelos. O desvio pode ocorrer ao longo do tempo, pois os modelos podem simplesmente mudar sua opinião e, portanto, suas respostas e conclusões, com base na evolução de seu treinamento, bem como na evolução dos dados contidos em seus prompts.
Além disso, os modelos muitas vezes mantêm, por engano, um contexto de conversação que não é mais válido em uma conversa ativa. A Capella e a NVIDIA AI Enterprise podem ajudar os desenvolvedores a criar grades de proteção mais rígidas e agentes mais intencionais que se desviam com menos frequência, mantêm o contexto adequado ao longo do tempo e, portanto, funcionam como seus autores esperavam. Por exemplo, as transcrições das conversas dos agentes devem ser capturadas e comparadas em tempo real no NIM para avaliar a precisão da resposta do modelo.
IA segura sem comprometimento
Nossa solução conjunta oferece uma maneira segura e rápida para as organizações criarem, implantarem e desenvolverem aplicativos com tecnologia de AI. A solução da NVIDIA aproveita LLMs e ferramentas pré-testadas, incluindo Guardrails do NVIDIA NeMo para ajudar as organizações a acelerar o desenvolvimento de IA e, ao mesmo tempo, aplicar políticas e proteções contra alucinações de IA, enquanto a Capella ajuda a manter a memória de curto e longo prazo da IA por meio de armazenamento em cache e transcrição, enquanto seu desempenho e proximidade com os modelos e a infraestrutura de execução reduzem as latências de conversação, o que é fundamental para a implantação do agente. A execução nos microsserviços NIM da NVIDIA, rigorosamente testados e prontos para produção, permite que as empresas atendam aos requisitos de privacidade, desempenho, escalabilidade e latência com seus aplicativos agênticos.
Um benefício final
Matt McDonough, nosso vice-presidente sênior de produtos e parceiros, destaca o valor de nossa colaboração:
As empresas precisam de uma plataforma de dados unificada e de alto desempenho para sustentar seus esforços de IA e dar suporte a todo o ciclo de vida do aplicativo, desde o desenvolvimento até a implantação e a otimização. Ao integrar os microsserviços NVIDIA NIM aos Capella AI Model Services, estamos oferecendo aos clientes a flexibilidade de executar seus modelos de IA preferidos de forma segura e governada, ao mesmo tempo em que proporcionamos melhor desempenho para cargas de trabalho de IA e integração perfeita de IA com dados transacionais, analíticos, de IA e móveis. Os Capella AI Services permitem que os clientes acelerem seus aplicativos RAG e agênticos com confiança, sabendo que podem dimensionar e otimizar seus aplicativos à medida que as necessidades de negócios evoluem.
Essa solução combinada NVIDIA/Couchbase não apenas ajuda os desenvolvedores a implantar, dimensionar e otimizar aplicativos agênticos com mais rapidez e segurança, mas também ajuda o DevOps a acelerar e gerenciar o AgentOps - a implantação de agentes juntamente com modelos otimizados, desempenho de baixa latência, segurança corporativa, governança, observabilidade e segurança. E para os líderes de projeto e detentores de orçamento, nossa solução combinada permite que suas organizações maximizem o ROI desses investimentos em IA, combinando as vantagens de desempenho e consolidação de dados da Capella com a proximidade do ambiente NVIDIA AI Enterprise, tudo isso enquanto operam na infraestrutura acelerada da NVIDIA. Talvez não exista uma combinação melhor para maximizar o ROI da inteligência artificial.
Veja-nos na Conferência de Tecnologia de GPU da NVIDIA

Saiba mais sobre Serviços de IA da Capella e inscreva-se no visualização privada.
Recursos adicionais
-
- Leia mais sobre como essa integração acelera o desenvolvimento de aplicativos de IA agêntica
- Saiba como Os serviços de IA da Capella capacitam os desenvolvedores a criar aplicativos agênticos
- Explorar Guardrails do NVIDIA NeMo
- Usar com segurança LLMs com propriedade Dados empresariais no NVIDIA NeMo