Novos recursos de consulta aparecem com destaque na versão mais recente do Couchbase Server 5.5. Confira o anúncio e faça o download da versão gratuita agora mesmo.
Nesta postagem, quero destacar alguns dos novos recursos e mostrar a você como começar a usá-los:
- ANSI JOINs - O N1QL no Couchbase já tem JOIN, mas agora o JOIN é mais compatível com os padrões e mais flexível.
- Uniões HASH - O desempenho em determinados tipos de uniões pode ser aprimorado com uma união HASH (somente na Enterprise Edition)
- Agregação de pushdowns - GROUP BY pode ser transferido para o indexador, melhorando o desempenho da agregação (somente na Enterprise Edition)
Todos os exemplos nesta postagem usam o bucket "travel-sample" que vem com o Couchbase.
ANSI JOINs
Até o Couchbase Server 5.5, os JOINs eram possíveis, com duas ressalvas:
- Um lado do JOIN deve ser a(s) chave(s) do documento
- Você deve usar o
SOBRE AS CHAVESsintaxe
No Couchbase Server 5.5, não é mais necessário usar o SOBRE AS CHAVESe, assim, escrever uniões se torna muito mais natural e mais alinhado com outros dialetos SQL.
Sintaxe JOIN anterior
Por exemplo, aqui está a sintaxe antiga:
|
1 2 3 4 5 6 7 |
SELECT r.destinationairport, r.sourceairport, r.distance, r.airlineid, a.name FROM `travel-sample` r JOIN `travel-sample` a ON KEYS r.airlineid WHERE r.type = 'route' AND r.sourceairport = 'CMH' ORDER BY r.distance DESC LIMIT 10; |
Isso obterá 10 rotas que começam no aeroporto CMH, juntamente com seus documentos de companhia aérea correspondentes. Os resultados estão abaixo (estou mostrando-os na exibição de tabela, mas ainda é JSON):
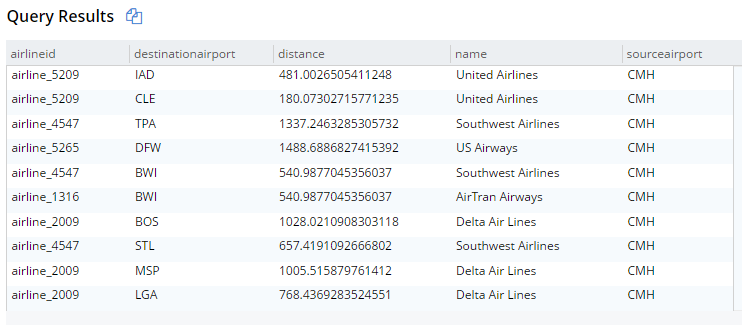
Nova sintaxe JOIN
E aqui está a nova sintaxe fazendo a mesma coisa:
|
1 2 3 4 5 6 7 |
SELECT r.destinationairport, r.sourceairport, r.distance, r.airlineid, a.name FROM `travel-sample` r JOIN `travel-sample` a ON META(a).id = r.airlineid WHERE r.type = 'route' AND r.sourceairport = 'CMH' ORDER BY r.distance DESC LIMIT 10; |
A única diferença é a ON. Em vez de SOBRE AS CHAVES, agora é ON =. É mais natural para quem vem de um histórico relacional (como eu).
Mas isso não é tudo. Agora você não está mais limitado a participar apenas de chaves de documentos. Aqui está um exemplo de um JUNTAR em um campo da cidade.
|
1 2 3 4 5 6 |
SELECT a.airportname, a.city AS airportCity, h.name AS hotelName, h.city AS hotelCity, h.address AS hotelAddress FROM `travel-sample` a INNER JOIN `travel-sample` h ON h.city = a.city WHERE a.type = 'airport' AND h.type = 'hotel' LIMIT 10; |
Essa consulta mostrará os hotéis que correspondem aos aeroportos com base em sua cidade.
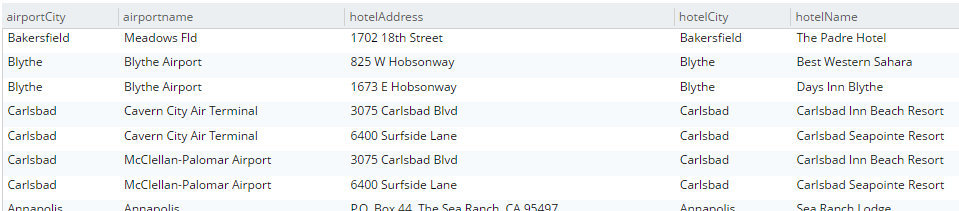
Observe que, para que isso funcione, você deve ter um índice criado no campo que está no lado interno do JOIN. O bucket "travel-sample" já contém um índice predefinido no campo city (cidade). Se eu tentasse fazer isso com outros campos, receberia uma mensagem de erro como "Nenhum índice disponível para o termo de união ANSI...".
Para obter mais informações sobre o ANSI JOIN, consulte o Documentação completa do N1QL JOIN.
Observação: a sintaxe antiga de JOIN, ON KEYS ainda funcionará, portanto, não se preocupe em ter que atualizar seu código antigo.
Junções de hash
Por baixo dos panos, há diferentes maneiras de realizar as uniões. Se você executar a consulta acima, o Couchbase usará um Loop aninhado (NL) para executar a união. No entanto, você também pode instruir o Couchbase a usar um junção de hash em vez disso. Às vezes, uma junção de hash pode ter mais desempenho do que um loop aninhado. Além disso, uma junção de hash não depende de um índice. No entanto, ela depende de a junção ser apenas uma junção de igualdade.
Por exemplo, em "travel-sample", eu poderia unir pontos de referência a hotéis em seus campos de e-mail. Talvez essa não seja a melhor maneira de descobrir se um hotel é um ponto de referência, mas como o e-mail não é indexado por padrão, isso ilustra o ponto.
|
1 2 3 4 5 |
SELECT l.name AS landmarkName, h.name AS hotelName, l.email AS landmarkEmail, h.email AS hotelEmail FROM `travel-sample` l INNER JOIN `travel-sample` h ON h.email = l.email WHERE l.type = 'landmark' AND h.type = 'hotel'; |
A consulta acima levará muito tempo para ser executada e, provavelmente, será encerrada.
Sintaxe
Em seguida, tentarei uma junção de hash, que deve ser explicitamente invocada com um USE HASH dica.
|
1 2 3 4 5 |
SELECT l.name AS landmarkName, h.name AS hotelName, l.email AS landmarkEmail, h.email AS hotelEmail FROM `travel-sample` l INNER JOIN `travel-sample` h USE HASH(BUILD) ON h.email = l.email WHERE l.type = 'landmark' AND h.type = 'hotel'; |
Uma junção de hash tem dois lados: um CONSTRUIR e um SONDA. O CONSTRUIR do lado da união será usado para criar uma tabela de hash na memória. A tabela SONDA usará essa tabela para encontrar correspondências e realizar a união. Normalmente, isso significa que você deseja que a tabela CONSTRUIR a ser usado no menor dos dois conjuntos. No entanto, você só pode fornecer uma dica de hash, e somente para o lado direito da união. Portanto, se você especificar CONSTRUIR no lado direito, então você está implicitamente usando SONDA no lado esquerdo (e vice-versa).
CONSTRUIR e PROVAR
Então, por que eu usei HASH(BUILD)?
Sei que, por usar INFER e/ou Insights sobre o balde que os pontos de referência representam aproximadamente 10% dos dados, e os hotéis representam aproximadamente 3%. Além disso, sei, só de experimentar, que HASH(BUILD) foi um pouco mais lento. Mas, em ambos os casos, o tempo de execução da consulta foi de milissegundos. Acontece que há dois pares de hotel-landmark com o mesmo endereço de e-mail.
USE HASH dirá ao Couchbase para tentativa uma junção de hash. Se não for possível fazer isso (ou se você estiver usando o Couchbase Server Community Edition), ele voltará para um loop aninhado. (A propósito, você pode especificar explicitamente o loop aninhado com a opção USO NL mas atualmente não há motivo para isso).
Para obter mais informações, consulte o Junção de HASH áreas da documentação.
Flexões agregadas
No passado, as agregações eram complicadas quando se tratava de desempenho. Com o Couchbase Server 5.5, flexões agregadas agora são suportados para SUM, COUNT, MIN, MAX e AVG.
Nas versões anteriores do Couchbase, a indexação não era usada para declarações que envolviam GRUPO POR. Isso pode afetar gravemente o desempenho, pois há uma etapa extra de "agrupamento" que precisa ser realizada. No Couchbase Server 5.5, o serviço de índice pode fazer o agrupamento/agregação.
Exemplo
Aqui está um exemplo de consulta que encontra o número total de hotéis e os agrupa por país, estado e cidade.
|
1 2 3 4 5 |
SELECT country, state, city, COUNT(1) AS total FROM `travel-sample` WHERE type = 'hotel' and country is not null GROUP BY country, state, city ORDER BY COUNT(1) DESC; |
A consulta será executada e retornará como resultado:
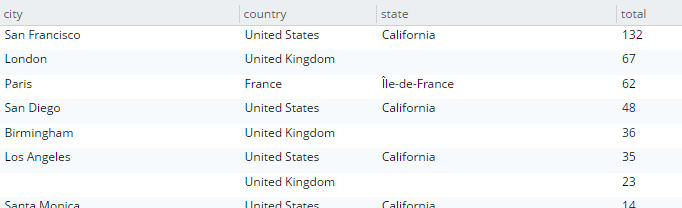
Vamos dar uma olhada no plano de consulta visual (disponível apenas na Enterprise Edition, mas você pode visualizar o texto bruto do plano na Community Edition).

Observe que o único índice que está sendo usado é o tipo campo. A etapa de agrupamento está fazendo o trabalho de agregação. Com o conjunto de dados de amostra de viagem relativamente pequeno, essa consulta está levando cerca de 90 ms em meu desktop de nó único. Mas vamos ver o que acontece se eu adicionar um índice aos campos pelos quais estou agrupando:
Indexação
|
1 |
CREATE INDEX ix_hotelregions ON `travel-sample` (country, state, city) WHERE type='hotel'; |
Agora, execute o comando acima SELECIONAR novamente. Ela deve retornar os mesmos resultados. Mas:
- Agora está levando cerca de 7 ms em meu desktop de nó único. Estamos usando ms, mas com um conjunto de dados grande e mais realista, essa é uma enorme diferença de magnitude.
- O plano de consulta é diferente.

Observe que, desta vez, não há nenhuma etapa de "grupo". Todo o trabalho está sendo transferido para o serviço de índice, que pode usar o ix_hotelregions índice. Ele pode usar esse índice porque minha consulta está correspondendo exatamente aos campos do índice.
O push down do índice nem sempre acontece: sua consulta precisa atender a condições específicas. Para obter mais informações, consulte a seção GROUP BY e desempenho agregado áreas da documentação.
Resumo
Com Servidor Couchbase 5.5O N1QL inclui ainda mais sintaxe compatível com os padrões e está mais eficiente do que nunca.
Experimente o N1QL hoje mesmo. Você pode instalar o Enterprise Edition ou experimente o N1QL diretamente em seu navegador.
Tem alguma pergunta para mim? Estou à disposição Twitter @mgroves. Você também pode dar uma olhada em @N1QL no Twitter. O Fórum N1QL é um bom lugar para ir se você tiver perguntas aprofundadas sobre o N1QL.
Obrigado por esse registro.
Agradeceria se você pudesse me ajudar a entender alguns pontos:
1. Uma junção HASH deve ser sempre instruída, ou seja, o otimizador nunca escolherá uma junção HASH por conta própria? Isso se deve ao fato de o otimizador ser baseado em regras? Em caso afirmativo, o otimizador baseado em custo futuro escolhe uma união HASH em vez de uma união NL se achar que o custo é menor?
2. Uma união HASH precisará de memória para manter a tabela de hash na memória. Essa memória será usada em qual nó: o nó que executa o serviço Data, o serviço Index ou o serviço Query?
Oi Purav,
Talvez você queira fazer essas perguntas em https://www.couchbase.com/forums/c/sql/16 - 1) Sim, ele precisa ser instruído. Não conheço muitos detalhes específicos sobre o otimizador e as uniões HASH/NL. 2) Não tenho certeza se é o índice ou a consulta, mas não será o serviço de dados.
Obrigado, Matthew. Agradeço a pronta reversão. Faremos isso.