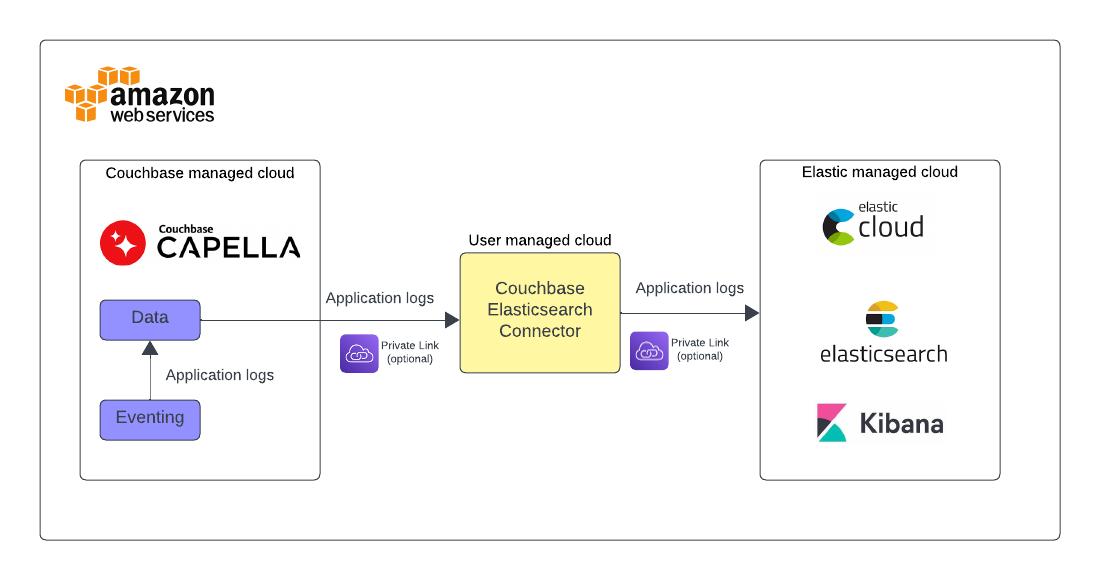
Nesta postagem do blog, mostraremos como usar o Couchbase Capella em conjunto com o ElasticSearch e os serviços do AWS para envio e análise eficientes de logs de aplicativos de eventos.
Couchbase Capella é uma plataforma de dados em nuvem NoSQL de vários modelos. Ela oferece resposta de dados em milissegundos em escala, com o melhor preço-desempenho de qualquer banco de dados como serviço de documentos. Capella Serviço de eventosO Capella® , permite que a lógica comercial definida pelo usuário seja acionada em tempo real quando houver alterações nos dados do Capella. Os casos de uso típicos incluem enriquecimento de documentos, exclusões em cascata, propagação de alterações de dados em um banco de dados e muito mais.
O Elastic Stack (também conhecido como ELK Stack) oferece uma solução avançada de registro centralizado para criar insights, definir alertas com base em KPIs e acompanhar o comportamento dos aplicativos.
As funções do Capella Eventing são fáceis de criar usando o editor Data Tools Eventing na interface do usuário. Os logs de aplicativos de eventos permitem que os usuários identifiquem e capturem várias atividades e erros relacionados à lógica comercial por meio de mensagens definidas pelo usuário específicas para cada função de eventos. Embora os logs de aplicativos possam ser visualizados na interface do usuário do Capella, o gerenciamento e a análise centralizados de logs usando soluções especializadas de logs podem ser úteis em muitos cenários. Este blog mostra instruções passo a passo sobre como trazer os logs de aplicação do Eventing para a Elastic e ajudar com o armazenamento e a análise centralizados de logs.
Pré-requisito
-
- Implantação do Couchbase Capella com serviços de dados e eventos. Registrar-se para uma conta de avaliação.
- Implantação do ElasticSearch Cloud. Registrar-se para uma conta de avaliação.
- Conta AWS com uma instância do EC2 para executar Conector do Couchbase ElasticSearch que pode ser baixado aqui.
Visão geral das etapas necessárias
Configuração do cluster Capella: Comece criando um Capella Cluster com serviços de dados e eventos. Um guia rápido pode ser encontrado em Documentação do Couchbase Capella.
Criação de balde/escopo/coleção: Crie os buckets, escopos e coleções necessários no Couchbase. Isso inclui "data", "eventing-logs" e seus respectivos escopos e coleções.
Preparação para funções de eventos: Preparar as funções de eventos para a população e transformação de dados. Isso envolve a criação de conjuntos de dados sintéticos e sua modificação para criar registros.
Criação de cluster e índice do ElasticSearch: Configure seu cluster do ElasticSearch e crie um índice para o manuseio eficiente dos dados.
Configuração de VPC e link privado: Crie uma nova VPC para o Elastic Connector e estabeleça um link privado do Couchbase Capella para a VPC.
Filtro de tráfego do ElasticSearch: Implementar filtragem de tráfego para transferência segura de dados.
Instalar e executar o conector ElasticSearch do Couchbase: Instale o Conector ElasticSearch do Couchbase em um computador EC2 e configure-o para envio de logs.
Visualização e análise de dados: Use a fonte de dados coletados para visualizar e analisar os registros, explorando os insights que eles fornecem.
Configuração detalhada
Ambiente do Couchbase
Precisamos criar dois buckets, seus escopos e coleções. Em um lado, criaremos tudo o que precisamos para gerenciar dados e funções de eventos. No outro, criaremos um segundo dedicado aos logs gerados pelas funções de eventos.
Os fundamentos dessa atividade simples podem ser encontrados no site Documentação do Couchbase Capella que ilustra os princípios e as ações envolvidas. Observe que a criação do bucket envolve a configuração de várias definições, das quais a mais proeminente é a cota de memória. Para fins de teste, você pode escolher 100 MB; caso contrário, um avaliação precisa será necessário.
Crie dois buckets com a seguinte estrutura:
-
- Nome: "dados"
- Nome do escopo: "eventos"
- Nome da coleção: "meta"
Armazenamento para pontos de verificação de funções de eventos
- Nome da coleção: "meta"
- Nome do escopo: "inventário"
- Nome da coleção: "dados"
Armazenamento de dados reais
- Nome da coleção: "dados"
- Nome do escopo: "eventos"
- Nome: "registros de eventos"
- Nome do escopo: "eventos"
- Nome da coleção: "registros"
Armazenamento para registros. Opcionalmente, podemos definir um TTL para reduzir a quantidade de armazenamento.
- Nome da coleção: "registros"
- Nome do escopo: "pontos de controle elásticos"
- Nome da coleção: "conector"
Armazenamento para pontos de verificação do Conector Couchbase-Elasticsearch
- Nome da coleção: "conector"
- Nome do escopo: "eventos"
- Nome: "dados"
População de dados
Agora, criaremos duas funções de eventos. Se esta é a primeira vez que você cria uma função de evento, pode se familiarizar com o ambiente seguindo este guia.
O objetivo dessas funções é:
-
- Primeira funçãoCriar dados nos quais podemos trabalhar. Um conjunto de dados que representa um catálogo de produtos.
Essa função cria documentos json simples, introduzindo alguma variabilidade em 100.000 iterações. Embora esse não seja um catálogo de produtos realista, ele estabelece uma boa base para experimentar funções de eventos que precisam registrar o desempenho. Observe que a função é acionada pela primeira vez ao criar um documento vazio. - Segunda funçãoFunção de eventos: a função de eventos real com alguma lógica comercial que gostaríamos de observar por meio da pilha ELK.
- Primeira funçãoCriar dados nos quais podemos trabalhar. Um conjunto de dados que representa um catálogo de produtos.
Enquanto a função de eventos é executada sem limites em todo o novo conjunto de dados, ela substitui a propriedade categoria sempre que corresponder ao valor "Categoria 3" e altera esse valor para "jeans". Em várias partes da função, podemos observar que ela é convenientemente chamada de uma função chamada logStuff: Sua finalidade é salvar uma linha de log em uma coleção dedicada que será posteriormente replicada para o ElasticSearch e indexada.
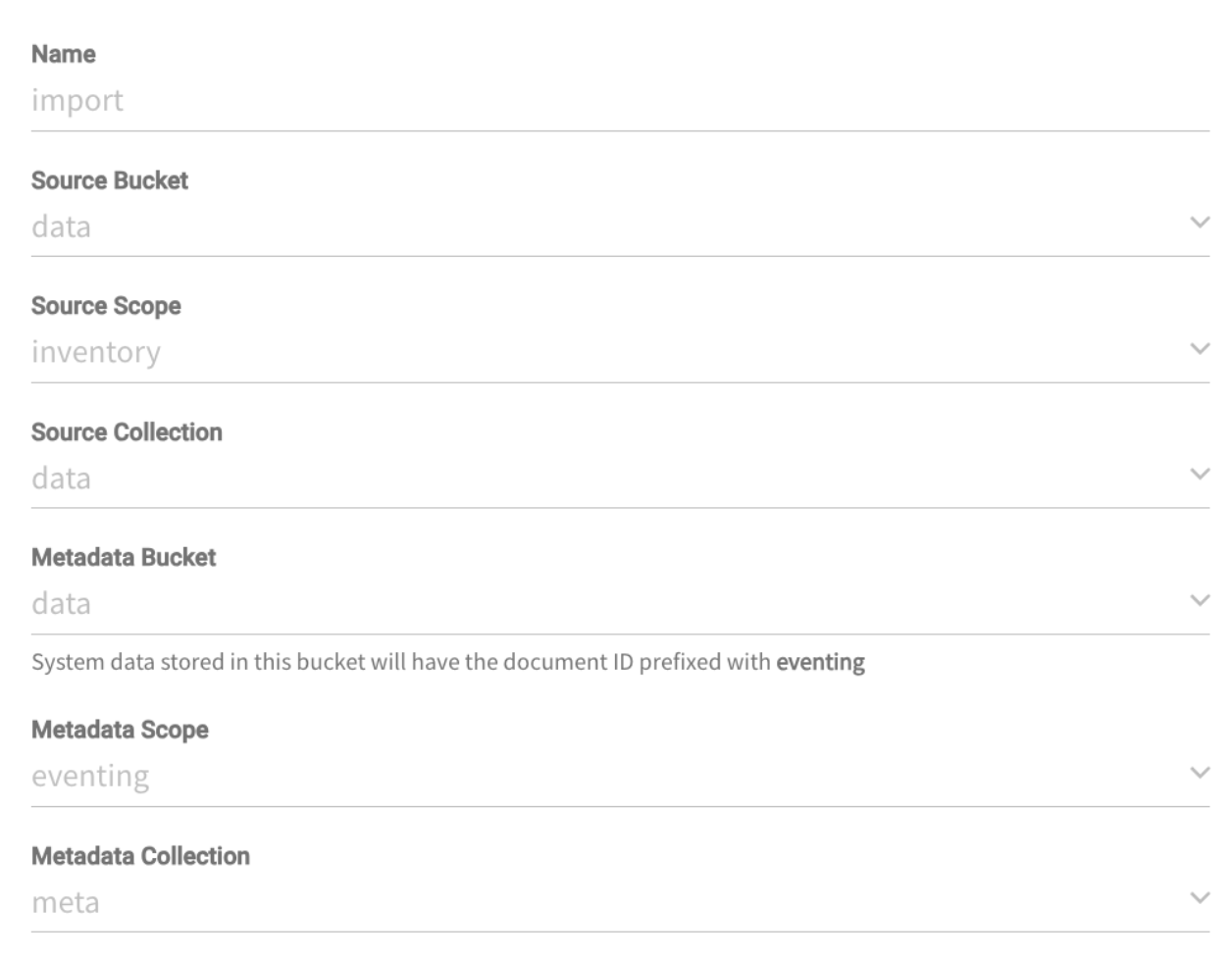
Função de população de dados
Crie uma função de eventos com as seguintes configurações:
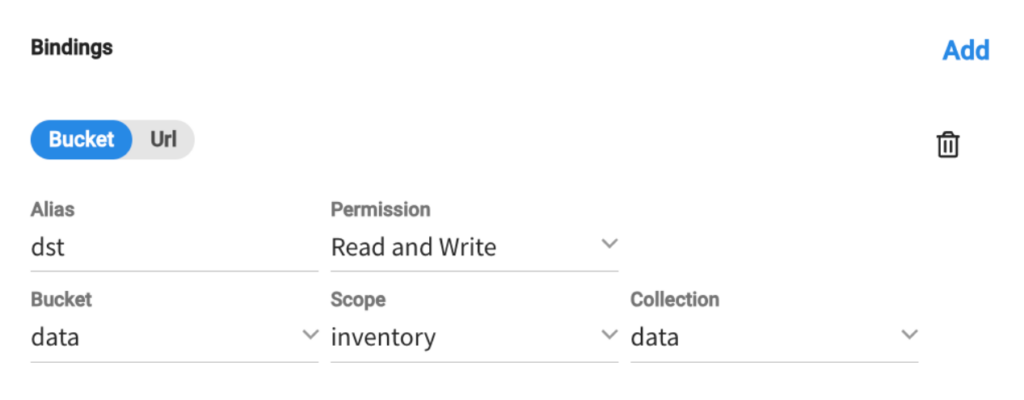
E a seguinte amarração de balde:
Aqui está a função:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
function OnUpdate(doc, meta) { // Placeholder function for handling document updates if(meta.id == 'start') { for(let i = 1; i <= 100000; i++) { var item = { "type": "inventoryItem", "itemId": i, "name": "Item " + i, "price": Math.random() * 100, // Random price between 0 and 100 "inStock": true, "category": "Category " + (i % 10) // 10 different categories }; var key = "item_" + i; dst[key] = item; } } } function OnDelete(meta) { // Placeholder function for handling document deletions } |
No momento em que a função obtém um documento em dados.inventário.dados com a ID iniciarele gerará 100.000 documentos aleatórios.
Observação: para gerar esse documento, você só precisa acessar o Ferramentas de dados selecione Documentos e, em seguida, clique no botão Criar novo documento (lembre-se de selecionar a coleção correta! Dados -> Inventário -> Dados).
Função de transformação de dados
Essa segunda função demonstrará como manter os registros no armazenamento temporário para serem usados posteriormente no ELK Stack. Enquanto executa sua lógica comercial no dados.inventário.dados ele salvará alguns registros de aplicativos no eventing-logs.eventing.logs para que ele possa exportá-los posteriormente para o ElasticSearch.
A configuração:
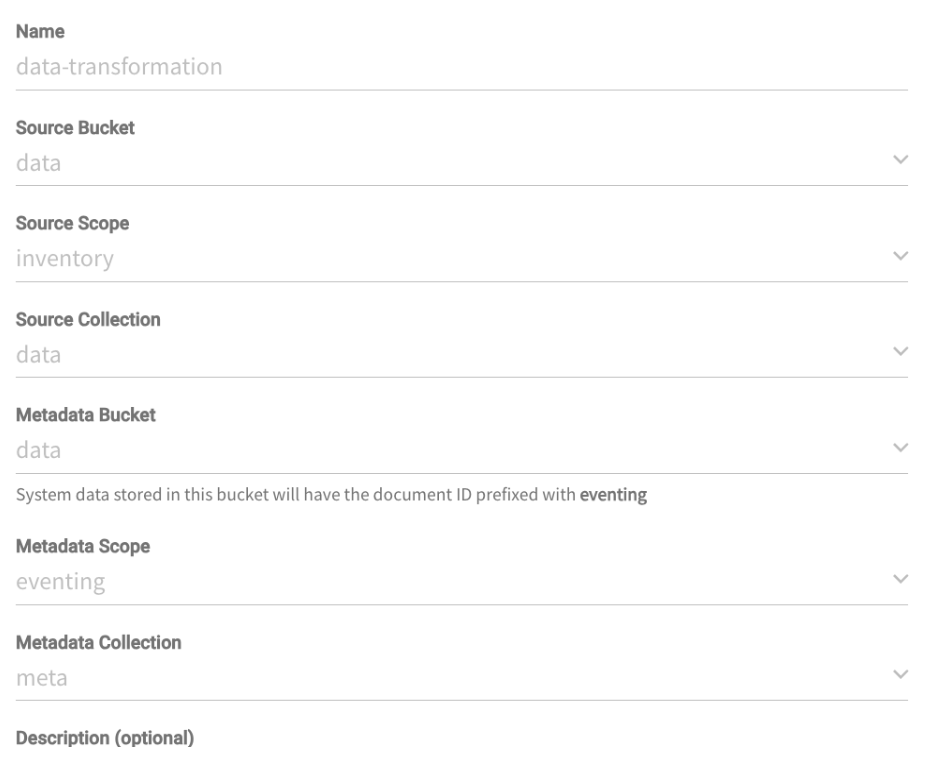
As encadernações:
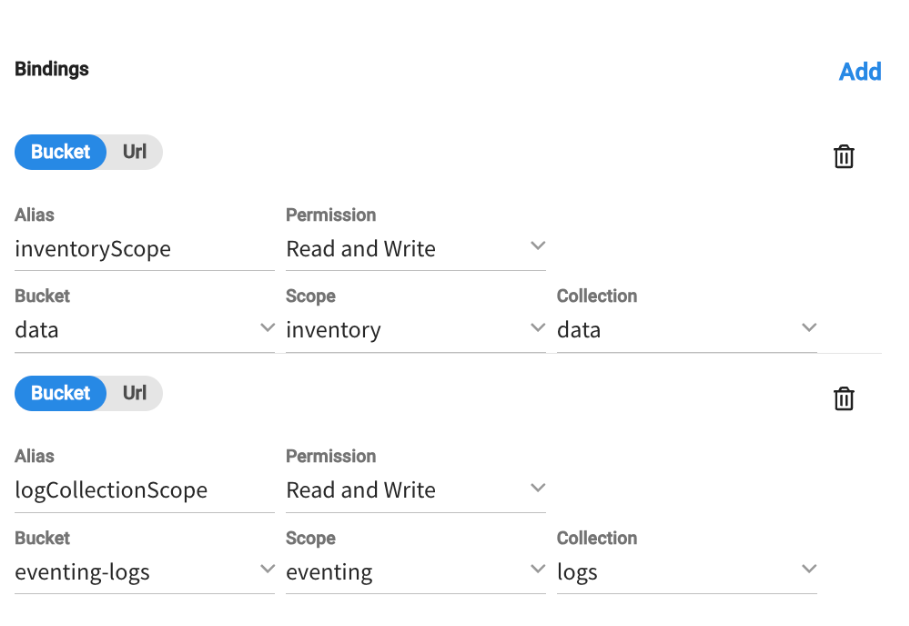
A função:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
function OnUpdate(doc, meta) { logStuff("debug", "start evaluating " + meta.id); if(doc.category == "Category 3") { logStuff("info", "start modifying " + meta.id); doc.category = "jeans"; inventoryScope[meta.id] = doc; logStuff("info", "end modifying " + meta.id); } logStuff("debug", "end evaluating " + meta.id); } function OnDelete(meta, options) { } function simpleHash(str) { let hash = 0; for (let i = 0; i < str.length; i++) { const char = str.charCodeAt(i); hash = (hash << 5) - hash + char; hash &= hash; // Convert to 32bit integer } return new Uint32Array([hash])[0].toString(36); } function logStuff(level, message) { var date = new Date(); date.toISOString(); var logLine = { "@timestamp": date, "log": { "level": level, "logger": "couchbase.eventing", "origin": { "function": "data-transformation-cat-3-to-tee" }, "original": message }, "message": message, "ecs": { "version": "1.6.0" } } var logEntryId = "data-transformation-" + Math.floor(Math.random() * 10000000) + date; logCollectionScope[simpleHash(logEntryId)] = logLine; } |
A função é responsável por modificar uma determinada categoria de dados e transformar seu rótulo. Ao fazer isso, precisamos acompanhar o desempenho da função por meio de logs que serão analisados posteriormente com a pilha ELK.
O logStuff cria um documento JSON com um formato compatível com o ECS e o persiste em um bucket separado.
Depois que a função de eventos for criada, lembre-se de implantação isso.
Depois que o conjunto de dados for criado e a função de transformação for executada, deveremos ter um bucket preenchido de logs pronto para ser enviado ao ElasticSearch.
Observação: para evitar colisões, as linhas de registros são criadas com carimbos de data e hora e números aleatórios, que são posteriormente transformados em hash para economizar espaço.
Configuração do Elastic Cloud
Antes de começar a sincronizar os dados, precisamos criar um índice no ElasticSearch. Certifique-se de modificar a variável Elasticsearch URL do ponto de extremidade e para criar um Chave da API com direitos administrativos.
Aqui está um exemplo de CURL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
curl -X PUT "https://<your ElasticSearch endpoint here>:443/couchbase-ecs" \ -H "Authorization: ApiKey "<your API key>"" \ -H "Content-Type: application/json" \ -d ' { "settings": { "number_of_shards": 1, "number_of_replicas": 1 }, "mappings": { "properties": { "@timestamp": { "type": "date" }, "log": { "properties": { "level": { "type": "keyword" }, "logger": { "type": "keyword" }, "origin": { "properties": { "function": { "type": "keyword" } } }, "original": { "type": "text" } } }, "message": { "type": "text" }, "ecs": { "properties": { "version": { "type": "keyword" } } } } } }' |
O índice mapeia o tipo de dados do registrador para que ele possa ser pesquisado com eficiência.
Conector ElasticSearch
Configuração de rede
Precisamos criar uma VPC com uma máquina EC2 com um endereço IP público que hospedará o conector do ElasticSearch. Uma instância normal do EC2 com 2 a 4 cpus fará o trabalho para este teste (usamos um t2.medium). Obviamente, se esse for um ambiente de produção, uma avaliação do dimensionamento dessa máquina seria uma etapa importante para essa implantação.
A próxima etapa é proteger a conectividade entre a VPC recém-criada e:
-
- Couchbase Capella e
- Elastic Cloud
A maneira mais prática (apenas para fins de teste!) é por meio da conectividade pública. Nas configurações do cluster do Capella, precisamos colocar na lista de permissões o IP público da instância do EC2 para que o Elasticsearch Connector possa estabelecer uma conexão com o banco de dados. Para o Elastic Cloud, em vez disso, precisamos criar um Chave da API.
Há também a alternativa de usar links privados e uma extensa documentação pode ser encontrada aqui:
Conector Couchbase-ElasticSearch
Depois de provisionar a instância do EC2, precisamos fazer o download dos executáveis do site do Couchbase. Antes disso, dê uma olhada nos requisitos, aqui e faça o download aqui.
Agora precisamos configurá-lo, modificando o $CBES_HOME/config/default-connector.toml arquivo.
Aqui estão algumas seções que lhe chamarão a atenção, e algumas seções foram removidas para manter o texto breve:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
[group] name = 'example-group' [group.static] memberNumber = 1 # A value from 1 to 'totalMembers', inclusive. totalMembers = 1 [...] [couchbase] hosts = ['<your Capella private endpoint>'] network = 'auto' bucket = 'eventing-logs' metadataBucket = 'eventing-logs' metadataCollection = 'elastic-checkpoints.connector' # your Capella username username = 'hello' # Remember to go to modify this file with the password pathToPassword = 'secrets/couchbase-password.toml' #Capella environment is always secured secureConnection = true [...] [elasticsearch] hosts = ['https://<your ElasticSearch endpoint here>:443'] username = 'elastic' # Remember to go to modify this file with your ElasticSearch ApiKey pathToPassword = 'secrets/elasticsearch-password.toml' secureConnection = true [...] [elasticsearch.elasticCloud] enabled = true [...] # If true, never delete matching documents from Elasticsearch. ignoreDeletes = true [[elasticsearch.type]] matchOnQualifiedKey = true prefix = 'eventing.logs.' index = 'couchbase-ecs' [...] |
Práticas recomendadas e dicas
Aqui estão algumas coisas que podem ser úteis para se ter em mente:
-
- Conector do Couchbase ElasticSearch - Certifique-se de que seu tipo de dados esteja correto, [[elasticsearch.type]]. Seu conector não alimentará os dados a menos que isso seja feito corretamente.
- Couchbase Capella - Não se esqueça de criar as credenciais do banco de dados para o Conector!
- ElasticSearch
- Depois que um índice é criado, você pode criar uma fonte de dados a partir da qual poderá criar seus insights.
- As ApiKeys podem ser criadas para fins administrativos (por exemplo, criar índices) ou aplicativos (por exemplo, enviar os dados por meio do Conector). Certifique-se de que esteja usando as corretas.
- Retenção de dados
- O salvamento de registros pode consumir muito disco. Evite isso:
- Excluindo notificações de exclusão do ElasticSearch Connector com o parâmetro ignoreDeletes = true bandeira
- Definir um TTL para a coleção que contém seus logs, para que o Couchbase Capella limpe automaticamente os logs que forem muito antigos
- O salvamento de registros pode consumir muito disco. Evite isso:
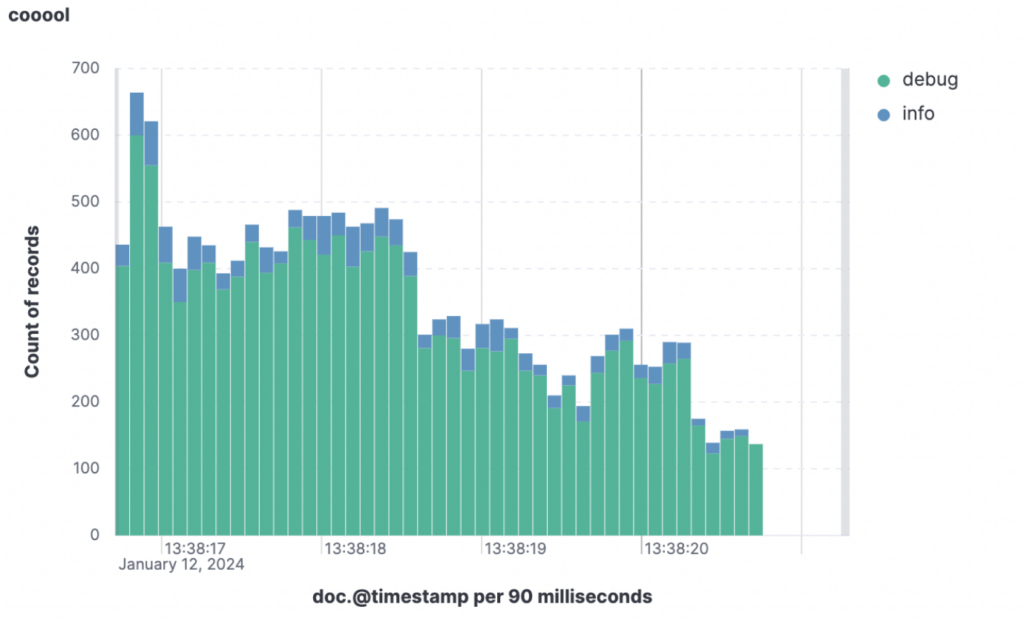
Conclusão
Neste tutorial, vimos como implementar a observabilidade em nossas Eventing Functions implementadas no Capella. Como próxima etapa, você pode registrar-se para uma avaliação do Capella e experimente você mesmo os diversos recursos oferecidos pelo banco de dados NoSQL mais avançado do mercado. Para ajudá-lo a se orientar, você também pode usar nosso playground e nossa Capella iQnosso assistente de IA generativa, para aprender a desenvolver e experimentar em um ambiente seguro.

