Introdução
O Couchbase Kafka Connector 1.2.0 acaba de ser lançado. Juntamente com as várias correções de bugs, há um novo código de amostra para um consumidor Kafka, além do produtor Kafka que estava disponível anteriormente. Para revisar rapidamente os termos:
- Um produtor do Kafka grava dados no Kafka, portanto, é uma fonte de mensagens do ponto de vista do Kafka.
- Na terminologia do Kafka, um consumidor é um processo que se inscreve em tópicos e, em seguida, faz algo com o feed de mensagens publicadas que são emitidas por um cluster do Kafka. É basicamente um sink.
Neste blog, você começará a trabalhar com um consumidor Kafka de amostra no estilo "Hello World!" que grava no Couchbase. Ao longo do caminho, você também obterá um ambiente sandbox com um broker Kafka e um servidor Couchbase de nó único para que possa executar e modificar o consumidor e o produtor de amostra.
Instalação de pré-requisitos
O amostras fazem parte do Conector Kafka do Couchbase árvore de origem. Para obtê-los, basta clonar o repositório inteiro:
|
1 |
$ git clone git://github.com/couchbase/couchbase-kafka-connector.git /tmp/kafka-connector |
Agora, vamos configurar seu ambiente de teste usando imagens pré-configuradas do Kafka e do Couchbase Server. Você precisa instalar o Vagrant, o VirtualBox e o Ansible para configurá-los localmente. Se você tiver esses serviços instalados em outro lugar, certifique-se de ajustar adequadamente os endereços de host ao longo deste guia.
|
1 |
$ cd /tmp/kafka-connector/env |
Verificar as versões das dependências:
|
1 2 3 |
$ ansible --version $ vboxmanage --version $ vagrant -v |
Você pode atribuir nomes legíveis por humanos às caixas usando o plug-in do Vagrant. Se você ainda não o tiver instalado, use o seguinte comando:
|
1 |
$ vagrant plugin install vagrant-hostsupdater |
Agora você está pronto para provisionar os servidores e começar a trabalhar:
|
1 |
$ vagrant up |
Observação: se um servidor falhar na instalação devido a tempos limite, tente novamente "vagrant up" após alguns minutos e talvez funcione.
Verifique se os hosts estão respondendo:
|
1 2 |
$ ping couchbase1.vagrant $ ping kafka1.vagrant |
Se você navegar até o Couchbase Server de nó único configurado com credenciais Administrador/senha.
Criando as amostras
Para evitar problemas de classpath, use o maven para criar um arquivo JAR autônomo para cada aplicativo de amostra.
O aplicativo gerador é um aplicativo CLI mínimo. Ele usa o SDK Java do Couchbase para agrupar as linhas de entrada do STDIN em documentos JSON e os envia para o bucket "padrão" no Couchbase Server:
|
1 2 |
$ cd /tmp/kafka-connector/samples/generator $ mvn assembly:assembly |
O produtor se conecta ao Couchbase Server e transmite todas as mutações para o Kafka. Esse aplicativo usa o projeto couchbase-kafkaconnector nos bastidores.
|
1 2 |
$ cd /tmp/kafka-connector/samples/producer $ mvn assembly:assembly |
O consumidor é um consumidor típico do Kafka, que, por padrão, apenas envia qualquer mensagem recebida no tópico "default" para STDOUT.
|
1 2 3 |
$ cd /tmp/kafka-connector/samples/consumer $ mvn assembly:assembly |
Executando as amostras
Agora que você tem tudo preparado, é hora de executar todas as amostras. Você precisará de três sessões de shell diferentes, pois cada uma delas executa um processo até ser interrompida. Vamos supor que você esteja na sessão /tmp/kafka-connector/samples diretório.
Primeiro, ligue o gerador:
|
1 2 |
$ java -jar generator/target/kafka-samples-generator-1.0-SNAPSHOT-jar-with-dependencies.jar |
Ele deve exibir as configurações de conexão e, em seguida, cair em um prompt de comando >. Você pode digitar qualquer coisa lá e verificar se ele está sendo criado corretamente, olhando na interface de administração do Couchbase Server:
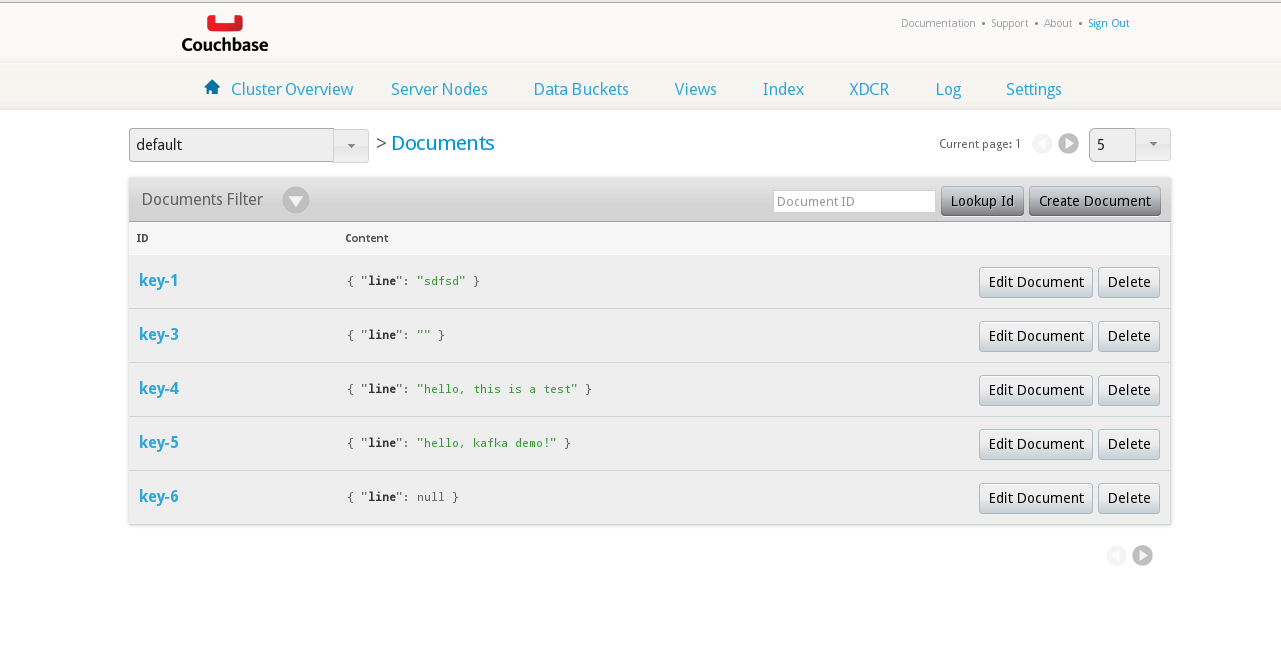
Documentos do gerador no balde
|
1 2 3 4 5 |
... INFO: Opened bucket default > hello, kafka demo! >> key=key-5, value={"line":"hello, kafka demo!"} |
Neste momento, você pode executar o exemplo do conector
|
1 |
$ java -jar producer/target/kafka-samples-producer-1.0-SNAPSHOT-jar-with-dependencies.jar |
Para cada linha digitada no gerador, você verá uma linha do produtor como esta:
|
1 |
RECEIVED: com.couchbase.kafka.DCPEvent@4e44cb88 |
O exemplo o grava logo antes de enviar a carga útil para o Kafka, na implementação da classe de filtro. Vamos verificar como o Kafka recebe essas mensagens.
|
1 2 3 |
$ java -jar consumer/target/kafka-samples-consumer-1.0-SNAPSHOT-jar-with-dependencies.jar 1: {"line":"hello, kafka demo!"} 2: {"line":"hello, this is a test"} |
Você pode continuar brincando com ele enquanto todos os três serviços estiverem em execução.
Desenvolvimento com o conector Kafka do Couchbase
Vamos seguir em frente e dar uma olhada no código. Todos os três aplicativos são bastante amigáveis para experimentos, por exemplo, o gerador cabe em apenas algumas linhas:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
public class Example { public static void main(String args[]) throws IOException { Random random = new Random(); Cluster cluster = CouchbaseCluster.create("couchbase1.vagrant"); Bucket bucket = cluster.openBucket(); BufferedReader input = new BufferedReader(new InputStreamReader(System.in)); String line; do { System.out.print("> "); line = input.readLine(); if (line == null) { break; } String key = "key-" + random.nextInt(10); JsonObject value = JsonObject.create().put("line", line); bucket.upsert(JsonDocument.create(key, value)); System.out.printf(">> key=%s, value=%sn", key, value); } while (true); } } |
Basicamente, o gerador abre uma conexão com o bucket "default" em sua instância "couchbase1.vagrant" e grava suas mensagens em chaves aleatórias. Você pode estendê-lo para enviar outros tipos de eventos. Outra coisa que você pode tentar fazer é remover chaves.
Por padrão, o Conector do Couchbase para Kafka é executado no modo de servidor, no qual toma emprestado o thread ativo e escuta ativamente o Couchbase Server em busca de novos eventos. Há vários pontos em que você pode aplicar suas ideias ou alterações. O mais óbvio é o construtor de configuração, onde você não apenas especifica as credenciais e os endereços dos serviços aos quais está se conectando, mas também pode especificar várias classes de serializador e filtro.
O aplicativo de amostra implementa várias delas. A classe Filter é a mais simples:
|
1 2 3 4 5 6 7 8 9 |
public class SampleFilter implements Filter { @Override public boolean pass(DCPEvent dcpEvent) { System.out.println("RECEIVED: " + dcpEvent); return true; } } |
Aqui você pode inserir as verificações personalizadas que desejar e, se passar() retornos falsoo conector descarta a mensagem e não a envia para o Kafka.
O codificador padrão, que vem com a distribuição do conector, tenta representar cada mensagem como JSON, mas isso provavelmente não é o que você precisa, portanto, você pode aplicar e converter para Evento DCPE e retorna uma matriz de bytes, que será armazenada no Kafka. Neste exemplo, apenas convertemos os eventos em sua representação de cadeia de caracteres.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
public class SampleEncoder extends AbstractEncoder { public SampleEncoder(final VerifiableProperties properties) { super(properties); } @Override public byte[] toBytes(final DCPEvent dcpEvent) { if (dcpEvent.message() instanceof MutationMessage) { MutationMessage message = (MutationMessage) dcpEvent.message(); return message.content().toString(CharsetUtil.UTF_8).getBytes(); } else { return dcpEvent.message().toString().getBytes(); } } } |
Uma configuração mais avançada é StateSerializer interface. Ao implementá-la, você pode controlar como a biblioteca rastreará os cursores de fluxo (ou seja, os números de sequência de cada partição dentro do Couchbase Server) e se ela será retomada após a reinicialização do conector. Há uma implementação do serializador de estado do Zookeeper na distribuição. Aqui na amostra, implementamos NullStateSerializer que não persiste em nada, mas mostra uma implementação mínima.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
public class NullStateSerializer implements StateSerializer { public NullStateSerializer(final CouchbaseKafkaEnvironment environment) { } @Override public void dump(BucketStreamAggregatorState aggregatorState) { } @Override public void dump(BucketStreamAggregatorState aggregatorState, short partition) { } @Override public BucketStreamAggregatorState load(BucketStreamAggregatorState aggregatorState) { return new BucketStreamAggregatorState(aggregatorState.name()); } @Override public BucketStreamState load(BucketStreamAggregatorState aggregatorState, short partition) { return new BucketStreamState(partition, 0, 0, 0xffffffff, 0, 0xffffffff); } } |
O último componente de seu cluster de demonstração é o consumidor Kafka AbstractConsumerque é uma instância bastante típica de um consumidor. Ele consiste em duas partes: A primeira, que implementa o bootstrap e o posicionamento no tópico do Kafka, e PrintConsumerque carrega sua "lógica de negócios", ou simplesmente emite todas as mensagens pelas quais passa AbstractConsumer:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
public class PrintConsumer extends AbstractConsumer { public PrintConsumer(String[] seedBrokers, int port) { super(seedBrokers, port); } public PrintConsumer(String seedBroker, int port) { super(seedBroker, port); } @Override public void handleMessage(long offset, byte[] bytes) { System.out.println(String.valueOf(offset) + ": " + new String(bytes)); } } |
Como nos outros exemplos aqui, você pode brincar com a modificação do consumidor de amostra. Você pode até mesmo fechar o circuito enviando tudo de volta ao Couchbase Server. O Kafka é um software distribuído, assim como o Couchbase Server, portanto, tenha isso em mente ao executar em seu próprio cluster e ajuste a função main() de acordo. Em nossa amostra, temos apenas uma única partição, a partição (0) no Kafka, de modo que o nosso principal tem a seguinte aparência:
|
1 2 3 4 5 6 |
public class Example { public static void main(String args[]) { PrintConsumer example = new PrintConsumer("kafka1.vagrant", 9092); example.run("default", 0); } } |
É claro que, em um cluster de produção, você executará mais de uma partição.
Conclusão
Espero que isso o ajude a ter um bom começo com o Couchbase e o Kafka. Parabéns!