Há seis mil anos, os sumérios inventaram a escrita para o processamento de transações. Gray e Reuter
De qualquer forma, o MongoDB é um banco de dados JSON popular orientado a documentos. Nos últimos doze anos, ele cresceu de seu início humilde de um único bloqueio por banco de dados para uma transação moderna de vários documentos com isolamento de instantâneos. A MongoDB University treinou um grande número de desenvolvedores para desenvolver no banco de dados MongoDB.
Atualmente, existem muitos bancos de dados JSON. Embora seja fácil começar com o MongoDB para aprender a usar o NoSQL e o esquema JSON flexível, muitos clientes escolhem o Couchbase por causa do desempenho, da escala e do SQL. À medida que avança na avaliação e evolução do banco de dados, você deve aprender sobre outros bancos de dados JSON. Estamos trabalhando em um curso de treinamento on-line para que os especialistas em MongoDB aprendam facilmente o Couchbase. Até publicarmos esse curso, você terá que ler este artigo :-)
Se você conhece RDBMS como Microsoft SQL Server e Oracle, temos cursos fáceis de seguir para aprender a mapear seu conhecimento de banco de dados para o Couchbase com esses dois cursos:
- CB116m - Introdução ao Couchbase para especialistas em MSSQL
- CB116o - Introdução ao Couchbase para especialistas em Oracle
RESUMO
O MongoDB e o Couchbase têm muitas coisas em comum. Ambos são NoSQL bancos de dados distribuídosAmbos usam o modelo JSON; ambos têm linguagens de consulta de alto nível com suporte para operações select-join-project; ambos têm índices secundários; ambos têm um otimizador que escolhe o plano de consulta automaticamente. Ambos suportam replicação intra e intercluster.
Como era de se esperar, há diferenças. Algumas são mais significativas do que outras. O Couchbase foi projetado para ser distribuído desde o início. Por exemplo, o contêiner de dados Bucket é sempre distribuído - sem nada para fragmentar. Basta adicionar novos nós e o sistema distribuirá automaticamente. A replicação intracluster não requer novos servidores - basta definir o número de réplicas e está tudo pronto. Do ponto de vista da interação com o desenvolvedor, a grande diferença é a própria linguagem de consulta - o MongoDB tem uma linguagem linguagem de consulta proprietária e o Couchbase tem N1QL - SQL para JSON. O MongoDB também usa seu índice baseado em B-Tree para pesquisa e lançou recentemente o $searchbeta para o serviço Atlas usando o Apache Lucene; o Couchbase tem um Pesquisa de texto completo.
Esperamos que as diferenças no Couchbase sejam aquelas que facilitam sua vida. Vamos nos aprofundar.
TÓPICOS DE ALTO NÍVEL
- Recursos
- Arquitetura
- Objetos de banco de dados
- Tipos de dados
- Modelo de dados
- SDK
- Linguagem de consulta
- Índices
- Otimizador
- Transações
- Análises
RECURSOS
MongoDB |
Couchbase |
|
|
Documentos |
||
|
Fóruns |
||
|
Versão mais recente (Abril de 2020) |
4.2.6 |
6.5.1 |
|
Licença |
https://www.mongodb.com/licensing/server-side-public-license/faq |
|
|
Linguagem de consulta |
ARQUITETURA
Versão para laptop:
MongoDB: Basta instalar e usar o Mongodb em seu laptop com os parâmetros corretos e pronto. Um único processo para lidar com todo o banco de dados. Isso mudou um pouco na versão 4.2, em que você precisaria do mongos para executar suas transações. Todos os recursos do MongoDB (dados, indexação, consulta) estão disponíveis aqui, exceto a pesquisa de texto completo, disponível apenas no serviço Atlas.
 Couchbase: O Couchbase é diferente. Ele abstraiu cada um dos serviços (dados, índice, consulta, pesquisa, análise, eventos) e você tem a opção de escolher quais dos recursos deseja executar em sua instância para otimizar os recursos. Uma instalação típica tem dados, índice e consulta. A pesquisa, os eventos e a análise serão executados em seu laptop - instale e use-os de acordo com seu caso de uso.
Couchbase: O Couchbase é diferente. Ele abstraiu cada um dos serviços (dados, índice, consulta, pesquisa, análise, eventos) e você tem a opção de escolher quais dos recursos deseja executar em sua instância para otimizar os recursos. Uma instalação típica tem dados, índice e consulta. A pesquisa, os eventos e a análise serão executados em seu laptop - instale e use-os de acordo com seu caso de uso.
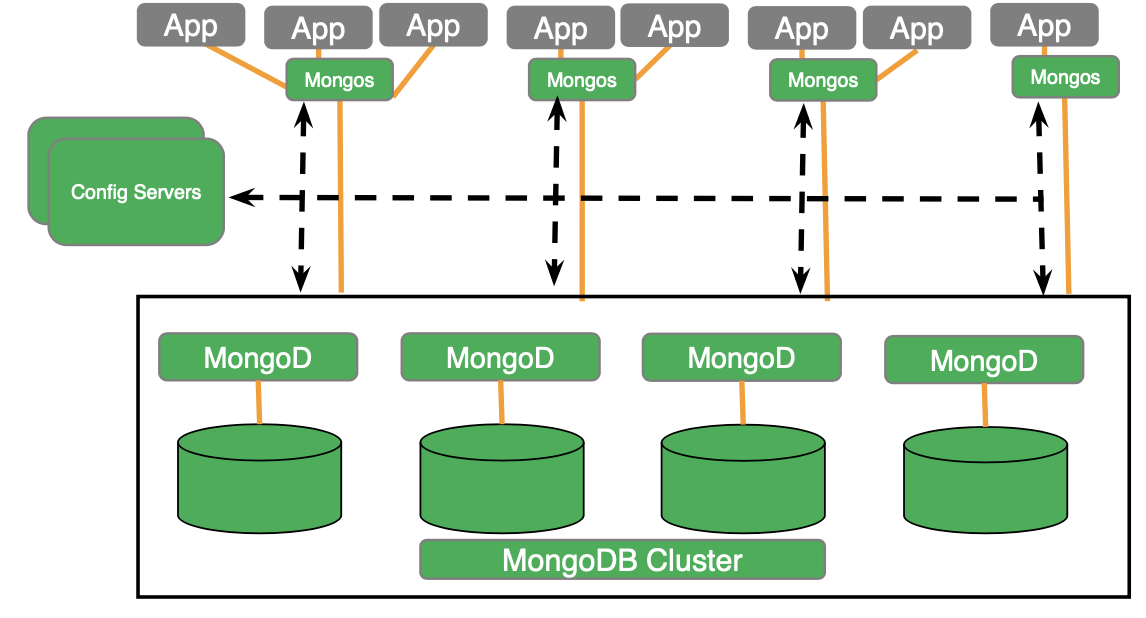
Implantação de cluster: Como acontece com a maioria dos bancos de dados NoSQL, tanto o MongoDB quanto o Couchbase podem ser escalonados. No MongoDB, você pode escalonar por fragmentação a coleção em vários nós. Você pode fragmentar por hash ou intervalo. Sem um shard explícito, cada coleção permanece em um único shard. Os servidores de configuração armazenam os metadados e a configuração do cluster. O MongoDB é distribuído de maneira uniforme e o Couchbase é distribuído de maneira multidimensional. O processo (serviço) do Mongodb gerencia os dados, o índice e a consulta em cada fragmento (nó), enquanto o Mongos faz o processamento da consulta distribuída e a fusão dos resultados intermediários e não gerencia nenhum dado ou índice. O Mongos atua como coordenador e o mongodb é a abelha operária.
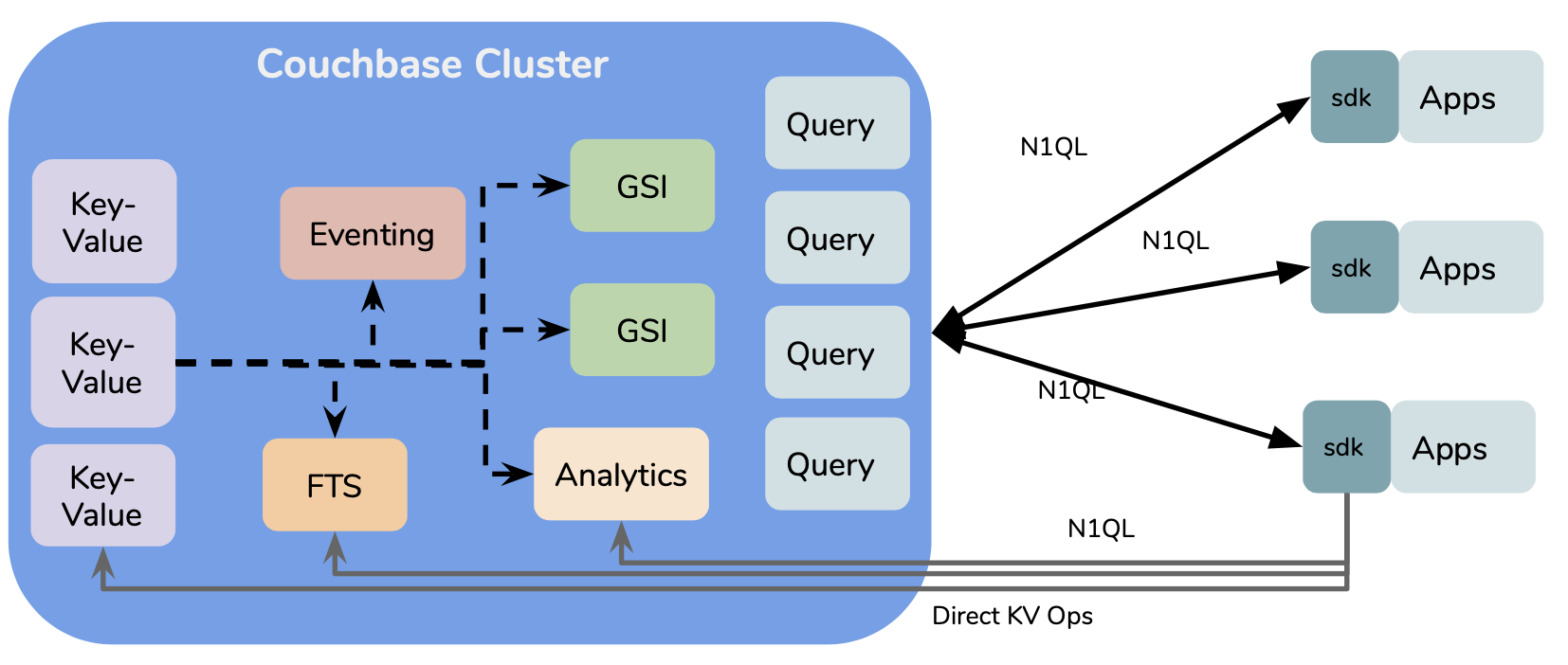
O Couchbase pode ser implantado em uma distribuição uniforme com cada nó gerenciando os dados e todos os serviços - dados, índice, consulta, análise e eventos. Cada serviço é uma camada do banco de dados tradicional. Esses serviços são fracamente acoplados - eles são executados em diferentes espaços de processo e se comunicam por meio de uma rede. Portanto, eles podem ser implantados uniformemente em um único nó ou distribuídos multidimensionalmente em um cluster. A escolha depende de sua carga de trabalho e dos SLAs. Os dados em si são armazenados em buckets. Todos os buckets são particionados por hash entre determinados nós - isso é automático e não requer nenhuma especificação. Quando o aplicativo tem as chaves do documento, ele pode operar diretamente nos dados sem nenhum nó intermediário. Essa é uma das principais diferenças arquitetônicas que contribuem para o alto desempenho e a expansão do Couchbase. Além disso, não há servidores de configuração. Os metadados e seu gerenciamento são incorporados ao banco de dados principal. O serviço de dados gerencia os dados, o cluster e a replicação em um cluster do Couchbase. A replicação entre vários clusters do Couchbase é gerenciada pelo XDCR. Leia este artigo para entender os mecanismos de replicação no MongoDB e no Couchbase: Replicação em bancos de dados de documentos NoSQL (Mongo DB vs Couchbase)

Dentro da implantação do cluster.
Os componentes e a implantação do cluster do MongoDB são explicados aqui e assumo isso como conhecimento prévio. Evitarei repetir.
A implantação do Couchbase começa com o serviço de dados de valor-chave. Esse é o armazenamento de dados de valor-chave distribuído em hash (consistente). Ele também tem replicação intracluster integrada, eliminando qualquer necessidade de servidores de réplica ou servidores de configuração separados. O serviço de consulta orquestra a execução de N1QL consultas. Usos GSI (Indexação secundária global), FTS (Full-Text Search) conforme necessário. O FTS gerencia o índice de texto completo e pode ser consultado diretamente ou através do N1QL serviço de consulta. A função Eventing permite que você acione automaticamente a ação (executando uma função Javascript) na mutação de dados. O Couchbase Mecanismo de análise é um mecanismo de consulta e dados MPP. Faz uma cópia dos dados e os redistribui em seus nós, executa a consulta em paralelo para obter o melhor desempenho possível. Tudo isso pode ser usado sem problemas pelo rico conjunto de APIs disponíveis em nosso SDKs disponível em todos os idiomas populares.
OBJETOS DE BANCO DE DADOS
O MongoDB tem uma coleção e um banco de dados como objetos lógicos com os quais os usuários precisam trabalhar. Tradicionalmente, o Couchbase tinha apenas o Baldes. O Bucket funcionava tanto para o gerenciamento de recursos (por exemplo, a quantidade de memória usada), quanto para a segurança e o contêiner de dados. Em 6.5, introduzimos a noção de coleta e escopo como uma prévia para desenvolvedores. Essa hierarquia bucket:scope:collection é análoga à database:schema:table do RDBMS. Isso torna o banco de dados mais seguro e um melhor multilocatário. Na versão 6.5, sem a visualização para desenvolvedores, cada compartimento usa um escopo e uma coleção padrão, o que torna a transição perfeita.

|
RDBMS |
MongoDB |
Couchbase |
|
Banco de dados |
Banco de dados |
Balde |
|
Tabela |
Coleção |
Balde Futuro: Coleção |
|
Linha |
Documento (BSON) |
Documento (JSON padrão) |
|
Coluna |
Campo/Atributo |
Campo/Atributo |
|
Partição (tabela/coleção/bucket) |
Não particionado por padrão. O particionamento de hash e intervalo (sharding) é suportado manualmente. |
Partição (hash automático) |
Notas para os desenvolvedores
No MongoDB, você começa com sua instância (implantação) e cria bancos de dados, coleções e índices.
No Couchbase, você começa com sua instância e cria seus buckets e índices. Cada bucket pode ter vários tipos de documentos, portanto, cada documento deve ter um campo designado pelo aplicativo para reconhecer seu tipo. {"type": "parts"}. Como cada compartimento pode ter qualquer número de tipos de documentos, você deve evitar criar muitos compartimentos. Isso também significa que, ao criar um índice, você estará interessado em criar um índice para cada tipo: cliente, peças, pedidos etc. Portanto, a criação do índice incluirá uma cláusula WHERE para o tipo de documento.
CREATE INDEX ix_customer_zip ON customer(zip) WHERE type = "customer";
SELECT * FROM customer WHERE zip = 94040 AND type = "customer"
Cada documento do MongoDB contém um campo _id de identificação de documento fornecido explicitamente ou gerado implicitamente.
No Couchbase, os usuários devem gerar e inserir uma chave de documento imutável para cada documento. Ao inserir via N1QL, você pode usar a função UUID() para gerar uma para você. Porém, é uma boa prática ter uma chave de documento estrutura regular para a chave do documento.
TIPOS DE DADOS
O modelo de dados do MongoDB é BSON e o modelo de dados do Couchbase é JSON. O tipo proprietário BSON tem alguns tipos que não existem no JSON. O JSON tem os tipos string, numérico, booleano (verdadeiro/falso), matriz e objeto. O BSON tem string, numérico, booleano, array, objeto, binário, UTC DateTime, timestamp e muitas outras extensões proprietárias personalizadas. No Couchbase, todos os dados relacionados a tempo são armazenados como string no formato ISO 8601. O N1QL do Couchbase tem uma infinidade de funções para extrair, converter e calcular a hora. Os detalhes completos das funções são disponível neste artigo.
|
Tipo de dados |
MongoDB |
Couchbase |
JSON |
|
Números |
Número BSON |
Número JSON |
{ "id": 5, "balance":2942.59 } |
|
Cordas |
Cadeia de caracteres BSON |
Cadeia de caracteres JSON |
{"name": "Joe", "city": "Morrisville" } |
|
booleano |
BSON Booleano |
JSON Booleano |
{"premium": true, "pending": false} |
|
data e hora |
Formato de dados personalizados |
JSON ISO 8901 String com funções de extração, conversão e aritmética |
{ "soldate": “2017-10-12T13:47:41.068-07:00” } MongoDB: { "soldate": ISODate(“2012-12-19T06:01:17.171Z”)} |
|
dados espaciais |
GeoJSON |
Oferece suporte ao vizinho mais próximo e à distância espacial. |
"geometria": {"type": "Point", "coordinates": [-104.99404, 39.75621]} |
|
FALTANDO |
Sem suporte |
FALTANDO |
|
|
NULL |
JSON Nulo |
JSON nulo |
{"last_address": null } |
|
Objetos |
Objetos JSON flexíveis |
Objetos JSON flexíveis |
{"address" (endereço): {"street": "1, Main street", "city": Morrisville, "zip": "94824″}} |
|
Matrizes |
Matrizes JSON flexíveis |
Matrizes JSON flexíveis |
{ "hobbies": ["tennis", "skiing", "lego"]} |
TUDO SOBRE A FALTA
MISSING é o valor de um campo ausente no documento ou literal JSON.
{"name": "joe"} Tudo, exceto o campo "name", está faltando no documento. Você também pode definir o valor de um campo como MISSING para fazer com que o campo desapareça. Os bancos de dados relacionais tradicionais usam lógica de três valores com true, false e NULL. Com a adição de MISSING, o N1QL usa lógica de 4 valores.
Você tem as seguintes expressões com MISSING.
|
ESTÁ FALTANDO |
Retorna true se o documento não tiver um campo de status FROM CUSTOMER WHERE status is MISSING; |
|
NÃO ESTÁ FALTANDO |
Retorna true se o documento tiver um campo de status FROM CUSTOMER WHERE status is NOT MISSING; |
|
AUSENTE E NULO |
MISSING é uma quantidade ausente conhecida null é um UNKNOWN conhecido. Você pode verificar se há um valor nulo semelhante a MISSING com a expressão IS NULL ou IS NOT NULL. JSON válido: {"status": null} |
|
Valor ausente |
Basta fazer com que o campo de qualquer tipo desapareça, definindo-o como MISSING UPDATE CUSTOMER SET status = MISSING WHERE cxid = "xyz232" |
MODELAGEM DE DADOS
| Relacionamento | MongoDB | Couchbase |
| 1:1 |
|
|
| 1:N |
|
|
| N:M |
|
|
GERENCIAMENTO DE ESPAÇO FÍSICO
| Tipo de índice | MongoDB | Couchbase |
| Armazenamento de mesa | Diretório do sistema de arquivos | Diretório do sistema de arquivos |
| Armazenamento de índices | Diretório do sistema de arquivos | Diretório do sistema de arquivos |
| Particionamento - Dados | Há suporte para fragmentação por intervalo e hash. | Particionamento de hash
Armazenado em 1024 vbuckets |
| Particionamento - Índice | Vinculado à estratégia de fragmentação da coleção, pois todos os (sub)índices são locais para cada nó mongod. | Sempre separado do Bucket
Índice global (pode usar uma estratégia diferente da do bloco/coleção) Oferece suporte ao particionamento de hash dos índices. Particionamento de intervalo, a indexação parcial é manual por meio de índices parciais. |
SDKs
Meu conhecimento pessoal dos dois SDKs é limitado. Deve haver APIs, drivers e conectores equivalentes nos dois produtos. Caso contrário, informe-nos.
| SDK | MongoDB | Couchbase |
| Java | Driver java do MongoDB | SDK Java do Couchbase,
Simba e CDATA JDBC |
| C | Driver C do MongoDB
Driver ODBC |
Couchbase C SDK,
Simba e CDATA ODBC |
| .NET, LINQ | Provedor Mongodb .NET. | Provedor do Couchbase .NET
Provedor LINQ |
| PHP, Python, Perl, Node.js | SDK do MongoDB em todos esses idiomas | SDK do Couchbase em todos esses idiomas |
| golang | Mongodb go sdk | SDK do Couchbase Go |
LINGUAGEM DE CONSULTA
SELECIONAR: O Mongo tem várias APIs para selecionar os documentos. find() e aggregate() podem fazer o trabalho de instruções SELECT simples. Veremos o aggregate() mais adiante nesta seção.
|
1 2 3 4 5 6 7 |
/* MongoDB */ db.CUSTOMER.find({zip:94040}) /* Couchbase: N1QL */ SELECIONAR * DE CLIENTE ONDE zíper = 94040; |
INSERIR
No MongoDB, fornecer _id é opcional. Se você não fornecer seu valor, o Mongo gerará o valor do campo e o salvará. O fornecimento de document KEY é obrigatório no Couchbase.
|
1 2 3 4 5 6 7 8 9 |
/* MongoDB */ db.CUSTOMER.save({_id: "xyz124", {"id": "xyz124", "name": "Joe Montana", "status": "Prêmio", "zip": 94040}) /* Couchbase:N1QL */ INSERIR PARA CLIENTE(CHAVE, VALOR) VALORES ('xyz124', {"id": "xyz124", "name": "Joe Montana", "status": "Prêmio", "zip": 94040}) |
ATUALIZAÇÃO
|
1 2 3 4 5 6 7 |
/* MongoDB */ db.CUSTOMER.atualização({_id:”xyz124’},{zip:94587}) /* Coudhbase:N1QL */ ATUALIZAÇÃO CLIENTE CONJUNTO zíper = 94587 ONDE id = 'xyz124' |
DELETE
|
1 2 3 4 5 6 7 8 |
/* MongoDB */ db.CUSTOMER.remove({_id:'pqr482'}) /* Couchbase:N1QL. Uma das instruções será suficiente para esses dados/esquema. */ DELETE DE CLIENTE ONDE id = 'pqr482'; DELETE DE CLIENTE ONDE META().id = 'pqr482'; |
MERGE: A operação MERGE em um conjunto de documentos JSON é frequentemente necessária como parte de seu processo de ETL ou de atualizações diárias. A instrução MERGE pode envolver fontes de dados complexas com predicados complexos baseados em regras de negócios. O Couchbase fornece a operação MERGE padrão com a mesma semântica. No MongoDB, era necessário escrever um longo programa para fazer isso, mas algumas das regras de operação definidas (por exemplo, cada documento deve ser atualizado APENAS uma vez) são difíceis de aplicar em um aplicativo. No Couchbase, você pode simplesmente usar a função Declaração MERGEcomo o RDBMS.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
/* MongoDB */ Não disponível. Necessidade para trabalho em torno de usando agregado(), personalizado-lógica programa, e atualização(). /* A segunda instrução do Couchbase:N1QL é compatível com ANSI SQL*/ MERGE PARA CLIENTE USO (SELECIONAR id DE CN ONDE x < 10) AS CN ON CHAVE CN.id QUANDO COMBINADO ENTÃO ATUALIZAÇÃO CONJUNTO CLIENTE.o4=1; MERGE PARA CLIENTE USO (SELECIONAR id DE CN ONDE x < 10) AS CN ON (CN.id = META(CUSTOKMER).id) QUANDO COMBINADO ENTÃO ATUALIZAÇÃO CONJUNTO CLIENTE.o4=1; |
DESCREVER:
Os dados JSON são autodescritivos e flexíveis. O auxiliar de esquema do MongoDB está disponível via Visualização da bússola somente na Enterprise Edition.
O Couchbase tem o INFER para analisar e entender o esquema. Tanto o serviço de consulta quanto o serviço analítico podem inferir o esquema.
-
- Serviço de consulta Comando INFER
- O Analytics Service tem array_infer_schema() função.
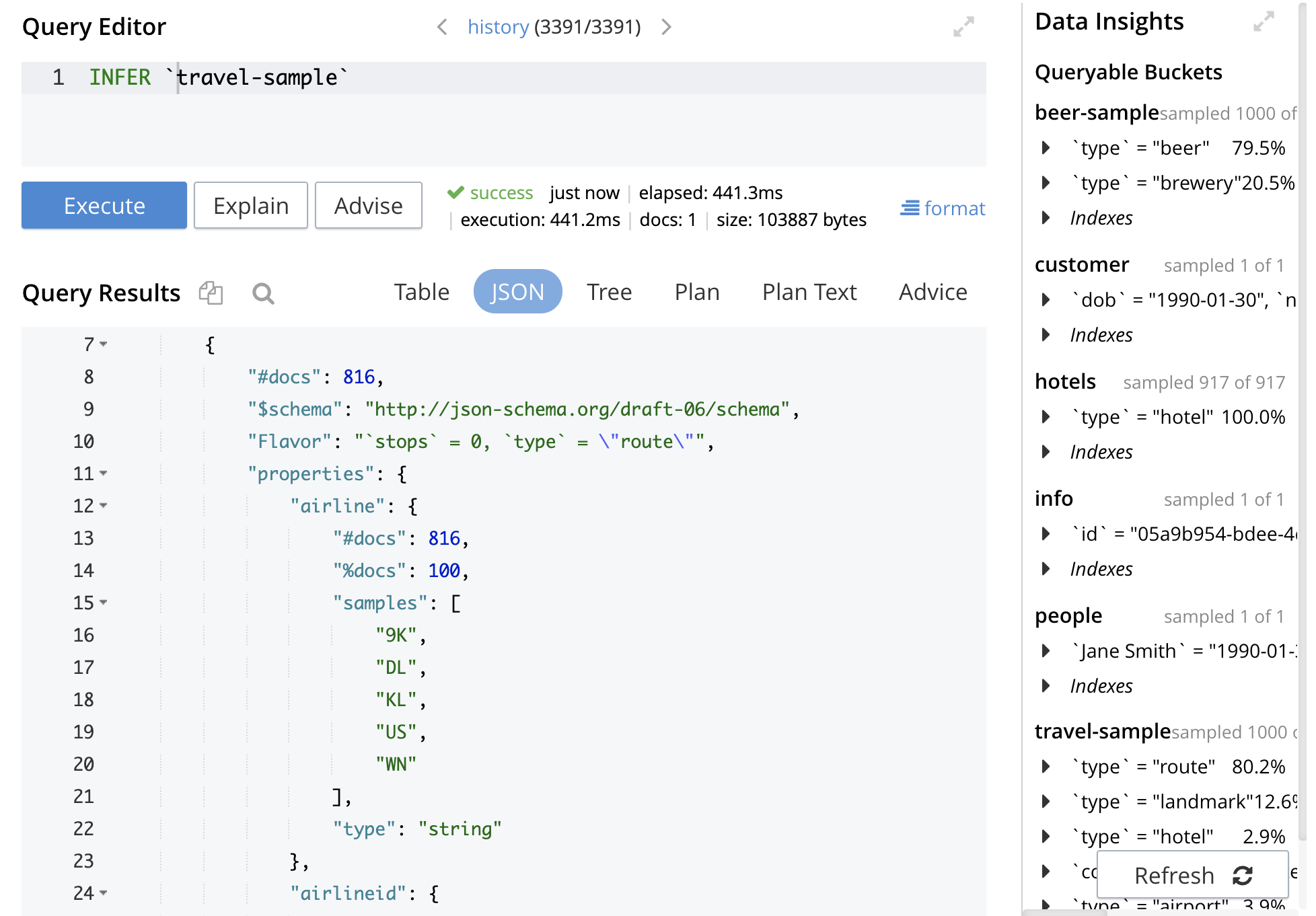
Aqui está o exemplo de saída do INFER.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755 756 757 758 759 760 761 762 763 764 765 766 767 768 769 770 771 772 773 774 775 776 777 778 779 780 781 782 783 784 785 786 787 788 789 790 791 792 793 794 795 796 797 798 799 800 801 802 803 804 805 806 807 808 809 810 811 812 813 814 815 816 817 818 819 820 821 822 823 824 825 826 827 828 829 830 831 832 833 834 835 836 837 838 839 840 841 842 843 844 845 846 847 848 849 850 851 852 853 854 855 856 857 858 859 860 861 862 863 864 865 866 867 868 869 870 871 872 873 874 875 876 877 878 879 880 881 882 883 884 885 886 887 888 889 890 891 892 893 894 895 896 897 898 899 900 901 902 903 904 905 906 907 908 909 910 911 912 913 914 915 916 917 918 919 920 921 922 923 924 925 926 927 928 929 930 931 932 933 934 935 936 937 938 939 940 941 942 943 944 945 946 947 948 949 950 951 952 953 954 955 956 957 958 959 960 961 962 963 964 965 966 967 968 969 970 971 972 973 974 975 976 977 978 979 980 981 982 983 984 985 986 987 988 989 990 991 992 993 994 995 996 997 998 999 1000 1001 1002 1003 1004 1005 1006 1007 1008 1009 1010 1011 1012 1013 1014 1015 1016 1017 1018 1019 1020 1021 1022 1023 1024 1025 1026 1027 1028 1029 1030 1031 1032 1033 1034 1035 1036 1037 1038 1039 1040 1041 1042 1043 1044 1045 1046 1047 1048 1049 1050 1051 1052 1053 1054 1055 1056 1057 1058 1059 1060 1061 1062 1063 1064 1065 1066 1067 1068 1069 1070 1071 1072 1073 1074 1075 1076 1077 1078 1079 1080 1081 1082 1083 1084 1085 1086 1087 1088 1089 1090 1091 1092 1093 1094 1095 1096 1097 1098 1099 1100 1101 1102 1103 1104 1105 1106 1107 1108 1109 1110 1111 1112 1113 1114 1115 1116 1117 1118 1119 1120 1121 1122 1123 1124 1125 1126 1127 1128 1129 1130 1131 1132 1133 1134 1135 1136 1137 1138 1139 1140 1141 1142 1143 1144 1145 1146 1147 1148 1149 1150 1151 1152 1153 1154 1155 1156 1157 1158 1159 1160 1161 1162 1163 1164 1165 1166 1167 1168 1169 1170 1171 1172 1173 1174 1175 1176 1177 1178 1179 1180 1181 1182 1183 1184 1185 1186 1187 1188 1189 1190 1191 1192 1193 1194 1195 1196 1197 1198 1199 1200 1201 1202 1203 1204 1205 1206 1207 1208 1209 1210 1211 1212 1213 1214 1215 1216 1217 1218 1219 1220 1221 1222 1223 1224 1225 1226 1227 1228 1229 1230 1231 1232 1233 1234 1235 1236 1237 1238 1239 1240 1241 1242 1243 1244 1245 1246 1247 1248 1249 1250 1251 1252 1253 1254 1255 1256 1257 1258 1259 1260 1261 1262 1263 1264 1265 1266 1267 1268 1269 1270 1271 1272 1273 1274 1275 1276 1277 1278 1279 1280 1281 1282 1283 1284 1285 1286 1287 1288 1289 1290 1291 1292 1293 1294 1295 1296 1297 1298 1299 1300 1301 1302 1303 1304 1305 1306 1307 1308 1309 1310 1311 1312 1313 1314 1315 1316 1317 1318 1319 1320 1321 1322 1323 1324 1325 1326 1327 1328 1329 1330 1331 1332 1333 1334 1335 1336 1337 1338 1339 1340 1341 1342 1343 1344 1345 1346 1347 1348 1349 1350 1351 1352 1353 1354 1355 1356 1357 1358 1359 1360 1361 1362 1363 1364 1365 1366 1367 1368 1369 1370 1371 1372 1373 1374 1375 1376 1377 1378 1379 1380 1381 1382 1383 1384 1385 1386 1387 1388 1389 1390 1391 1392 1393 1394 1395 1396 1397 1398 1399 1400 1401 1402 1403 1404 1405 1406 1407 1408 1409 1410 1411 1412 1413 1414 1415 1416 1417 1418 1419 1420 1421 1422 1423 1424 1425 1426 1427 1428 1429 1430 1431 1432 1433 1434 1435 1436 1437 1438 1439 1440 1441 1442 1443 1444 1445 1446 1447 1448 1449 1450 1451 1452 1453 1454 1455 1456 1457 1458 1459 1460 1461 1462 1463 1464 1465 1466 1467 1468 1469 1470 1471 1472 1473 1474 1475 1476 1477 1478 1479 1480 1481 1482 1483 1484 1485 1486 1487 1488 1489 1490 1491 1492 1493 1494 1495 1496 1497 1498 1499 1500 1501 1502 1503 1504 1505 1506 1507 1508 1509 1510 1511 1512 1513 1514 1515 1516 1517 1518 1519 1520 1521 1522 1523 1524 1525 1526 1527 1528 1529 1530 1531 1532 1533 1534 1535 1536 1537 1538 1539 1540 1541 1542 1543 1544 1545 1546 1547 1548 1549 1550 1551 1552 1553 1554 1555 1556 1557 1558 1559 1560 1561 1562 1563 1564 1565 1566 1567 1568 1569 1570 1571 1572 1573 1574 1575 1576 1577 1578 1579 1580 1581 1582 1583 1584 1585 1586 1587 1588 1589 1590 1591 1592 1593 1594 1595 1596 1597 1598 1599 1600 1601 1602 1603 1604 1605 1606 1607 1608 1609 1610 1611 1612 1613 1614 1615 1616 1617 1618 1619 1620 1621 1622 1623 1624 1625 1626 1627 1628 1629 1630 1631 1632 1633 1634 1635 1636 1637 1638 1639 1640 1641 1642 1643 1644 1645 1646 1647 1648 1649 1650 1651 1652 1653 1654 1655 1656 1657 1658 1659 1660 1661 1662 1663 1664 1665 1666 1667 1668 1669 1670 1671 1672 1673 1674 1675 1676 1677 1678 1679 1680 1681 1682 1683 1684 1685 1686 1687 1688 1689 1690 1691 1692 1693 1694 1695 1696 1697 1698 1699 1700 1701 1702 1703 1704 1705 1706 1707 1708 1709 1710 1711 1712 1713 1714 1715 1716 1717 1718 1719 1720 1721 1722 1723 1724 1725 1726 1727 1728 1729 1730 1731 1732 1733 1734 1735 1736 1737 1738 1739 1740 1741 1742 1743 1744 1745 1746 1747 1748 1749 1750 1751 1752 1753 1754 1755 1756 1757 1758 1759 1760 1761 1762 1763 1764 1765 1766 1767 1768 1769 1770 1771 1772 1773 1774 1775 1776 1777 1778 1779 1780 1781 1782 1783 1784 1785 1786 1787 1788 1789 1790 1791 1792 1793 1794 1795 1796 1797 1798 1799 1800 1801 1802 1803 1804 1805 1806 1807 1808 1809 1810 1811 1812 1813 1814 1815 1816 1817 1818 1819 1820 1821 1822 1823 1824 1825 1826 1827 1828 1829 1830 1831 1832 1833 1834 1835 1836 1837 1838 1839 1840 1841 1842 1843 1844 1845 1846 1847 1848 1849 1850 1851 1852 1853 1854 1855 1856 1857 1858 1859 1860 1861 1862 1863 1864 1865 1866 1867 1868 1869 1870 1871 1872 1873 1874 1875 1876 1877 1878 1879 1880 1881 1882 1883 1884 1885 1886 1887 1888 1889 1890 1891 1892 1893 1894 1895 1896 1897 1898 1899 1900 1901 1902 1903 1904 1905 1906 1907 1908 1909 1910 1911 1912 1913 1914 1915 1916 1917 1918 1919 1920 1921 1922 1923 1924 1925 1926 1927 1928 1929 1930 1931 1932 1933 1934 1935 1936 1937 1938 1939 1940 1941 1942 1943 1944 1945 1946 1947 1948 1949 1950 1951 1952 1953 1954 1955 1956 1957 1958 1959 1960 1961 1962 1963 1964 1965 1966 1967 1968 1969 1970 1971 1972 1973 1974 1975 1976 1977 1978 1979 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 2021 2022 2023 2024 2025 2026 2027 2028 2029 2030 2031 2032 2033 2034 2035 2036 2037 2038 2039 2040 2041 2042 2043 2044 2045 2046 2047 2048 2049 2050 2051 2052 2053 2054 2055 2056 2057 2058 2059 2060 2061 2062 2063 2064 2065 2066 2067 2068 2069 2070 2071 2072 2073 2074 2075 2076 2077 2078 2079 2080 2081 2082 2083 2084 2085 2086 2087 2088 2089 2090 2091 2092 2093 2094 2095 2096 2097 2098 2099 2100 2101 2102 2103 2104 2105 2106 2107 2108 2109 2110 2111 2112 2113 2114 2115 2116 2117 2118 2119 2120 2121 2122 2123 2124 2125 2126 2127 2128 2129 2130 2131 2132 2133 2134 2135 2136 2137 2138 2139 2140 2141 2142 2143 2144 2145 2146 2147 2148 2149 2150 2151 2152 2153 2154 2155 2156 2157 2158 2159 2160 2161 2162 2163 2164 2165 2166 2167 2168 2169 2170 2171 2172 2173 2174 2175 2176 2177 2178 2179 2180 2181 2182 2183 2184 2185 2186 2187 2188 2189 2190 2191 2192 2193 2194 2195 2196 2197 2198 2199 2200 2201 2202 2203 2204 2205 2206 2207 2208 2209 2210 2211 2212 2213 2214 2215 2216 2217 2218 2219 2220 2221 2222 2223 2224 2225 2226 2227 2228 2229 2230 2231 2232 2233 2234 2235 2236 2237 2238 2239 2240 2241 2242 2243 2244 2245 2246 2247 2248 2249 2250 2251 2252 2253 2254 2255 2256 2257 2258 2259 2260 2261 2262 2263 2264 2265 2266 2267 2268 2269 2270 2271 2272 2273 2274 2275 2276 2277 2278 2279 2280 2281 2282 2283 2284 2285 2286 2287 2288 2289 2290 2291 2292 2293 2294 2295 2296 2297 2298 2299 2300 2301 2302 2303 2304 2305 2306 2307 2308 2309 2310 2311 2312 2313 2314 2315 2316 2317 2318 2319 2320 2321 2322 2323 2324 2325 2326 2327 2328 2329 2330 2331 2332 2333 2334 2335 2336 2337 2338 2339 2340 2341 2342 2343 2344 |
INFER `amostra de viagem`; { "requestID": "59c444b1-a468-486b-aac3-949be1ddaed1", "clientContextID": "634e367b-ac7c-4815-90da-1506d6902d78", "assinatura": nulo, "resultados": [ [ { "#docs": 816, "$schema": "http://json-schema.org/draft-06/schema", "Sabor": "`stops` = 0, `type` = \"route\"", "propriedades": { "companhia aérea": { "#docs": 816, "%docs": 100, "amostras": [ "9K", "DL", "KL", "EUA", "WN" ], "tipo": "string" }, "airlineid": { "#docs": 816, "%docs": 100, "amostras": [ "airline_1629", "airline_2009", "airline_3090", "airline_4547", "airline_5265" ], "tipo": "string" }, "destinationairport" (aeroporto de destino): { "#docs": 816, "%docs": 100, "amostras": [ "ACK", "ATL", "BWI", "CMH", "HOMEM" ], "tipo": "string" }, "distância": { "#docs": 816, "%docs": 100, "amostras": [ 49.792009674515775, 335.34343397923425, 775.5437991859698, 2524.506189235734, 6139.9648921034795 ], "tipo": "número" }, "equipamento": { "#docs": [ 1, 815 ], "%docs": [ 0.12, 99.87 ], "amostras": [ [ nulo ], [ "73W 738", "763", "CNA", "CRJ", "ERJ CRJ" ] ], "tipo": [ "null", "string" ] }, "id": { "#docs": 816, "%docs": 100, "amostras": [ 3645, 20935, 36958, 59930, 64450 ], "tipo": "número" }, "agenda": { "#docs": 816, "%docs": 100, "itens": { "#docs": 17124, "$schema": "http://json-schema.org/draft-06/schema", "propriedades": { "dia": { "tipo": "número" }, "voo": { "tipo": "string" }, "utc": { "tipo": "string" } }, "tipo": "objeto" }, "maxItems": 31, "minItems": 10, "amostras": [ [ { "dia": 0, "voo": "9K006", "utc": "19:36:00" }, { "dia": 0, "voo": "9K802", "utc": "22:34:00" }, { "dia": 0, "voo": "9K210", "utc": "20:08:00" }, { "dia": 0, "voo": "9K316", "utc": "01:02:00" }, { "dia": 1, "voo": "9K408", "utc": "05:50:00" }, { "dia": 1, "voo": "9K452", "utc": "12:34:00" }, { "dia": 1, "voo": "9K799", "utc": "04:36:00" }, { "dia": 2, "voo": "9K157", "utc": "19:35:00" }, { "dia": 2, "voo": "9K923", "utc": "01:09:00" }, { "dia": 3, "voo": "9K201", "utc": "09:24:00" }, { "dia": 4, "voo": "9K355", "utc": "04:29:00" }, { "dia": 4, "voo": "9K845", "utc": "12:24:00" }, { "dia": 4, "voo": "9K515", "utc": "17:56:00" }, { "dia": 4, "voo": "9K472", "utc": "11:16:00" }, { "dia": 4, "voo": "9K506", "utc": "04:17:00" }, { "dia": 5, "voo": "9K040", "utc": "20:32:00" }, { "dia": 5, "voo": "9K273", "utc": "04:29:00" }, { "dia": 5, "voo": "9K131", "utc": "22:14:00" }, { "dia": 5, "voo": "9K494", "utc": "18:54:00" }, { "dia": 6, "voo": "9K037", "utc": "21:13:00" }, { "dia": 6, "voo": "9K786", "utc": "16:07:00" }, { "dia": 6, "voo": "9K724", "utc": "15:53:00" } ], [ { "dia": 0, "voo": "DL113", "utc": "15:48:00" }, { "dia": 0, "voo": "DL864", "utc": "09:13:00" }, { "dia": 1, "voo": "DL880", "utc": "23:27:00" }, { "dia": 2, "voo": "DL399", "utc": "06:42:00" }, { "dia": 2, "voo": "DL705", "utc": "15:54:00" }, { "dia": 2, "voo": "DL630", "utc": "21:52:00" }, { "dia": 3, "voo": "DL570", "utc": "00:02:00" }, { "dia": 4, "voo": "DL702", "utc": "18:46:00" }, { "dia": 4, "voo": "DL668", "utc": "20:09:00" }, { "dia": 4, "voo": "DL214", "utc": "10:27:00" }, { "dia": 4, "voo": "DL748", "utc": "13:36:00" }, { "dia": 5, "voo": "DL935", "utc": "20:48:00" }, { "dia": 6, "voo": "DL074", "utc": "19:27:00" }, { "dia": 6, "voo": "DL618", "utc": "10:54:00" }, { "dia": 6, "voo": "DL983", "utc": "19:41:00" }, { "dia": 6, "voo": "DL951", "utc": "17:45:00" }, { "dia": 6, "voo": "DL546", "utc": "12:19:00" } ], [ { "dia": 0, "voo": "KL362", "utc": "22:09:00" }, { "dia": 0, "voo": "KL430", "utc": "10:39:00" }, { "dia": 0, "voo": "KL249", "utc": "18:12:00" }, { "dia": 1, "voo": "KL670", "utc": "16:10:00" }, { "dia": 1, "voo": "KL164", "utc": "00:58:00" }, { "dia": 2, "voo": "KL015", "utc": "16:29:00" }, { "dia": 3, "voo": "KL731", "utc": "17:12:00" }, { "dia": 4, "voo": "KL047", "utc": "14:58:00" }, { "dia": 4, "voo": "KL854", "utc": "08:41:00" }, { "dia": 4, "voo": "KL173", "utc": "21:20:00" }, { "dia": 5, "voo": "KL006", "utc": "19:12:00" }, { "dia": 5, "voo": "KL886", "utc": "21:32:00" }, { "dia": 6, "voo": "KL448", "utc": "22:24:00" }, { "dia": 6, "voo": "KL286", "utc": "14:05:00" }, { "dia": 6, "voo": "KL170", "utc": "03:36:00" } ], [ { "dia": 0, "voo": "US931", "utc": "19:24:00" }, { "dia": 0, "voo": "US257", "utc": "20:54:00" }, { "dia": 1, "voo": "US375", "utc": "08:22:00" }, { "dia": 1, "voo": "US674", "utc": "20:41:00" }, { "dia": 1, "voo": "US866", "utc": "03:58:00" }, { "dia": 1, "voo": "US142", "utc": "16:05:00" }, { "dia": 2, "voo": "US572", "utc": "19:33:00" }, { "dia": 2, "voo": "US270", "utc": "12:58:00" }, { "dia": 2, "voo": "US151", "utc": "07:46:00" }, { "dia": 3, "voo": "US513", "utc": "13:58:00" }, { "dia": 3, "voo": "US410", "utc": "00:44:00" }, { "dia": 3, "voo": "US262", "utc": "14:52:00" }, { "dia": 3, "voo": "US962", "utc": "05:32:00" }, { "dia": 3, "voo": "US527", "utc": "17:42:00" }, { "dia": 4, "voo": "US068", "utc": "04:14:00" }, { "dia": 4, "voo": "US448", "utc": "09:39:00" }, { "dia": 4, "voo": "US914", "utc": "07:16:00" }, { "dia": 4, "voo": "US090", "utc": "06:06:00" }, { "dia": 4, "voo": "US514", "utc": "14:38:00" }, { "dia": 5, "voo": "US817", "utc": "09:41:00" }, { "dia": 5, "voo": "US665", "utc": "03:49:00" }, { "dia": 6, "voo": "US740", "utc": "07:27:00" }, { "dia": 6, "voo": "US803", "utc": "18:37:00" }, { "dia": 6, "voo": "US300", "utc": "09:08:00" }, { "dia": 6, "voo": "US496", "utc": "07:05:00" } ], [ { "dia": 0, "voo": "WN044", "utc": "13:39:00" }, { "dia": 0, "voo": "WN799", "utc": "07:15:00" }, { "dia": 0, "voo": "WN792", "utc": "09:16:00" }, { "dia": 1, "voo": "WN030", "utc": "09:51:00" }, { "dia": 1, "voo": "WN377", "utc": "03:41:00" }, { "dia": 2, "voo": "WN081", "utc": "01:53:00" }, { "dia": 2, "voo": "WN413", "utc": "04:49:00" }, { "dia": 2, "voo": "WN132", "utc": "16:06:00" }, { "dia": 2, "voo": "WN882", "utc": "21:16:00" }, { "dia": 2, "voo": "WN773", "utc": "04:55:00" }, { "dia": 3, "voo": "WN286", "utc": "04:17:00" }, { "dia": 3, "voo": "WN295", "utc": "04:35:00" }, { "dia": 4, "voo": "WN932", "utc": "16:34:00" }, { "dia": 4, "voo": "WN315", "utc": "00:35:00" }, { "dia": 4, "voo": "WN016", "utc": "09:10:00" }, { "dia": 4, "voo": "WN509", "utc": "22:28:00" }, { "dia": 5, "voo": "WN090", "utc": "13:46:00" }, { "dia": 6, "voo": "WN456", "utc": "04:05:00" }, { "dia": 6, "voo": "WN111", "utc": "05:10:00" } ] ], "tipo": "array" }, "sourceairport" (aeroporto de origem): { "#docs": 816, "%docs": 100, "amostras": [ "HYA", "JFK", "ORD", "SJU", "VLD" ], "tipo": "string" }, "paradas": { "#docs": 816, "%docs": 100, "amostras": [ 0 ], "tipo": "número" }, "tipo": { "#docs": 816, "%docs": 100, "amostras": [ "route" (rota) ], "tipo": "string" } }, "tipo": "objeto" }, { "#docs": 109, "$schema": "http://json-schema.org/draft-06/schema", "Sabor": "`type` = \"landmark\"", "propriedades": { "atividade": { "#docs": 109, "%docs": 100, "amostras": [ "comprar", "do", "bebida", "comer", "ver" ], "tipo": "string" }, "endereço": { "#docs": [ 106, 3 ], "%docs": [ 97.24, 2.75 ], "amostras": [ [ nulo ], [ "310 Uxbridge Rd, W12 7LJ", "Craven Cottage, Stevenage Rd, ...", "Warwick Road, SW5 9TA" ] ], "tipo": [ "null", "string" ] }, "alt": { "#docs": [ 108, 1 ], "%docs": [ 99.08, 0.91 ], "amostras": [ [ nulo ], [ "anteriormente Shanghai Red's" ] ], "tipo": [ "null", "string" ] }, "cidade": { "#docs": 109, "%docs": 100, "amostras": [ "Carpentras", "Llanddona", "Llangrannog", "Londres", "Los Angeles" ], "tipo": "string" }, "content" (conteúdo): { "#docs": 109, "%docs": 100, "amostras": [ "Realiza convenções frequentes, por exemplo...", "Originalmente um salão de dança, este ...", "O Museu de Cera de Hollywood é o...", "A casa da torcida da Premier League...", "Várias corridas de cavalos anuais, b..." ], "tipo": "string" }, "país": { "#docs": 109, "%docs": 100, "amostras": [ "França", "Reino Unido", "Estados Unidos" ], "tipo": "string" }, "direções": { "#docs": [ 106, 3 ], "%docs": [ 97.24, 2.75 ], "amostras": [ [ nulo ], [ "Cerca de 10 minutos a pé de ambas as Pu...", "tubo: Earl's Court ou West Bro...", "tubo: Shepherd's Bush Market" ] ], "tipo": [ "null", "string" ] }, "email": { "#docs": [ 106, 3 ], "%docs": [ 97.24, 2.75 ], "amostras": [ [ nulo ], [ "enquiries@fulhamfc.com", "info@eco.co.uk", "notes@bushhallmusic.co.uk" ] ], "tipo": [ "null", "string" ] }, "geo": { "#docs": 109, "%docs": 100, "propriedades": { "precisão": { "#docs": 109, "%docs": 100, "amostras": [ "APROXIMADO", "RANGE_INTERPOLATED", "ROOFTOP" ], "tipo": "string" }, "lat": { "#docs": 109, "%docs": 100, "amostras": [ 34.101757, 44.037882130818225, 51.4749, 51.4888, 51.5064 ], "tipo": "número" }, "longo": { "#docs": 109, "%docs": 100, "amostras": [ -118.338056, -0.2317, -0.2216, -0.1977, 5.064881989019341 ], "tipo": "número" } }, "amostras": [ { "precisão": "APROXIMADO", "lat": 51.4749, "longo": -0.2216 }, { "precisão": "RANGE_INTERPOLATED", "lat": 34.101757, "longo": -118.338056 }, { "precisão": "RANGE_INTERPOLATED", "lat": 44.037882130818225, "longo": 5.064881989019341 }, { "precisão": "RANGE_INTERPOLATED", "lat": 51.5064, "longo": -0.2317 }, { "precisão": "ROOFTOP", "lat": 51.4888, "longo": -0.1977 } ], "tipo": "objeto" }, "horas": { "#docs": [ 108, 1 ], "%docs": [ 99.08, 0.91 ], "amostras": [ [ nulo ], [ "Das 10h à meia-noite, diariamente" ] ], "tipo": [ "null", "string" ] }, "id": { "#docs": 109, "%docs": 100, "amostras": [ 11755, 16141, 16149, 16387, 40348 ], "tipo": "número" }, "imagem": { "#docs": [ 1, 108 ], "%docs": [ 0.91, 99.08 ], "amostras": [ [ nulo ], [ "https://en.wikivoyage.org/wiki...", "https://en.wikivoyage.org/wiki...", "https://en.wikivoyage.org/wiki...", "https://en.wikivoyage.org/wiki...", "https://en.wikivoyage.org/wiki..." ] ], "tipo": [ "null", "string" ] }, "image_direct_url": { "#docs": 7, "%docs": 6.42, "amostras": [ "https://upload.wikimedia.org/w...", "https://upload.wikimedia.org/w...", "https://upload.wikimedia.org/w...", "https://upload.wikimedia.org/w...", "" ], "tipo": "string" }, "name" (nome): { "#docs": 109, "%docs": 100, "amostras": [ "Bush Hall", "Centro de Exposições Earl's Court", "Fulham FC", "Hipódromo de Saint-Ponchon", "Museu de Cera de Hollywood" ], "tipo": "string" }, "telefone": { "#docs": [ 106, 3 ], "%docs": [ 97.24, 2.75 ], "amostras": [ [ nulo ], [ "+44 20 7385-1200", "+44 20 8222-6955", "+44 870 442 1222" ] ], "tipo": [ "null", "string" ] }, "price" (preço): { "#docs": [ 108, 1 ], "%docs": [ 99.08, 0.91 ], "amostras": [ [ nulo ], [ "Adultos (13+) $15.95, crianças ..." ] ], "tipo": [ "null", "string" ] }, "estado": { "#docs": [ 3, 106 ], "%docs": [ 2.75, 97.24 ], "amostras": [ [ nulo ], [ "Alsácia-Champagne-Ardenne-Lorra...", "Basse-Normandie", "Califórnia", "Provence-Alpes-Côte d'Azur", "Île-de-France" ] ], "tipo": [ "null", "string" ] }, "título": { "#docs": 109, "%docs": 100, "amostras": [ "Carpentras", "Hollywood", "Londres/Hammersmith e Fulham", "Londres/South Kensington-Chelse...", "Caminho da Costa do País de Gales" ], "tipo": "string" }, "tollfree": { "#docs": 109, "%docs": 100, "amostras": [ nulo ], "tipo": "null" }, "tipo": { "#docs": 109, "%docs": 100, "amostras": [ "marco" ], "tipo": "string" }, "url": { "#docs": [ 106, 3 ], "%docs": [ 97.24, 2.75 ], "amostras": [ [ nulo ], [ "http://www.bushhallmusic.co.uk...", "http://www.eco.co.uk/", "http://www.fulhamfc.com/" ] ], "tipo": [ "null", "string" ] } }, "tipo": "objeto" }, { "#docs": 23, "$schema": "http://json-schema.org/draft-06/schema", "Sabor": "`type` = \"hotel\"", "propriedades": { "endereço": { "#docs": [ 2, 21 ], "%docs": [ 8.69, 91.3 ], "amostras": [ [ nulo ], [ "68, rue de Longchamp", "Capstone Road, ME7 3JE", "Gower Holiday Village, Scurlag...", "Knockard Road, PH16 5HJ, 0870 0...", "Llanbedrgoch" ] ], "tipo": [ "null", "string" ] }, "alias": { "#docs": [ 22, 1 ], "%docs": [ 95.65, 4.34 ], "amostras": [ [ nulo ], [ "antigo Concorde Lafayette" ] ], "tipo": [ "null", "string" ] }, "checkin": { "#docs": [ 22, 1 ], "%docs": [ 95.65, 4.34 ], "amostras": [ [ nulo ], [ "3PM" ] ], "tipo": [ "null", "string" ] }, "checkout": { "#docs": [ 22, 1 ], "%docs": [ 95.65, 4.34 ], "amostras": [ [ nulo ], [ "meio-dia" ] ], "tipo": [ "null", "string" ] }, "cidade": { "#docs": [ 1, 22 ], "%docs": [ 4.34, 95.65 ], "amostras": [ [ nulo ], [ "Condado de Inyo", "Medway", "Paris", "Pitlochry", "Condado de Riverside" ] ], "tipo": [ "null", "string" ] }, "país": { "#docs": 23, "%docs": 100, "amostras": [ "França", "Reino Unido", "Estados Unidos" ], "tipo": "string" }, "description" (descrição): { "#docs": 23, "%docs": 100, "amostras": [ "(O ano todo). Este acampamento para trailers...", "Hotel boutique 3 estrelas.", "Hostel de verão com 40 camas a cerca de 3 m...", "Facilmente acessível a partir de West En...", "Ótimo albergue com 62 camas, perto da t..." ], "tipo": "string" }, "direções": { "#docs": [ 22, 1 ], "%docs": [ 95.65, 4.34 ], "amostras": [ [ nulo ], [ "centro da cidade" ] ], "tipo": [ "null", "string" ] }, "email": { "#docs": [ 22, 1 ], "%docs": [ 95.65, 4.34 ], "amostras": [ [ nulo ], [ "julia@number38thegower.co.uk" ] ], "tipo": [ "null", "string" ] }, "fax": { "#docs": [ 22, 1 ], "%docs": [ 95.65, 4.34 ], "amostras": [ [ nulo ], [ "+1-310-821-8098" ] ], "tipo": [ "null", "string" ] }, "free_breakfast" (café da manhã gratuito): { "#docs": 23, "%docs": 100, "amostras": [ falso, verdadeiro ], "tipo": "booleano" }, "free_internet": { "#docs": 23, "%docs": 100, "amostras": [ falso, verdadeiro ], "tipo": "booleano" }, "free_parking" (estacionamento gratuito): { "#docs": 23, "%docs": 100, "amostras": [ falso, verdadeiro ], "tipo": "booleano" }, "geo": { "#docs": 23, "%docs": 100, "propriedades": { "precisão": { "#docs": 23, "%docs": 100, "amostras": [ "APROXIMADO", "RANGE_INTERPOLATED", "ROOFTOP" ], "tipo": "string" }, "lat": { "#docs": 23, "%docs": 100, "amostras": [ 33.9829, 36.60545, 48.86522, 51.35785, 56.7049 ], "tipo": "número" }, "longo": { "#docs": 23, "%docs": 100, "amostras": [ -117.14634, -116.1545, -3.7291, 0.55818, 2.28566 ], "tipo": "número" } }, "amostras": [ { "precisão": "APROXIMADO", "lat": 56.7049, "longo": -3.7291 }, { "precisão": "RANGE_INTERPOLATED", "lat": 36.60545, "longo": -117.14634 }, { "precisão": "RANGE_INTERPOLATED", "lat": 48.86522, "longo": 2.28566 }, { "precisão": "RANGE_INTERPOLATED", "lat": 51.35785, "longo": 0.55818 }, { "precisão": "ROOFTOP", "lat": 33.9829, "longo": -116.1545 } ], "tipo": "objeto" }, "id": { "#docs": 23, "%docs": 100, "amostras": [ 7392, 10025, 12928, 21663, 22461 ], "tipo": "número" }, "name" (nome): { "#docs": 23, "%docs": 100, "amostras": [ "Hotel Longchamp Elysées", "Albergue da Juventude de Medway", "Albergue da Juventude de Pitlochry", "Ryan Campground", "Acampamento para trailers em Stovepipe Wells" ], "tipo": "string" }, "pets_ok": { "#docs": 23, "%docs": 100, "amostras": [ falso, verdadeiro ], "tipo": "booleano" }, "telefone": { "#docs": [ 21, 2 ], "%docs": [ 91.3, 8.69 ], "amostras": [ [ nulo ], [ "+44 1248 450051", "+44 870 770 5964" ] ], "tipo": [ "null", "string" ] }, "price" (preço): { "#docs": [ 21, 2 ], "%docs": [ 91.3, 8.69 ], "amostras": [ [ nulo ], [ "$10 por noite", "$23 por noite" ] ], "tipo": [ "null", "string" ] }, "public_likes": { "#docs": 23, "%docs": 100, "itens": { "tipo": "string" }, "maxItems": 9, "minItems": 0, "amostras": [ [], [ "Julius Tromp I", "Corrine Hilll", "Jaeden McKenzie", "Vallie Ryan", "Brian Kilback", "Lilian McLaughlin", "Sra. Moses Feeney", "Elnora Trantow" ], [ "Sr. Franco Collins", "Cloyd Stark", "Eliseo Herman" ], [ "Sra. Wiley Torp", "Missouri Sauer", "Chanel Kirlin", "Trystan Rolfson", "Sr. Emma Oberbrunner", "Marina Stracke", "Cody Hand", "Tracey Price", "Raven Romaguera" ], [ "Stefan Greenfelder", "Rosemary Doyle", "Abdullah Lindgren", "Gregorio Emard" ] ], "tipo": "array" }, "avaliações": { "#docs": 23, "%docs": 100, "itens": { "#docs": 3, "$schema": "http://json-schema.org/draft-06/schema", "Sabor": "", "propriedades": { "autor": { "#docs": 3, "%docs": 100, "amostras": [ "Cornelius Brakus", "Dorcas VonRueden", "Jo Collier" ], "tipo": "string" }, "content" (conteúdo): { "#docs": 3, "%docs": 100, "amostras": [ "Um quarto de tamanho decente para o lo...", "BOM NEGÓCIO PELO PREÇO E PELO PREÇO...", "Fique longe deste hotel! Com..." ], "tipo": "string" }, "data": { "#docs": 3, "%docs": 100, "amostras": [ "2012-09-05 22:33:09 +0300", "2012-09-11 19:21:15 +0300", "2014-06-11 09:35:15 +0300" ], "tipo": "string" }, "classificações": { "#docs": 3, "%docs": 100, "propriedades": { "Serviço comercial (por exemplo, acesso à Internet)": { "#docs": 1, "%docs": 33.33, "amostras": [ 1 ], "tipo": "número" }, "Check-in / recepção": { "#docs": 2, "%docs": 66.66, "amostras": [ 2, 5 ], "tipo": "número" }, "Limpeza": { "#docs": 2, "%docs": 66.66, "amostras": [ 4, 5 ], "tipo": "número" }, "Localização": { "#docs": 3, "%docs": 100, "amostras": [ 2, 3, 5 ], "tipo": "número" }, "Geral": { "#docs": 3, "%docs": 100, "amostras": [ 1, 4, 5 ], "tipo": "número" }, "Quartos": { "#docs": 3, "%docs": 100, "amostras": [ 1, 3, 5 ], "tipo": "número" }, "Serviço": { "#docs": 3, "%docs": 100, "amostras": [ 2, 3, 5 ], "tipo": "número" }, "Valor": { "#docs": 3, "%docs": 100, "amostras": [ 2, 5 ], "tipo": "número" } }, "amostras": [ { "Limpeza": 4, "Localização": 3, "Geral": 4, "Quartos": 3, "Serviço": 3, "Valor": 5 } ], "tipo": "objeto" } }, "tipo": "objeto" }, "maxItems": 9, "minItems": 0, "amostras": [ [ { "autor": "Bernhard Armstrong III", "content" (conteúdo): "Quando eu disse ao motorista de táxi onde estava hospedado, ele olhou para mim duas vezes. Esse deveria ter sido meu aviso, mas como eu não tinha para onde ir, fiquei preso. Dizer que esse lugar está cansado é um eufemismo. Ao entrar, levei cerca de 10 minutos para localizar a "recepção"... que é pouco mais que um quiosque embutido. Cheguei ao elevador e entrei em meu quarto. O quarto era cavernoso... muito grande e coberto com carpete rosa manchado. As portas faziam barulho e a fechadura não parecia segura. À noite, coloquei uma cadeira contra a porta para maior proteção. O quarto era enorme, mas os móveis escassos estavam dispostos ao redor das paredes e tornavam o quarto desconfortavelmente grande. A cama estava encostada em uma parede e a pequena TV estava do outro lado do quarto, em uma cômoda velha. Estava tão longe que o controle remoto não funcionava a menos que eu saísse da cama e andasse alguns metros. O cassino em si é velho... velho... velho. O carpete é velho, manchado e cansado. Assim como o cemitério de elefantes, eu realmente acredito que é aqui que os jogadores vão morrer. Joguei um pouco de texas hold 'em lá e, como a "imprensa" dizia, o proprietário sentou-se e jogou conosco. Ele era um cara legal, mas tinha sérios problemas de saúde e bebeu até ficar estuporado enquanto jogava. A senhora do drinque obviamente o conhecia bem e estava lá há anos. Ela estava visivelmente preocupada com a saúde dele e questionou o fato de ele beber... o que só agravou a situação do proprietário. Não foi uma cena agradável e foi realmente deprimente. O proprietário acabou se afastando cambaleando. Enquanto estava na mesa, iniciei uma conversa com o rapaz ao meu lado. Estávamos tendo uma conversa agradável e esse dealer em particular nos criticou incessantemente por "falar na mesa". Eu gosto de jogos sociais e isso é metade da diversão, mas esse cara nos irritou a ponto de pararmos de lhe dar gorjeta. O outro cara acabou dizendo ao dealer para ir ---- e saiu, e eu fiz o mesmo. O cassino fica a uma quadra da Fremont Street Experience e o quarteirão que você tem que atravessar é uma preocupação. O motorista do táxi me alertou para não sair à noite naquela área. Ele disse que havia muitos viciados em crack e que eles eram conhecidos por assaltar pessoas. Acabei brincando muito no centro da cidade, mas voltava antes de escurecer todas as noites. O Careful Kitty's é bom. É uma lanchonete antiga. A comida estava boa e o atendimento foi amigável. Havia muitas pessoas idosas e de aparência cansada por lá, que pareciam ter problemas de saúde. Eu realmente sinto muito por essas pessoas, mas eu estava lá para me divertir e era simplesmente deprimente. Voltei lá uma vez com minha namorada para lhe mostrar o lugar. Ela não conseguia acreditar que eu realmente havia ficado lá. Ela jogou em alguns caça-níqueis e depois disse que o lugar a "assustava" e que queria ir embora AGORA... Eu me hospedaria no centro da cidade sempre que quisesse e, na verdade, prefiro o centro da cidade ao strip, mas nunca mais cometeria esse erro. O quarto era barato, mas paguei um preço muito mais alto ao sacrificar minha diversão. Já estive em Las Vegas muitas vezes e essa foi, de longe, a pior experiência que já tive.", "data": "2012-03-26 11:54:35 +0300", "classificações": { "Limpeza": 2, "Geral": 1, "Quartos": 1, "Serviço": 3, "Valor": 1 } } ], [ { "autor": "Jo Collier", "content" (conteúdo): "Um quarto de tamanho decente pelo preço baixo de $100s a duas paradas da Times Square no trem expresso. Se estiver procurando conhecer Nova York (e não passar os dias em sua acomodação), o Hotel Newton funciona muito bem. É um lugar agradável, parece bem conservado. Não tivemos nenhum problema, funcionou muito bem como um lugar para dormir e guardar nossas coisas enquanto fazíamos turismo. Fica a uma curta distância de algumas coisas, mas a localização é melhor porque você está a uma quadra e meia da estação 96th st, que o levará ao centro da cidade rapidamente em um trem expresso.", "data": "2014-06-11 09:35:15 +0300", "classificações": { "Limpeza": 4, "Localização": 3, "Geral": 4, "Quartos": 3, "Serviço": 3, "Valor": 5 } }, { "autor": "Cornelius Brakus", "content" (conteúdo): "Fique longe desse hotel!!! Com o mesmo preço, você poderia ter um hotel com melhor localização, quarto limpo e banheiro próprio. Nosso quarto era muito pequeno, muito frio, sujo (e a faxineira não o limpou durante a nossa estadia) e o banheiro compartilhado era horrível. Nossa estadia parecia que estávamos em um motel. Além disso, não se trata de um hotel três estrelas, como consta no Booking.com, mas sim de um hotel 1 estrela, ou mais parecido com um albergue.", "data": "2012-09-05 22:33:09 +0300", "classificações": { "Serviço comercial (por exemplo, acesso à Internet)": 1, "Check-in / recepção": 2, "Localização": 2, "Geral": 1, "Quartos": 1, "Serviço": 2, "Valor": 2 } }, { "autor": "Dorcas VonRueden", "content" (conteúdo): "BOM NEGÓCIO PELO PREÇO E LOCALIZAÇÃO, uma equipe simpática e prestativa... os quartos são limpos, rm 502, 503 com vista para a broadway... nada para ver além de carros... área tranquila e segura, rite aid perto, mcdonald's para lanches noturnos. Visita em setembro de 2008, 4 adultos, 2 quartos,...economizei 500,00-600,00 cada um ficando aqui em vez do Sheraton ou Park Central. O hotel Newton tem uma localização ideal na linha principal do metrô, na 96th Street. Um trem expresso com destino ao Brooklyn leva você ao coração da Times Square em apenas alguns minutos. Ficaríamos aqui novamente... pesquisamos muitos sites e não ficamos desapontados com a escolha...", "data": "2012-09-11 19:21:15 +0300", "classificações": { "Check-in / recepção": 5, "Limpeza": 5, "Localização": 5, "Geral": 5, "Quartos": 5, "Serviço": 5, "Valor": 5 } } ], [ { "autor": "Joshua Rogahn", "content" (conteúdo): "Sou um viajante muito exigente e o AVIA superou minhas expectativas com a oferta de uma experiência de hotel 5 estrelas por uma tarifa 3 estrelas. Um hotel novo e bonito, com comodidades excepcionais nos quartos (lareira dupla face, TVs de tela plana enormes, decoração moderna e de bom gosto, camas confortáveis etc.). A concierge foi muito prestativa, conectada e bem informada, e ficou evidente que ela realmente se preocupa com a experiência dos hóspedes em Napa. As recomendações de restaurantes foram \"certeiras\" e ela nos reservou uma excursão verdadeiramente memorável e de primeira classe pelo Vale de Napa (por uma fração do preço e do incômodo do que poderíamos ter organizado por conta própria). Em suma, uma experiência excelente.", "data": "2013-12-22 18:40:29 +0300", "classificações": { "Geral": 5 } }, { "autor": "Madisyn Greenholt", "content" (conteúdo): "Que achado maravilhoso! Aninhado no coração do centro da cidade está este \"oásis urbano\" que oferece uma experiência de hospedagem calorosa e hospitaleira. Diferentemente de algumas das experiências de \"ursinho de pelúcia e renda\" de viagens anteriores, o AVIA Napa começa e termina com você se sentindo como se fosse um membro da família há muito perdido, em casa para uma breve visita. Os quartos são confortáveis e convidativos. Equipados com roupas de cama luxuosas que cobrem uma das camas mais confortáveis em que já dormimos. Os banheiros são claros e espaçosos, com bastante espaço para duas pessoas. Nosso quarto tinha uma bela banheira de imersão e uma grande televisão de tela plana. O restaurante serve apenas café da manhã e almoço, o que é ótimo, pois a maioria das pessoas sai para degustar vinhos ou fazer compras durante o dia. O café da manhã era um banquete para os olhos e para o estômago, oferecendo de tudo, desde aveia cortada em aço até omeletes perfeitos. O cardápio do jantar apresenta uma variedade de deliciosos \"pratos pequenos\" com algo para todos os paladares. Tudo estava muito bom!", "data": "2013-11-10 19:53:53 +0300", "classificações": { "Limpeza": 5, "Localização": 5, "Geral": 5, "Quartos": 5, "Serviço": 5, "Valor": 5 } }, { "autor": "Griffin Barton", "content" (conteúdo): "Fiquei aqui durante minha última viagem. os quartos são limpos. o banheiro é grande, mas não tão funcional. wifi gratuito e água mineral. a localização fica a uma boa caminhada da nathan road, portanto, se você pretende ir e voltar do seu quarto de hotel, pode ser uma tarefa árdua. há barulho que você pode ouvir dentro do quarto nas noites de fim de semana porque há clubes perto do hotel. no geral, ainda é um bom valor!", "data": "2014-05-05 23:33:30 +0300", "classificações": { "Limpeza": 5, "Localização": 4, "Geral": 5, "Quartos": 5, "Serviço": 4, "Qualidade do sono": 5, "Valor": 5 } }, { "autor": "Marguerite Crist", "content" (conteúdo): "Boa localização! Valeu a pena gastar um pouco mais com o quarto deluxe. Embora, por algum motivo estranho, o elevador sempre cheirasse a cigarro! Não sei por que?!? Os quartos para não fumantes não têm cheiro.", "data": "2013-10-21 19:04:09 +0300", "classificações": { "Limpeza": 4, "Localização": 5, "Geral": 4, "Quartos": 4, "Serviço": 3, "Valor": 3 } } ], [ { "autor": "Senhorita Alycia Schulist", "content" (conteúdo): "Um hotel incrível e moderno! Como diz meu marido: 'Fora de si'. Gostaria de ter ficado mais tempo. Uma ou duas surpresas em nosso quarto todos os dias, de pirulitos a água e chocolates. Mal posso esperar para voltar lá"., "data": "2015-08-06 06:15:56 +0300", "classificações": { "Limpeza": 5, "Geral": 5, "Serviço": 5, "Qualidade do sono": 5, "Valor": 5 } }, { "autor": "Reynold O'Connell", "content" (conteúdo): "Acabamos de voltar de uma viagem de avião a Barcelona para visitar a família e os amigos. Uma ótima desculpa para viajar a qualquer momento, mas agora que tivemos a \"experiência ME\", estamos economizando os centavos em um ritmo furioso para podermos voltar o mais rápido possível. O hotel está localizado na Avenguda Diagonal, não muito longe do edifício \"Gherkin\", e foi facilmente alcançado pelo traslado de ônibus do aeroporto e por uma curta viagem de táxi. As primeiras impressões na recepção foram realmente muito boas. É um hotel estilo butique e o ambiente é bem discreto, não pretensioso, mas muito acolhedor. Após um rápido check-in, fomos levados aos nossos quartos no 23º andar. Tivemos a sorte de reservar uma suíte e nada nos decepcionou, desde as vistas espetaculares da cidade até os móveis de alta qualidade e os extras oferecidos. Todos os aparelhos eletrônicos são da Sony, Philips etc. e os acessórios do banheiro são todos de marcas de alta qualidade. O hotel fornece praticamente tudo no quarto para a sua estadia como padrão e qualquer outra coisa está a apenas uma ligação telefônica para a recepção. Nossos quartos também significavam que tínhamos acesso ao \"Level\". Esse é um lounge no 25º andar, onde os hóspedes podem se beneficiar de cerveja, vinho, destilados e lanches leves de cortesia, que são renovados durante todo o dia. É um ótimo lugar para se reunir para o café da manhã ou para tomar um drinque antes de se aventurar pela cidade. O restaurante do hotel foi recentemente premiado com sua primeira estrela Michelin e conhecemos o chef em um passeio pelo hotel. Ele teve grande prazer em nos mostrar suas cozinhas, que estavam se preparando para os pratos daquela noite. E isso também resume toda a atitude da equipe desse hotel. Obviamente, todos eles têm orgulho de seu hotel e do trabalho que realizam nele. Se puderem fazer algo por você, farão bem feito e de maneira adorável. Nossa estada em Barcelona foi muito melhorada por nossa estada no hotel ME - espero que a sua também seja", "data": "2014-05-11 05:34:53 +0300", "classificações": { "Limpeza": 5, "Localização": 4, "Geral": 5, "Quartos": 5, "Serviço": 5, "Qualidade do sono": 5, "Valor": 5 } }, { "autor": "Elton Willms IV", "content" (conteúdo): "Quando você chega depois de um dia de turismo às 17h30 e seu quarto ainda não foi limpo... Deixo a seu critério decidir se esse é o seu tipo de hotel. Então agora você tem que esperar na passagem ou no saguão para que eles limpem o quarto...! (NÃO, não deixamos acidentalmente as placas \"Não perturbe\" na porta ou qualquer outra coisa que pudesse impedi-los de limpar o quarto - estávamos fora do quarto às 9h). Também tenho os seguintes comentários sobre o hotel: 1. Quartos pequenos 2. Não há instalações para chá/café no quarto - o serviço de quarto levou 35 minutos para entregar 4 cafés a um custo de cerca de EUR 20 3. Não há banheira - é claro que o hotel é divertido, mas um bom banho depois de um dia de passeio é muito bom. 4. Concordo com o crítico anterior em relação aos interruptores de luz/cortina, que podem ser confusos. Sou da área de TI e levei um tempo para resolver isso. O controle deslizante da cortina em nosso quarto estava fora de serviço. 5. A iluminação do quarto não é adequada para trabalhar. Algumas pessoas têm a sorte de sair em uma viagem de trabalho ou férias sem ter que trabalhar à noite, mas eu tive que fazer isso e foi muito cansativo para os olhos. 6. A localização NÃO fica perto de La Rambla ou do Gothic Q, como sugerido por outros avaliadores. Não há retorno rápido para o hotel. A estação de metrô mais próxima fica a cerca de 3 quadras de distância. Devo dizer que é agradável e tranquilo. 7. Privacidade no banheiro. Acho que alguns hóspedes podem achar isso espetacular - eu não. Se o preço for seu fator determinante, talvez você goste desse hotel. Por favor, não espere o charme do velho mundo. Tudo isso é aço e vidro muito moderno.", "data": "2014-06-09 15:13:13 +0300", "classificações": { "Limpeza": 3, "Localização": 2, "Geral": 2, "Quartos": 2, "Serviço": 2, "Qualidade do sono": 2, "Valor": 3 } }, { "autor": "Arjun Turner", "content" (conteúdo): "Nós (eu e meu marido) já estivemos em muitos hotéis em toda a Europa, mas realmente não acho que voltaremos a visitar esse hotel em particular no futuro. Ficamos no ME Barcelona entre 11/09 e 17/09 durante um congresso médico do qual meu marido teve que participar. Nosso quarto tinha vista para a piscina e parte da cidade (ficava no 7º andar), mas não era a localização que importava. Não havia luminária na escrivaninha e a luminária sobre o sofá não funcionava, assim como a minha luminária de leitura (do meu lado da cama) não funcionava. O único local suportável para fazer tudo isso era apenas UM LADO DA CAMA. Além de tudo isso (e o mais irritante), toda vez que o chuveiro do quarto logo acima do nosso era usado, a água do teto corria dentro do nosso próprio chuveiro. Devo mencionar que a TV não funcionava? (Mencionamos o problema das lâmpadas e do chuveiro ao concierge (todos eles são muito simpáticos e falam inglês muito bem) e, como resultado, alguém bateu à nossa porta uma vez e mencionou as lâmpadas, mas naquele momento eu estava descansando e não pude recebê-lo. Aparentemente, não houve uma segunda tentativa depois disso. Como ponto positivo, mencionarei que, devido a uma festa que ocorreria durante nossa última noite no hotel, nos ofereceram um quarto de nível (20º andar) para evitar o incômodo do barulho, onde todas as lâmpadas estavam funcionando, pelo menos, e você não precisaria se preocupar se o seu vizinho desconhecido do andar superior pensaria em tomar banho ao mesmo tempo que você. Além disso, o café da manhã era decente e, para todos os que gostam de design moderno e frio, o hotel é um deleite. A área é uma desvantagem, no entanto, o mau cheiro dos esgotos era, em alguns pontos, insuportável no momento em que você pisava fora do portão do hotel.", "data": "2014-09-08 13:41:38 +0300", "classificações": { "Limpeza": 3, "Localização": 2, "Geral": 2, "Quartos": 2, "Serviço": 2, "Qualidade do sono": 4, "Valor": 2 } }, { "autor": "Senhorita Abelardo Mitchell", "content" (conteúdo): "Ficamos aqui por 4 noites em junho, depois de termos passado 3 noites no W Barcelona. Fizemos a reserva no Last Minute.com, então conseguimos um preço mais barato do que as tarifas normais de quarto, porém ainda era mais caro do que outros hotéis mais próximos do centro da cidade. Estávamos querendo um pouco de luxo por uma semana e achamos que Barcelona era ideal para umas férias relaxantes na praia/sol e uma pausa na cidade. Só reservamos esse hotel porque ele tinha piscina e era classificado como 5*. Chegamos ao hotel e a fila para o check-in estava enorme, então tomamos um drinque relaxante na confortável área do bar. Para ser justo, o check-in foi rápido quando chegamos na frente da fila, mas toda a área do saguão tinha um cheiro um pouco estranho. O local está se esforçando demais para ser descolado, com escolhas de cores duvidosas para os móveis e paredes de aço??!!! Nosso quarto era bom, a cama era muito confortável e tivemos uma boa noite de sono (mas éramos acordados todas as manhãs pelas camareiras por volta das 9h). O banheiro não tinha exaustor que pudéssemos encontrar e, após o banho, a condensação escorria pelo painel de vidro que separava o quarto do banheiro e deixava marcas de sujeira no parapeito da janela. Eu não diria que o quarto era impecável, mas era adequado. O hotel estava em uma localização bastante ruim - ok, razoavelmente perto da estação de metrô mais próxima (10 minutos a pé) e da parada de bonde (5 minutos), mas muito longe da cidade. No entanto, os táxis em Barcelona são bem baratos, então isso não é um grande problema. A pior parte de nossa estadia foi que, em nosso último dia, estávamos tomando sol na área da piscina quando fomos solicitados a sair devido a uma festa particular na área. Não houve nenhum aviso prévio ou notificação sobre isso e tivemos que nos levantar e ir até a praia pelo metrô para aproveitar nosso último dia de sol (estou grávida de 5 meses de gêmeos, então esperava um dia relaxante !!!!!!!!). Eu não recomendaria esse hotel se você estiver esperando luxo de 5*. Se você está satisfeito com a qualidade e o serviço de 3-4* em uma localização bastante ruim, este hotel pode ser para você!", "data": "2013-11-27 03:52:23 +0300", "classificações": { "Limpeza": 2, "Localização": 1, "Geral": 3, "Quartos": 3, "Serviço": 2, "Qualidade do sono": 4, "Valor": 2 } }, { "autor": "Abdullah Lubowitz", "content" (conteúdo): "... nem tudo que reluz é ouro e o Hotel Me realmente não me agradou. Estávamos aqui para uma convenção de negócios e, à primeira vista, o hotel e os quartos parecem ótimos, até você tentar usá-los. O hotel fica a uma corrida de táxi de qualquer área turística de Barcelona ou a 30 minutos a pé. Há uma área decente a cerca de 8 minutos de caminhada para restaurantes, mas este NÃO é um hotel no centro da cidade. Os quartos estão tentando ser modernos e minimalistas, mas acabam sendo pouco funcionais e desconfortáveis. Aqui estão meus problemas com o quarto: 1. Não há chaleira/cafeteira no quarto. Praticamente inédito em um hotel de sua \"classe\". 2. Piso de cimento no quarto, escorregadio quando molhado e frio. Carpetes, madeira, qualquer coisa... não essa alternativa barata. 3. A cadeira na escrivaninha não é uma cadeira de estação de trabalho, mas um design de plástico barato e moderno - nada bom. 4. É impossível tomar banho sem encharcar o chão do banheiro. 5. A cortina que envolve as duas paredes... de quem foi essa ideia? Apenas uma parede tem janela, mas a cortina cobre as duas e é MUITO lenta em sua abertura/fechamento automático. Além disso, ela não fechava totalmente e deixava um espaço de 5 cm para a luz entrar às 6h da manhã. 6. Há um painel de controle para todas as luzes e o ar-condicionado. Cada botão pressionado fazia algo diferente, a cada vez. Todos com quem conversei tiveram esse problema. 7. Minibar e serviço de quarto com preços escandalosos (18 euros por um hambúrguer) e, como você está a quilômetros de distância, é um bom hotel para perda de peso! As camas eram boas, a TV era boa, as outras instalações do banheiro eram boas - e o serviço de limpeza é um dos melhores que já vi. Outros problemas. A equipe do bar é inútil. As pessoas ficavam esperando para serem servidas, enquanto dois deles abasteciam e limpavam, um servia - muito lentamente. 5 euros por um copo de 330 ml de cerveja de torneira é o dobro do preço de qualquer outro lugar onde bebemos. Do lado de fora dos elevadores, em todos os andares, havia cheiro de banheiro - provavelmente porque os banheiros dos quartos davam para essa área. Ventilação ruim? O café da manhã é servido generosamente às 11h, exceto nos fins de semana, quando é ainda melhor às 12h. Ao chegarmos às 11h05 em um sábado, fomos informados de que já havia terminado. Quando perguntamos o motivo, ela disse: "porque temos que preparar uma reunião para o almoço nesta sala". Apesar de termos dito a ela que o bilhete no quarto dizia 12 horas, quando fizemos o check-in nos disseram 12 horas - ela disse que não podia fazer nada, embora pudéssemos ver uma mesa de bufê de café-da-manhã cheia e pessoas comendo. Foi somente depois de exigir um gerente que outro membro da equipe fez uma ligação e nos deixou entrar - não deveria ter chegado a esse ponto. Fumantes - esqueçam se chover, não há nenhuma área externa coberta, nem mesmo remota ou parcialmente! No geral, esse hotel simplesmente falhou. Ele tem alguns pontos positivos, mas não é confortável, não proporciona uma sensação de luxo ou um nível de relaxamento e parece que eles não sabem o que estão fazendo.", "data": "2012-03-29 11:12:46 +0300", "classificações": { "Limpeza": 5, "Localização": 1, "Geral": 2, "Quartos": 2, "Serviço": 3, "Qualidade do sono": 2, "Valor": 1 } }, { "autor": "Kory Schultz", "content" (conteúdo): "Reservamos o ME para 9 noites, fizemos o check-out depois de 3, a equipe foi muito antipática e inútil. Os quartos estão entre os menores em que já me hospedei. Não consigo entender como esse hotel foi classificado como 5 estrelas, de jeito nenhum, no máximo 3 estrelas. As paredes do quarto estavam marcadas, os corredores pareciam nunca ter sido aspirados. As tomadas estavam soltas. No segundo dia, ninguém limpou nosso quarto ou arrumou a cama, tivemos que ligar duas vezes para pedir rolos de papel higiênico e toalhas, o ar-condicionado não passou das 23 horas. Mal podíamos esperar para fazer o check-out e nos mudamos para o Arts Hotel, onde encontramos um verdadeiro hotel 5 estrelas", "data": "2014-05-19 00:36:42 +0300", "classificações": { "Limpeza": 1, "Localização": 2, "Geral": 1, "Quartos": 1, "Serviço": 1, "Valor": 1 } }, { "autor": "Curt Nolan", "content" (conteúdo): "Um hotel visualmente impressionante. Os quartos eram compactos, mas muito bem projetados. Não há indícios de problemas com odores, música e ralos que tenham sido mencionados em avaliações anteriores. MAS - dois grandes problemas: 1. Depois de ser informado de que eu tinha direito a passar uma peça de roupa por dia - de cortesia -, dei minha camisa para a senhora muito charmosa que me mostrou o quarto. A camisa só apareceu 45 minutos depois que eu deveria sair na manhã seguinte, o que me atrasou para uma reunião. Também tive que fazer várias ligações para receber a camisa de volta. 2. O sanduíche de 22 euros com batatas fritas não era comestível. Uma vergonha. Não importa o quanto um hotel seja bonito e elegante, se ele não consegue fazer o básico direito, ele deve e vai fracassar. Eu teria recomendado esse hotel de todo o coração às 21 horas do dia da minha chegada - agora, não recomendo mais. É por isso que é uma pena.", "data": "2014-08-09 00:49:46 +0300", "classificações": { "Limpeza": 5, "Localização": 3, "Geral": 2, "Quartos": 5, "Serviço": 1, "Valor": 3 } } ], [ { "autor": "Ozella Sipes", "content" (conteúdo): "Esta foi nossa segunda viagem aqui e gostamos tanto ou mais do que no ano passado. Excelente localização, em frente ao French Market e do outro lado da rua da parada do bonde. Muito conveniente para vários restaurantes pequenos, mas bons. Muito limpo e bem conservado. A equipe de limpeza e os outros funcionários são todos simpáticos e prestativos. Gostamos muito de sentar no terraço do segundo andar sobre a entrada e "observar as pessoas" na Esplanade Ave. e conversar com nossos colegas hóspedes. Alguns móveis poderiam ser um pouco atualizados ou substituídos, mas nada de mais.", "data": "2013-06-22 18:33:50 +0300", "classificações": { "Limpeza": 5, "Localização": 4, "Geral": 4, "Quartos": 3, "Serviço": 5, "Valor": 4 } }, { "autor": "Barton Marks", "content" (conteúdo): "Encontramos o hotel de la Monnaie por meio da Interval e pensamos em experimentá-lo enquanto participávamos de uma conferência em Nova Orleans. Esse lugar tinha uma localização perfeita e definitivamente superou a estadia no centro da cidade, no Hilton, com o restante dos participantes. Estávamos bem na orla do French Quarter, a uma curta distância a pé de toda a área. A localização na Esplanade é mais uma área residencial, portanto, você está perto da diversão, mas longe o suficiente para desfrutar de um tempo de descanso tranquilo. Adoramos o bonde do outro lado da rua e o levamos até o centro de conferências nos dias em que participamos da conferência. Também o pegamos na Canal Street e quase chegamos ao museu da Segunda Guerra Mundial. De lá, pudemos pegar uma carona para o Garden District - uma visita obrigatória se você gosta de arquitetura antiga - belas casas antigas (mansões). No almoço, comemos no Joey K's e estava excelente. Comemos em tantos lugares no French Quarter que não consigo me lembrar de todos os nomes. Meu marido adorou todas as comidas do NOL - gumbo, jambalya e muito mais. Ainda bem que encontramos o Louisiana Pizza Kitchen do outro lado da U.S. Mint (do outro lado da rua da Monnaie). Um lugar pequeno, mas com uma pizza excelente! No dia em que chegamos, estava acontecendo um grande festival de jazz do outro lado da rua. No entanto, uma vez em nossos quartos, não era possível ouvir nenhum barulho externo. Apenas o trem à noite apitando! Gostamos de estar tão perto do French Market e a uma curta distância de todos os locais para visitar. E você não pode deixar de visitar o Cafe du Monde, no final da rua - um lugar movimentado e com as melhores rosquinhas francesas!!! Delicioso! Com certeza voltaremos e ficaríamos aqui novamente. Não fomos pressionados a comprar nada. Meu marido recebeu apenas uma ligação telefônica sobre timeshare e a mulher foi muito agradável. A equipe era descontraída e amigável. Minha única reclamação foi a cama muito firme. Fora isso, gostamos muito de nossa estadia. Obrigado, Hotel de la Monnaie!", "data": "2015-03-02 19:56:13 +0300", "classificações": { "Serviço comercial (por exemplo, acesso à Internet)": 4, "Check-in / recepção": 4, "Limpeza": 4, "Localização": 4, "Geral": 4, "Quartos": 3, "Serviço": 3, "Valor": 5 } } ] ], "tipo": "array" }, "estado": { "#docs": [ 21, 2 ], "%docs": [ 91.3, 8.69 ], "amostras": [ [ nulo ], [ "Califórnia" ] ], "tipo": [ "null", "string" ] }, "título": { "#docs": 23, "%docs": 100, "amostras": [ "Parque Nacional do Vale da Morte", "Gillingham (Kent)", "Parque Nacional Joshua Tree", "Paris/16º arrondissement", "Pitlochry" ], "tipo": "string" }, "tollfree": { "#docs": [ 22, 1 ], "%docs": [ 95.65, 4.34 ], "amostras": [ [ nulo ], [ "+1-000-821-8277" ] ], "tipo": [ "null", "string" ] }, "tipo": { "#docs": 23, "%docs": 100, "amostras": [ "hotel" ], "tipo": "string" }, "url": { "#docs": [ 2, 21 ], "%docs": [ 8.69, 91.3 ], "amostras": [ [ nulo ], [ "http://paris-hotel-longchamp.c...", "http://www.number38thegower.co...", "http://www.syha.org.uk/hostels...", "http://www.walestouristsonline...", "http://www.yha.org.uk" ] ], "tipo": [ "null", "string" ] }, "vaga": { "#docs": 23, "%docs": 100, "amostras": [ falso, verdadeiro ], "tipo": "booleano" } }, "tipo": "objeto" }, { "#docs": 3, "$schema": "http://json-schema.org/draft-06/schema", "Sabor": "`type` = \"airline\"", "propriedades": { "indicativo": { "#docs": 3, "%docs": 100, "amostras": [ "BEE MED", "CYCLONE", "REUNIÃO" ], "tipo": "string" }, "país": { "#docs": 3, "%docs": 100, "amostras": [ "França", "Reino Unido", "Estados Unidos" ], "tipo": "string" }, "iata": { "#docs": 3, "%docs": 100, "amostras": [ "KJ", "UU", "ZA" ], "tipo": "string" }, "icao": { "#docs": 3, "%docs": 100, "amostras": [ "CYD", "LAJ", "REU" ], "tipo": "string" }, "id": { "#docs": 3, "%docs": 100, "amostras": [ 792, 1191, 1543 ], "tipo": "número" }, "name" (nome): { "#docs": 3, "%docs": 100, "amostras": [ "Access Air", "Air Austral", "British Mediterranean Airways" ], "tipo": "string" }, "tipo": { "#docs": 3, "%docs": 100, "amostras": [ "companhia aérea" ], "tipo": "string" } }, "tipo": "objeto" }, { "#docs": 49, "$schema": "http://json-schema.org/draft-06/schema", "Sabor": "`type` = \"airport\"", "propriedades": { "nome do aeroporto": { "#docs": 49, "%docs": 100, "amostras": [ "Base da Força Aérea de Hickam", "Joigny", "RNAS WATTON", "Sky Ranch em Carefree", "Villaroche" ], "tipo": "string" }, "cidade": { "#docs": 49, "%docs": 100, "amostras": [ "Carefree" (despreocupado), "Honolulu", "Joigny", "Melun", "WATTON" ], "tipo": "string" }, "país": { "#docs": 49, "%docs": 100, "amostras": [ "França", "Reino Unido", "Estados Unidos" ], "tipo": "string" }, "faa": { "#docs": [ 13, 36 ], "%docs": [ 26.53, 73.46 ], "amostras": [ [ nulo ], [ "BZR", "GRI", "IGQ", "PRC", "RCA" ] ], "tipo": [ "null", "string" ] }, "geo": { "#docs": 49, "%docs": 100, "propriedades": { "alt": { "#docs": 49, "%docs": 100, "amostras": [ 13, 173, 302, 732, 2568 ], "tipo": "número" }, "lat": { "#docs": 49, "%docs": 100, "amostras": [ 21.318681, 33.8180947, 47.992222, 48.604725, 52.33 ], "tipo": "número" }, "longo": { "#docs": 49, "%docs": 100, "amostras": [ -157.922427, -111.8979242, 0.51, 2.671119, 3.392222 ], "tipo": "número" } }, "amostras": [ { "alt": 13, "lat": 21.318681, "longo": -157.922427 }, { "alt": 173, "lat": 52.33, "longo": 0.51 }, { "alt": 302, "lat": 48.604725, "longo": 2.671119 }, { "alt": 732, "lat": 47.992222, "longo": 3.392222 }, { "alt": 2568, "lat": 33.8180947, "longo": -111.8979242 } ], "tipo": "objeto" }, "icao": { "#docs": [ 7, 42 ], "%docs": [ 14.28, 85.71 ], "amostras": [ [ nulo ], [ "18AZ", "EGYR", "LFGK", "LFPM", "PHIK" ] ], "tipo": [ "null", "string" ] }, "id": { "#docs": 49, "%docs": 100, "amostras": [ 1310, 1384, 4346, 7055, 8397 ], "tipo": "número" }, "tipo": { "#docs": 49, "%docs": 100, "amostras": [ "aeroporto" ], "tipo": "string" }, "tz": { "#docs": 49, "%docs": 100, "amostras": [ "America/Phoenix", "Europa/Londres", "Europa/Paris", "N", "Pacífico/Honolulu" ], "tipo": "string" } }, "tipo": "objeto" } ] ], "status": "sucesso", "métricas": { "elapsedTime" (tempo decorrido): "441.291712ms", "executionTime": "441.241719ms", "resultCount": 1, "resultSize": 103887 }, "profile" (perfil): { "phaseTimes": { "autorizar": "753.932µs", "instanciar": "6.388µs", "parse" (analisar): "151.233µs", "plano": "7.117µs", "executar": "441.069318ms" }, "phaseOperators": { "autorizar": 1 }, "executionTimings": { "#operator": "Authorize" (Autorizar), "#stats": { "#phaseSwitches": 4, "execTime": "1.738µs", "servTime": "752.194µs" }, "privilégios": { "Lista": [ { "Alvo": "amostra de viagem", "Priv": 7 } ] }, "~child": { "#operator": "Sequência", "#stats": { "#phaseSwitches": 1, "execTime": "9.743µs" }, "~crianças": [ { "#operator": "InferKeyspace", "#stats": { "#itemsOut": 1, "#phaseSwitches": 7, "execTime": "9.345µs", "kernTime": "438.011515ms" }, "espaço-chave": "amostra de viagem", "namespace": "", "usando": "default" }, { "#operator": "Fluxo", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 6, "execTime": "2.257622ms", "kernTime": "438.028393ms" } } ] }, "~versões": [ "7.0.0-N1QL", "7.0.0-1784-enterprise" ] } } } |
EXPLICAR
O Explain informa o plano de consulta para cada consulta - os índices escolhidos, os predicados e outros pushdowns, os tipos de junção, a ordem de junção etc. Tanto o MongoDB quanto o Couchbase produzem o explain em formato JSON - algo natural para bancos de dados JSON.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
MongoDB Empresa > db.CLIENTE.encontrar({zíper:94040}).explicar() { "queryPlanner" : { "plannerVersion" : 1, "namespace" : "test.CUSTOMER", "indexFilterSet" : falso, "parsedQuery" : { "zip" : { "$eq" : 94040 } }, "winningPlan" : { "estágio" : "FETCH", "inputStage" : { "estágio" : "IXSCAN", "keyPattern" : { "zip" : 1 }, "indexName" : "zip_1", "isMultiKey" : falso, "multiKeyPaths" : { "zip" : [ ] }, "isUnique" : falso, "isSparse" : falso, "isPartial" : falso, "indexVersion" : 2, "direção" : "avançar", "indexBounds" : { "zip" : [ "[94040.0, 94040.0]" ] } } }, "rejectedPlans" : [ ] }, "serverInfo" : { "host" : "MacBook-Pro-4.attlocal.net", "porta" : 27017, "versão" : "4.0.0", "gitVersion" : "3b07af3d4f471ae89e8186d33bbb1d5259597d51" }, "ok" : 1 } MongoDB Empresa > |
No Couchbase, basta prefixar a declaração com EXPLAIN. Você pode explicar qualquer declaração no N1QL.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
EXPLICAR SELECIONAR * DE CLIENTE ONDE zíper = 94040; [ { "plano": { "#operator": "Sequência", "~crianças": [ { "#operator": "IndexScan3", "índice": "ix_customer", "index_id": "b312ed00505a074d", "index_projection": { "primary_key": verdadeiro }, "espaço-chave": "CLIENTE", "namespace": "default", "vãos": [ { "exato": verdadeiro, "intervalo": [ { "alto": "94040", "inclusão": 3, "baixo": "94040" } ] } ], "usando": "gsi" }, { "#operator": "Buscar", "espaço-chave": "CLIENTE", "namespace": "default" }, { "#operator": "Paralelo", "~child": { "#operator": "Sequência", "~crianças": [ { "#operator": "Filtro", "condição": "((`CUSTOMER`.`zip`) = 94040)" }, { "#operator": "InitialProject" (Projeto inicial), "result_terms": [ { "expr": "self", "estrela": verdadeiro } ] } ] } } ] }, "texto": "SELECT * FROM CUSTOMER WHERE zip = 94040;" } ] |
O workbench de consulta também tem uma explicação visual, juntamente com a criação de perfis. (para uma consulta)
A cláusula "GROUP BY" do MongoDB faz parte da API aggregate(). Aqui está a comparação.
Diferentemente do SQL e do N1QL, a API de consulta do MongoDB tem muitos significados implícitos sem definições formais. Com N1QL, você está ciente dos agrupamentos (b e c) e agregações (SUM(a)) explicitamente.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
/* MongoDB */ Agrupamento e agregação é combinado. $grupo : { [ { a: "$a"}, {b: "$b"}, {c: "$c"}, contagem: { $soma: 1 } ] } /* Couchbase: N1QL */ SELECIONAR b, c, SUM(a) DE t GRUPO BY b, c |
|
1 2 3 4 5 6 |
/* MongoDB */ ORDEM BY { $classificar : { idade : -1, postagens: 1 } } /* Couchbase: N1QLL */ ORDEM BY idade DESC, postagens ASC |
OFFSET e LIMIT
Eles são comumente usados para o método de paginação de deslocamento, suportado pelo Mongo e pelo Couchbase. No entanto, paginação do conjunto de teclas é uma abordagem superior que utiliza menos recursos e tem melhor desempenho. O Mongo usa as cláusulas $skip e $limit e o N1QL usa OFFSET e LIMIT. Não tenho certeza sobre as otimizações de paginação feitas no MongoDB.
As junções são geralmente desencorajadas em bancos de dados NoSQL e no MongoDB em particular. Mas o mundo real é complexo e não pode ser desnormalizado em uma única coleção. O MongoDB tem o operador $lookup para a união e faz um loop aninhado entre uma coleção (potencialmente fragmentada) e outra coleção (não pode ser fragmentada). No Couchbase, todos os buckets são particionados (sharded). Operações JOINs (INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, junções com subconsultas, NEST e UNNEST) Temos um artigo detalhado que mostra as operações equivalentes entre o MongoDB e o JSON. Recomendo que você leia o artigo Juntando JSON: comparando Couchbase e MongoDB.
| Tipo de JOIN | MongoDB | Couchbase |
| INNER JOIN | Não. O $lookup é uma união externa esquerda limitada somente em coleções sem fragmentos. Os aplicativos precisam fazer isso e, em seguida, remover os documentos sem os documentos correspondentes. | A cláusula ON requer referência à chave do documento. Somente Equi-join |
| UNIÃO EXTERNA ESQUERDA | $lookup limitado.
Não é possível unir matrizes. É necessário achatar as matrizes manualmente antes da união. |
União externa esquerda completa, incluindo predicados de matriz na cláusula ON. |
| UNIÃO EXTERNA DIREITA | Sem suporte. Deve ser tratado no aplicativo | Suporte limitado a RIGHT OUTER JOIN; foi possível contornar o problema com o uso de outros JOINs. |
| JUNÇÃO EXTERNA COMPLETA | Sem suporte. Deve ser tratado no aplicativo | Trabalhou com o uso de outros JOINs. |
|
1 2 3 4 5 6 7 8 9 |
/* MongoDB */ db.grantPrivilegesToRole() db.revokePrivilegesFromRole (revogar privilégios da função)() /* Couchbase: N1QL */ CONCESSÃO consulta_seleção ON pedidos, clientes PARA conta, linda; REVOGAÇÃO query_update ON `viagens-amostra` DE debby |
ÍNDICES
Abaixo está uma visão geral dos recursos de índice do MongoDB e do Couchbase. Ambos têm uma variedade de índices. Os tipos e o uso do índice do Couchbase estão bem documentados no artigo: Crie o índice certo e obtenha o desempenho certo. Além disso, o Couchbase tem um consultor de índice integrado para a declaração individual bem como o carga de trabalho e, além disso, tem o Serviço de consultoria de índices que é atualizado mensalmente.
| Tipo de índice | MongoDB | Couchbase |
| Índice primário | Varreduras de tabela, índice primário | Índice primário |
| Índice secundário | Índice secundário | Índice secundário |
| Índice composto | Índice composto | Índice composto |
| Índice funcional
(Índice de Expressão) |
Não disponível | Índice Funcional, Índice de Expressão |
| Índice parcial | Não disponível | Índice parcial |
| Índice particionado de intervalo | Índice particionado por intervalo, Intervalo, Lista, Ref, Hash, Índice particionado híbrido | Intervalo manual particionado usando o Índice parcial |
| Índice ARRAY | 1. Índice baseado em B-Tree com uma chave de matriz por índice.
2. A chave de uma matriz pode ser simples ou composta (várias chaves). |
1. Índice baseado em árvore B com uma chave de matriz por índice.
2. A chave da matriz pode ser composta 3. Usando SEARCH(): Índice baseado em árvore invertida com um número ilimitado de chaves de matriz por índice. |
| Índice de matriz em expressões | Não disponível | Sim |
| Objetos | Sim | Sim |
PESQUISA DE TEXTO COMPLETO
O produto MongoDB tem pesquisa de texto e agora está experimentando a integração do Lucene em seu serviço Atlas por meio do $searchbeta recurso. O Couchbase tem um recurso indexação de pesquisa de texto completo que pode ser executado em seu laptop e no cluster. Novamente, temos um artigo detalhado comparando o pesquisa de texto, recurso por recursocom exemplos. O Couchbase 6.5 integra o FTS com N1QLtornando a consulta ainda mais complexa.
OTIMIZADOR
Um otimizador de consultas tenta reescrever a consulta para melhor otimização, escolher o índice mais adequado, decidir o pushdown do índice, a ordem de junção, o tipo de junção e criar um plano que o mecanismo possa executar. Cada banco de dados tem um otimizador especializado que entende os recursos e as peculiaridades do mecanismo.
| Recurso | MongoDB | Couchbase |
| Tipo de otimizador | Consulta baseada em forma | Baseado em regras |
| Seleção de índice | Consulta baseada em forma | Baseado em regras
Baseado em custos (visualização em 6.5) |
| Reescrita de consulta | Não | Sim, limitado. |
| JOIN Order | Como está escrito, procedimento que usa a estrutura de agregação | Especificado pelo usuário (da esquerda para a direita) |
| Tipo de associação | Loop aninhado | Loop aninhado
Junção de Hash |
| DICAS | Sim. $hint | Sim.
USAR ÍNDICE, USAR HASH |
| EXPLICAR | 1TP4Explicar | EXPLICAR |
| Explicação visual | Sim | Sim. |
| Criação de perfil de consulta | Sim | sim |
TRANSAÇÕES
Os bancos de dados NoSQL foram inventados para evitar SQL e transações. Com o tempo, cada banco de dados está adicionando um ou outro, ou ambos! O MongoDB adicionou o transações com vários documentos com isolamento de snapshot. O Couchbase adicionou o transações com vários documentos com isolamento de confirmação de leitura. As transações de vários documentos ainda não são compatíveis com o N1QL.
| Recurso | MongoDB | Couchbase |
| Atualizações do índice | Os índices são mantidos de forma síncrona | Os índices são mantidos de forma assíncrona |
| Atomicidade | Documento único
Multi-documento (em 4.2) |
Documento único
Multi-documento (na versão 6.5) |
| Consistência | Os dados e os índices são atualizados de forma síncrona. Por padrão, leitura suja nos dados e índices. | O acesso aos dados é sempre consistente
Os índices têm vários níveis de consistência (UNBOUNDED, AT_PLUS, REQUEST_PLUS) |
| Isolamento | Padrão: Leitura suja
Transação: Isolamento de instantâneos |
Bloqueio otimista com verificação de CAS
Transações: Isolamento atômico monotônico |
| Durabilidade | Durável com opção de maioria de gravação. | Durável com confirmação após a replicação |
ANALÍTICA
Análise do Couchbase foi projetado para fornecer insights sobre seus dados JSON sem ETL - NoETL para NoSQL. Os dados JSON no armazenamento de dados de valor-chave são copiados para o serviço de análise que distribui os dados em seu armazenamento. O serviço de consulta e o serviço de dados do Couchbase foram projetados para lidar com um grande número de operações ou consultas simultâneas para executar os aplicativos. O serviço de análise foi projetado para analisar um grande número de documentos para fornecer insights sobre os negócios. Em termos tradicionais, o serviço de análise é projetado para OLAP, e os demais são projetados para OLTP. O MongoDB não tem um serviço de análise equivalente. Você teria que sobrecarregar seu cluster existente com cargas de trabalho OLTP e OLAP. Como você aprenderá, não existe almoço grátis. As grandes varreduras necessárias para a carga de trabalho de análise afetarão as latências de suas consultas OLTP. Em seguida, você começa a alocar novos nós para suas cópias secundárias e terciárias dos dados nos quais você pode fazer a carga de trabalho de leitura. O que acontecerá ou deverá acontecer em um failover? O secundário assume o controle, mas novamente afeta sua carga de trabalho OLTP.
Há um segundo motivo para um serviço distinto: o processamento de consultas para análise requer uma abordagem diferente das consultas OLTP. Há um grande conjunto de recursos para você aprender sobre esse serviço, incluindo o livro de Don Chamberlin, co-inventor do SQL.
- SQL++ para usuários de SQL: UM TUTORIAL: https://resources.couchbase.com/analytics/sql-book
- Couchbase Analytics: Sob o capô - Connect Silicon Valley 2018: https://www.youtube.com/watch?v=1dN11TUj58c
- De SQL para NoSQL
- Além das linhas e colunas: A quarta vez é o charme - Couchbase Connect 2016: https://www.youtube.com/watch?v=HVJNxgLKtbo
- NoETL para NoSQL - Análise em tempo real com o Couchbase: https://www.youtube.com/watch?v=MIno71jTOUI
- N1QL: Consultar ou analisar?
- Parte 2: N1QL: Consultar ou analisar?
Resumo: Parte dois
Os bancos de dados são extraordinariamente úteis. Eles têm nuances e também são pegajosos. Eles são essenciais para a civilização. Os sumérios inventaram a escrita para o processamento de transações: criar um banco de dados a partir de tábuas de argila para manter o controle de impostos, terras, ouro e descobrir informações. Haverá bancos de dados para sempre. Cada banco de dados é diferente - sejam eles bancos de dados SQL ou bancos de dados NoSQL. Nem todos os bancos de dados SQL são iguais. Nem todos os bancos de dados NoSQL são iguais. A compreensão dos diferentes bancos de dados aumenta a flexibilidade e a eficácia de sua organização.
RECURSOS: Parte Dois
- SQL++ para usuários de SQL: UM TUTORIAL: https://resources.couchbase.com/analytics/sql-book
- N1QL Guias práticos
- Blogs do Couchbase 6.5: https://www.couchbase.com/blog/tag/6.5/