Tenho o prazer de anunciar o Multi-Dimensional Scaling.
Nós reinventamos e redefinimos a maneira como as empresas dimensionam um banco de dados distribuído com o Multi-Dimensional Scaling. É a opção de separar, isolar e dimensionar serviços de banco de dados individuais - consulta, índice e dados - para melhorar o desempenho e a utilização de recursos.
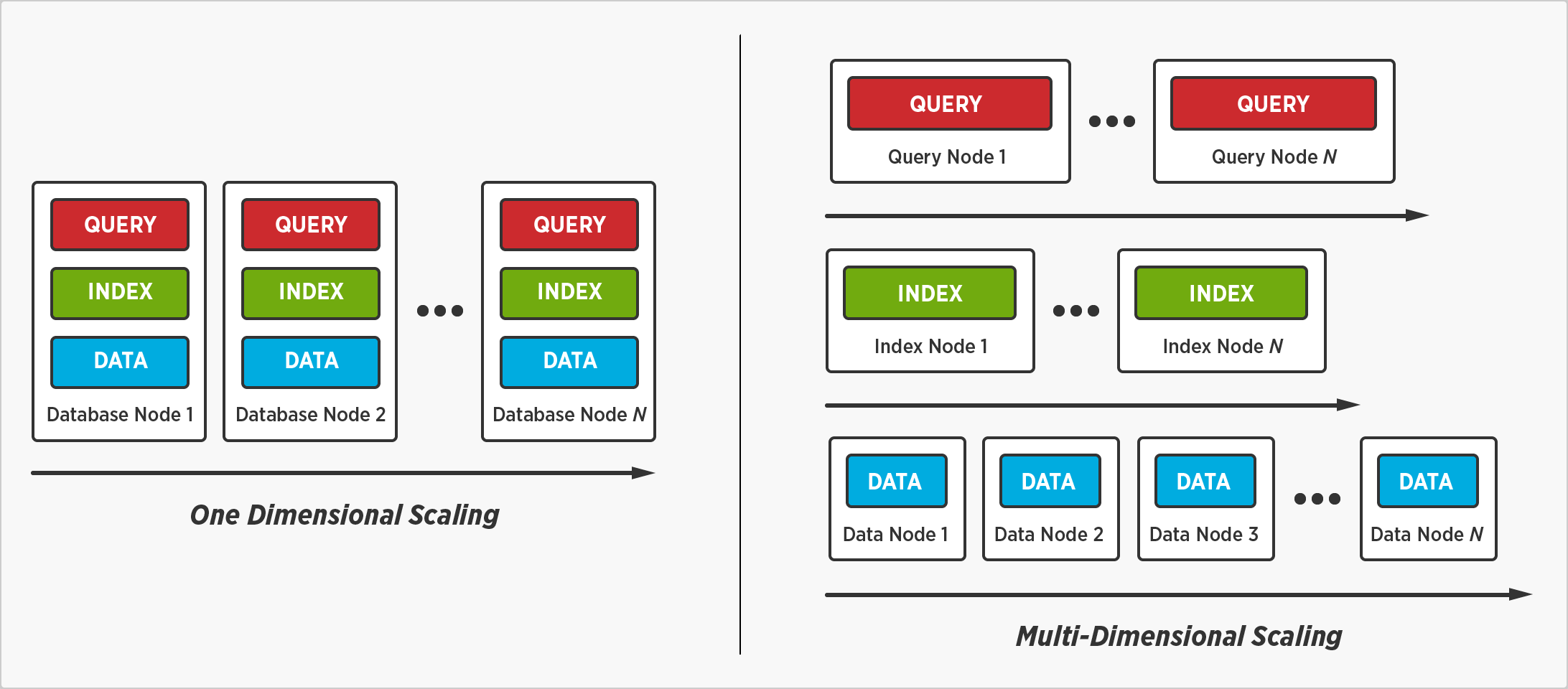
Distribua os dados, não a execução de consultas e os índices
O dimensionamento multidimensional nos permite distribuir dados sem distribuir a execução de consultas e índices. Uma consulta será concluída mais rapidamente se não for executada em todos os nós, e um índice será pesquisado mais rapidamente se não for armazenado em todos os nós.
Otimize o hardware para o serviço, não para o banco de dados
O dimensionamento multidimensional nos permite oferecer suporte a vários perfis de hardware, executando diferentes serviços em diferentes nós. Como resultado, cada nó não precisa ter o processador mais rápido, a unidade de estado sólido mais rápida e a maior quantidade de memória.
- Embora os nós de consulta exijam um processador mais rápido, os nós de índice e de dados não precisam.
- Embora os nós de índice exijam uma unidade de estado sólido mais rápida, os nós de consulta não precisam.
- Embora os nós de dados precisem de mais memória, os nós de consulta e índice não precisam.
Eliminar a contenção de recursos
O dimensionamento multidimensional nos permite eliminar a contenção de recursos executando diferentes serviços em diferentes nós. Quando as consultas são executadas em nós separados, não há contenção de CPU entre as consultas e as leituras ou gravações. Quando os índices são armazenados em nós separados, não há contenção de E/S de disco entre os índices e as leituras ou gravações.
O Multi-Dimensional Scaling melhora o desempenho:
- Armazenamento de dados e índices em nós separados - sem contenção de E/S de disco
- Armazenamento de dados e execução de consultas em nós separados - sem contenção de CPU
- Execução de uma consulta sem distribuí-la a todos os nós - sem sobrecarga de rede
- Armazenamento de um índice sem distribuí-lo para todos os nós - sem sobrecarga de rede
O Multi-Dimensional Scaling melhora a utilização de recursos:
- Configuração de nós de serviço de consulta com processadores rápidos, sem SSDs e com menos memória
- Configuração de nós de serviço de índice com SSDs rápidos e menos memória.
- Configuração de nós de serviço de dados com mais memória e um HDD ou SSD.
Conceitos
Serviços da Elastic permitem o dimensionamento independente dos serviços de dados, índice e consulta. O serviço de dados pode ser dimensionado sem dimensionar os serviços de consulta ou índice.
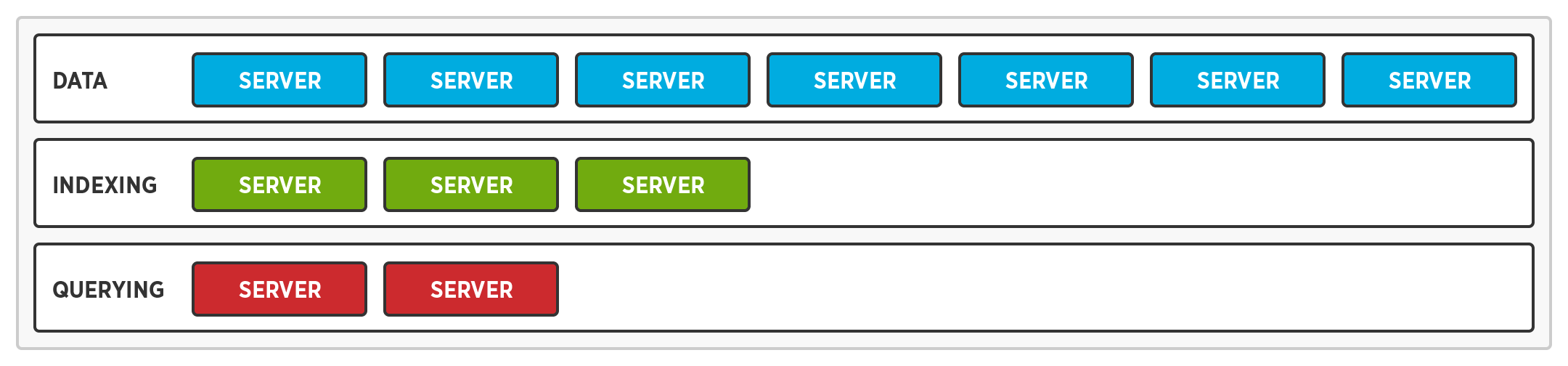
Otimização de serviços permite que o hardware de um nó seja otimizado com base no serviço que está sendo executado. Afinal de contas, os requisitos de hardware para os serviços de consulta, índice e dados são diferentes.
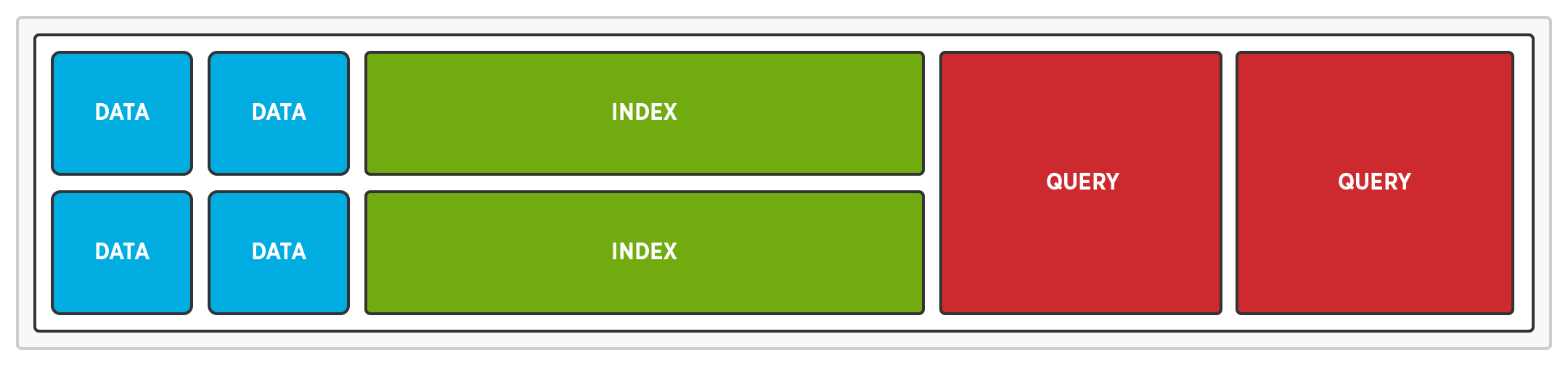
Isolamento de serviço garante que os serviços de consulta, índice e dados não sofram com a contenção de recursos. Ele isola os serviços de consulta, índice e dados para evitar que as consultas e os índices reduzam a velocidade das leituras e gravações.

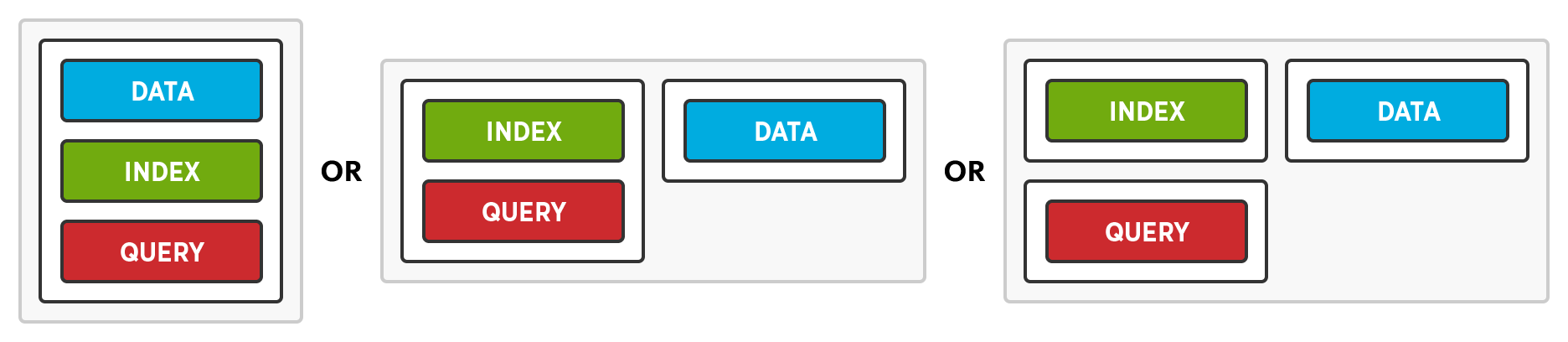
Implementação flexível permite que os administradores decidam se querem ou não aproveitar o Multi-Dimensional Scaling. Quando um nó é adicionado, os administradores podem ativar todos os serviços, alguns dos serviços ou apenas um dos serviços.
Saiba mais sobre o Multi-Dimensional Scaling e descubra o que está por vir no Couchbase Server 4.0 aqui.
Discutir sobre Notícias Hacker
Vocês já pensaram em localidade de dados? Sharding por uma coluna personalizada
como \"user_id\", dessa forma, todos os dados estarão em um nó e
as consultas complexas serão mais rápidas, pois nenhum dado será transferido entre
nós.
Ou até mesmo a fragmentação por um subconjunto da chave primária (como a fragmentação regex feita pelo redislabs)
Obrigado pela menção - fico feliz que tenha gostado do recurso de fragmentação de regex, temos muito orgulho dele :)
Isso não limitaria as consultas a um único campo - a coluna personalizada? Você poderia fragmentar por cidade do usuário e consultar os usuários por cidade, mas e se você quiser consultar os usuários por idade também? E se a sua consulta unir usuários e compras?
Se você quiser que sua consulta atinja um nó/ fragmento específico, deverá incluir o \"user_id\" e adicionar outras cláusulas.
Se quiser consultar por outro atributo (obter todos os usuários com idade), você atingirá todos os nós.
O problema com a sua maneira é que você armazena o índice em um nó separado (portanto, SEMPRE haverá tráfego entre nós, mesmo para consultas básicas \"select column from user where whatever_filter (column is not indexed))\".
No seu caso, cada consulta atingirá todos os nós de índice, por mais rápidos que sejam, eles se desintegrarão depois de algum tempo, pois cada nó terá que responder a cada consulta, mesmo que todos os dados estejam na memória, pois cada servidor tem uma quantidade limitada de CPU.
A única maneira de ter um escalonamento REAL (você não pode criar aplicativos APENAS com o kv-access, pode criar apenas alguns recursos) é seguir o caminho do particionamento automático de intervalo (como hbase, hypertable).
Outra maneira (mais fácil de fazer, com menos recursos) é fazer a fragmentação por uma coluna personalizada.
Esse é o benefício do MDS. Não atingiremos todos os nós. Posso criar um índice para cidade. O índice inteiro será armazenado em um dos nós de índice. Um nó de consulta enviará uma solicitação a esse nó de índice. Ele retornará todos os IDs de usuário correspondentes (cidade=Chicago). O nó de consulta obterá então esses usuários (e somente dos nós que os contêm). Ele não precisa enviar uma solicitação a cada nó.
E se o índice crescer mais do que 1 nó?
Acho que consideraríamos a possibilidade de dividir um índice e armazená-lo em vários nós de índice. No entanto, não posso deixar de me perguntar quantos índices exigirão terabytes de espaço em disco, já que eles serão compactados com o Snappy.
Suponha que você queira indexar todos os objetos da tabela (o que normalmente faz). Agora, cada inserção/atualização/exclusão precisa ir para esse único nó de índice.
A maneira mais frequente é colocar dados + índice no mesmo nó.
Mais ou menos, os índices serão atualizados de forma assíncrona por padrão. Eles não reduzirão a velocidade das gravações, independentemente de quantos forem. Dito isso, uma consulta pode ser enviada com uma opção para forçar uma atualização de índice primeiro. Alguns dos problemas com a localização conjunta de dados e índices são a sobrecarga da rede e as junções. Essa é a maneira mais frequente porque a) é fácil e b) outros fornecedores estão dispostos a excluir as uniões. Como lembrete, estamos falando de índices secundários, não do índice primário.