O pO objetivo é muito simples: no mundo das tecnologias díspares em que uma não funciona ou não se integra bem à outra, o Couchbase e o Confluent Kafka são produtos incríveis e extremamente complementares entre si. O Couchbase é um banco de dados NoSQL JSON distribuído e linearmente dimensionável. Seu principal caso de uso é para qualquer aplicativo/serviço da Web que exija um único dígito ms latência de resposta de leitura/gravação/atualização. Ele pode ser usado como sistema de registro (SoR) ou camada de cache para dados transitórios de mutação rápida ou descarregar o Db2/Oracle/SQL Server etc. para que os serviços downstream possam consumir dados do Couchbase.
CO Confluent Kafka é uma plataforma completa de streaming distribuído que também é linearmente dimensionável e capaz de lidar com trilhões de eventos em um dia. A Confluent Platform facilita a criação de pipelines de dados em tempo real e aplicativos de streaming, integrando dados de várias fontes e locais em uma única plataforma central de streaming de eventos para sua empresa.
Nesta postagem do blog, abordaremos como podemos mover dados do Couchbase e enviá-los para um tópico do Confluent kafka como evento de replicação.
O conector do Couchbase Kafka transfere documentos do Couchbase de forma eficiente e confiável usando o protocolo de replicação interno do Couchbase, DCP. Cada alteração ou exclusão do documento gera um evento de replicação, que é enviado para o tópico do Kafka configurado.
O conector Kafka pode ser usado para mover dados para fora do Couchbase e mover dados do Kafka para o Couchbase usando o conector sink. Para este blog, configuraremos e usaremos o conector de origem.
Em alto nível, o diagrama de arquitetura tem a seguinte aparência
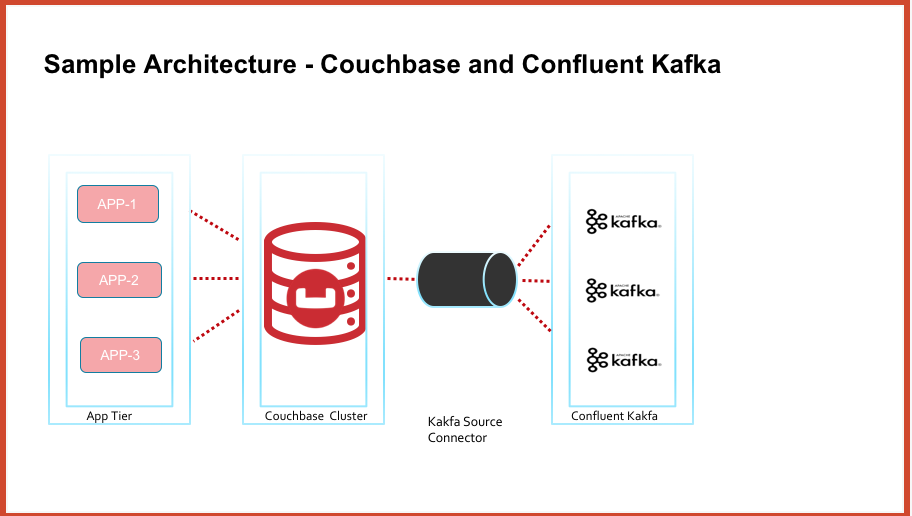
Pré-requisitos
Cluster do Couchbase com a versão 5.X ou superior. Baixar o Couchbase aqui
Conector kafka do Couchbase. Baixar o conector kafka do Couchbase aqui
Confluent Kafka. Baixar o Confluent Kafka aqui
A configuração do cluster do Couchbase está fora do escopo desta postagem do blog. No entanto, discutiremos a configuração do Confluent kafka e do conector kafka do Couchbase para mover dados para fora do Couchbase.
Configuração do Confluent Kafka
Descompacte o pacote baixado acima em uma VM/pod. Para fins deste blog, implantei um pod do Ubuntu em um cluster do Kubernetes em execução no GKE.
Antes de instalar o confluent kafka, é necessário que os computadores tenham a versão java 8.
Instalar/iniciar o kafka
O kafka tem os seguintes processos, que devem estar todos ativos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<em class="markup--em markup--p-em">zookeeper is [UP]</em> <em class="markup--em markup--p-em">kafka is [UP]</em> <em class="markup--em markup--p-em">schema-registry is [UP]</em> <em class="markup--em markup--p-em">kafka-rest is [UP]</em> <em class="markup--em markup--p-em">connect is [UP]</em> <em class="markup--em markup--p-em">ksql-server is [UP]</em> <em class="markup--em markup--p-em">control-center is [UP]</em> |
O pod que executa o confluent kafka pode ser exposto por meio do serviço NodePort à máquina/laptop local. O arquivo do pod do aplicativo é aqui. O arquivo yaml do serviço é aqui
|
1 2 3 4 5 |
<em class="markup--em markup--p-em">$ kubectl get svc -n mynamespace</em> <em class="markup--em markup--p-em">NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE</em> <em class="markup--em markup--p-em">app-service ClusterIP 10.51.248.154 <none> 9021/TCP,8083/TCP 115s</em> |
Encaminhar o serviço para a porta local 9021
|
1 2 3 4 5 |
<em class="markup--em markup--p-em">$ kubectl port-forward service/app-service 9021:9021 -- namespace cbdb</em> <em class="markup--em markup--p-em">Forwarding from 127.0.0.1:9021 -> 9021</em> <em class="markup--em markup--p-em">Forwarding from [::1]:9021 -> 9021</em> |
Acesse a URL: https://localhost:9021
Configuração do conector Kafka do Couchbase
Descompacte o pacote baixado acima
|
1 |
<em class="markup--em markup--p-em">$ unzip kafka-connect-couchbase-3.4.5.zip</em> |
|
1 |
<em class="markup--em markup--p-em">$ cd kafka-connect-couchbase-3.4.5/</em>config |
Editar arquivo quickstart-couchbase-source.properties com (pelo menos) as seguintes informações
Cadeia de conexão do cluster
|
1 |
<em class="markup--em markup--p-em">connection.cluster_address=cb-demo-0000.cb-demo.default.svc.cluster.local</em> |
nome do bucket e credenciais de acesso ao bucket
|
1 2 3 |
<em class="markup--em markup--p-em">connection.bucket=travel-sample connection.username=Administrator connection.password=pa$$word</em> |
Observação: Insira as credenciais do bucket para o qual você deseja mover os dados. No meu exemplo, estou usando o bucket travel-sample, com as credenciais de usuário do bucket.
Exportar a variável CONFLUENT_HOME
|
1 |
<em class="markup--em markup--p-em">export CONFLUENT_HOME=/root/confluent-5.2.1</em> |
Iniciar o conector kafka
|
1 |
<em class="markup--em markup--p-em">env CLASSPATH=./* connect-standalone $CONFLUENT_HOME/etc/schema-registry/connect-avro-standalone.properties config/quickstart-couchbase-source.properties</em> |
Quando o conector é iniciado, ele cria um tópico do kafka com o nome cb-topic e podemos ver todos os documentos do Couchbase amostra de viagem o balde é transferido para o tópico do kafka cb-topic como eventos

Conclusão
Em questão de minutos, é possível integrar o Couchbase e o Confluent Kafka. A facilidade de uso, a implementação e a capacidade de suporte são fatores fundamentais no uso da tecnologia. Nesta postagem do blog, vimos que é possível mover facilmente os dados do Couchbase para um tópico do Kafka. Quando os dados estiverem no tópico do Kafka, usando o KSQL, será possível criar aplicativos de processamento de fluxo em tempo real que atendam às necessidades dos negócios.
Referências:
- https://docs.confluent.io/current/quickstart/ce-quickstart.html#ce-quickstart
- https://docs.couchbase.com/kafka-connector/3.4/quickstart.html
- https://docs.couchbase.com/kafka-connector/3.4/source-configuration-options.html