p서로 잘 작동하지 않거나 잘 통합되지 않는 이질적인 기술의 세계에서 Couchbase와 Confluent Kafka는 놀라운 제품이며 서로를 매우 보완적으로 보완합니다. Couchbase는 선형적으로 확장 가능한 분산형 NoSQL JSON 데이터베이스입니다. 주요 사용 사례는 한 자리 숫자가 필요한 모든 애플리케이션/웹 서비스입니다. ms 읽기/쓰기/업데이트 응답을 지연시킵니다. 빠르게 변하는 트랜잭션 데이터를 빠르게 처리하거나 다운스트림 서비스가 Couchbase의 데이터를 사용할 수 있도록 Db2/Oracle/SQL 서버 등을 오프로드하기 위한 시스템 오브 레코드(SoR) 또는 캐싱 레이어로 사용할 수 있습니다.
C온플루언트 카프카는 선형적으로 확장 가능하며 하루에 수조 개의 이벤트를 처리할 수 있는 본격적인 분산 스트리밍 플랫폼입니다. 여러 소스 및 위치의 데이터를 하나의 중앙 이벤트 스트리밍 플랫폼으로 통합하여 실시간 데이터 파이프라인과 스트리밍 애플리케이션을 쉽게 구축할 수 있습니다.
이 블로그 게시물에서는 Couchbase에서 데이터를 원활하게 이동하여 복제 이벤트로서 Confluent kafka 토픽으로 푸시하는 방법에 대해 설명합니다.
Couchbase Kafka 커넥터는 Couchbase의 내부 복제 프로토콜을 사용하여 효율적이고 안정적으로 Couchbase에서 문서를 전송합니다, DCP. 문서가 변경되거나 삭제될 때마다 복제 이벤트가 생성되며, 이 이벤트는 구성된 Kafka 토픽으로 전송됩니다.
Kafka 커넥터를 사용하여 Couchbase에서 데이터를 이동하고 싱크 커넥터를 사용하여 kafka에서 Couchbase로 데이터를 이동하는 데 사용할 수 있습니다. 이 블로그에서는 소스 커넥터를 구성하고 사용하겠습니다.
높은 수준에서 아키텍처 다이어그램은 다음과 같습니다.
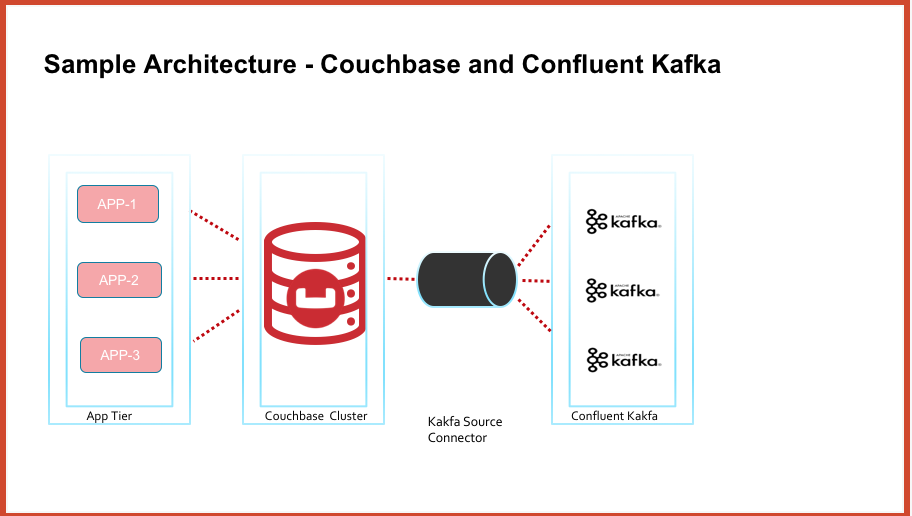
사전 요구 사항
버전 5.X 이상을 실행하는 Couchbase Cluster. Couchbase 다운로드 여기
카우치베이스 카프카 커넥터. 카우치베이스 카프카 커넥터 다운로드 여기
Confluent Kafka. Confluent Kafka 다운로드 여기
Couchbase 클러스터 구성은 이 블로그 게시물의 범위를 벗어납니다. 그러나 Couchbase에서 데이터를 이동하기 위해 Confluent kafka 및 Couchbase kafka 커넥터를 구성하는 방법에 대해서는 설명하겠습니다.
Confluent Kafka 구성
위에서 다운로드한 패키지를 VM/팟에 언타르합니다. 이 블로그의 목적을 위해, 저는 GKE에서 실행되는 쿠버네티스 클러스터에 우분투 파드를 배포했습니다.
컨플루언트 카프카 머신을 설치하기 전에 Java 8 버전이 있어야 합니다.
카프카 설치/시작
카프카에는 다음과 같은 프로세스가 있으며, 모두 가동되어야 합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<em class="markup--em markup--p-em">zookeeper is [UP]</em> <em class="markup--em markup--p-em">kafka is [UP]</em> <em class="markup--em markup--p-em">schema-registry is [UP]</em> <em class="markup--em markup--p-em">kafka-rest is [UP]</em> <em class="markup--em markup--p-em">connect is [UP]</em> <em class="markup--em markup--p-em">ksql-server is [UP]</em> <em class="markup--em markup--p-em">control-center is [UP]</em> |
컨플루언트 카프카를 실행하는 파드는 NodePort 서비스를 통해 로컬 머신/노트북에 노출될 수 있습니다. 앱 포드 파일은 여기. 서비스 yaml 파일은 여기
|
1 2 3 4 5 |
<em class="markup--em markup--p-em">$ kubectl get svc -n mynamespace</em> <em class="markup--em markup--p-em">NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE</em> <em class="markup--em markup--p-em">app-service ClusterIP 10.51.248.154 <none> 9021/TCP,8083/TCP 115s</em> |
로컬 포트 9021에서 서비스를 포트 포워딩합니다.
|
1 2 3 4 5 |
<em class="markup--em markup--p-em">$ kubectl port-forward service/app-service 9021:9021 -- namespace cbdb</em> <em class="markup--em markup--p-em">Forwarding from 127.0.0.1:9021 -> 9021</em> <em class="markup--em markup--p-em">Forwarding from [::1]:9021 -> 9021</em> |
URL을 누르세요: https://localhost:9021
카우치베이스 카프카 커넥터 구성하기
위에서 다운로드한 패키지의 압축을 풉니다.
|
1 |
<em class="markup--em markup--p-em">$ unzip kafka-connect-couchbase-3.4.5.zip</em> |
|
1 |
<em class="markup--em markup--p-em">$ cd kafka-connect-couchbase-3.4.5/</em>config |
파일 편집 빠른 시작 카우치베이스 소스 속성 (최소한) 다음 정보를 포함해야 합니다.
클러스터 연결 문자열
|
1 |
<em class="markup--em markup--p-em">connection.cluster_address=cb-demo-0000.cb-demo.default.svc.cluster.local</em> |
버킷 이름 및 버킷 액세스 자격 증명
|
1 2 3 |
<em class="markup--em markup--p-em">connection.bucket=travel-sample connection.username=Administrator connection.password=pa$$word</em> |
참고: 데이터를 옮기려는 버킷의 자격증명도 입력합니다. 이 예에서는 버킷 사용자 자격 증명과 함께 여행 샘플 버킷을 사용하고 있습니다.
CONFLUENT_HOME 변수 내보내기
|
1 |
<em class="markup--em markup--p-em">export CONFLUENT_HOME=/root/confluent-5.2.1</em> |
카프카 커넥터 시작
|
1 |
<em class="markup--em markup--p-em">env CLASSPATH=./* connect-standalone $CONFLUENT_HOME/etc/schema-registry/connect-avro-standalone.properties config/quickstart-couchbase-source.properties</em> |
커넥터가 시작되면 다음과 같은 이름의 kafka 토픽을 생성합니다. cb-topic 에서 모든 문서를 볼 수 있습니다. 여행 샘플 버킷이 카프카 토픽으로 이전됨 cb-topic 이벤트로

결론
단 몇 분 만에 Couchbase와 Confluent Kafka를 통합할 수 있습니다. 사용의 용이성, 배포 및 지원 가능성은 기술 사용의 핵심 요소입니다. 이 블로그 게시물에서는 Couchbase에서 Kafka 토픽으로 데이터를 원활하게 이동할 수 있다는 것을 확인했습니다. 일단 데이터가 kafka 토픽에 들어가면, KSQL을 사용해 비즈니스 요구사항에 맞는 실시간 스트림 처리 애플리케이션을 만들 수 있습니다.
참조:
- https://docs.confluent.io/current/quickstart/ce-quickstart.html#ce-quickstart
- https://docs.couchbase.com/kafka-connector/3.4/quickstart.html
- https://docs.couchbase.com/kafka-connector/3.4/source-configuration-options.html