Índices para N1QL: ou como consegui um aumento de velocidade de uma ordem de magnitude
No Couchbase 4.0, introduzimos a linguagem de consulta N1QL: uma linguagem de consulta flexível que traz uma consulta semelhante à SQL para documentos JSON.
Sempre que falamos sobre N1QL, o conversa sempre abre espaço para perguntas sobre desempenho: o que esperar em termos de desempenho e quais opções existem para otimizar as consultas.
A primeira resposta a ser dada é provavelmente "depende do seu caso de uso e do formato dos seus dados", mas, sinceramente, isso não ajuda muito.
Esta postagem do blog tenta responder à questão do desempenho com um pouco mais de detalhes e fornecer alguns números reais em termos de tempo de execução, além de mostrar como otimizar as consultas para obter mais desempenho.
História de fundo
O Couchbase usa o N1QL em várias ferramentas e aplicativos internos e, na semana passada, fiz uma observação muito importante!
Ao usar o N1QL, é extremamente importante criar índices!
Em um pequeno aplicativo, a adição de um índice a um atributo alterou o tempo de execução de 2 minutos para 2 segundos. Nenhuma alteração foi feita na consulta em si, a única alteração foi o índice!
Observação: o tempo de consulta acima não se refere a uma única consulta N1QL, mas a uma sequência de várias consultas no aplicativo em uma VM de potência relativamente baixa.
O tempo de execução esperado para uma consulta depende muito da complexidade da consulta e do sistema, do Couchbase Server e do hardware.
Portanto, para dar uma resposta mais precisa, é necessário um banco de testes. Um conjunto bem definido de testes que pode ser executado em diferentes sistemas para revelar as métricas de desempenho reais de uma determinada configuração. Dessa forma, uma medição pode ser fornecida para um sistema e uma consulta reais.
Portanto, em vez de apenas afirmar que o N1QL é rápido, podemos testá-lo em um sistema real: sua própria configuração!
Criação de um banco de testes
Primeiro, o desempenho é um desafio. É um desafio medir, mas o verdadeiro problema é que muitas vezes esquecemos O QUE estamos testando e, portanto, também esquecemos quando iniciar o "cronômetro" e quando pará-lo novamente.
Portanto, ao executar um teste, é importante definir o que o teste pretende medir e como medi-lo de forma justa, repetível e comparável.
Em nosso caso, gostaríamos de medir a diferença no tempo de execução de uma consulta N1QL predefinida quando usamos um índice e quando não usamos um índice.
Estamos interessados apenas no tempo de execução real da consulta N1QL, independentemente de qualquer atraso específico da plataforma, como atrasos na rede, tempo de inicialização, desempenho do SDK, tempos de configuração/limpeza etc.
Em outras palavras, para esse teste de desempenho específico, estamos ignorando tudo o que não seja o 'tempo de execução da consulta' nos dois cenários!
Felizmente, medir o tempo de execução de uma consulta é muito fácil! Toda resposta do Couchbase Server é retornada com um Medida que contém todas as métricas sobre a solicitação.
|
1 2 3 4 5 6 7 8 9 10 |
"Métricas": { "elapsedTime" (tempo decorrido): "1.7900093s", "executionTime": "1.7900093s", "resultCount": 0, "resultSize": 0, "mutationCount" (contagem de mutações): 0, "errorCount": 0, "warningCount": 0 } |
As métricas acima contêm tempo de execução e esse valor representa o tempo de execução no Couchbase Server, independentemente da latência da rede, do tempo de execução do código da plataforma etc. É exatamente o que precisamos!
Antes de executar qualquer consulta, precisamos de alguns dados de teste para executar as consultas. A quantidade de dados de teste que temos pode influenciar muito os resultados do teste e, portanto, isso deve ser configurável para cada execução de teste.
A forma como criamos os dados de teste não é de todo importante para o nosso teste, nem o tempo necessário para criá-los. O que é importante é a forma dos dados, pois eles devem refletir os dados reais, da melhor forma possível. Fora isso, temos um alto nível de liberdade sobre como criá-los e quanto tempo leva.
Na maioria dos casos, é justo presumir que os documentos variarão em tamanho e formato. O Couchbase não é afetado pela forma do documento. O Couchbase apenas "vê" uma chave apontando para um valor. O tamanho é um tópico diferente e, portanto, os documentos no conjunto de dados devem variar em tamanho.
A imitação de alguns documentos diferentes pode ser obtida alterando um tipo no documento JSON. Novamente, a forma não é importante para o Couchbase, mas ao alterar o atributo tipo podemos imitar diferentes tipos de documentos, embora eles compartilhem a mesma estrutura de documentos.
Os critérios de dados de teste agora podem ser resumidos a:
- Os documentos devem variar em tamanho
- O documento pode compartilhar a mesma estrutura JSON
- O conteúdo dos documentos deve ser exclusivo
- O documento deve ter um
tipoque pode ser alterado para imitar diferentes documentos no conjunto de dados.
Com isso em mente, vamos definir a estrutura do documento JSON da seguinte forma:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "Id": "GUID", "tipo": "perfTest", "IndexedType": "pessoa + #", "NoneIndexedType": "pessoa + #", "Dia": 1->29, "Mês": 1->12, "Ano": 2015, "TextSmall": "100->250 caracteres aleatórios", "TextMedium": "200->500 caracteres aleatórios", "TextLarge": "700->1000 caracteres aleatórios", "TextExtraLarge": "1200-1500 caracteres aleatórios" } |
A estrutura do documento acima representa o documento de teste. O tamanho de cada documento pode variar muito, pois todos os Texto... Os atributos recebem um tamanho e um valor aleatórios. Com esse tamanho e conteúdo aleatórios, cada documento imita melhor os documentos reais em um sistema real.
É provável que um sistema real contenha mais de um tipo de documento e, ao alterar o valor de IndexedType a mesma estrutura de documento pode imitar diferentes tipos de documentos no sistema.
O atributo IndexedType pode assumir alguns valores previsíveis diferentes no formulário: pessoa1, pessoa2, pessoa3 e pessoa4. Os quatro valores diferentes são usados para imitar quatro documentos diferentes. É possível adicionar mais 'tipos' mas, para o nosso teste, quatro são suficientes.
O tipo permite a fácil pesquisa e exclusão dos documentos de teste quando o teste é concluído e sempre recebe o valor perfTest.
O carregamento dos documentos em um bucket no Couchbase Server pode ser feito de várias maneiras. Uma opção seria pré-criar documentos e carregá-los no bucket usando uma combinação dos métodos cbbackup e cbrestore ferramentas.
Outra opção seria criar os dados de teste em tempo real. Acho que você provavelmente pode pensar em outras maneiras de carregar os dados. Lembre-se de que essa etapa não é crítica para o desempenho! Faça o que for mais fácil.
Com as definições acima em vigor, estamos prontos para definir as etapas do banco de testes:
- Colocar o sistema em um estado conhecido
- Dados do teste de carga
- Consultar dados de teste e medir o tempo de execução
- Criar índices
- Consultar dados de teste e medir o tempo de execução
- Colocar o sistema em um estado conhecido
- Imprimir resultado
Implementação
Etapa 1
Embora os recursos de manipulação de dados do N1QL ainda estejam em fase de visualização, eles podem ser usados atualmente. Isso torna a limpeza de dados muito simples:
|
1 |
"DELETE DE `padrão` d ONDE d.tipo = 'perfTest' RETORNO d.Id |
Os índices podem ser excluídos usando o comando DROP comando:
|
1 2 3 |
DROP ÍNDICE `padrão`.`índice_1` USO GSI; DROP ÍNDICE `padrão`.`índice_2` USO GSI; DROP ÍNDICE `padrão`.`índice_3` USO GSI; |
O Couchbase Server retornará um erro se o DROP é executado em um índice que não existe. Isso pode ser superado com uma verificação da existência ou não do índice:
|
1 2 3 |
SELECT * DE sistema:índices ONDE nome='índice_1'; SELECT * DE sistema:índices ONDE nome='índice_2'; SELECT * DE sistema:índices ONDE nome='índice_3'; |
Etapa 2
Provavelmente seria possível continuar usando os recursos de manipulação de dados do N1QL para criar um conjunto de dados aleatórios, mas também seria um pouco mais complicado do que criar os documentos em código.
O código do banco de testes será implementado usando o .NET e os documentos serão gerados usando o seguinte snippet C#:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
privado estático vazio GerarDocumentos() { int rodadas = numberOfTestDocuments (número de documentos de teste) > batchSize ? numberOfTestDocuments (número de documentos de teste) / batchSize : 1; int testDocsPerLoop = rodadas > 1 ? batchSize : numberOfTestDocuments (número de documentos de teste); Aleatório correu = novo Aleatório(); para (int n = 0; n < rodadas; n++) { var documentos = novo Dicionário<string, dinâmico>(); para (int i = 0; i < testDocsPerLoop; i++) { string id = Guia.NovoGuia().ToString(); string postFix = correu.Próximo(1, 4).ToString(); var doc = novo { Id = id, tipo = "perfTest", IndexedType = "pessoa" + postFix, NoneIndexedType = "pessoa" + postFix, Dia = correu.Próximo(1, 29), Mês = correu.Próximo(1, 12), Ano = "2015", TextSmall = novo string( Enumerável.Faixa(0, correu.Próximo(100, 250)).Selecione(item => (char)correu.Próximo(44, 126)).ToArray()), TextMedium = novo string( Enumerável.Faixa(0, correu.Próximo(200, 500)).Selecione(item => (char)correu.Próximo(44, 126)).ToArray()), TextLarge = novo string( Enumerável.Faixa(0, correu.Próximo(700, 1000)).Selecione(item => (char)correu.Próximo(44, 126)).ToArray()), TextExtraLarge = novo string( Enumerável.Faixa(0, correu.Próximo(1200, 1500)).Selecione(item => (char)correu.Próximo(44, 126)).ToArray()) }; documentos.Adicionar(id, doc); } Ajudante de cluster .GetBucket("default") .Upsert<dinâmico>(documentos); Console.Escrever("."); } } |
O método usa um loop interno e um externo. O loop interno define o tamanho do lote de upload. O loop externo define o número de lotes a serem carregados no Couchbase Server.
Os loops são adicionados para garantir que o programa não fique sem memória ao fazer o upload de um grande conjunto de dados.
Etapa 3
Depois de carregar os documentos de teste no Couchbase Server, é hora de executar a primeira parte do teste e registrar o tempo de execução:
|
1 |
SELECT * DE `padrão` ONDE IndexedType='pessoa3' E Mês > 5 E Dia < 20 |
Dependendo do número de documentos usados no teste, é provável que essa consulta tenha um tempo limite. No meu sistema, a execução dessa consulta em 500 mil documentos resulta em um tempo limite. 15 mil documentos têm um tempo de consulta de cerca de 15s.
Etapa 4
Agora é hora de criar os índices:
|
1 2 3 |
CRIAR ÍNDICE `índice_1` ON `padrão`(IndexedType) USO GSI; CRIAR ÍNDICE `índice_2` ON `padrão`(Mês) USO GSI; CRIAR ÍNDICE `índice_3` ON `padrão`(Dia) USO GSI; |
O CRIAR ÍNDICE é síncrono e retorna quando o índice secundário é criado e está pronto. Isso significa que esse comando pode demorar um pouco para ser concluído, dependendo do número de documentos no teste e do tamanho de sua máquina.
Índice múltiplo versus um índice: Ter vários índices independentes é vantajoso se você pesquisar em cada atributo em consultas independentes em que outros atributos estejam ausentes.
No entanto, ter apenas um índice reduz a sobrecarga de manutenção de índices separados e pode simplesmente reduzir os requisitos de recursos, além de acelerar ainda mais a consulta, já que tem a capacidade de encontrar os itens qualificados para todos os critérios de filtro de uma só vez.
Em vez dos três índices independentes, poderíamos usar isso:
|
1 |
CRIAR ÍNDICE `index_type_month_year` ON `padrão`(IndexedType, Mês, Ano) USO GSI; |
Ou até mesmo:
|
1 |
CRIAR ÍNDICE `index_type_month_year` ON `padrão`(IndexedType, Mês, Ano) ONDE IndexedType='pessoa3' E Mês > 5 E Dia < 20 USO GSI; |
No entanto, considero mais correto ter vários índices para esse tipo de teste. Você sempre pode executar o teste com um único índice e medir a diferença no tempo de execução e usar essa medida para tomar uma decisão final sobre o que é melhor para o seu caso específico.
Etapa 5
Depois que os índices são criados, é hora de executar a segunda parte do teste e registrar o tempo de execução:
|
1 |
SELECT * DE `padrão` ONDE IndexedType='pessoa3' E Mês > 5 E Dia < 20 |
Observação: essa é exatamente a mesma consulta usada na etapa 3. Nenhuma alteração foi feita na própria consulta.
Os tempos de execução típicos em meu sistema estão entre 4ms e 23ms! Essa é uma grande diferença! Mas como o tamanho do conjunto de dados afeta essa medida? Você terá que continuar lendo para obter essa resposta.
Etapa 6
Excluindo todos os documentos de teste, eliminando os índices e trazendo o sistema de volta ao estado conhecido antes da execução do teste. É o mesmo que a etapa 1.
Você poderia argumentar que a etapa 1 ou a etapa 6 não são necessárias, mas ambas são muito importantes. Pense no caso em que uma execução de teste é interrompida (cancelada, falha, etc.)
Etapa 7
A etapa final e, com sorte, a mais interessante, o resultado.
Resultados do meu sistema:
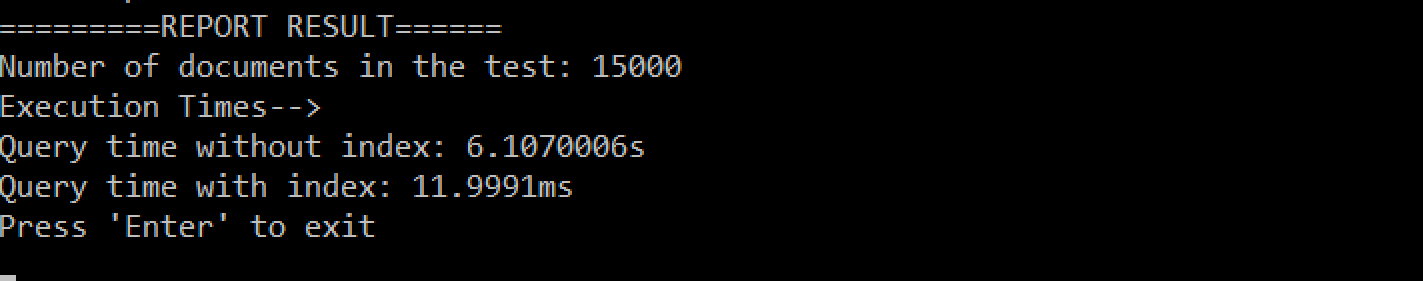
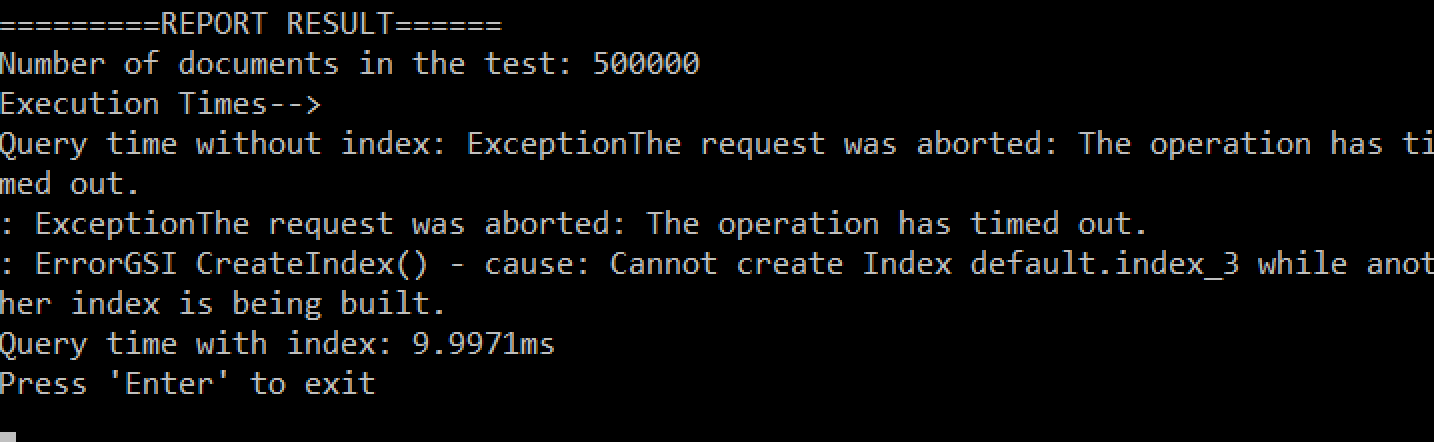
Resumo dos resultados do meu sistema:
MacBook Pro com 16 GB de memória, Couchbase Server em execução no Windows 10 usando o Parallels Desktop com 10 GB de memória (o Couchbase Server tem 2 GB de memória)
- 15.000 documentos
- Índice de não conformidade: 15s
- índice: 7ms
- 500.000 documentos:
- NO-index: tempo limite (mais de 5min)
- índice: 10ms
Observação, Em termos de tempo de execução, não há grande diferença entre 15 mil documentos e 500 mil documentos quando se usa um índice.
Aprendizagem, o uso de índices secundários é realmente importante e ajuda muito no desempenho da consulta!
Código-fonte
O código-fonte pode ser encontrado no GitHub:
Código de teste do índice N1QL
A implementação tenta compensar os tempos limite/erros e as novas tentativas em falhas de operação e tempos limite.
Um tempo limite ocorre com frequência ao usar o comando beta do N1QL&apos DELETE em um grande conjunto de dados (500.000 documentos). Lembre-se de que esse recurso ainda está em pré-visualização e, portanto, esse comportamento não deve ser esperado quando for lançado, mas, por enquanto, é necessário esperar esse comportamento e compensar de acordo.
Essa é a questão dos benchmarks. Depende.
Que desempenho você pode esperar do seu sistema? Bem, isso depende! Mas agora você pode executar o código de teste em sua configuração e ter uma ideia melhor.
Mas uma coisa é certa! Não se esqueça de criar esses índices secundários! Eles melhoram muito o desempenho! Em termos de números, os índices podem melhorar o desempenho em um fator de 100 a 1000!
O uso de índices tem um impacto sobre o uso da CPU do cluster, portanto, vale a pena considerar exatamente quais índices implementar e não criar mais do que o necessário.
Dito isso, para uma única linha de código, esse é um ótimo custo-benefício;)
|
1 |
CRIAR ÍNDICE `{INDEX_NAME}` ON `{BUCKET_NAME}`({ATRIBUTO_NOME}) USO GSI; |
Fique à vontade para publicar os resultados de seus testes nos comentários abaixo e nos ajudar a entender melhor o desempenho esperado do N1QL.