Na postagem anterior do blog, falamos sobre por que a pesquisa de texto completo é uma solução melhor em escala para implementar uma pesquisa bem projetada em seu aplicativo. Nesta segunda parte, vamos nos aprofundar no Índice Invertido e explorar como analisadores, tokenizadores e filtros podem moldar o resultado de suas pesquisas.
Portanto, não importa se você está indexando e pesquisando registros, genes em um DNA, sua própria estrutura de dados e, é claro, a linguagem. Todos eles funcionarão basicamente da mesma maneira.
Para dar um exemplo de como é possível usar o FTS mesmo quando você tem sua própria estrutura personalizada, vamos aproveitar o fato de que a Apple finalmente comprou o Shazam e criar um aplicativo imaginário semelhante ao Shazam. No entanto, em vez de ouvir um pequeno fragmento de música como o Shazam faz, pediremos que o usuário assovie.
Espere... por que preciso do Full-text Search para isso?
Como o usuário pode assobiar erroneamente algumas partes da música, precisaremos dividi-la em "pequenos blocos de melodia" e tentar combiná-los com a nossa biblioteca. Supondo que a nossa biblioteca tenha milhares ou até milhões de músicas (as bibliotecas da Apple e do Spotify têm mais de 30 milhões de músicas), um simples LIKE "%melody%" não tem chance de trazer resultados em um período de tempo razoável.
Um índice invertido parece ser a ferramenta certa para o trabalho, pois podemos encontrar facilmente todas as músicas que contêm um determinado bloco de melodia. Se você ainda não está familiarizado com esse conceito, consulte veja minha postagem anterior no blog sobre isso.
O Código Parsons
A primeira coisa que precisamos fazer é converter nossa biblioteca de músicas em texto. Podemos fazer isso usando a função Código Parsonsque é uma notação usada para identificar uma peça musical de acordo com os movimentos do campo para cima e para baixo:
- * = primeiro tom como referência,
- u = "up" (para cima), para quando a nota é mais alta do que a nota anterior,
- d = "down", para quando a nota é mais baixa do que a nota anterior,
- r = "repeat" (repetir), para quando a nota tem a mesma altura da nota anterior.
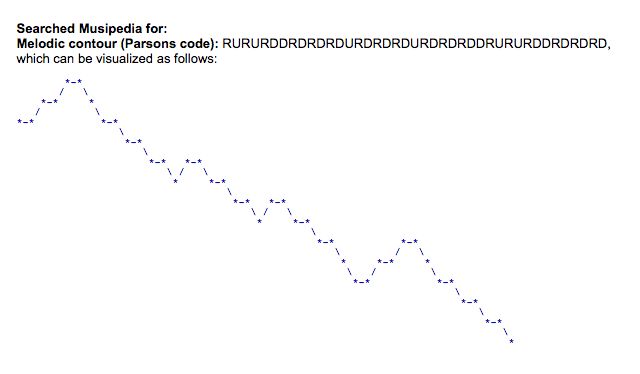
Usando o código de parsons, uma música como "Twinkle Twinkle Little Star" será convertido para *rururddrdrdrdurdrdrdurdrdrddrururddrdrdrd.
Aqui está a música completa:
e aqui está sua visualização usando o código Parsons:
Analisadores
Para criar nosso índice invertido, precisamos primeiro preparar nosso texto, como dividi-lo em partes menores, convertê-lo em letras minúsculas, remover palavras irrelevantes etc. A fase de preparação/análise geralmente é executada durante a criação de índices e antes de a consulta ser executada. Dessa forma, podemos garantir que tanto o texto de destino quanto o termo que está sendo correspondido passaram exatamente pelas mesmas transformações.
O código responsável por essa transformação é chamado de Analisador e, em termos gerais, agrupamos os analisadores em duas categorias principais: tokenizadores e filtros.
Tokenizadores
Quando estivermos lidando com idiomas, o tokenizador padrão dividirá um texto em palavras. A estratégia de tokenização mudará ligeiramente de acordo com o idioma, pois também devemos considerar outros caracteres além dos espaços em branco, como l'amour em francês ou "I'm" em inglês.
No Couchbase FTS, o tokenizador padrão funciona imediatamente na maioria das vezes, mas também fornecemos tokenizadores para HTML e algumas outras estruturas de dados. Portanto, sempre vale a pena verificar se você está usando o mais adequado.
Idealmente, em nosso aplicativo semelhante ao Shazam, deveríamos criar um tokenizador de n-grama personalizado, mas, para manter as coisas simples, vamos tentar aproveitar o padrão. Para fazer isso, precisaremos alterar ligeiramente o código Parsons inserindo um espaço em branco após cada 5 letras. O motivo disso é que estou presumindo que, se o usuário conseguir assobiar corretamente pelo menos 5 notas seguidas, considerarei isso um "bloco de melodia" e tentarei compará-lo com nosso índice invertido.
Dessa forma, nosso "Twinkle Twinkle Little Star" será armazenado como *rurur ddrdr drdur drdrd urdrd rddru rurdd rdrdr d.
Filtros
O Couchbase FTS também vem com uma variedade de filtross, os três mais populares são potencialmente os to_lower, stop_tokense modelador de tronco:
- to_lower: Converte todos os caracteres em minúsculas. Por exemplo, HTML se torna html.
- stop_tokens: Remove do fluxo os tokens considerados desnecessários para uma pesquisa de texto completo: por exemplo, and, is, and the.
- Stemmer: Usos libstemmerpara reduzir tokens a palavras-temas. Por exemplo, palavras como pesca, pescadose pescador são reduzidos a peixes.
O ideal é que você tenha vários índices para os mesmos dados, em que cada índice use uma composição de filtros focados em destacar uma característica específica. Falaremos mais sobre isso nos próximos artigos.
Para nosso aplicativo semelhante ao Shazam, os filtros podem não ser necessários, mas se quisermos melhorar nossos resultados, também podemos adicionar algum tipo de filtro personalizado stop_tokens ou filtro de caracteres personalizado.
Por exemplo, na maioria das músicas pop, o cantor pode gritar por alguns segundos um "Ahhhhhhh" ou "Ohhhhhh". Usando o código Parsons, ele será traduzido em uma série de r ("repeat", para quando a nota tem o mesmo tom da nota anterior). Portanto, nosso filtro de caracteres stop_tokens/custom pode remover qualquer sequência de dez | vinte "r".
Ex: *rururddrdrdrdurdrdrdurdrdrddrururddrdrdrdrrrrrrrrrr torna-se *rururddrdrdrdurdrdrdurdrdrddrururddrdrdrd
Dessa forma, a música será identificada por sua melodia principal, em vez de tentar encontrá-la por uma sequência de notas repetidas, o que poderia gerar resultados errados.
Consultando os dados
Agora que temos nossa biblioteca de músicas devidamente indexada, tudo o que precisamos fazer é registrar o assobio do usuário, convertê-lo em Parsons Code e, finalmente, consultar o banco de dados. O FTS transformará automaticamente nosso termo de consulta usando os mesmos tokenizadores e analisadores que usamos para indexar os dados.
Por enquanto, vamos supor que a consulta simplesmente trará resultados ordenados pelo total de correspondências.
Ex:
Uma consulta como rurur ddrdr potencialmente trará o "Twinkle Twinkle Little Star", pois temos 4 partidas nela:
*rururddrdrdrdurdrdrdrdurdrdrddrururddrdrdrd
Onde está a demonstração?
Vamos criar outro tipo de aplicativo durante esta série do blog, mas se você estiver interessado em experimentar um aplicativo real que implemente algo semelhante ao que descrevi aqui, confira Midemi.
Conclusão
O objetivo deste artigo foi mostrar a importância dos tokenizadores e filtros mesmo quando estamos lidando com outros tipos de estruturas. Recomendo fortemente a leitura da documentação oficial sobre eles para entender qual é o melhor caso de uso para cada um deles.
Se você já tem um bom conhecimento de FTS, deve ter notado alguns possíveis problemas com nosso aplicativo semelhante ao Shazam: Como o usuário geralmente não começa a assobiar a música desde o início, podemos tokenizar o assobio a partir de um ponto diferente daquele em que tokenizamos a música original. Como estamos agrupando a música em tokens de 5 notas, as chances de tokenizar tanto a música quanto o termo consultado no ponto correto são de 1 em 5.
Ex:
“Twinkle Twinkle Little Star“: rururddrdrdrdrdrdurdrdrdrdrdurdrdrdrdrdrdrdrdrdrdrdrdrdrdrd
Tokenized "Twinkle Twinkle Little Star“: rurur ddrdr drdur drdrd urdrd rddru rurdd rdrdr d
Apito do usuário: rdrdrdurdrdrdrdurdrd (uma parte aleatória no meio da música)
Apito do usuário tokenizado: rdrdr durdr drdur drd
No exemplo acima, tivemos 2 correspondências (rdrdr e drdur) por acaso, mas como eles estão fora de ordem, a pontuação dessa música será seriamente comprometida, o que pode levar a resultados inesperados.
Série de pesquisa de texto completo
- Por que você deve evitar o LIKE % - Parte 2
- Correspondência difusa - Parte 3
Veremos como resolver esse problema e alguns outros nos próximos artigos desta série. Enquanto isso, se você tiver alguma dúvida, envie-me um tweet para @deniswsrosa