O Couchbase é excelente como fonte para o Apache Kafka usando o conector DCP.
No entanto, ele também é excelente como um ponto de extremidade para digerir dados, pois é rápido, com memória em primeiro lugar e armazenamento confiável.
Nesta postagem do blog, mostrarei como criar um aplicativo Java simples para um produtor e um consumidor que salvam as mensagens publicadas do Kafka no Couchbase.
Presumo que você já tenha um cluster do Kafka (mesmo que seja um cluster de nó único). Caso contrário, tente seguir esse guia de instalação.
Este ambiente de blog tem 4 partes:
- Produtor da Kafka
- Fila do Apache Kafka
- Consumidor Kafka
- Servidor Couchbase
Produtor
Precisamos do produtor para enviar mensagens à nossa fila.
Na fila, essas mensagens estão sendo digeridas e todos os aplicativos que se inscreveram no tópico podem ler essas mensagens.
A fonte de nossas mensagens será um arquivo JSON fictício que criei usando o Mockaroo, que será dividido e enviado para a fila.
Nossos dados JSON de amostra são semelhantes a:
|
1 2 3 4 5 6 7 8 9 |
{ "id":1, "gender":"Female", "first_name":"Jane", "last_name":"Holmes", "email":"jholmes0@myspace.com", "ip_address":"230.49.112.20", "city":"Houston" } |
O código do produtor:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
import com.fasterxml.jackson.databind.JsonNode; import com.fasterxml.jackson.databind.ObjectMapper; import com.fasterxml.jackson.databind.node.ArrayNode; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.io.File; import java.nio.charset.Charset; import java.nio.file.Files; import java.nio.file.Paths; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.concurrent.Future; public class KafkaSimpleProducer { public static void main(String[] args) throws Exception { Map<String, Object> config = new HashMap<>(); config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); config.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); config.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String, String> producer = new KafkaProducer<String, String>(config); File input = new File("sampleJsonData.json"); byte[] encoded = Files.readAllBytes(Paths.get(input.getPath() )); String jsons = new String(encoded, Charset.defaultCharset()); System.out.println("Splitting file to jsons...."); List splittedJsons = split(jsons); System.out.println("Converting to JsonDocuments...."); int docCount = splittedJsons.size(); System.out.println("Number of documents is: " + docCount ); System.out.println("Starting sending msg to kafka...."); int count = 0; for ( String doc : splittedJsons) { System.out.println("sending msg...." + count); ProducerRecord<String,String> record = new ProducerRecord<>( "couchbaseTopic", doc ); Future meta = producer.send(record); System.out.println("msg sent...." + count); count++; } System.out.println("Total of " + count + " messages sent"); producer.close(); } public static List split(String jsonArray) throws Exception { List splittedJsonElements = new ArrayList(); ObjectMapper jsonMapper = new ObjectMapper(); JsonNode jsonNode = jsonMapper.readTree(jsonArray); if (jsonNode.isArray()) { ArrayNode arrayNode = (ArrayNode) jsonNode; for (int i = 0; i < arrayNode.size(); i++) { JsonNode individualElement = arrayNode.get(i); splittedJsonElements.add(individualElement.toString()); } } return splittedJsonElements; } } |
Saída do aplicativo produtor Kafka
Consumidor
Essa é uma solução simples, muito direta, basta obter as mensagens da fila e usar o Couchbase Java SDK para inserir documentos no Couchbase. Para simplificar, usarei o sync java SDK, mas o uso do async é totalmente possível e até recomendado.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
import com.couchbase.client.java.Bucket; import com.couchbase.client.java.Cluster; import com.couchbase.client.java.CouchbaseCluster; import com.couchbase.client.java.document.JsonDocument; import com.couchbase.client.java.document.json.JsonObject; import kafka.consumer.Consumer; import kafka.consumer.ConsumerConfig; import kafka.consumer.KafkaStream; import kafka.javaapi.consumer.ConsumerConnector; import kafka.message.MessageAndMetadata; import java.util.*; public class KafkaSimpleConsumer { public static void main(String[] args) { Properties config = new Properties(); config.put("zookeeper.connect", "localhost:2181"); config.put("zookeeper.connectiontimeout.ms", "10000"); config.put("group.id", "default"); ConsumerConfig consumerConfig = new kafka.consumer.ConsumerConfig(config); ConsumerConnector consumerConnector = Consumer.createJavaConsumerConnector(consumerConfig); Map<String, Integer> topicCountMap = new HashMap<>(); topicCountMap.put("couchbaseTopic", 1); Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumerConnector.createMessageStreams(topicCountMap); List<KafkaStream<byte[], byte[]>> streams = consumerMap.get("couchbaseTopic"); List nodes = new ArrayList<>(); nodes.add("localhost"); Cluster cluster = CouchbaseCluster.create(nodes); final Bucket bucket = cluster.openBucket("kafkaExample"); try { for (final KafkaStream<byte[], byte[]> stream : streams) { for (MessageAndMetadata<byte[], byte[]> msgAndMetaData : stream) { String msg = convertPayloadToString(msgAndMetaData.message()); System.out.println(msgAndMetaData.topic() + ": " + msg); try { JsonObject doc = JsonObject.fromJson(msg); String id = UUID.randomUUID().toString(); bucket.upsert(JsonDocument.create(id, doc)); } catch (Exception ex) { System.out.println("Not a json object: " + ex.getMessage()); } } } } catch (Exception ex) { System.out.println("EXCEPTION!!!!" + ex.getMessage()); cluster.disconnect(); } cluster.disconnect(); } private static String convertPayloadToString(final byte[] message) { String string = new String(message); return string; } } |
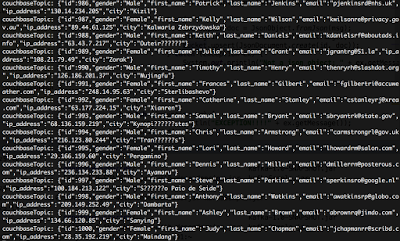
Saída do console do nosso consumidor Kafka
Servidor Couchbase
Agora podemos ver o resultado no servidor Couchbase.
Veja o bucket kafkaExample - preenchido com 1.000 documentos.
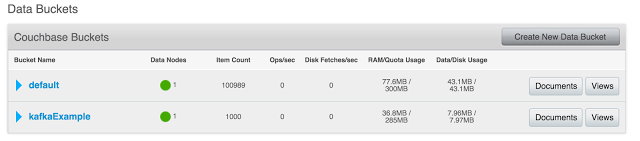
Baldes do Couchbase
Cada documento tem uma aparência semelhante a essa:

Documento de amostra
Solução simples de três partes.
Observe que, em um ambiente de produção, o Producer, o Consumer, o Kafka ou o Couchbase estarão em uma ou mais máquinas cada.
Código completo (incluindo dependências Maven) em GitHub.
Roi.