Você já se perguntou: "O que é fuzzy matching?" A correspondência difusa permite que você identifique correspondências não exatas do seu item de destino. É a pedra fundamental de muitas estruturas de mecanismos de pesquisa e um dos principais motivos pelos quais você pode obter resultados de pesquisa relevantes mesmo que tenha um erro de digitação na consulta ou um tempo verbal diferente.
Como era de se esperar, há muitos algoritmos de busca difusa que podem ser usados para texto, mas praticamente todas as estruturas de mecanismos de busca (incluindo sangrar) usam principalmente a distância Levenshtein para correspondência de strings difusas:
Distância de Levenshtein
Também conhecido como Editar distânciaé o número de transformações (exclusões, inserções ou substituições) necessárias para transformar uma cadeia de caracteres de origem na cadeia de caracteres de destino. Para um exemplo de pesquisa difusa, se o termo de destino for "book" e a fonte for "back", você precisará alterar o primeiro "o" para "a" e o segundo "o" para "c", o que nos dará uma distância de Levenshtein de 2.Você pode encontrar implementações de Levenshtein em JavaScript, Kotlin, Java e muitos outros aqui).
Além disso, algumas estruturas também suportam a distância Damerau-Levenshtein:
Distância Damerau-Levenshtein
É uma extensão da distância de Levenshtein, permitindo uma operação extra: Transposição de dois caracteres adjacentes:
Ex: TSAR para STAR
Distância Damerau-Levenshtein = 1 (A troca das posições S e T custa apenas uma operação)
Distância de Levenshtein = 2 (Substituir S por T e T por S)
Correspondência e relevância difusa
A correspondência difusa tem um grande efeito colateral: ela prejudica a relevância. Embora Damerau-Levenshtein seja um algoritmo de correspondência difusa que considera a maioria dos erros ortográficos comuns do usuário, ele também pode incluir um número significativo de falsos positivosespecialmente quando estamos usando uma linguagem com um média de apenas 5 letras por palavracomo o inglês. É por isso que a maioria das estruturas dos mecanismos de busca prefere usar a distância de Levenshtein. Vamos ver um exemplo real de correspondência fuzzy:
Primeiro, vamos usar esse conjunto de dados do catálogo de filmes. Eu o recomendo muito se você quiser brincar com a pesquisa de texto completo. Em seguida, vamos pesquisar filmes com "livro" no título. Um código simples seria parecido com o seguinte:
|
1 2 3 4 5 6 |
String indexName = "movies_index"; MatchQuery query = SearchQuery.match("book").field("title"); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(6)); printResults(movies); |
O código acima produzirá os seguintes resultados:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
1) The Book Thief score: 4.826942606027416 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> Thief] ----------------------------- 2) The Book of Eli score: 4.826942606027416 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Eli] ----------------------------- 3) The Book of Life score: 4.826942606027416 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Life] ----------------------------- 4) Black Book score: 4.826942606027416 Hit Locations: field:title term:book fragment:[Black <mark>Book</mark>] ----------------------------- 5) The Jungle Book score: 4.826942606027416 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark>] ----------------------------- 6) The Jungle Book 2 score: 3.9411821308689627 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark> 2] ----------------------------- |
Por padrão, os resultados não diferenciam maiúsculas de minúsculas, mas você pode alterar facilmente esse comportamento criando novos índices com analisadores diferentes.
Agora, vamos adicionar um recurso de correspondência difusa à nossa consulta, definindo a imprecisão como 1 (distância de Levenshtein 1), o que significa que "livro" e "olhar" terá a mesma relevância.
|
1 2 3 4 5 6 |
String indexName = "movies_index"; MatchQuery query = SearchQuery.match("book").field("title").fuzziness(1); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(6)); printResults(movies); |
E aqui está o resultado da pesquisa difusa:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
1) Hook score: 1.1012248063242538 Hit Locations: field:title term:hook fragment:[<mark>Hook</mark>] ----------------------------- 2) Here Comes the Boom score: 0.7786835148361213 Hit Locations: field:title term:boom fragment:[Here Comes the <mark>Boom</mark>] ----------------------------- 3) Look Who's Talking Too score: 0.7047266634351538 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who's Talking Too] ----------------------------- 4) Look Who's Talking score: 0.7047266634351538 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who's Talking] ----------------------------- 5) The Book Thief score: 0.5228811753737184 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> Thief] ----------------------------- 6) The Book of Eli score: 0.5228811753737184 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Eli] ----------------------------- |
Agora, o filme chamado "Gancho" é o primeiro resultado da pesquisa, que pode não ser exatamente o que o usuário está esperando em uma pesquisa por "Livro".
Como minimizar os falsos positivos durante as pesquisas difusas
Em um mundo ideal, os usuários nunca cometeriam erros de digitação ao pesquisar algo. No entanto, esse não é o mundo em que vivemos e, se você quiser que seus usuários tenham uma experiência agradável, terá de lidar com pelo menos uma distância de edição de 1. Portanto, a verdadeira questão é: como podemos fazer a correspondência de strings fuzzy minimizando a perda de relevância?
Podemos tirar proveito de uma característica da maioria das estruturas de mecanismos de pesquisa: Uma correspondência com uma distância de edição menor geralmente terá uma pontuação mais alta. Essa característica nos permite combinar essas duas consultas com diferentes níveis de imprecisão em uma só:
|
1 2 3 4 5 6 7 8 |
String indexName = "movies_index"; String word = "Book"; MatchQuery titleFuzzy = SearchQuery.match(word).fuzziness(1).field("title"); MatchQuery titleSimple = SearchQuery.match(word).field("title"); DisjunctionQuery ftsQuery = SearchQuery.disjuncts(titleSimple, titleFuzzy); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, ftsQuery).highlight().limit(20)); printResults(result); |
Aqui está o resultado da consulta fuzzy acima:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 |
1) The Book Thief score: 2.398890092610849 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> Thief] ----------------------------- field:title term:book fragment:[The <mark>Book</mark> Thief] ----------------------------- 2) The Book of Eli score: 2.398890092610849 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Eli] ----------------------------- field:title term:book fragment:[The <mark>Book</mark> of Eli] ----------------------------- 3) The Book of Life score: 2.398890092610849 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Life] ----------------------------- field:title term:book fragment:[The <mark>Book</mark> of Life] ----------------------------- 4) Black Book score: 2.398890092610849 Hit Locations: field:title term:book fragment:[Black <mark>Book</mark>] ----------------------------- field:title term:book fragment:[Black <mark>Book</mark>] ----------------------------- 5) The Jungle Book score: 2.398890092610849 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark>] ----------------------------- field:title term:book fragment:[The Jungle <mark>Book</mark>] ----------------------------- 6) The Jungle Book 2 score: 1.958685557004688 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark> 2] ----------------------------- field:title term:book fragment:[The Jungle <mark>Book</mark> 2] ----------------------------- 7) National Treasure: Book of Secrets score: 1.6962714808368062 Hit Locations: field:title term:book fragment:[National Treasure: <mark>Book</mark> of Secrets] ----------------------------- field:title term:book fragment:[National Treasure: <mark>Book</mark> of Secrets] ----------------------------- 8) American Pie Presents: The Book of Love score: 1.517191317611584 Hit Locations: field:title term:book fragment:[American Pie Presents: The <mark>Book</mark> of Love] ----------------------------- field:title term:book fragment:[American Pie Presents: The <mark>Book</mark> of Love] ----------------------------- 9) Hook score: 0.5052232518679681 Hit Locations: field:title term:hook fragment:[<mark>Hook</mark>] ----------------------------- 10) Here Comes the Boom score: 0.357246781294941 Hit Locations: field:title term:boom fragment:[Here Comes the <mark>Boom</mark>] ----------------------------- 11) Look Who's Talking Too score: 0.32331663301992025 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who's Talking Too] ----------------------------- 12) Look Who's Talking score: 0.32331663301992025 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who's Talking] ----------------------------- |
Como você pode ver, esse resultado está muito mais próximo do que o usuário poderia esperar. Observe que estamos usando uma classe chamada DisjunctionQuery agora, pois as disjunções são equivalentes a "OU" no SQL.
O que mais poderíamos melhorar para reduzir o efeito colateral negativo de um algoritmo de correspondência difusa? Vamos reanalisar nosso problema para entender se ele precisa de mais melhorias:
Já sabemos que as pesquisas difusas podem produzir alguns resultados inesperados (por exemplo, Book -> Look, Hook). No entanto, uma pesquisa de termo único geralmente é uma consulta terrível, pois mal nos dá uma dica do que exatamente o usuário está tentando realizar.
Mesmo o Google, que tem um dos algoritmos de pesquisa difusa mais desenvolvidos em uso, não sabe exatamente o que estou procurando quando pesquiso "tabela":
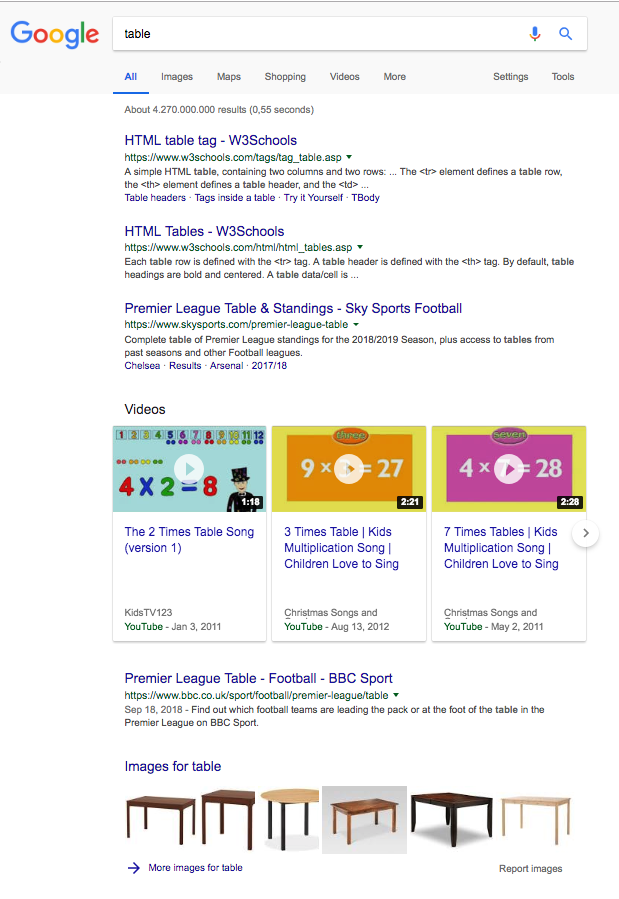
Então, qual é o tamanho médio das palavras-chave em uma consulta de pesquisa? Para responder a essa pergunta, mostrarei um gráfico de Apresentação de Rand Fishkin em 2016. (Ele é um dos gurus mais famosos do mundo de SEO)
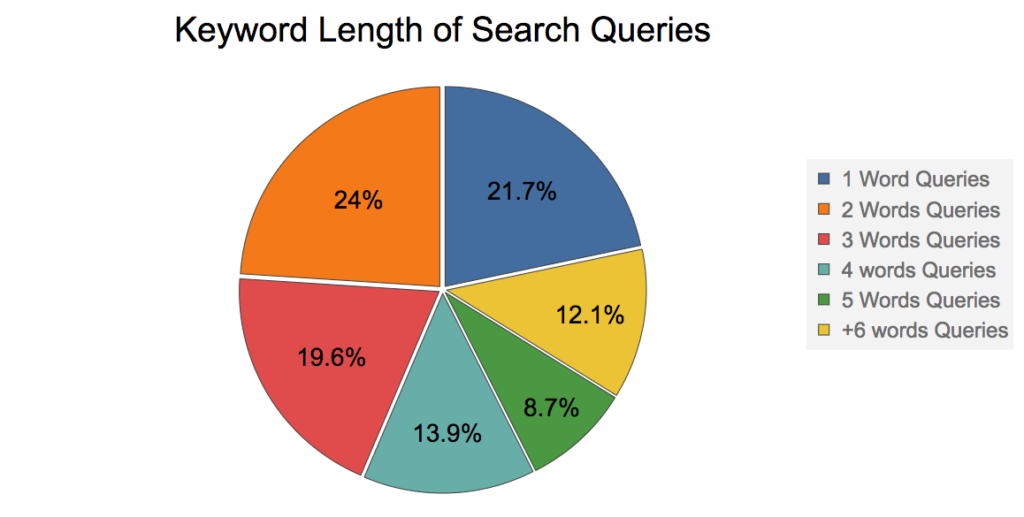
De acordo com o gráfico acima, ~80% das consultas de pesquisa têm 2 ou mais palavras-chave, portanto, vamos tentar pesquisar o filme "Black Book" usando a fuzziness 1:
|
1 2 3 4 5 6 |
String indexName = "movies_index"; MatchQuery query = SearchQuery.match("Black Book").field("title").fuzziness(1); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(12)); printResults(movies); |
Resultado:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
1) Black Book score: 0.6946442424065404 Hit Locations: field:title term:book fragment:[<mark>Black</mark> <mark>Book</mark>] ----------------------------- field:title term:black fragment:[<mark>Black</mark> <mark>Book</mark>] ----------------------------- 2) Hook score: 0.40139742528039857 Hit Locations: field:title term:hook fragment:[<mark>Hook</mark>] ----------------------------- 3) Attack the Block score: 0.2838308365090324 Hit Locations: field:title term:block fragment:[Attack the <mark>Block</mark>] ----------------------------- 4) Here Comes the Boom score: 0.2838308365090324 Hit Locations: field:title term:boom fragment:[Here Comes the <mark>Boom</mark>] ----------------------------- 5) Look Who's Talking Too score: 0.25687349813115684 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who's Talking Too] ----------------------------- 6) Look Who's Talking score: 0.25687349813115684 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who's Talking] ----------------------------- 7) Grosse Pointe Blank score: 0.2317469073782136 Hit Locations: field:title term:blank fragment:[Grosse Pointe <mark>Blank</mark>] ----------------------------- 8) The Book Thief score: 0.19059065534780495 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> Thief] ----------------------------- 9) The Book of Eli score: 0.19059065534780495 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Eli] ----------------------------- 10) The Book of Life score: 0.19059065534780495 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Life] ----------------------------- 11) The Jungle Book score: 0.19059065534780495 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark>] ----------------------------- 12) Back to the Future score: 0.17061000968368 Hit Locations: field:title term:back fragment:[<mark>Back</mark> to the Future] ----------------------------- |
Nada mal. Obtivemos o filme que estávamos procurando como o primeiro resultado. No entanto, uma consulta de disjunção ainda traria um conjunto melhor de resultados.
Mas, ainda assim, parece que temos uma nova propriedade interessante aqui; o efeito colateral da correspondência de imprecisão diminui ligeiramente à medida que o número de palavras-chave aumenta. Uma busca por "Livro preto" com imprecisão 1 ainda pode trazer resultados como back look ou lack cook (algumas combinações com edit distance 1), mas é improvável que esses sejam títulos de filmes reais.
Uma busca por "livro eli" com a imprecisão 2 ainda o traria como o terceiro resultado:
|
1 2 3 4 5 6 |
String indexName = "movies_index"; MatchQuery query = SearchQuery.match("book eli").field("title").fuzziness(2); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(12)); printResults(movies); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
1) Ed Wood score: 0.030723793900031805 Hit Locations: field:title term:wood fragment:[<mark>Ed</mark> <mark>Wood</mark>] ----------------------------- field:title term:ed fragment:[<mark>Ed</mark> <mark>Wood</mark>] ----------------------------- 2) Man of Tai Chi score: 0.0271042761982626 Hit Locations: field:title term:chi fragment:[Man of <mark>Tai</mark> <mark>Chi</mark>] ----------------------------- field:title term:tai fragment:[Man of <mark>Tai</mark> <mark>Chi</mark>] ----------------------------- 3) The Book of Eli score: 0.02608335441670756 Hit Locations: field:title term:eli fragment:[The <mark>Book</mark> of <mark>Eli</mark>] ----------------------------- field:title term:book fragment:[The <mark>Book</mark> of <mark>Eli</mark>] ----------------------------- 4) The Good Lie score: 0.02439822770591834 Hit Locations: field:title term:lie fragment:[The <mark>Good</mark> <mark>Lie</mark>] ----------------------------- field:title term:good fragment:[The <mark>Good</mark> <mark>Lie</mark>] ----------------------------- |
Entretanto, como a palavra média em inglês tem 5 letras, eu NÃO recomendamos o uso de uma distância de edição maior que 2, a menos que o usuário esteja pesquisando palavras longas e fáceis de serem escritas incorretamente, como "Schwarzenegger", por exemplo (pelo menos para quem não é alemão ou austríaco).
Conclusão
Neste artigo, discutimos a correspondência difusa e como superar seu principal efeito colateral sem prejudicar sua relevância. Lembre-se de que a correspondência difusa é apenas um dos muitos recursos que você deve aproveitar ao implementar uma pesquisa relevante e fácil de usar. Vamos discutir alguns deles durante esta série: N-Gramas, Stopwords, Steeming, Shingle, Elision. Etc.
Confira também o Parte 1 e Parte 2 desta série.
Enquanto isso, se você tiver alguma dúvida, envie-me um tweet para @deniswsrosa.
Como a pontuação retornada do índice está relacionada a uma correspondência percentual? Como seria possível construir uma consulta para a qual a pontuação de relevância dos resultados representasse uma relevância de > 50%, por exemplo?
Se você quiser saber mais sobre como os documentos são pontuados, tanto o lucene quanto o bleve têm o método "explain". No couchbase, você pode definir explain(true) para ver exatamente como a pontuação é calculada. Por padrão, os resultados são classificados por pontuação, de modo que os mais relevantes devem ser os primeiros da lista. O que você está tentando alcançar exatamente?