Encaminhamento e processamento de registros com o Couchbase está mais fácil do que nunca.
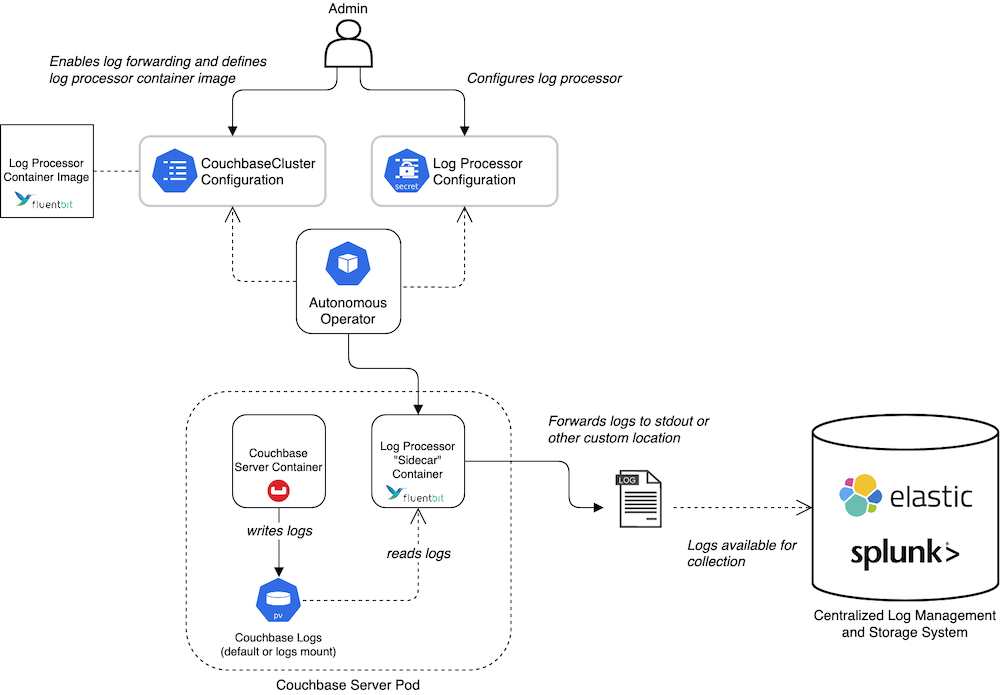
Temos suporte para encaminhamento de logs e gerenciamento de logs de auditoria para o Operador Autônomo do Couchbase (ou seja, Kubernetes) e para Implantações do Couchbase Server no local. Em ambos os casos, o processamento de registros é alimentado por Bit fluente.
Por que escolhemos o Fluent Bit? Os usuários do Couchbase precisam de logs em um formato comum com configuração dinâmica, e queríamos usar um padrão do setor com o mínimo de sobrecarga. O Fluent Bit foi uma escolha natural.
Este artigo aborda dicas e truques para aproveitar ao máximo o uso do Fluent Bit para encaminhamento de logs com o Couchbase. Usarei o Operador autônomo do Couchbase em meus exemplos de implantação. (Também apresentarei uma análise mais aprofundada desta postagem em a próxima FluentCon.)
Antes do Fluent Bit, os formatos de registro do Couchbase variavam em vários arquivos. Abaixo está uma única linha de quatro arquivos de registro diferentes:
|
1 2 3 4 |
2021-03-09T17:32:25.520+00:00 DEBU CBAS.util.MXHelper [main] ignoring exception calling RuntimeMXBean.getBootClassPath; returning null java.lang.UnsupportedOperationException: Boot class path mechanism is not supported at sun.management.RuntimeImpl.getBootClassPath(Unknown Source) ~[?:?] at org.apache.hyracks.util.MXHelper.getBootClassPath(MXHelper.java:111) [hyracks-util.jar:6.6.0-7909] |
|
1 2 3 |
{"bucket":"default","description":"The specified bucket was selected","id":20492,"name":"select bucket","peername":"127.0.0.1:56021","real_userid":{"domain":"local","user":"@ns_server"},"sockname":"127.0.0.1:11209","timestamp":"2021-03-09T20:12:17.445039Z"} [ns_server:warn,2021-03-09T17:31:55.401Z,babysitter_of_ns_1@cb.local:ns_crash_log<0.102.0>:ns_crash_log:read_crash_log:148]Couldn't load crash_log from /opt/couchbase/var/lib/couchbase/logs/crash_log_v2.bin (perhaps it's first startup): {error, enoent} |
|
1 2 3 |
[error_logger:info,2021-03-09T17:31:55.401Z,babysitter_of_ns_1@cb.local:error_logger<0.32.0>:ale_error_logger_handler:do_log:203] =========================PROGRESS REPORT========================= supervisor: {local,ns_babysitter_sup} |
|
1 |
127.0.0.1 - @ [09/Mar/2021:17:32:02 +0000] "RPCCONNECT /goxdcr-cbauth HTTP/1.1" 200 0 - Go-http-client/1.1 |
Com a atualização para o Fluent Bit, agora você pode transmitir visualizações de logs ao vivo da seguinte forma a arquitetura de registro padrão do Kubernetes o que também significa integração simples com painéis do Grafana e outras ferramentas padrão do setor. Abaixo está uma captura de tela tirada de o exemplo de pilha Loki que temos no repositório Fluent Bit.
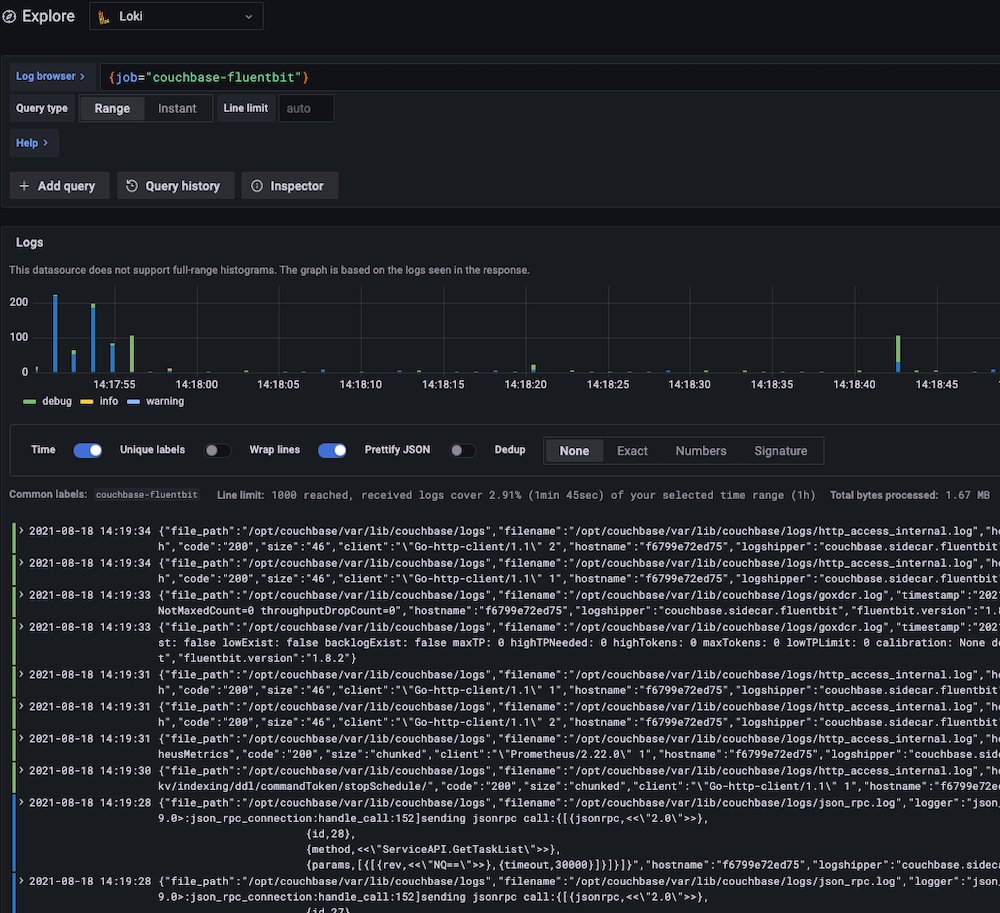
Quer você seja novo no Fluent Bit ou um profissional experiente, espero que este artigo o ajude a navegar pelas complexidades de usá-lo para o processamento de logs com o Couchbase.
Qual é a sua principal dúvida ou desafio com o Fluent Bit?
Pule diretamente para o seu desafio ou pergunta específica com o Fluent Bit usando os links abaixo ou role mais para baixo para ler todas as dicas e truques.
O que é (e por que) Fluent Bit?
Como faço para fazer perguntas, obter orientação ou dar sugestões sobre o Fluent Bit? Envolver-se com a comunidade OSS e contribuir com ela.
Como faço para descobrir o que está acontecendo de errado com o Fluent Bit? Use o saída plug-in e aumente o nível de registro ao depurar.
Como posso saber se meu analisador está falhando? Se você vir o padrão registro no registro, então você sabe que a análise falhou.
Por que meu analisador de regex não está funcionando? Verificar e simplificar, especialmente para análise de várias linhas.
Como faço para restringir um campo (por exemplo, nível de registro) a valores conhecidos? Restrinja e padronize os valores de saída com alguns filtros simples.
Como faço para adicionar informações opcionais que podem não estar presentes? Use o modificador de registro não o filtro modificar filtro - se você quiser incluir informações opcionais.
Como posso identificar qual plug-in ou filtro está acionando uma métrica ou mensagem de registro? Usar aliases.
Como faço para concluir o processamento especial ou sob medida (por exemplo, redação parcial)? Use o filtro Lua: Ele pode fazer tudo!.
Como faço para verificar minhas alterações ou testar se uma nova versão ainda funciona? Fornecer testes de regressão automatizados.
Como faço para testar cada parte da minha configuração? Separe sua configuração em partes menores. (Bônus: isso permite uma reutilização personalizada mais simples).
Como posso usar o Fluent Bit com o Red Hat OpenShift?
Respondo a essas e muitas outras perguntas no artigo abaixo. Vamos nos aprofundar.
O que é (e por que) Fluent Bit?
Então, o que é o Fluent Bit? O Fluent Bit é a irmã mais delicada do Fluentd, que são ambos Fundação de computação nativa da nuvem (CNCF) projetos sob a organização da Fluent.
O Fluent Bit consome essencialmente vários tipos de entrada, aplica um tubulação de processamento para essa entrada e, em seguida, suporta roteamento esses dados para vários tipos de pontos finais.
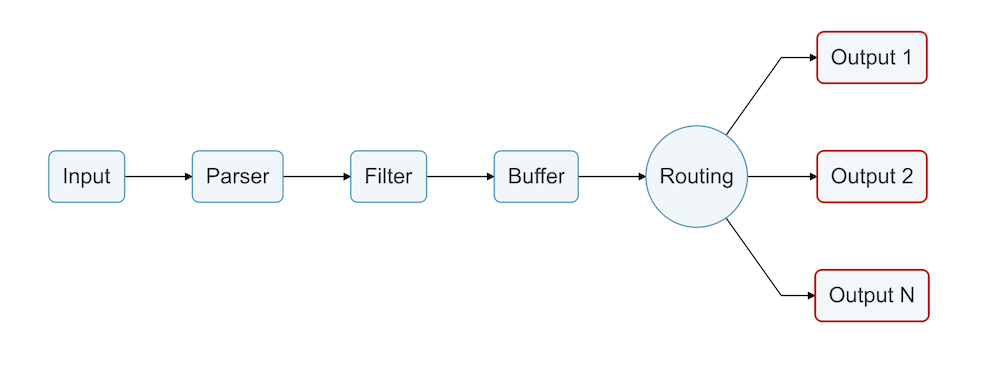
Quando se trata de Fluentd vs. Fluent Bit, o último é uma escolha melhor do que o Fluentd para tarefas mais simples, especialmente quando você só precisa de encaminhamento de logs com processamento mínimo e nada mais complexo.
Avaliamos várias outras opções antes do Fluent Bit, como Logstash, Promtail e rsyslog, mas acabamos optando pelo Fluent Bit por alguns motivos. Primeiro, ele é uma solução OSS com suporte do CNCF e já é amplamente utilizado em provedores locais e de nuvem. Segundo, ele é leve e também é executado no OpenShift. Terceiro, e o mais importante, ele tem amplas opções de configuração para que você possa direcionar qualquer endpoint que você precise.
(Veja meu artigo anterior sobre o Fluent Bit ou a documentação detalhada de encaminhamento de registros para obter mais informações).
Dica #1: Conecte-se com a comunidade OSS
Minha primeira recomendação para usar o Fluent Bit é contribuir e se envolver com sua comunidade de código aberto.
Quase tudo neste artigo é descaradamente reutilizado de outros, seja de o Slack Fluente, postagens de blog, Repositórios do GitHub ou coisas do gênero. Ao mesmo tempo, contribuí com vários analisadores que criamos para o Couchbase de volta ao repositório oficialEspero que eu tenha levantado algumas questões úteis!
A comunidade OSS do Fluent Bit é ativa. Seus mantenedores se comunicam regularmente, corrigem problemas e sugerem soluções. Por exemplo, FluentCon EU 2021 gerou muitas sugestões e comentários úteis sobre o uso do Fluent Bit que, desde então, integramos em versões subsequentes. (FluentCon é tipicamente co-localizado em eventos da KubeCon).
Dica #2: Depuração quando tudo está quebrado
Nos canais do Slack da comunidade Fluent Bit, as perguntas mais comuns são sobre como depurar as coisas quando elas não estão funcionando. Minhas duas recomendações aqui são:
- Use o
saídaplugin. - Aumente o nível de registro do Fluent Bit.
Minha primeira sugestão seria simplificar. A maioria dos usuários do Fluent Bit está tentando canalizar os logs para uma pilha maior, por exemplo, Elastic-Fluentd-Kibana (EFK) ou Prometheus-Loki-Grafana (PLG). Para começar, não olhe para o que o Kibana ou o Grafana estão lhe dizendo até que você tenha removido todos os possíveis problemas com o encanamento na pilha de sua escolha.
Use o saída plug-in para determinar o que o Fluent Bit acha que é a saída. Em seguida, itere até obter a saída múltipla do Fluent Bit que você estava esperando. É muito mais fácil começar aqui do que lidar com todas as partes móveis de uma pilha EFK ou PLG.
Minha segunda dica de depuração é aumentar o nível de registro. Essa etapa torna óbvio o que o Fluent Bit está tentando encontrar e/ou analisar. Em muitos casos, o aumento do nível de registro destaca correções simples, como problemas de permissões ou o uso do curinga/caminho errado.
Considerações sobre as verificações de integridade do Helm
Se estiver usando o Helm, ative o servidor HTTP para verificações de integridade se tiver ativado essas sondas.
O Helm é bom para uma instalação simples, mas como é uma ferramenta genérica, você precisa garantir que a configuração do Helm seja aceitável. Se você habilitar as sondas de verificação de integridade no Kubernetes, também precisará habilitar o endpoint para elas na configuração do Fluent Bit.
As versões mais recentes do Fluent Bit têm uma verificação de saúde dedicada (que também usaremos na próxima versão do Operador Autônomo do Couchbase).
Dica #3: Transformando água em vinho com análise
Normalmente, você deseja analisar seus registros depois de lê-los. Eu uso o plug-in de entrada de cauda para converter dados não estruturados em dados estruturados (por a terminologia oficial).
O fracasso não é uma opção
Quando se trata da solução de problemas do Fluent Bit, um ponto importante a ser lembrado é que Se a análise falhar, você ainda obterá a saída. O analisador do Fluent Bit apenas fornece toda a linha de registro como um único registro. Esse recurso de retorno é um bom recurso do Fluent Bit, pois você nunca perde informações e uma ferramenta de downstream diferente sempre pode analisá-las novamente.
Um truque útil aqui é garantir que você nunca tenha a opção padrão registro no registro após a análise. Se você vir a mensagem registro então você sabe que a análise falhou. Caso contrário, nem sempre é óbvio.
Dica #4: Você não consegue lidar com a verdade (análise de várias linhas)
Análise de várias linhas é um recurso fundamental do Fluent Bit. Alguns registros são produzidos por processos Erlang ou Java que o utilizam extensivamente.
O objetivo com análise de várias linhas é fazer uma passagem inicial para extrair um conjunto comum de informações. Para os logs do Couchbase, decidimos que cada entrada de log tem um carimbo de data/hora, nível e mensagem (com mensagem sendo bastante aberto, pois continha tudo o que não foi capturado nos dois primeiros).
O nome do arquivo de registro também é usado como parte do a tag Fluent Bit. Implementamos essa prática porque você pode querer rotear diferentes registros para destinos separadosPor exemplo o registro de auditoria tende a ser um requisito de segurança:
|
1 2 3 4 5 |
@include /fluent-bit/etc/fluent-bit.conf [OUTPUT] Name s3 Match couchbase.log.audit ... |
Conforme mostrado acima (e em mais detalhes aqui), esse código ainda envia todos os logs para a saída padrão por padrão, mas também envia os logs de auditoria para o AWS S3.
Vamos dar uma olhada em outro exemplo de análise de várias linhas com este passo a passo abaixo (e no GitHub aqui):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[INPUT] Name tail Alias erlang_tail # ^See note 1 below Path ${COUCHBASE_LOGS}/babysitter.log,${COUCHBASE_LOGS}/couchdb.log,${COUCHBASE_LOGS}/debug.log,${COUCHBASE_LOGS}/json_rpc.log,${COUCHBASE_LOGS}/metakv.log,${COUCHBASE_LOGS}/ns_couchdb.log,${COUCHBASE_LOGS}/reports.log Multiline On Parser_Firstline couchbase_erlang_multiline Refresh_Interval 10 # ^See note 2 Skip_Long_Lines On # ^See note 3 Skip_Empty_Lines On # ^See note 4 Path_Key filename # ^See note 5 # We want to tag with the name of the log so we can easily send named logs to different output destinations. # This requires a bit of regex to extract the info we want. Tag couchbase.log. Tag_Regex ${COUCHBASE_LOGS}/(?[^.]+).log$ # ^See note 6 |
Observações:
[1] Especifique um alias para esse plug-in de entrada. Isso é muito útil se houver um problema ou para rastrear métricas.
[2] A lista de registros é atualizada a cada 10 segundos para coletar novos registros.
[3] Se você atingir uma linha longa, isso a ignorará em vez de interromper qualquer outra entrada. Lembre-se de que o Fluent Bit começou como uma solução incorporada, portanto, muito do suporte a limites estáticos está em vigor por padrão.
[4] Uma adição recente à versão 1.8 foi a possibilidade de pular linhas vazias. Essa opção está ativada para manter o ruído baixo e garantir que os testes automatizados ainda sejam aprovados.
[5] Certifique-se de adicionar a tag Fluent Bit filename no registro. Isso é útil no downstream para filtragem.
[6] Tag por nome de arquivo. Nesse caso, usamos um regex para extrair o nome do arquivo, pois estamos trabalhando com vários arquivos.
Uma recomendação óbvia é garantir que seu regex funcione por meio de testes. Você pode usar uma ferramenta on-line, como a:
-
- Rubular
- RegEx101
- Caliptia (A Calyptia também tem uma ferramenta de visualização, e eu tenho um script para lidar com os arquivos incluídos, para extrair tudo em um único arquivo pastável.)
É importante observar que, como sempre, há aspectos específicos do mecanismo de regex usado pelo Fluent Bit, portanto, em última análise, você também precisa testar esse aspecto. Por exemplo, certifique-se de que você nomear os grupos adequadamente (alfanumérico mais sublinhado apenas, sem hífens), pois isso pode causar problemas.
Dica: Se a regex não estiver funcionando, mesmo que deve - simplificar as coisas até que isso aconteça.
O exemplo anterior do analisador multilinha do Fluent Bit lidou com as mensagens Erlang, que tinham a seguinte aparência:
|
1 2 |
[ns_server:info,2021-03-09T17:31:55.351Z,babysitter_of_ns_1@cb.local:<0.92.0>:ns_babysitter:init_logging:136]Brought up babysitter logging [ns_server:debug,2021-03-09T17:31:55.373Z,babysitter_of_ns_1@cb.local:<0.92.0>:dist_manager:configure_net_kernel:293]Set net_kernel vebosity to 10 -> 0 |
O snippet acima mostra apenas mensagens de linha única para fins de brevidade, mas também há exemplos grandes e com várias linhas nos testes. Lembre-se de que o analisador procura os colchetes para indicar o início de cada mensagem de registro possivelmente com várias linhas:
|
1 2 3 4 5 6 7 |
[PARSER] Name couchbase_erlang_multiline Format regex Regex \[(?\w+):(?\w+),(?\d+-\d+-\d+T\d+:\d+:\d+.\d+Z),(?.*)$ Time_Key timestamp Time_Format %Y-%m-%dT%H:%M:%S.%L Time_Keep On |
Complicações e considerações sobre a análise de carimbo de data/hora
Infelizmente, você não pode ter um regex completo para o carimbo de data/hora campo. Se você tiver vários formatos de data e hora, será difícil lidar com isso. Por exemplo, você pode encontrar os seguintes formatos de registro de data e hora no mesmo arquivo de registro:
|
1 2 |
2021-03-09T17:32:15.545+00:00 [INFO] Using ... 2021/03/09 17:32:15 audit: ... |
Na época do lançamento da versão 1.7, não havia uma boa maneira de analisar formatos de carimbo de data/hora em uma única passagem. Portanto, para os logs do Couchbase, projetamos o Fluent Bit para ignorar qualquer falha na análise do carimbo de data/hora do log e usamos apenas a hora da análise como o valor do Fluent Bit. A hora real não é vital e deve ser próxima o suficiente.
A análise de vários formatos na série Fluent Bit 1.8 deve ser capaz de suportar uma melhor análise de carimbo de data/hora. Porém, até o momento em que este texto foi escrito, o Couchbase ainda não estava usando essa funcionalidade. O snippet abaixo mostra um exemplo de análise de vários formatos:
|
1 2 3 4 5 6 7 8 9 10 |
# Cope with two different log formats, e.g.: # 2021/03/09 17:32:15 cbauth: ... # 2021-03-09T17:32:15.303+00:00 [INFO] ... # https://rubular.com/r/XUt7xQqEJnrF2M [PARSER] Name couchbase_simple_log_mixed Format regex Regex ^(?\d+(-|/)\d+(-|/)\d+(T|\s+)\d+:\d+:\d+(\.\d+(\+|-)\d+:\d+|))\s+((\[)?(?\w+)(\]|:))(?.*)$ Time_Key timestamp Time_Keep On |
Outro aspecto a ser observado aqui é que o teste de regressão automatizado é obrigatório!
Dica #5: Garimpagem de ouro com filtragem
Sou um grande fã de a pilha Loki/GrafanaPor isso, eu o usei bastante ao testar o encaminhamento de logs com o Couchbase.
Um problema com a versão original do contêiner do Couchbase era que os níveis de registro não eram padronizados: você poderia obter coisas como INFORMAÇÕES, Informações, informações com casos diferentes ou DEBU, depurar, etc. com diferentes cadeias de caracteres reais para o mesmo nível. Essa falta de padronização dificultava a visualização e a filtragem no Grafana (ou na ferramenta de sua escolha) sem algum processamento extra.
Com base em uma sugestão de um usuário do Slack, Adicionei alguns filtros que efetivamente restringem todos os vários níveis em um único nível usando a seguinte enumeração: DESCONHECIDO, DEBUG, INFORMAÇÕES, AVISO, ERRO. Esses filtros do Fluent Bit começam com os vários casos de canto e, em seguida, são aplicados para tornar todos os níveis consistentes.
Veja como isso funciona: Sempre que um campo é fixo para um valor conhecido, uma chave temporária extra é adicionada para ele. Essa chave temporária a exclui de qualquer outra correspondência nesse conjunto de filtros. A chave a chave temporária é então removida no final. Veja abaixo um exemplo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[FILTER] Name modify Alias handle_levels_uppercase_error_modify Match couchbase.log.* Condition Key_value_matches level (?i:ERRO\w*) Set level ERROR # Make sure we don't re-match it Condition Key_value_does_not_equal __temp_level_fixed Y Set __temp_level_fixed Y … # Remove all "temp" vars here [FILTER] Name modify Alias handle_levels_remove_temp_vars_modify Match couchbase.log.* Remove_regex __temp_.+ |
No final, o conjunto restrito de resultados é muito mais fácil de usar.
Dica #6: Como adicionar informações opcionais
Uma coisa que você provavelmente vai querer incluir nos logs do Couchbase são dados extras, se estiverem disponíveis.
Para meus próprios projetos, inicialmente usei A parte fluente modificar filtro para adicionar chaves extras ao registro. No entanto, se determinadas variáveis não forem definidas, o modificar o filtro sairia.
Descobri mais tarde que você deve usar o modificador de registro filtro em vez disso. Esse filtro avisa se uma variável não estiver definida, portanto, você pode usá-lo com um superconjunto das informações que deseja incluir.
Em resumo: Se quiser adicionar informações opcionais ao encaminhamento de logs, use modificador de registro em vez de modificar.
Incluí um exemplo de modificador de registro abaixo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
[FILTER] Name record_modifier Alias common_info_modifier Match couchbase.log.* Record hostname ${HOSTNAME} Record logshipper couchbase.sidecar.fluentbit # These should be built into the container Record couchbase.logging.version ${COUCHBASE_FLUENTBIT_VERSION} Record fluentbit.version ${FLUENTBIT_VERSION} # The following are set by the operator from the pod meta-data, they may not exist on normal containers Record pod.namespace ${POD_NAMESPACE} Record pod.name ${POD_NAME} Record pod.uid ${POD_UID} # The following come from kubernetes annotations and labels set as env vars so also may not exist Record couchbase.cluster ${couchbase_cluster} Record couchbase.operator.version ${operator.couchbase.com/version} Record couchbase.server.version ${server.couchbase.com/version} Record couchbase.node ${couchbase_node} Record couchbase.node-config ${couchbase_node_conf} Record couchbase.server ${couchbase_server} # These are config dependent so will trigger a failure if missing but this can be ignored Record couchbase.analytics ${couchbase_service_analytics} Record couchbase.data ${couchbase_service_data} Record couchbase.eventing ${couchbase_service_eventing} Record couchbase.index ${couchbase_service_index} Record couchbase.query ${couchbase_service_query} Record couchbase.search ${couchbase_service_search} |
Eu também uso o filtro Nest para consolidar todos os couchbase.* e pod.* em estruturas JSON aninhadas para saída. Ao usar o filtro Nest, todas as operações de downstream são simplificadas porque as informações específicas do Couchbase estão em uma única estrutura aninhada, em vez de ter que analisar todo o registro de log para tudo. Isso é semelhante para as informações do pod, que podem estar faltando nas informações locais.
Dica #7: Use pseudônimos
Outra dica valiosa que você já deve ter notado nos exemplos até agora: usar aliases.
Ao usar um alias para um filtro específico (ou entrada/saída), você tem um nome legível e agradável nos logs e métricas do Fluent Bit, em vez de um número difícil de descobrir. Recomendo que você crie um processo de nomeação de alias de acordo com o local e a função do arquivo.
A documentação do Fluent Bit mostra a você como acessar métricas no formato Prometheus com vários exemplos.
A execução com a imagem do Couchbase Fluent Bit mostra a seguinte saída em vez de apenas cauda.0, cauda.1 ou similar com os filtros:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# HELP fluentbit_filter_drop_records_total Fluentbit metrics. # TYPE fluentbit_filter_drop_records_total counter fluentbit_filter_drop_records_total{name="common_info_modifier"} 0 1629194033696 fluentbit_filter_drop_records_total{name="couchbase_common_info_nest"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_filenames_add_missing_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_add_info_missing_level_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_add_unknown_missing_level_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_check_for_incorrect_level"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_remove_temp_vars_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_uppercase_debug_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_uppercase_error_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_uppercase_info_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_uppercase_warn_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_filename_in_log_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_message_unknown_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_msg_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_tail_filename_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_ts_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="parser.16"} 0 1629194033696 fluentbit_filter_drop_records_total{name="pod_common_info_nest"} 0 1629194033696 # HELP fluentbit_input_bytes_total Number of input bytes. # TYPE fluentbit_input_bytes_total counter fluentbit_input_bytes_total{name="audit_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="erlang_tail"} 691360 1629194033696 fluentbit_input_bytes_total{name="http_tail"} 4302 1629194033696 fluentbit_input_bytes_total{name="java_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="memcached_tail"} 10623 1629194033696 fluentbit_input_bytes_total{name="prometheus_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="rebalance_process_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="simple_mixed_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="simple_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="xdcr_tail"} 26544 1629194033696 |
E se algo der errado nos registros, você não precisará perder tempo descobrindo qual plug-in pode ter causado o problema com base em seu ID numérico.
Outra consideração sobre aliases
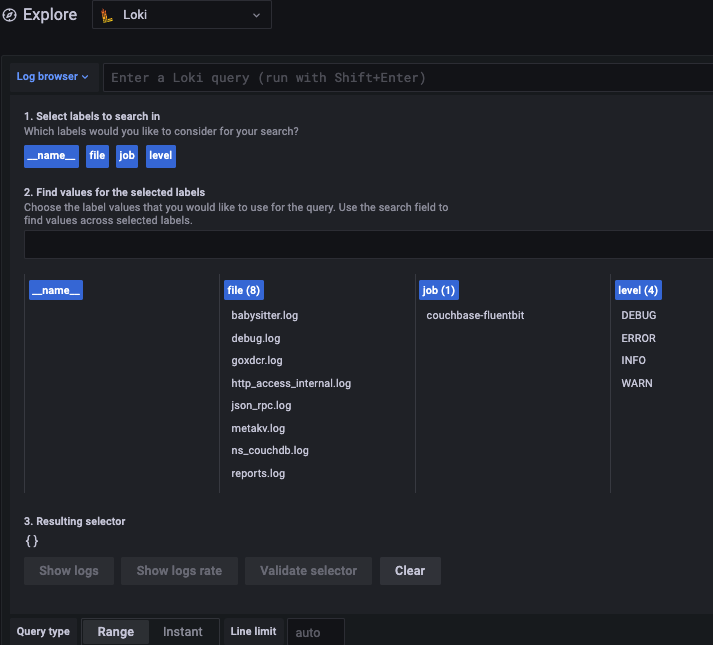
Se você estiver usando o Loki, como eu, poderá ter outro problema com aliases.
No meu caso, eu estava filtrando o arquivo de log usando o nome do arquivo. Embora o plug-in tail preencha automaticamente o nome do arquivo para você, infelizmente ele inclui o caminho completo do nome do arquivo. Mas o Grafana mostra apenas a primeira parte da cadeia de caracteres do nome do arquivo até que ela seja cortada, o que é particularmente inútil, já que todos os registros estão no mesmo local de qualquer maneira.
O resultado final é uma experiência frustrante, como você pode ver abaixo.
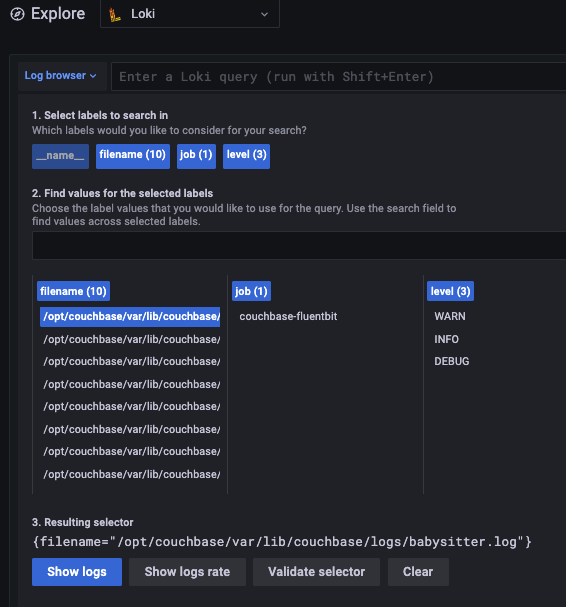
Para resolver esse problema, Adicionei um filtro extra que fornece um nome de arquivo reduzido e mantém o original também. Esse filtro requer um analisador simples, que incluí abaixo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[PARSER] Name couchbase_filename_shortener Format regex Regex ^(?.*)/(?.*)$ [FILTER] Name parser Match couchbase.log.* Key_Name filename Parser couchbase_filename_shortener # Do not overwrite original field Preserve_Key On # Keep everything else Reserve_Data On |
Com esse analisador instalado, você obtém um filtro simples com entradas como audit.log, babá.registroetc., em vez de prefixos de caminho completo, como /opt/couchbase/var/lib/couchbase/logs/.
Dica #8: Filtro Lua: Todas as suas bases (de sofá) pertencem a nós
A parte fluente Filtro Lua pode resolver praticamente todos os problemas. A questão, porém, é, Deveria?
A imagem do Couchbase Fluent Bit inclui um pouco de código Lua para suporte à redação por meio de hashing para campos específicos nos registros do Couchbase. O objetivo dessa redação é substituir os dados identificáveis por um hash que possa ser correlacionado entre os logs para fins de depuração sem vazar as informações originais. Usando um filtro Lua, o Couchbase redige os registros em tempo real por meio do hash SHA-1 do conteúdo de qualquer coisa cercada por tags .. na mensagem de registro.
Na FluentCon EU deste ano, Mike Marshall apresentou algumas dicas excelentes sobre o uso de filtros Lua com o Fluent Bit incluindo um Lua especial camiseta filtro que permite que você toque em vários pontos do pipeline para ver o que está acontecendo. É um filtro genérico que despeja todos os seus pares de valores-chave nesse ponto do pipeline, o que é útil para criar uma visualização antes e depois de um determinado campo.
Dica #9: Teste, teste e teste novamente
Considerando todos esses vários recursos, a configuração do Couchbase Fluent Bit é grande. Confira a imagem abaixo que mostra a configuração da versão 1.1.0 usando o visualizador Calyptia.
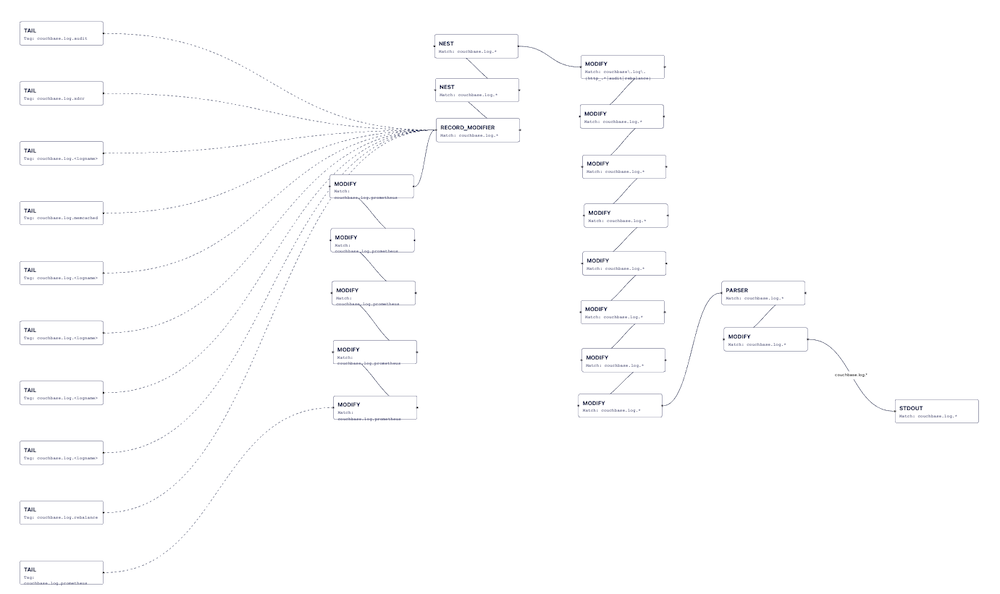
Dado o tamanho dessa configuração, a equipe do Couchbase fez muitos testes para garantir que tudo se comporte conforme o esperado. A partir de todos esses testes, criei exemplos de conjuntos de mensagens problemáticas e os vários formatos em cada arquivo de registro para usar como um conjunto de testes automatizados em relação ao resultado esperado. Também criei um contêiner de teste que executa todos esses testes; é um contêiner de produção com scripts e dados de teste sobrepostos. À medida que a equipe encontrar novos problemas, estenderei os casos de teste.
Essas ferramentas também ajudam você a fazer testes para melhorar o resultado. Por exemplo, se você estiver encurtando o nome do arquivoSe você não estiver usando o sistema, poderá usar essas ferramentas para vê-lo diretamente e confirmar se está funcionando corretamente.
Dica #10: Separe suas áreas de preocupação
Cada parte do A configuração do Couchbase Fluent Bit é dividida em um arquivo separado. Há um arquivo por plugin de cauda, um arquivo para cada conjunto de filtros comuns e um para cada plugin de saída. Eu o projetei dessa forma por dois motivos principais:
- Reutilização simples de diferentes configurações
- Testes
O Couchbase fornece uma configuração padrão, mas é provável que você queira ajustar quais logs deseja analisar e como. Você pode simplesmente @incluir a parte específica de a configuração que você desejaPor exemplo, se você quiser apenas a análise e a saída de logs de auditoria, poderá incluir apenas isso. Não há necessidade de escrever a configuração diretamente, o que poupa o esforço de aprender todas as opções e reduz os erros.
Essa configuração dividida também simplifica os testes automatizados. Por exemplo, você pode simplesmente inclua a configuração da cauda e, em seguida, adicione um read_from_head para que ele leia todas as entradas. Eu mostrei isso abaixo
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
cat > "$testConfig" << __FB_EOF @include /fluent-bit/test/conf/test-service.conf # Now we include the configuration we want to test which should cover the logfile as well. # We cannot exit when done as this then pauses the rest of the pipeline so leads to a race getting chunks out. # https://github.com/fluent/fluent-bit/issues/3274 # Instead we rely on a timeout ending the test case. @include $i Read_from_head On @include /fluent-bit/test/conf/test-filters.conf @include /fluent-bit/test/conf/test-output.conf __FB_EOF |
Mas há uma advertência: Certifique-se de testar também a configuração geral em conjunto. Recentemente me deparei com um problema em que cometi um erro de digitação no nome do include quando usado na configuração geral. A adição de uma chamada para -corrida a seco detectou isso em testes automatizados, conforme mostrado abaixo:
|
1 |
if "${COUCHBASE_LOGS_BINARY}" --dry-run --config="$i"; then |
Isso valida que a configuração está correta o suficiente para passar nas verificações estáticas. Lembre-se de que ainda pode haver falhas durante o tempo de execução quando ele carrega determinados plug-ins com essa configuração. Nesses casos, aumentar o nível de registro normalmente ajuda (consulte a Dica #2 acima).
Espere o inesperado durante o teste
Quando você estiver testando ou solucionando problemas no Fluent Bit, é importante lembrar que cada mensagem de registro deve conter determinados campos (como mensagem, nívele carimbo de data/hora) e não outros (como registro).
Essa distinção é particularmente útil quando você deseja testar uma nova entrada de registro, mas não tem uma saída de ouro para comparar. Por exemplo, quando estiver testando uma nova versão do Couchbase Server e ele está produzindo registros ligeiramente diferentes. Minha recomendação é usar o Esperar plug-in para sair quando uma condição de falha for encontrada e acionar uma falha de teste dessa forma.
Infelizmente Atualmente, o Fluent Bit é encerrado com um código 0, mesmo em caso de falha, portanto, você precisa analisar a saída para verificar por que ele foi encerrado. Nesse caso, você também deve executar com um tempo limite em vez de um exit_when_done. Caso contrário, você aciona uma saída assim que o arquivo de entrada chega ao fim que pode ser antes de você ter liberado toda a saída para o diff:
|
1 2 3 4 |
timeout -s 9 "${EXPECT_TEST_TIMEOUT}" "${COUCHBASE_LOGS_BINARY}" --config "$testConfig" > "$testLog" 2>&1 # Currently it always exits with 0 so we have to check for a specific error message. # https://github.com/fluent/fluent-bit/issues/3268 if grep -iq -e "exception on rule" -e "invalid config" "$testLog" ; then |
Também preciso manter o script de teste funcional tanto para o Busybox (o contêiner de depuração oficial) quanto para o UBI (o contêiner da Red Hat), que às vezes limita os recursos do Bash ou os binários extras usados.
Dica #11: Como usar o Fluent Bit com o Red Hat OpenShift
Há um operador autônomo do Couchbase para o Red Hat OpenShift que exige que todos os contêineres passem por várias verificações para certificação. Uma dessas verificações é que a imagem base seja UBI ou RHEL.
A equipe do Couchbase usa a imagem oficial do Fluent Bit para tudo, exceto para o OpenShift, e nós construí-lo a partir da fonte em uma imagem de base UBI para o catálogo de contêineres da Red Hat. Nós o criamos a partir do código-fonte para que o número da versão seja especificado, já que atualmente o repositório Yum fornece apenas a versão mais recente. Além disso, ele é um alvo CentOS 7 RPM que aumenta a imagem se ela for implantada com todos os RPMs de suporte adicionais para execução no UBI 8.
Há um exemplo no repositório que mostra como usar os RPMs diretamente também.
Conclusão
Espero que essas dicas e truques tenham ajudado você a usar melhor o Fluent Bit para encaminhamento de logs e gerenciamento de logs de auditoria com o Couchbase.
Escolhemos o Fluent Bit para que seus logs do Couchbase tivessem um formato comum com configuração dinâmica. Também queríamos usar um padrão do setor com o mínimo de sobrecarga para facilitar o trabalho de usuários como você.
Se você estiver interessado em saber mais, apresentarei um mergulho mais profundo nesse mesmo conteúdo em a próxima FluentCon. Espero vê-lo lá.
Faça o download do Couchbase Server 7 hoje mesmo
