Aaron Benton é um arquiteto experiente, especializado em soluções criativas para desenvolver aplicativos móveis inovadores. Ele tem mais de 10 anos de experiência em desenvolvimento de pilha completa, incluindo ColdFusion, SQL, NoSQL, JavaScript, HTML e CSS. Atualmente, Aaron é Arquiteto de Aplicativos da Shop.com em Greensboro, Carolina do Norte, e é um Campeão da comunidade do Couchbase.

Série FakeIt 3 de 5: Modelos Lean por meio de definições
Em nossa postagem anterior FakeIt Série 2 de 5: Dados compartilhados e dependências, vimos como criar dependências de vários modelos com a FakeIt. Hoje, veremos como podemos criar os mesmos modelos, porém menores, aproveitando as definições.
As definições são uma forma de criar conjuntos reutilizáveis em seu modelo. Elas permitem que você defina um conjunto de propriedades/valores uma única vez, referenciando-os várias vezes em seu modelo. As definições em um modelo FakeIt são muito semelhantes ao modo como as definições são usadas no Swagger / Especificação de API aberta.
Modelo de usuários
Começaremos com nosso modelo users.yaml que definimos em nosso primeira publicação.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
name: Users type: object key: _id properties: _id: type: string description: The document id built by the prefix "user_" and the users id data: post_build: `user_${this.user_id}` doc_type: type: string description: The document type data: value: user user_id: type: integer description: An auto-incrementing number data: build: document_index first_name: type: string description: The users first name data: build: faker.name.firstName() last_name: type: string description: The users last name data: build: faker.name.lastName() username: type: string description: The username data: build: faker.internet.userName() password: type: string description: The users password data: build: faker.internet.password() email_address: type: string description: The users email address data: build: faker.internet.email() created_on: type: integer description: An epoch time of when the user was created data: build: new Date(faker.date.past()).getTime() |
Digamos que temos um novo requisito em que precisamos oferecer suporte a um endereço residencial e comercial para cada usuário. Com base nesse requisito, decidimos criar uma propriedade de nível superior chamada endereços que conterá propriedades aninhadas de residência e trabalho.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ ... "addresses": { "home": { "address_1": "123 Broadway St", "address_2": "Apt. C", "locality": "Greensboro", "region": "NC", "postal_code": "27409", "country": "US" }, "work": { "address_1": "321 Morningside Ave", "address_2": "", "locality": "Greensboro", "region": "NC", "postal_code": "27409", "country": "US" } } } |
Nosso modelo users.yaml precisará ser atualizado para dar suporte a essas novas propriedades de endereço.
(Para fins de brevidade, as outras propriedades foram deixadas de fora da definição do modelo)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
... properties: ... addresses: type: object description: An object containing the home and work addresses for the user properties: home: type: object description: The users home address properties: address_1: type: string description: The address 1 data: build: `${faker.address.streetAddress()} ${faker.address.streetSuffix()}` address_2: type: string description: The address 2 data: build: chance.bool({ likelihood: 35 }) ? faker.address.secondaryAddress() : null locality: type: string description: The city / locality data: build: faker.address.city() region: type: string description: The region / state / province data: build: faker.address.stateAbbr() postal_code: type: string description: The zip code / postal code data: build: faker.address.zipCode() country: type: string description: The country code data: build: faker.address.countryCode() work: type: object description: The users home address properties: address_1: type: string description: The address 1 data: build: `${faker.address.streetAddress()} ${faker.address.streetSuffix()}` address_2: type: string description: The address 2 data: build: chance.bool({ likelihood: 35 }) ? faker.address.secondaryAddress() : null locality: type: string description: The city / locality data: build: faker.address.city() region: type: string description: The region / state / province data: build: faker.address.stateAbbr() postal_code: type: string description: The zip code / postal code data: build: faker.address.zipCode() country: type: string description: The country code data: build: faker.address.countryCode() |
Como você pode ver, nossas propriedades de endereço residencial e comercial contêm exatamente as mesmas propriedades aninhadas. Essa duplicação torna nosso modelo maior e mais detalhado. Além disso, o que acontecerá se nossos requisitos de endereço precisarem mudar? Teríamos que fazer duas atualizações para manter a mesma estrutura. É nesse ponto que podemos tirar proveito das definições, definindo uma única maneira de criar um endereço e fazer referência a ele.
(Para fins de brevidade, as outras propriedades foram deixadas de fora da definição do modelo)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
... properties: ... addresses: type: object description: An object containing the home and work addresses for the user properties: home: description: The users home address schema: $ref: '#/definitions/Address' work: description: The users work address schema: $ref: '#/definitions/Address' definitions: Address: type: object properties: address_1: type: string description: The address 1 data: build: `${faker.address.streetAddress()} ${faker.address.streetSuffix()}` address_2: type: string description: The address 2 data: build: chance.bool({ likelihood: 35 }) ? faker.address.secondaryAddress() : null locality: type: string description: The city / locality data: build: faker.address.city() region: type: string description: The region / state / province data: build: faker.address.stateAbbr() postal_code: type: string description: The zip code / postal code data: build: faker.address.zipCode() country: type: string description: The country code data: build: faker.address.countryCode() |
As definições são definidas na raiz do modelo, especificando uma propriedade definitions: e, em seguida, o nome da definição. As definições são referenciadas usando $ref com o valor sendo o caminho para a definição, por exemplo, #/definitions/Address. Com o uso de definições, economizamos quase 30 linhas de código em nosso modelo e criamos um único local para a definição e a geração de um endereço em nosso modelo de usuários.
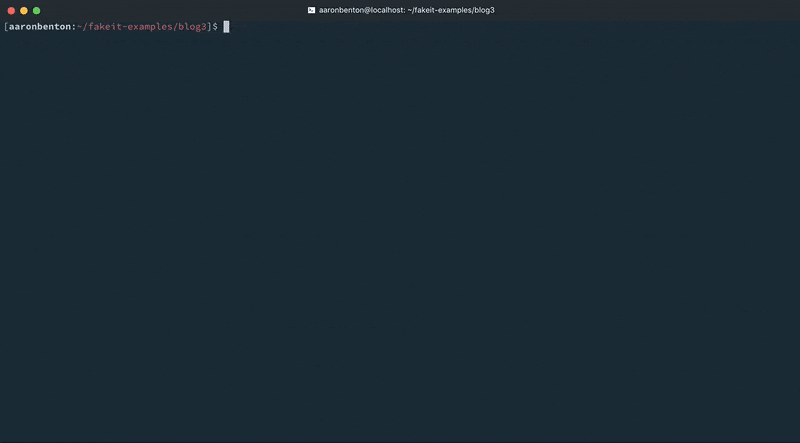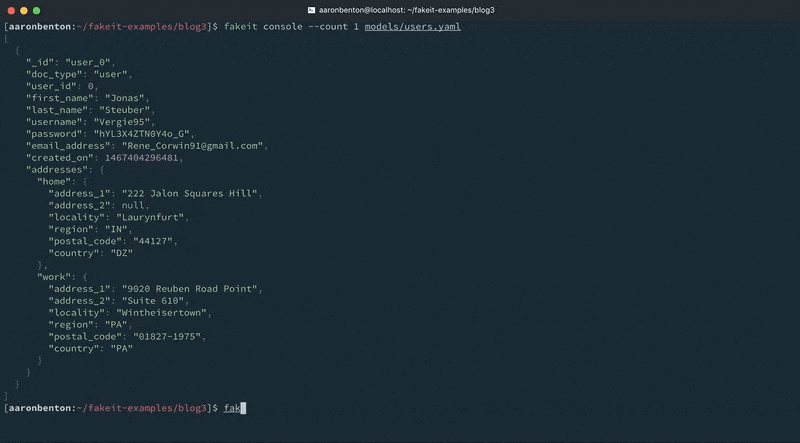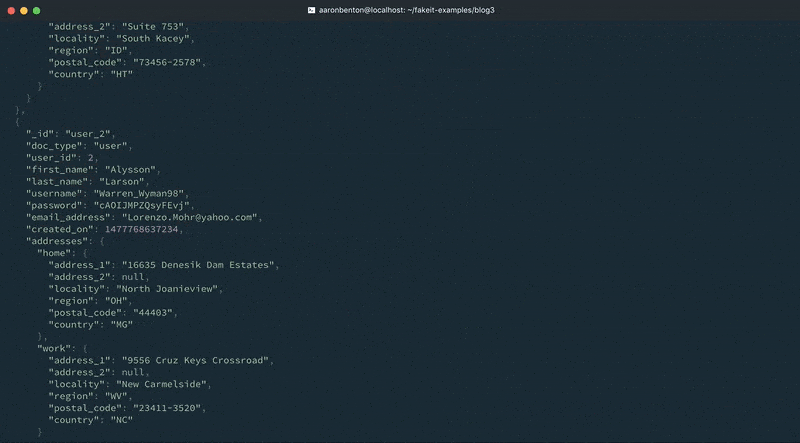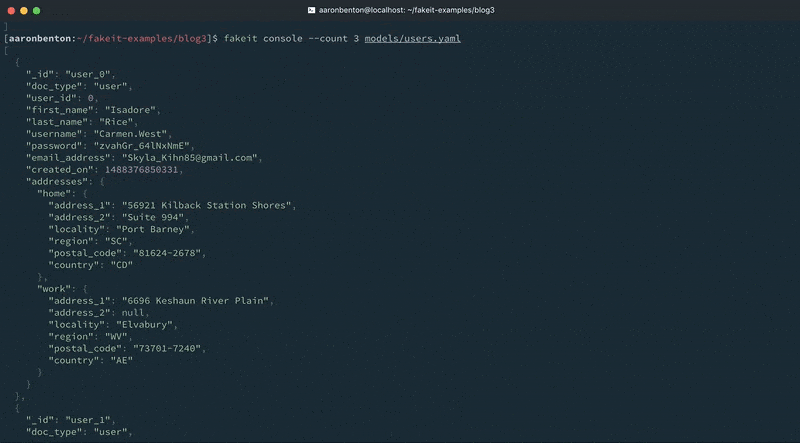
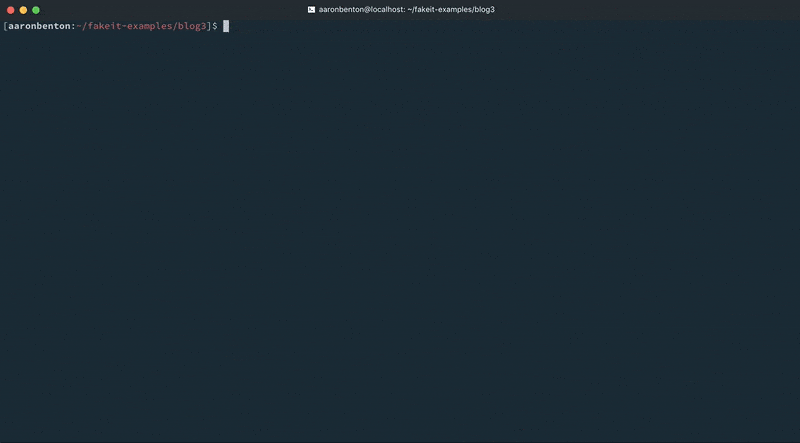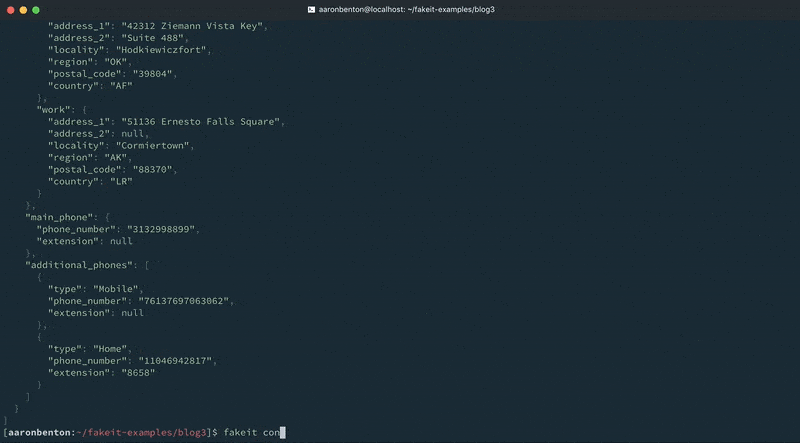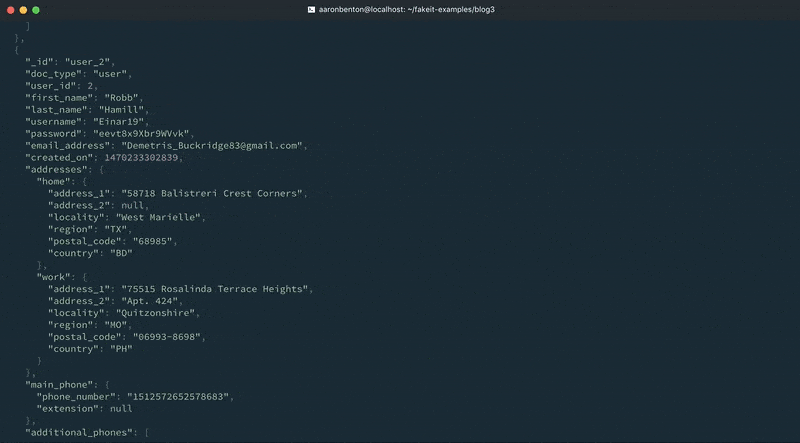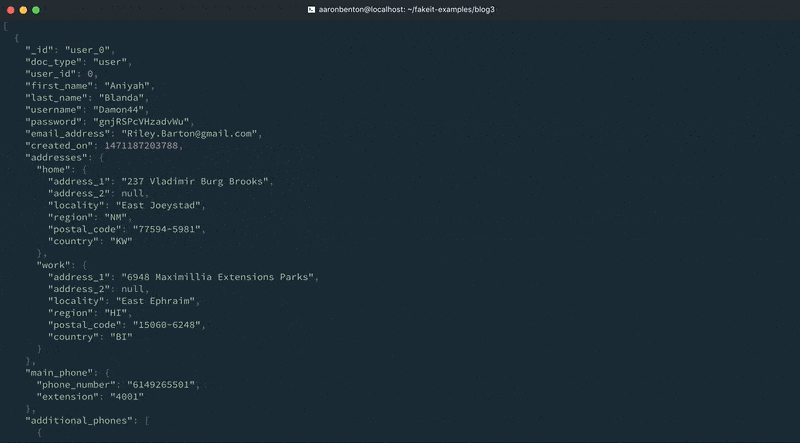
Podemos testar a saída de nossos endereços de modelo de usuários atualizados usando o seguinte comando:
|
1 |
fakeit console --count 1 models/users.yaml |
Agora, digamos que tenhamos um requisito para armazenar o número de telefone principal de um usuário e, em seguida, armazenar números de telefone adicionais opcionais, ou seja, residencial, comercial, celular, fax etc. Para essa alteração, usaremos duas novas propriedades de nível superior: main_phone e additional_phones, que são uma matriz.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ ... "main_phone": { "phone_number": "7852322322", "extension": null }, "additional_phones": [ { "phone_number": "3368232032", "extension": "3233", "type": "Work" }, { "phone_number": "4075922921", "extension": null, "type": "Mobile" } ] } |
Embora esse possa não ser o modelo de dados mais prático, ou como eu pessoalmente teria modelado esses dados, podemos usar esse exemplo novamente para ilustrar como podemos tirar proveito do uso de definições em nosso modelo FakeIt.
(Para fins de brevidade, as outras propriedades foram deixadas de fora da definição do modelo)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
... properties: ... main_phone: description: The users main phone number schema: $ref: '#/definitions/Phone' data: post_build: | delete this.main_phone.type return this.main_phone additional_phones: type: array description: The users additional phone numbers items: $ref: '#/definitions/Phone' data: min: 1 max: 4 definitions: Phone: type: object properties: type: type: string description: The phone type data: build: faker.random.arrayElement([ 'Home', 'Work', 'Mobile', 'Other' ]) phone_number: type: string description: The phone number data: build: faker.phone.phoneNumber().replace(/[^0-9]+/g, '') extension: type: string description: The phone extension data: build: chance.bool({ likelihood: 30 }) ? chance.integer({ min: 1000, max: 9999 }) : null |
Para este exemplo, criamos uma definição de Phone que contém 3 propriedades: type, phone_number e extension. Você notará que definimos uma função post_build na propriedade main_phone que remove o atributo type. Isso ilustra como as definições podem ser usadas em conjunto com uma função de compilação para manipular o que é retornado pela definição. A propriedade additional_phones é uma matriz de definições de telefone que gerará entre 1 e 4 telefones. Podemos testar a saída dos números de telefone do nosso modelo Users atualizado usando o seguinte comando:
|
1 |
fakeit console --count 1 models/users.yaml |
Conclusão
As definições permitem que você simplifique seus modelos FakeIt criando conjuntos reutilizáveis de código para modelos menores e mais eficientes.
Próximo
- FakeIt Série 4 de 5: Trabalhando com dados existentes
- FakeIt Series 5 de 5: Desenvolvimento móvel rápido com o Sync-Gateway
Anterior
- FakeIt Série 1 de 5: Geração de dados falsos
- FakeIt Série 2 de 5: Dados compartilhados e dependências
 Esta postagem faz parte do Programa de Redação da Comunidade Couchbase
Esta postagem faz parte do Programa de Redação da Comunidade Couchbase