Além de todas as discussões recentes sobre o Kubernetes e se você deve ou não Dockerizar seu banco de dados, hoje eu gostaria de mostrar por que essas duas coisas podem ser boas soluções quando a escalabilidade e a elasticidade são um grande requisito em sua arquitetura.
O segredo aqui é simples: Spring Boot com Kubernetes para implantação do aplicativo e do banco de dados usando NoSQL.
Por que NoSQL e Spring Data?
Com os bancos de dados de documentos, é possível evitar muitas junções desnecessárias, pois toda a estrutura é armazenada em um único documento. Portanto, ele terá um desempenho naturalmente mais rápido do que um modelo relacional à medida que seus dados crescerem.
Se você estiver usando qualquer uma das linguagens JVM, o Spring Data e o Spring Boot podem ser algo bastante familiar para você. Assim, você pode começar rapidamente com o NoSQL mesmo sem nenhum conhecimento prévio.
Por que Kubernetes?
O Kubernetes (K8s) permite escalonar para cima e para baixo seu aplicativo sem estado em um ambiente independente de nuvem. Nas últimas versões, o K8s também adicionou a capacidade de executar aplicativos com estado, como bancos de dados, e esse é um dos (muitos) motivos pelos quais ele é um tema tão importante atualmente.
Eu mostrei em Minha postagem anterior no blog como implantar o Couchbase no K8s e como torná-lo "elástico", aumentando e diminuindo a escala facilmente. Se você ainda não o leu, dedique alguns minutos extras à transcrição do vídeo, pois ela é uma parte importante do que falaremos aqui.
Criação de um microsserviço de perfil de usuário
Na maioria dos sistemas, o usuário (e todas as entidades relacionadas) é o dado acessado com mais frequência. Consequentemente, essa é uma das primeiras partes do sistema que precisa passar por algum tipo de otimização à medida que os dados crescem.
Adicionar uma camada de cache é o primeiro tipo de otimização que podemos pensar. No entanto, ainda não é a "solução final". As coisas podem ficar um pouco mais complicadas se você tiver milhares de usuários ou se precisar armazenar entidades relacionadas ao usuário também na memória.
O gerenciamento de grandes quantidades de perfis de usuários é uma boa opção para bancos de dados de documentos. Basta dar uma olhada no Caso de uso do Pokémon Gopor exemplo. Portanto, a criação de um serviço de perfil de usuário altamente dimensionável e elástico parece ser um desafio suficientemente bom para demonstrar como projetar um microsserviço altamente dimensionável.
O que você vai precisar:
- Couchbase
- JDK e o plug-in do Lombok para Eclipse ou Intellij
- Maven
- Um cluster do Kubernetes - estou executando este exemplo em 3 nós no AWS (não recomendo usar o minikube). Se você não sabe como configurar um, assista a este vídeo vídeo.
O Código
Você pode clonar o projeto inteiro aqui:
|
1 |
https://github.com/couchbaselabs/kubernetes-starter-kit |
Vamos começar criando nossa entidade principal chamada Usuário:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
@Documento @Data @AllArgsConstructor @NoArgsConstructor @EqualsAndHashCode público classe Usuário se estende BasicEntity { @NotNull @Id privado Cordas id; @NotNull @Campo privado Cordas nome; @Campo privado Endereço endereço; @Campo privado Lista<Preference> preferências = novo ArrayList<>(); @Campo privado Lista<String> funções de segurança = novo ArrayList<>(); } |
Nessa entidade, temos duas propriedades importantes:
- securityRoles: Todas as funções que o usuário pode desempenhar no sistema.
- preferências: Todas as possíveis preferências que o usuário possa ter, como idioma, notificações, moeda etc.
Agora, vamos brincar um pouco com nosso Repositório. Como estamos usando o Spring Data, você pode usar praticamente todos os seus recursos aqui:
|
1 2 3 4 5 |
@N1qlPrimaryIndexed @ViewIndexed(designDoc = "usuário") público interface Repositório de usuários se estende CouchbasePagingAndSortingRepository<Usuário, Cordas> { Lista<Usuário> findByName(Cordas nome); } |
Se você quiser saber mais sobre o Couchbase e o Spring Data, Confira este tutorial.
Também implementamos dois outros métodos:
|
1 2 3 4 5 6 |
@Consulta("#{#n1ql.selectEntity} where #{#n1ql.filter} and ANY preference IN " + " preferências SATISFIES preferência.nome = $1 END") Lista<Usuário> findUsersByPreferenceName(Cordas nome); @Consulta("#{#n1ql.selectEntity} where #{#n1ql.filter} and meta().id = $1 and ARRAY_CONTAINS(securityRoles, $2)") Usuário hasRole(Cordas userId, Cordas função); |
- hasRole: Verifica se um usuário tem uma função especificada:
- findUsersByPreferencyName: Como o nome diz, ele encontra todos os usuários que contêm uma determinada preferência.
Observe que estamos usando a sintaxe N1QL no código acima, pois ela torna as consultas muito mais simples do que o uso de JQL simples.
Além disso, você pode executar todos os testes para se certificar de que tudo está funcionando corretamente:
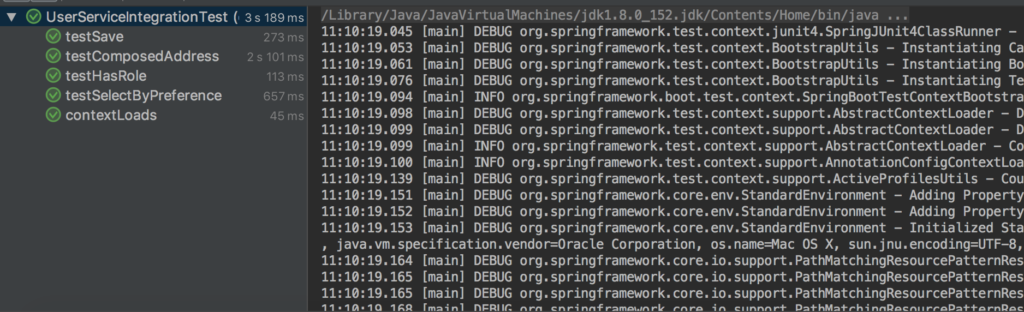
Não se esqueça de alterar seu application.properties com as credenciais corretas do seu banco de dados:
|
1 2 3 4 |
mola.couchbase.bootstrap-anfitriões=localhost mola.couchbase.balde.nome=teste mola.couchbase.balde.senha=couchbase mola.dados.couchbase.automático-índice=verdadeiro |
Para testar nosso microsserviço, adicionei alguns endpoints Restful:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
@RestController @RequestMapping("/api/user") público classe Controlador UserService { @Com fio automático privado Serviço de usuário userService; @RequestMapping(valor = "/{id}", método = OBTER, produz = VALOR_JSON_APLICATIVO) público Usuário findById(@PathParam("id") Cordas id) { retorno userService.findById(id); } @RequestMapping(valor = "/preferência", método = OBTER, produz = VALOR_JSON_APLICATIVO) público Lista<Usuário> findPreference(@RequestParam("name" (nome)) Cordas nome) { retorno userService.findUsersByPreferenceName(nome); } @RequestMapping(valor = "/find", método = OBTER, produz = VALOR_JSON_APLICATIVO) público Lista<Usuário> findUserByName(@RequestParam("name" (nome)) Cordas nome) { retorno userService.findByName(nome); } @RequestMapping(valor = "/save", método = POST, produz = VALOR_JSON_APLICATIVO) público Usuário findUserByName(@Corpo da solicitação Usuário usuário) { retorno userService.salvar(usuário); } } |
Dockerizando seu microsserviço
Primeiro, altere seu application.properties para obter as credenciais de conexão das variáveis de ambiente:
|
1 2 3 4 |
mola.couchbase.bootstrap-anfitriões=${COUCHBASE_HOST} mola.couchbase.balde.nome=${COUCHBASE_BUCKET} mola.couchbase.balde.senha=${COUCHBASE_PASSWORD} mola.dados.couchbase.automático-índice=verdadeiro |
E agora podemos criar nosso Dockerfile:
|
1 2 3 4 5 6 |
DE openjdk:8-jdk-alpino VOLUME /tmp MANTENEDOR Denis Rosa <denis.rosa@couchbase.com> ARG JAR_FILE ADD ${JAR_FILE} aplicativo.frasco PONTO DE ENTRADA ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"] |
Em seguida, criamos e publicamos nossa imagem no Docker Hub:
- Crie sua imagem:
|
1 |
./mvnw instalar arquivo de encaixe:construir -DskipTests |
- Faça login no Docker Hub a partir da linha de comando
|
1 |
doca login |

- Vamos pegar o imageId de nossa imagem criada recentemente:
1doca imagens

- Crie sua nova tag usando o imageId:
|
1 2 |
//docker tag YOUR_IMAGE_ID YOUR_USER/REPO_NAME doca etiqueta 3f9db98544bd deniswsrosa/kubernetes-inicial-kit |
- Por fim, impulsione sua imagem:
1doca empurrar deniswsrosa/kubernetes-inicial-kit
 Sua imagem agora deve estar disponível no Docker Hub:
Sua imagem agora deve estar disponível no Docker Hub:

Configuração do banco de dados
Escrevi um artigo inteiro sobre isso aquimas para ser breve. Basta executar os seguintes comandos dentro do diretório do kubernetes.
|
1 2 3 4 |
./rbac/função de cluster.sh kubectl criar -f segredo.yaml kubectl criar -f operador.yaml kubectl criar -f couchbase-agrupamento.yaml |
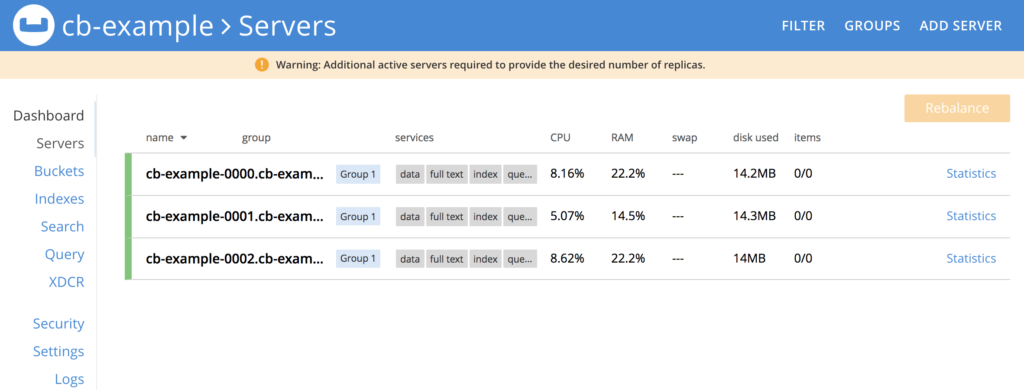
Depois de algum tempo, todas as três instâncias do nosso banco de dados deverão estar em execução:

Vamos encaminhar a porta do Console da Web para nossa máquina local:
|
1 |
kubectl porto-avançar cb-exemplo-0000 8091:8091 |
E agora podemos acessar o console da Web em http://localhost:8091. Você pode fazer login usando o nome de usuário Administrador e a senha senha
Ir para Segurança -> ADICIONAR USUÁRIO com as seguintes propriedades:
- Nome de usuário: amostra de couchbase
- Nome completo: amostra de couchbase
- Senha: amostra de couchbase
- Verificar senha: amostra de couchbase
- Funções: De acordo com a imagem abaixo:
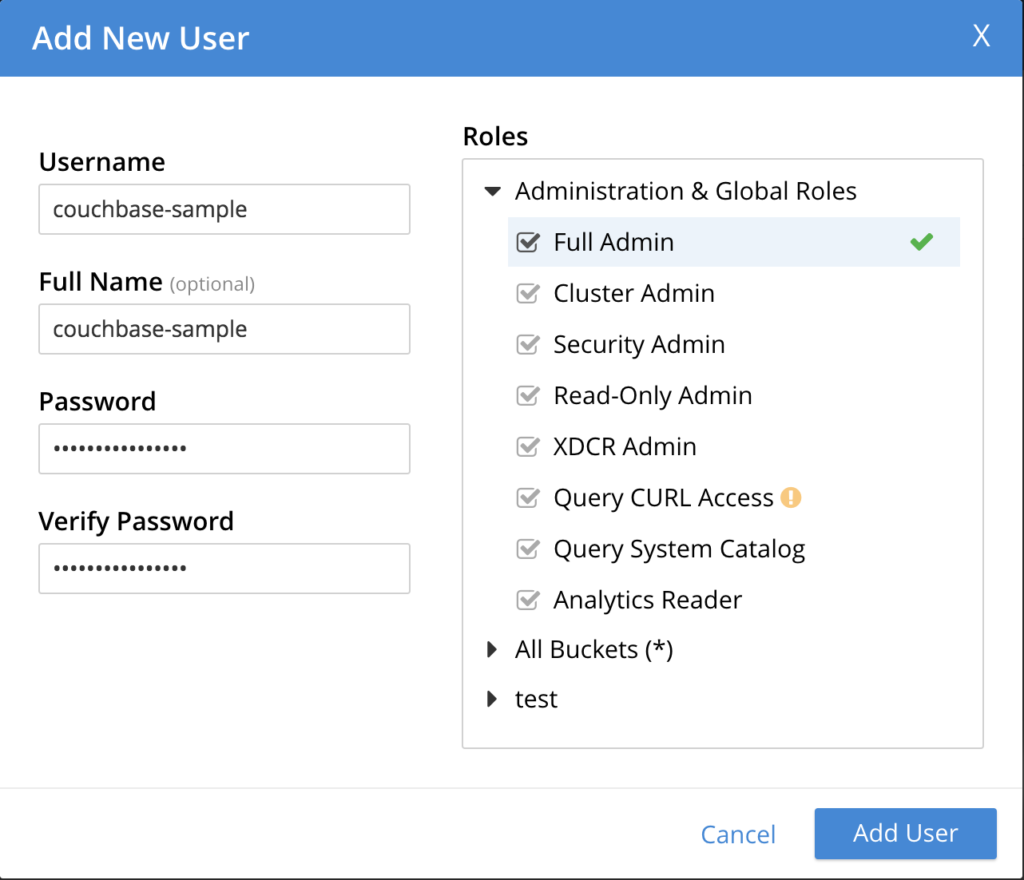
OBS: Em um ambiente de produção, não adicione seu aplicativo como administrador
Implantação de seu microsserviço
Primeiro, vamos criar um segredo do Kubernetes onde armazenaremos a senha para nos conectarmos ao nosso banco de dados:
|
1 2 3 4 5 6 7 |
Versão da API: v1 gentil: Secreto metadados: nome: mola-inicialização-aplicativo-segredo tipo: Opaco dados: bucket_password: Y291Y2hiYXNlLXNhbXBsZQ== #couchbase-sample em base64 |
Execute o seguinte comando para criar o segredo:
|
1 |
kubectl criar -f mola-inicialização-aplicativo-segredo.yaml |
O arquivo spring-boot-app.yaml é o responsável pela implantação do nosso aplicativo. Vamos dar uma olhada em seu conteúdo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
Versão da API: apps/v1beta1 gentil: Implantação metadados: nome: implantação do spring-boot especificação: seletor: matchLabels: aplicativo: spring-boot-app réplicas: 2 # diz à implementação para executar 2 pods correspondentes ao modelo modelo: # cria pods usando a definição de pod neste modelo metadados: rótulos: aplicativo: spring-boot-app especificação: contêineres: - nome: spring-boot-app imagem: deniswsrosa/kubernetes-starter-kit imagePullPolicy: Sempre portos: - containerPort: 8080 nome: servidor - containerPort: 8081 nome: gerenciamento env: - nome: COUCHBASE_PASSWORD valueFrom: secretKeyRef: nome: spring-boot-app-secret chave: bucket_password - nome: COUCHBASE_BUCKET valor: couchbase-sample - nome: COUCHBASE_HOST valor: cb-example |
Gostaria de destacar algumas partes importantes desse arquivo:
- réplicas: 2 -> O Kubernetes iniciará duas instâncias do nosso aplicativo
- imagem: deniswsrosa/kubernetes-starter-kit -> A imagem do docker que criamos anteriormente.
- contêineres: nome: -> Aqui é onde definimos o nome do contêiner que executa nosso aplicativo. Você usará esse nome no Kubernetes sempre que quiser definir quantas instâncias devem estar em execução, estratégias de escalonamento automático, balanceamento de carga etc.
- env: -> É aqui que definimos as variáveis de ambiente do nosso aplicativo. Observe que também estamos nos referindo ao segredo que criamos anteriormente.
Execute o seguinte comando para implementar nosso aplicativo:
|
1 |
kubectl criar -f mola-inicialização-aplicativo.yaml |
Em alguns segundos, você perceberá que as duas instâncias do seu aplicativo já estão em execução:
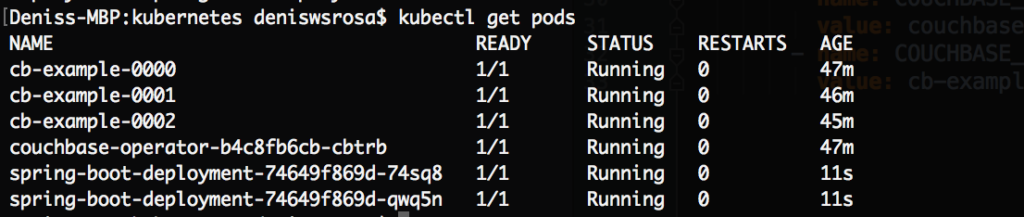
Por fim, vamos expor nosso microsserviço ao mundo externo. Há dezenas de possibilidades diferentes de como isso pode ser feito. No nosso caso, vamos simplesmente criar um balanceador de carga:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Versão da API: v1 gentil: Serviço metadados: nome: balanceador de carga de inicialização de mola especificação: portos: - porto: 8080 porta de destino: 8080 nome: http - porto: 8081 porta de destino: 8081 nome: gerenciamento seletor: aplicativo: spring-boot-app tipo: Balanceador de carga |
O seletor é uma das partes mais importantes do arquivo acima. É onde definimos os contêineres para os quais o tráfego será redirecionado. Nesse caso, estamos apenas apontando para o aplicativo que implantamos anteriormente.
Execute o seguinte comando para criar nosso balanceador de carga:
|
1 |
kubectl criar -f mola-inicialização-carregar-balanceador.yaml |
O balanceador de carga levará alguns minutos para ser ativado e redirecionar o tráfego para nossos pods. Você pode executar o seguinte comando para verificar seu status:
|
1 |
kubectl descrever serviço mola-inicialização-carregar-balanceador |
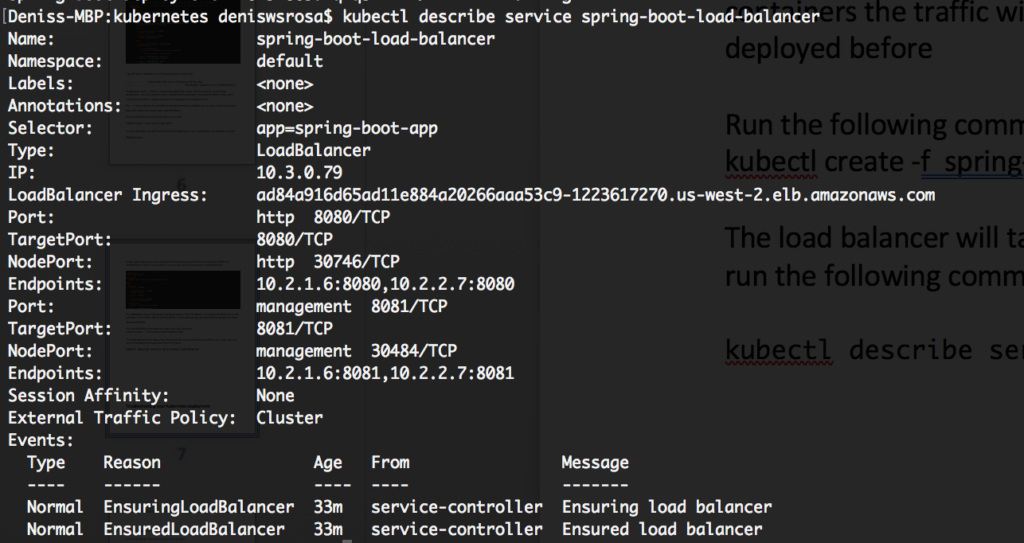
Como você pode ver na imagem acima, nosso balanceador de carga pode ser acessado em ad84a916d65ad11e884a20266aa53c9-1223617270.us-west-2.elb.amazonaws.com, e o targetPort 8080 redirecionará o tráfego para dois endpoints: 10.2.1.6:8080 e 10.2.2.7:8080
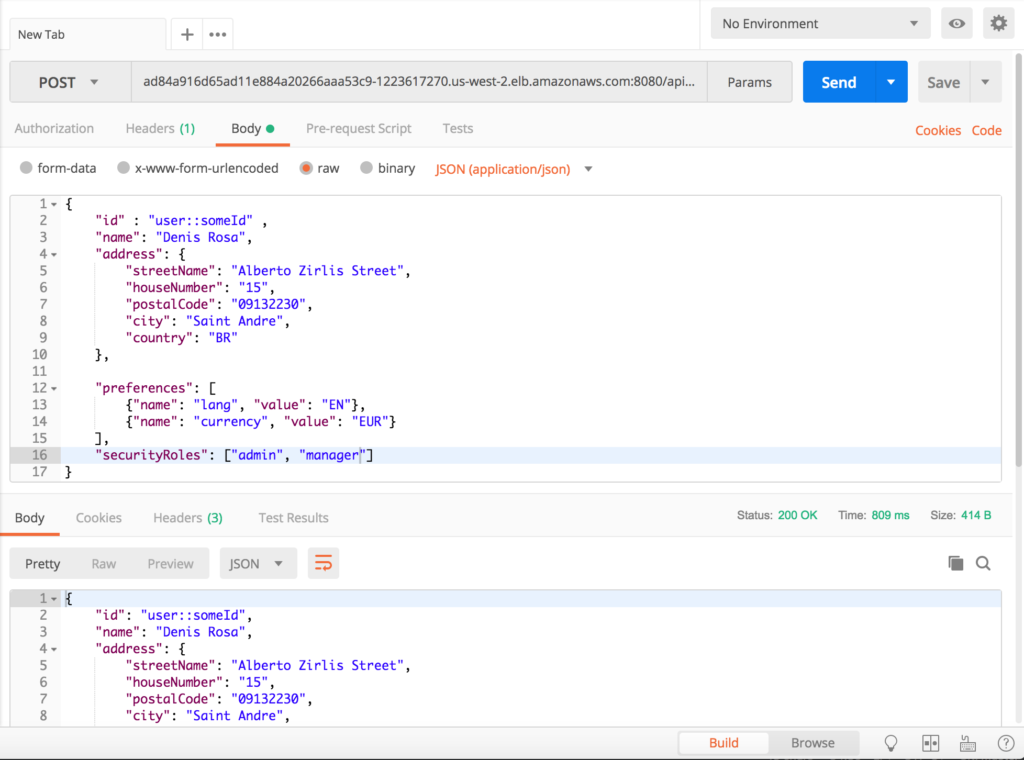
Por fim, podemos acessar nosso aplicativo e começar a enviar solicitações a ele:
- Inserção de um novo usuário:
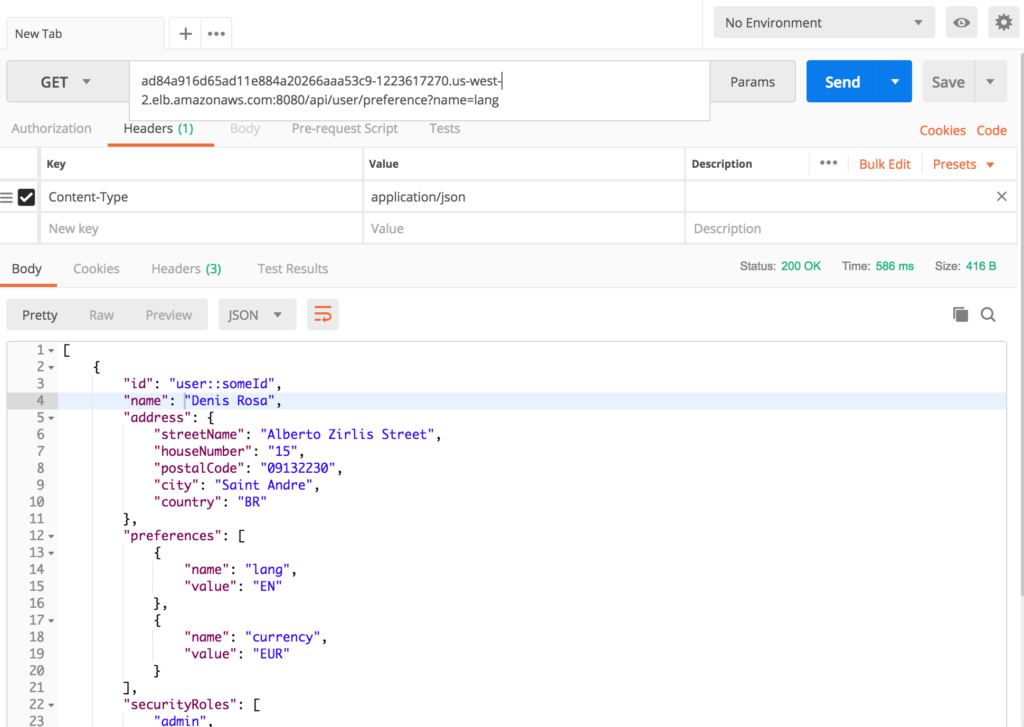
- Busca de usuários:
E quanto a ser elástico?
É aqui que as coisas ficam realmente interessantes. E se precisarmos aumentar a escala de todo o nosso microsserviço? Digamos que a Black Friday esteja chegando e que precisemos preparar nossa infraestrutura para suportar esse fluxo maciço de usuários que chegam ao nosso site. Bem, esse é um problema fácil de resolver:
- Para escalonar nosso aplicativo, basta alterar o número de réplicas no spring-boot-app.yaml arquivo.
12345678910...especificação:seletor:matchLabels:aplicativo: spring-boot-appréplicas: 6 # informa à implementação para executar 6 pods correspondentes ao modelomodelo: # cria pods usando a definição de pod neste modelometadados:rótulos:...
Em seguida, execute o seguinte comando:
|
1 |
kubectl substituir -f mola-inicialização-aplicativo.yaml |
Está faltando alguma coisa? Sim. E quanto ao nosso banco de dados? Devemos ampliá-lo também:
- Altere o atributo size no couchbase-cluster.yaml file:
|
1 2 3 4 5 6 7 8 9 |
... enableIndexReplica: falso servidores: - tamanho: 6 nome: todos_serviços serviços: - dados - índice ... |
Por fim, execute o seguinte comando:
|
1 |
kubectl substituir -f couchbase-agrupamento.yaml |
Como posso reduzir a escala?
Reduzir a escala é tão fácil quanto aumentar a escala; você só precisa alterar ambos couchbase-cluster.yaml e spring-boot-app.yaml:
- couchbase-cluster.yaml
|
1 2 3 4 5 6 7 8 9 |
... enableIndexReplica: falso servidores: - tamanho: 1 nome: todos_serviços serviços: - dados - índice ... |
- spring-boot-app.yaml:
|
1 2 3 4 5 6 7 8 9 10 |
... especificação: seletor: matchLabels: aplicativo: mola-inicialização-aplicativo réplicas: 1 modelo: metadados: rótulos: ... |
E execute os seguintes comandos:
|
1 2 |
kubectl substituir -f couchbase-agrupamento.yaml kubectl substituir -f mola-inicialização-aplicativo.yaml |
Escalonamento automático de microsserviços no Kubernetes
Vou me aprofundar nesse tópico na parte 2 deste artigo. Enquanto isso, você pode conferir este vídeo sobre dimensionamento automático de pods.
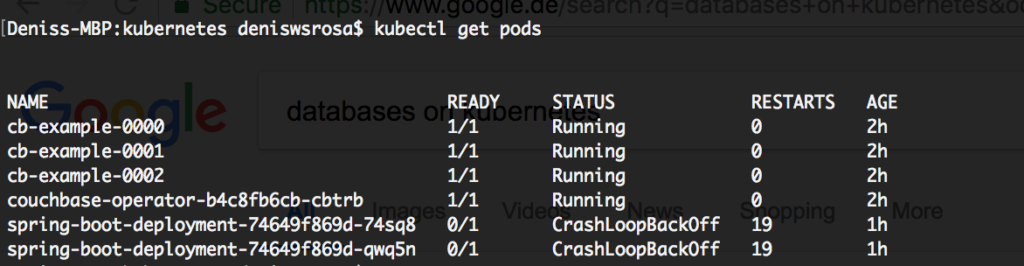
Solução de problemas de sua implantação do Kubernetes
Se seus pods não conseguirem iniciar, há muitas maneiras de solucionar o problema. No caso abaixo, ambos os aplicativos não conseguiram iniciar:
Como eles fazem parte da implantação, vamos descrever a implantação para tentar entender o que está acontecendo:
|
1 |
kubectl descrever implantação mola-inicialização-implantação |
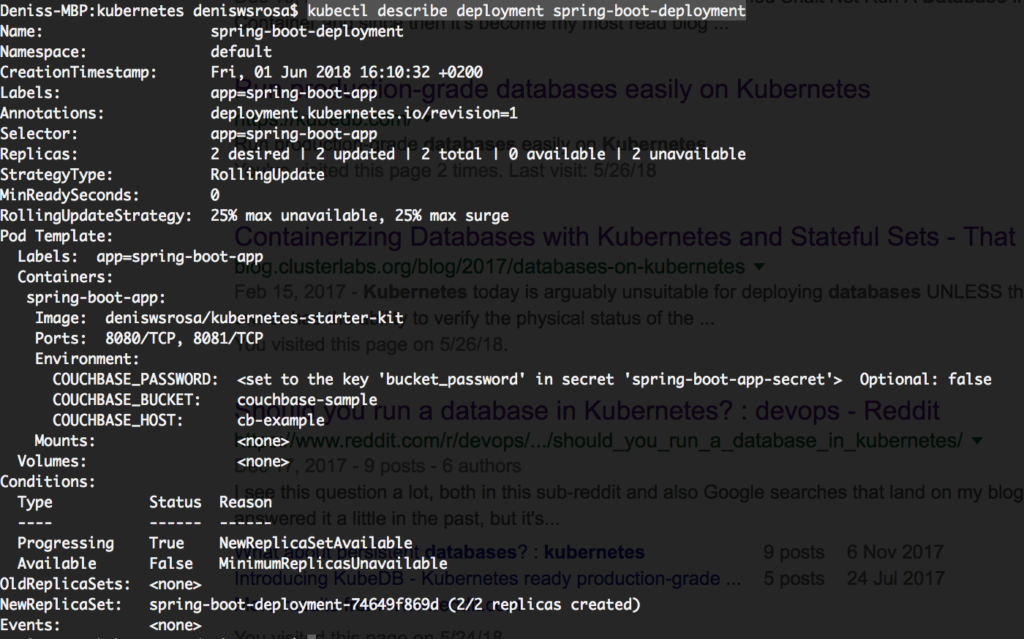
Bem, nada é realmente relevante nesse caso. Então, vamos dar uma olhada em um dos registros do pod:
|
1 |
kubectl registro mola-inicialização-implantação-74649f869d-74sq8 |
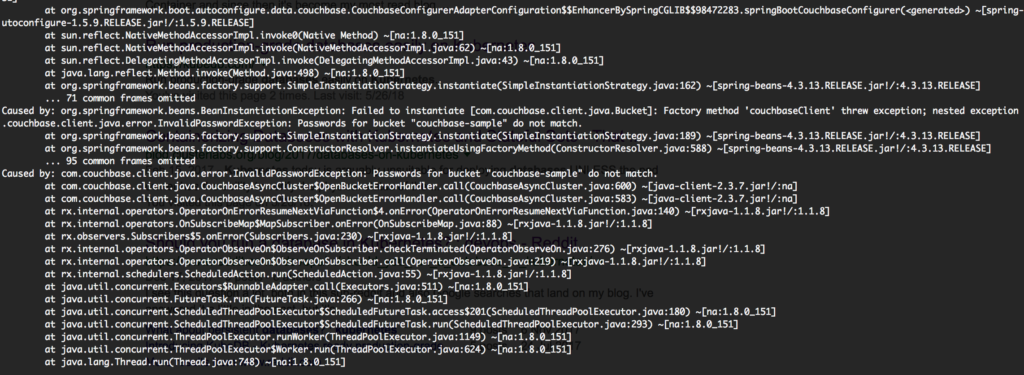
Entendi! O aplicativo não foi iniciado porque esquecemos de criar o usuário no Couchbase. Basta criar o usuário para que os pods sejam ativados em alguns segundos:
Conclusão
Os bancos de dados são aplicativos com estado, e dimensioná-los não é tão rápido quanto dimensionar aplicativos sem estado (e provavelmente nunca será), mas se você precisar criar uma arquitetura realmente elástica, deverá planejar o dimensionamento de todos os componentes da sua infraestrutura. Caso contrário, você estará apenas criando um gargalo em outro lugar.
Neste artigo, tentei mostrar apenas uma pequena introdução sobre como você pode tornar elásticos seu aplicativo e seu banco de dados no Kubernetes. No entanto, essa ainda não é uma arquitetura pronta para produção. Ainda há muitos outros aspectos a serem considerados, e abordarei alguns deles nos próximos artigos.
Enquanto isso, se você tiver alguma dúvida, envie-me um tweet para @deniswsrosa ou deixe um comentário abaixo.