Se eu perguntasse a cinco pessoas diferentes Se eu perguntar às pessoas o que é "computação de borda", certamente receberei cinco respostas diferentes. O mais confuso é que provavelmente todas elas estariam certas.
A computação de borda é uma arquitetura estratégica que está crescendo em popularidade, mas suas diferentes permutações e sua miríade de casos de uso dificultam sua definição.
A computação de borda é móvel? ou IoT? ou ambientes inteligentes? É na nuvem? ou no local? ou no dispositivo? É sobre computação? ou rede? ou 5G? Ela se aplica a robôs em uma fábrica? ou monitores em uma sala de cirurgia? ou carros sem motorista?
A computação de borda é tudo isso e muito mais.
Neste artigo, apresentarei os conceitos essenciais da computação de borda e o que você precisa para criar com sucesso sua própria arquitetura de borda. Mas (alerta de spoiler!) aproveitar os benefícios da computação de borda se resume basicamente a uma coisa: dados - onde e como você os processa e como você os envia para a borda e a partir dela.
Primeiro, vamos definir computação de borda.
O que é a arquitetura de computação de borda?
Wikipédia descreve a computação de borda como:
A computação de borda é um paradigma de computação distribuída que aproxima a computação e o armazenamento de dados das fontes de dados. Espera-se que isso melhore os tempos de resposta e economize largura de banda. O termo refere-se a uma arquitetura e não a uma tecnologia específica.
A computação de borda consiste em armazenar e processar dados mais próximos dos usuários e aplicativos que os consomem. No final, ela reduz a latência e protege contra interrupções na Internet. As arquiteturas de computação de borda prometem impulsionar inovações como
-
- Casas conectadas
- Veículos autônomos
- Cirurgia robótica
- Jogos avançados em tempo real
A computação de borda é uma arquitetura alternativa à computação em nuvem para aplicativos que exigem alta velocidade e alta disponibilidade. Isso ocorre porque os aplicativos que dependem exclusivamente da nuvem para armazenar e processar dados tornam-se dependentes da conectividade com a Internet e, portanto, sujeitos à sua falta de confiabilidade inerente. Quando a Internet fica lenta ou indisponível, o aplicativo inteiro fica lento ou falha.
A computação de borda contorna as dependências da Internet localizando os dados o mais próximo possível de onde eles são produzidos e consumidos, o que acelera os aplicativos e melhora sua disponibilidade.
Um exemplo real de computação de borda
Vamos dar uma olhada em um exemplo concreto.
Imagine uma plataforma de perfuração de petróleo no meio do Mar do Norte. Os operadores coletam dados de sensores em toda a plataforma como parte de uma rotina diária, medindo coisas como pressão, temperatura, altura das ondas e outros fatores que afetam a capacidade operacional. Esse tipo de dado chega rapidamente, muda com frequência e exige uma resposta em tempo real.
Suponha que os dados da plataforma de petróleo sejam armazenados e processados em um data center em nuvem. Os operadores da plataforma teriam que enviar seus dados pela Internet - e no Mar do Norte isso significa via satélite, o que é lento e caro - apenas para avaliar suas medições.
Agora, imagine que um sensor em um componente crítico da plataforma comece a detectar sinais de uma provável falha, uma possível interrupção que poderia levar a uma perigosa reviravolta nos eventos. Leva muito tempo para coletar pontos de dados sobre o componente, enviá-los para a nuvem para processamento e, em seguida, aguardar um curso de ação recomendado. E se a conexão ficar lenta ou falhar, mesmo que seja só um pouquinho? O tempo crítico é perdido. Quando os operadores da plataforma receberem uma resposta da nuvem, poderá ser tarde demais.
Quando os segundos contam e quando a diferença entre tempo de atividade e tempo de inatividade determina a segurança ou o desastre, depender de uma conexão de Internet não confiável não é uma opção.
Entre na computação de borda. É uma solução simples: elimine os riscos de um desastre colocando um data center na própria plataforma de perfuração de petróleo. Quando você transfere o processamento de dados críticos para o local onde isso aconteceVocê resolve os problemas de latência e tempo de inatividade. Em vez de enviar dados para a nuvem, eles são processados em um data center de borda - não há mais espera em uma conexão lenta para análise crítica.
Com um data center de borda, quando as medições ou leituras precisam de atenção imediata, elas são detectadas instantaneamente e os operadores podem responder em tempo real. As operações são mais eficientes e os riscos à segurança são significativamente reduzidos. E quando a conectividade permite, apenas os dados agregados precisam ser enviados para a nuvem para armazenamento de longo prazo, economizando nos custos de largura de banda.
Esse é o poder e a promessa da computação de borda.
Visualização de uma arquitetura de computação de borda
A computação de borda aproxima o processamento e o armazenamento de dados dos aplicativos e dos dispositivos clientes, aproveitando os data centers de borda em camadas, juntamente com o armazenamento de dados incorporado diretamente nos dispositivos, quando apropriado.
Essa abordagem em camadas isola os aplicativos das interrupções dos data centers centrais e regionais. Cada camada aproveita cada vez mais a conectividade local - que é mais confiável - e sincroniza os dados dentro e entre as camadas, conforme a conectividade permite. A computação de borda é como você alimenta aplicativos sempre rápidos e sempre ativos.
Gosto de visualizar as arquiteturas de borda como um conjunto de camadas, o que facilita a compreensão do conceito. Dê uma olhada no diagrama abaixo:
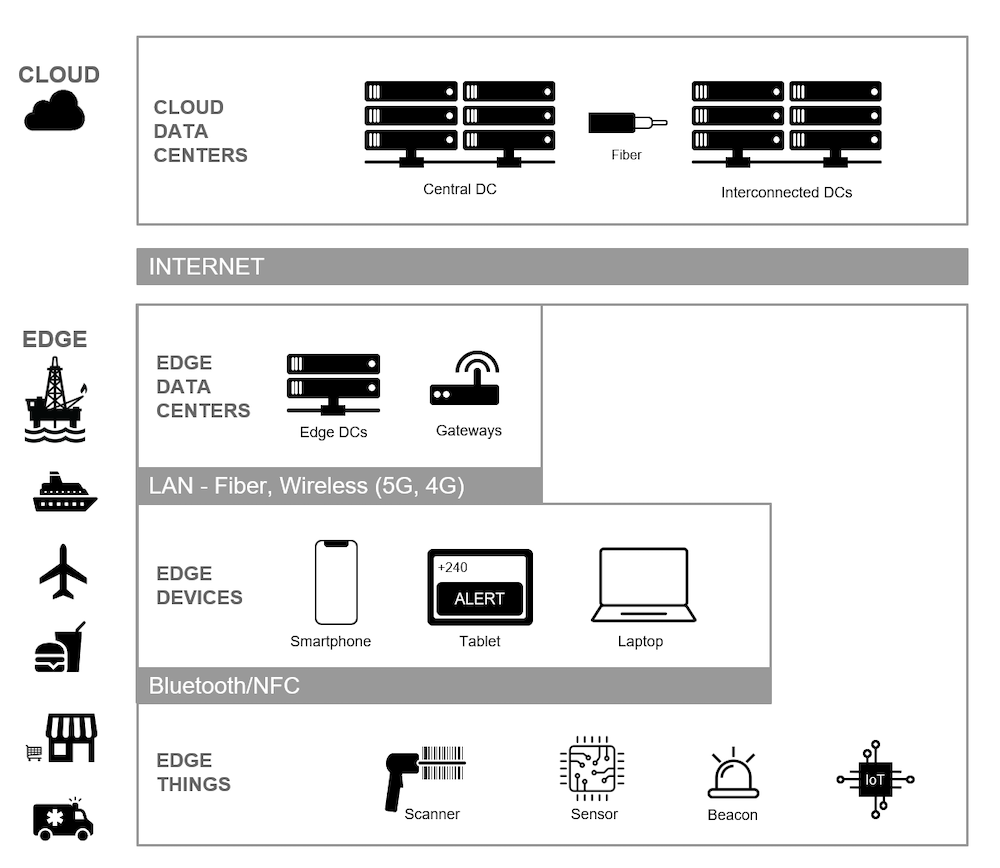
No diagrama acima, a camada superior representa os data centers em nuvem, compostos por um data center central e data centers regionais interconectados. Os data centers em nuvem ainda desempenham uma função crucial em uma arquitetura de computação de borda porque são o repositório final de informações. Entretanto, os data centers em nuvem não são usados para aplicativos locais.
A próxima camada abaixo é a camada de borda. A borda pode ser uma plataforma de petróleo, como em nosso exemplo anterior, mas também pode ser um navio de cruzeiro, um avião, um restaurante, uma loja de varejo ou uma clínica médica móvel. A camada de borda contém data centers de borda e gateways de Internet das Coisas (IoT). Eles são executados em uma rede de área local, que pode ser de fibra, sem fio, 5G ou redes mais antigas, como 4G e anteriores.
Na camada de borda, você vê dispositivos individuais, smartphones, tablets e laptops carregados pelos usuários, bem como dispositivos de IoT que se comunicam com o data center de borda. Também há comunicação entre dispositivos por meio de uma rede de área privada, como RF ou Bluetooth.
Embora essa representação mostre um único data center de borda para simplificar, pode haver n número de data centers de borda adicionais para facilitar a computação em um ecossistema de negócios. Por exemplo, você pode alimentar sistemas de PDV para uma cadeia de lojas de varejo usando data centers de borda em cada cidade onde as lojas estão concentradas.
Computação de borda e bancos de dados
Todas as arquiteturas de computação de borda têm um requisito importante: usar o direito tipo de banco de dados. Se estiver criando uma arquitetura de borda, precisará usar um banco de dados que:
-
- Funciona em todas as camadas
- Distribui sua pegada de dados em todas as camadas
- Sincroniza instantaneamente as alterações de dados em todas as camadas
Em essência, você precisa criar uma estrutura síncrona de processamento de dados que abranja toda a arquitetura: da nuvem à borda e ao dispositivo. Vamos dar uma olhada mais de perto em nosso diagrama de arquitetura anterior:
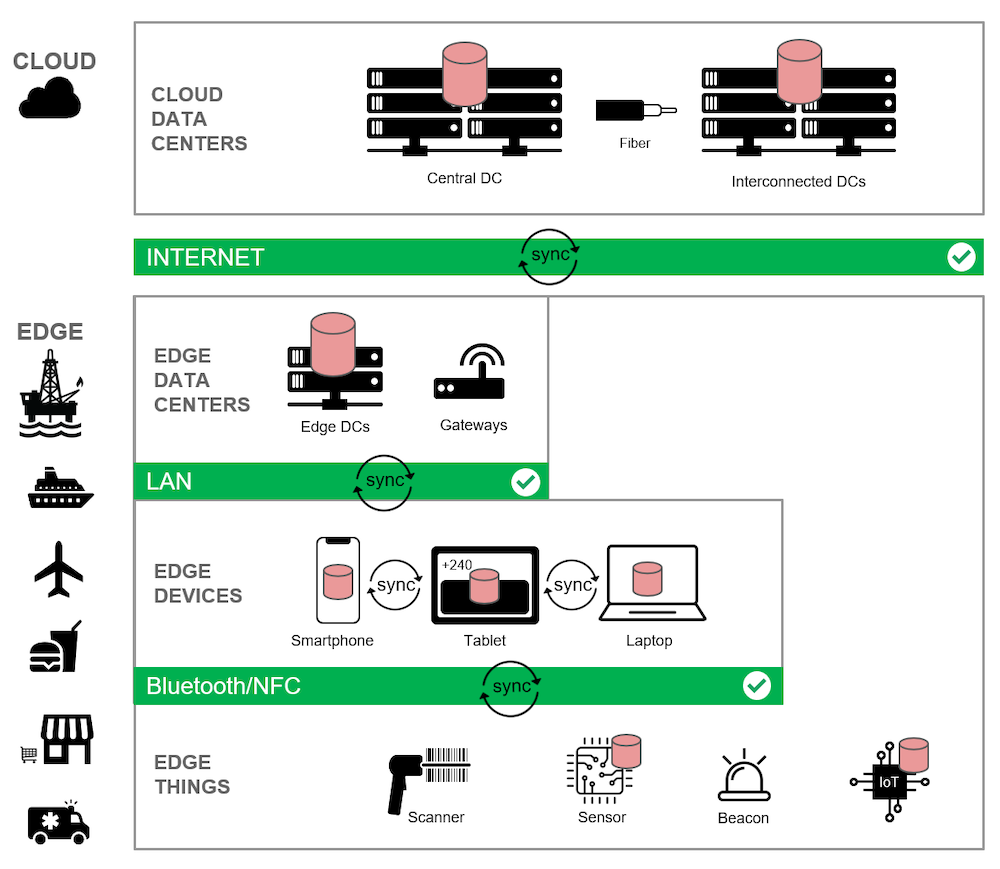
Nesta versão da arquitetura de computação de borda, adicionei ícones vermelhos de banco de dados para enfatizar onde os dados são armazenados e processados.
Na camada de nuvem, você vê um servidor de banco de dados instalado no data center central, bem como os data centers interconectados nas regiões de nuvem.
Em seguida, na camada de borda, um servidor de banco de dados é instalado no data center de borda.
Por fim, um banco de dados é incorporado diretamente a dispositivos móveis e de IoT de ponta selecionados, permitindo que eles continuem processando, mesmo em caso de falha total da rede.
Mas a computação de borda é muito mais do que simplesmente instalar um banco de dados em todos os níveis. Os bancos de dados deve ser capaz de trabalhar em conjunto como um todo coeso, replicando e sincronizando os dados capturados na borda em todo o restante do ambiente para garantir que os dados estejam sempre disponíveis e nunca sejam perdidos ou corrompidos.
Dessa forma, no diagrama, você também vê os dados sendo sincronizados:
-
- Entre servidores de banco de dados na nuvem e na borda
- Entre bancos de dados incorporados em dispositivos e servidores de banco de dados na borda ou na nuvem
- Entre os bancos de dados incorporados em dispositivos e coisas, usando redes de área privada
Ao distribuir o processamento de dados em todas as camadas da sua arquitetura, você obtém maior velocidade, resiliência, segurança e eficiência de largura de banda.
Se a conexão de Internet com o data center na nuvem ficar lenta ou parar, os aplicativos processarão os dados nos data centers de borda, sem serem afetados e com alta capacidade de resposta. E se o data center na nuvem e Se o centro de dados de borda se tornar indisponível, os aplicativos com bancos de dados incorporados continuarão a ser executados como pretendido - e em tempo real - processando e sincronizando dados diretamente nos dispositivos e entre eles. E se o catastrófico acontecer e todos as camadas de rede ficarem indisponíveis, os dispositivos de borda com processamento de dados incorporado funcionam como seus próprios microcentros de dados, executados isoladamente com disponibilidade de 100% e capacidade de resposta em tempo real até que a conectividade seja restaurada.
Outro grande benefício do modelo de computação de borda é o suporte robusto à privacidade e à segurança dos dados. Essas considerações são essenciais para aplicativos que lidam com dados confidenciais, como na área de saúde ou finanças. Um ponto de valor importante para a computação de borda é que os dados confidenciais nunca precisam sair da borda.
Com uma arquitetura de computação de borda, os usuários e dispositivos sempre têm acesso rápido aos dados, mesmo em caso de latência ou interrupção da Internet. E seu banco de dados desempenha um papel fundamental para que tudo isso aconteça.
Como criar sua própria arquitetura de computação de borda
Então, como criar sua própria arquitetura de computação de borda?
Você precisa considerar dois aspectos: infraestrutura e processamento de dados. Ambos são tópicos aprofundados, mas vou abordar brevemente cada um deles.
Infraestrutura de computação de borda
Nos primeiros dias da computação de borda, os arquitetos tinham que construir tudo do zero.
Eles tiveram que criar sua própria infraestrutura estendida além da nuvem e tiveram que considerar onde essa infraestrutura ficaria: no local? em uma nuvem privada? co-localizada? em contêineres? Tiveram que considerar as implicações da coexistência de uma infraestrutura personalizada com nuvens públicas.
Se eles construíssem um data center de borda em um local, como poderiam conectá-lo à nuvem para armazenamento centralizado e estendê-lo a outros locais conforme necessário? E como poderiam garantir a padronização e a consistência dos componentes arquitetônicos entre os locais, bem como a redundância e a alta disponibilidade? Esses tipos de perguntas tornaram o estabelecimento de uma infraestrutura de computação de borda um empreendimento complexo em sua infância.
Felizmente, essa complexidade está desaparecendo.
Muitos dos principais provedores de serviços em nuvem agora oferecem serviços de computação de borda. Por exemplo, A AWS lançou um conjunto abrangente de serviços que facilitam a computação de borda para uma variedade de casos de uso. Essencialmente, elas estendem sua infraestrutura de nuvem para a borda e permitem que os data centers sejam configurados localmente em cidades específicas, no local e/ou em redes 5G.
Serviços como esses, da AWS e de outros provedores de serviços em nuvem, trazem mais opções, flexibilidade e simplicidade para iniciativas de computação de borda. Por sua vez, esses serviços permitem que sua organização comece rapidamente, aproveitando a infraestrutura sob demanda, e evolua com eficiência, mantendo um ambiente padronizado e repetível.
Processamento de dados na borda
Como afirmei anteriormente, você não pode esperar instalar qualquer banco de dados antigo para a computação de borda e alcançar o sucesso. É importante escolher um banco de dados com os recursos e as funcionalidades certas.
Em uma arquitetura distribuída que abrange desde a nuvem até a borda, você deve facilitar o processamento de dados em todas as camadas do seu ecossistema. Todas as camadas precisam compartilhar uma compreensão em tempo real dos dados, e qualquer camada deve ser capaz de ser executada isoladamente em caso de perda de conectividade.
Isso significa que você precisa de um banco de dados que distribua nativamente o armazenamento e a carga de trabalho entre as várias camadas de uma arquitetura de borda. Seu banco de dados também deve ter a capacidade de replicar e sincronizar instantaneamente os dados entre as instâncias do banco de dados, estejam elas na nuvem ou em um data center de borda.
Além disso, seu banco de dados precisa ser incorporável. O armazenamento de dados deve ser integrado diretamente ao dispositivo de borda para facilitar o processamento de dados quando estiver completamente off-line. Dessa forma, o banco de dados incorporado deve ser capaz de operar sem nenhum ponto de controle central na nuvem e deve sincronizar-se automaticamente com o restante do ecossistema de dados quando a conectividade retornar.
Além disso, a sincronização deve ser bidirecional e controlável para fornecer um fluxo seguro e ideal de dados em toda a arquitetura de borda. Por exemplo, em um cenário de fábrica inteligente, os dados de alta velocidade capturados de uma linha de montagem podem ser processados e analisados na borda, mas - para eficiência da largura de banda da rede - somente os dados agregados são sincronizados com a nuvem para armazenamento final.
Ao planejar suas próprias iniciativas de computação de borda, você só deve considerar um banco de dados que atenda a todos os requisitos de processamento de dados acima.
Construa com ousadia no limite
Uma arquitetura de computação de borda garante baixa latência e resiliência aos problemas da Internet. Ao processar os dados mais perto de onde eles acontecem, a computação de borda torna os aplicativos mais rápidos e, consequentemente, mais confiáveis.
Essa abordagem direta alimentará uma nova classe de aplicativos modernos e inovações futuras. A chave para obter sucesso com arquiteturas de computação de borda é aproveitar um banco de dados pronto para a borda.
Saiba mais sobre a computação de borda e os serviços de borda neste relatório da IDC: "Responsabilidade de desempenho e tomada de decisões de ponta com o Couchbase." O relatório abrange o cenário emergente de serviços de borda e destaca os resultados do teste de benchmark de latência do Couchbase em zonas de serviço de borda da AWS e da Verizon.
Obtenha o relatório aqui

[...] Uma introdução às arquiteturas de computação de borda (Mark Gamble) [...]