Prólogo
Espera-se que os aplicativos empresariais modernos estejam ativos 24 horas por dia, 7 dias por semana, mesmo durante a implementação planejada de novos recursos e a aplicação periódica de patches no sistema operacional ou no aplicativo. Para conseguir esse feito, são necessárias ferramentas e tecnologias que garantam a velocidade do desenvolvimento, a estabilidade da infraestrutura e a capacidade de dimensionamento.
As ferramentas de orquestração de contêineres, como o Kubernetes, estão revolucionando a maneira como os aplicativos estão sendo desenvolvidos e implantados atualmente, abstraindo as máquinas físicas que gerenciam. Com o Kubernetes, você pode descrever a quantidade de memória e a capacidade de computação que deseja e disponibilizá-las sem se preocupar com a infraestrutura subjacente.
Os pods (unidade de recurso de computação) e os contêineres (onde os aplicativos são executados) em um ambiente Kubernetes podem se recuperar automaticamente em caso de qualquer tipo de falha. Eles são, em essência, efêmeros. Isso funciona muito bem quando você tem um microsserviço sem estado, mas os aplicativos que exigem que seu estado seja mantido, por exemplo, sistemas de gerenciamento de banco de dados como o Couchbase, precisam ser capazes de externalizar o armazenamento do gerenciamento do ciclo de vida de pods e contêineres para que os dados possam ser recuperados rapidamente simplesmente remontando os volumes de armazenamento em um pod recém-eleito.
Isso é o que Volumes persistentes permite implementações baseadas em Kubernetes. Operador autônomo do Couchbase é um dos primeiros a adotar essa tecnologia para tornar a recuperação de qualquer falha baseada em infraestrutura perfeita e, principalmente, mais rápida.
Neste artigo, veremos passo a passo como você pode implantar o cluster do Couchbase no Amazon Elastic Container Service for Kubernetes (Amazon EKS): 1) usando vários grupos de servidores do Couchbase que podem ser mapeados para uma zona de disponibilidade separada para alta disponibilidade 2) aproveitando volumes persistentes para recuperação rápida de falhas na infraestrutura.
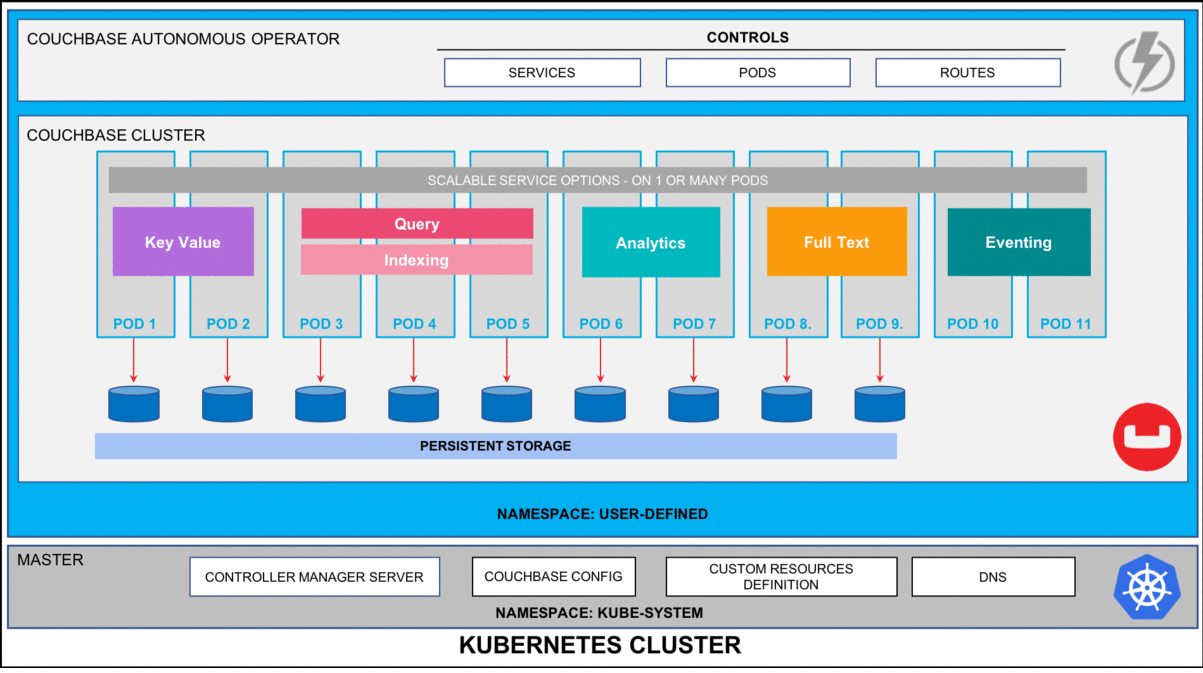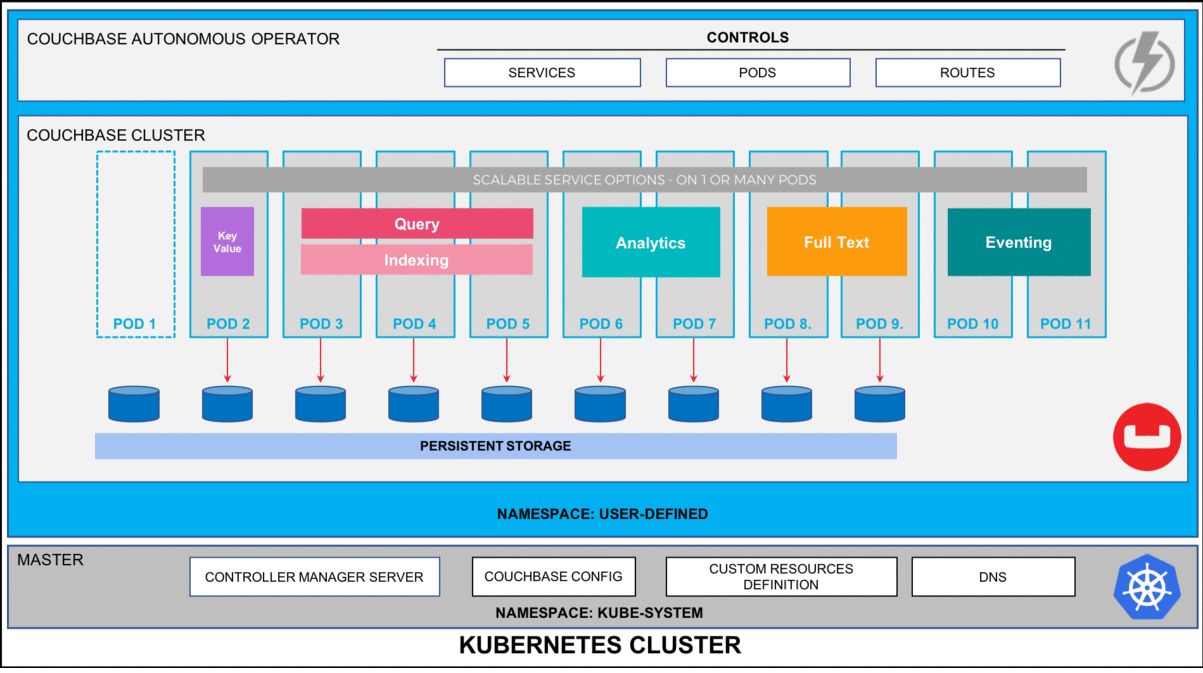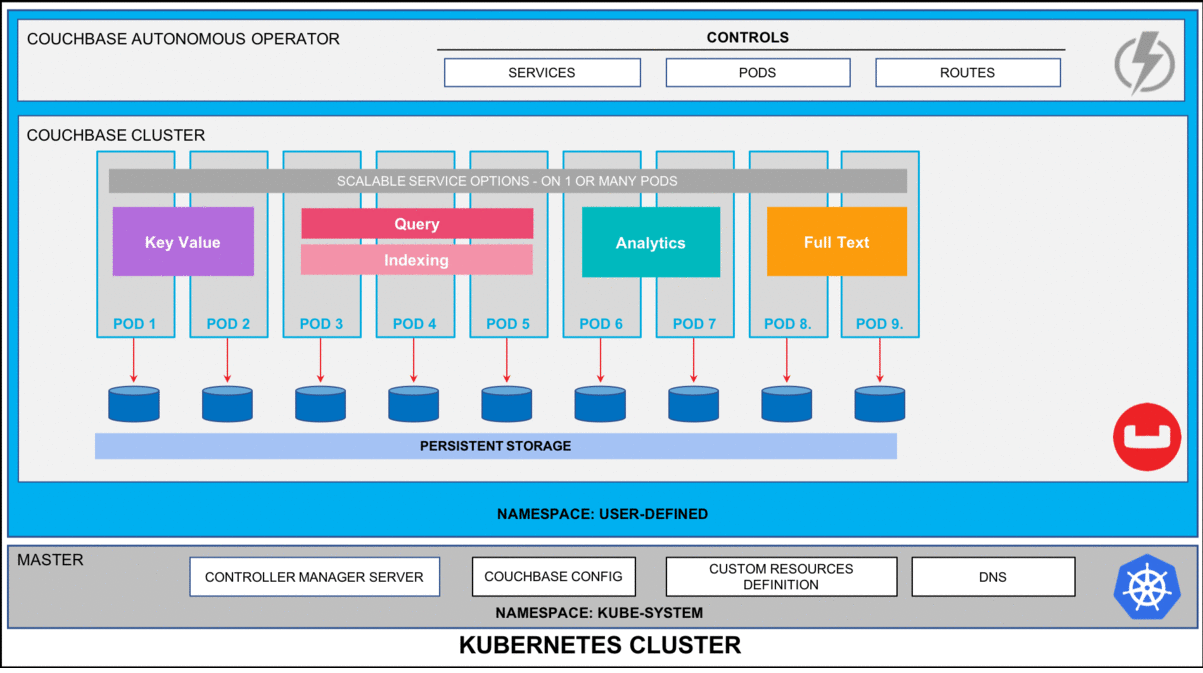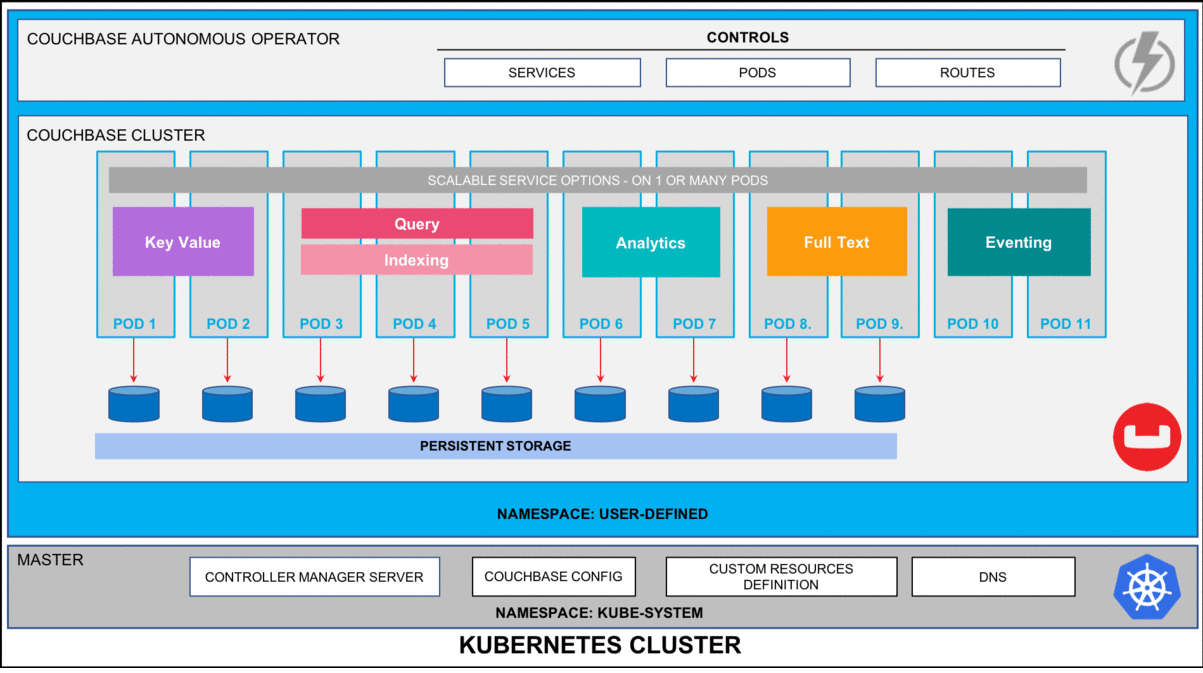
Figura 1: Operador autônomo do Couchbase para Kubernetes monitora e cura automaticamente a plataforma de banco de dados do Couchbase.
1. Pré-requisitos
Há três pré-requisitos de alto nível antes de começarmos a implementação do Couchbase Autonomous Operator no EKS:
- Você tem kubectl instalado em nosso computador local.
- Mais recentes CLI DO AWS está configurado para que possamos estabelecer com segurança um canal entre nossa máquina local e o plano de controle do Kubernetes em execução no AWS.
- Amazon Grupo EKS é implantado com pelo menos três nós de trabalho em três zonas de disponibilidade separadas para que possamos implantar e gerenciar nosso cluster do Couchbase posteriormente. Usaremos us-east-1 como região e us-east-1a/1b/1c como três zonas de disponibilidade, mas você pode implementar em qualquer região/zona fazendo pequenas alterações nos arquivos YAML nos exemplos abaixo.
2. Implantar o operador autônomo do Couchbase
Antes de iniciarmos a configuração do Couchbase Operator, execute o comando "kubectl get nodes" no computador local para confirmar se o cluster EKS está funcionando.
|
1 2 3 4 5 6 |
$ kubectl obter nós NOME STATUS PAPÉIS IDADE VERSÃO ip-192-168-106-132.ec2.internal Pronto <nenhum> 110m v1.11.9 ip-192-168-153-241.ec2.internal Pronto <nenhum> 110m v1.11.9 ip-192-168-218-112.ec2.internal Pronto <nenhum> 110m v1.11.9 |
Depois de testarmos que podemos nos conectar ao plano de controle do Kubernetes em execução no cluster do Amazon EKS a partir de nossa máquina local, podemos agora começar com as etapas necessárias para implantar o Couchbase Autonomous Operator, que é a tecnologia de cola que permite que o cluster do Couchbase Server seja gerenciado pelo Kubernetes.
2.1. Download do pacote Operator
Vamos começar fazendo o download da versão mais recente do Operador autônomo do Couchbase e descompacte-o na máquina local. Altere o diretório para a pasta do operador para que possamos encontrar os arquivos YAML necessários para implantar o operador do Couchbase:
|
1 2 3 4 5 6 7 8 |
$ cd couchbase-autônomo-operador-kubernetes_1.2.0-981_linux-x86_64 $ ls Licença.txt couchbase-cli-criar-usuário.yaml operador-função-vinculação.yaml segredo.yaml LEIAME.txt couchbase-agrupamento.yaml operador-função.yaml admissão.yaml crd.yaml operador-serviço-conta.yaml caixa operador-implantação.yaml briga de travesseiros-dados-carregador.yaml |
2.2. Criar um espaço de nome
Crie um namespace que permita que os recursos do cluster sejam bem separados entre vários usuários. Para fazer isso, usaremos um namespace exclusivo chamado emart para nossa implantação e, posteriormente, usaremos esse namespace para implantar o cluster do Couchbase.
Em seu diretório de trabalho, crie um arquivo namespace.yaml com esse conteúdo e salve-o no próprio diretório do operador do Couchbase:
|
1 2 3 4 |
Versão da API: v1 gentil: Namespace metadados: nome: emart |
Depois de salvar a configuração do namespace em um arquivo, execute kubectl cmd para criá-lo:
|
1 |
$ kubectl criar -f espaço de nome.yaml |
Execute o comando get namespace para confirmar que ele foi criado com sucesso:
|
1 2 3 4 5 6 7 |
$ kubectl obter Espaços de nomes saída: NOME STATUS IDADE padrão Ativo 1h emart Ativo 12s |
A partir de agora, usaremos o emart como namespace para todo o provisionamento de recursos.
2.3. Adicionar certificado TLS
Criar segredo para o Couchbase Operator e servidores com um determinado certificado. Veja como criar um certificado personalizado se não tiver uma.
|
1 2 3 |
$ kubectl criar segredo genérico couchbase-servidor-tls --de-arquivo cadeia.pem --de-arquivo chave.chave --espaço de nome emart segredo/couchbase-servidor-tls criado |
|
1 2 3 |
$ kubectl criar segredo genérico couchbase-operador-tls --de-arquivo pki/ca.crt --espaço de nome emart segredo/couchbase-operador-tls criado |
2.4. Instalar o controlador de admissão
O controlador de admissão é um componente necessário do Couchbase Autonomous Operator e precisa ser instalado separadamente. O objetivo principal do controlador de admissão é validar as alterações de configuração do cluster do Couchbase antes que o Operador atue sobre elas, protegendo assim sua implementação do Couchbase (e o Operador) de qualquer dano acidental que possa surgir de uma configuração inválida. Para obter detalhes sobre a arquitetura, visite a página de documentação no site Controlador de Admissão
Siga as etapas a seguir para implementar o controlador de admissão:
- No diretório do operador do Couchbase, execute o seguinte comando para criar o controlador de admissão:
|
1 |
$ kubectl criar -f admissão.yaml --espaço de nome emart |
- Confirme se o controlador de admissão foi implantado com êxito:
|
1 2 3 4 |
$ kubectl obter implantações --espaço de nome emart NOME DESEJADO ATUAL UP-PARA-DATA DISPONÍVEL IDADE couchbase-operador-admissão 1 1 1 1 1m |
2.5. Instalar o CRD
A primeira etapa da instalação do Operator é instalar a definição de recurso personalizado (CRD) que descreve o tipo de recurso CouchbaseCluster. Isso pode ser feito com o seguinte comando:
|
1 |
kubectl criar -f crd.yaml --espaço de nome emart |
2.6. Criar uma função de operador
Em seguida, criaremos um arquivo função de cluster que permite que o Operador acesse os recursos necessários para sua execução. Como o Operador gerenciará muitos Espaços de nomesSe você não tiver uma função de cluster, é melhor criar uma função de cluster primeiro, pois você pode atribuir essa função a um conta de serviço em qualquer namespace.
Para criar a função de cluster para o Operator, execute o seguinte comando:
|
1 |
$ kubectl criar -f operador-função.yaml --espaço de nome emart |
Essa função de cluster só precisa ser criada uma vez.
2.7. Criar uma conta de serviço
Depois que a função de cluster for criada, você precisará criar uma conta de serviço no namespace em que está instalando o Operator. Para criar a conta de serviço:
|
1 |
$ kubectl criar conta de serviço couchbase-operador --espaço de nome emart |
Agora, atribua a função de operador à conta de serviço:
|
1 2 3 4 5 6 |
$ kubectl criar vinculação de função couchbase-operador --função couchbase-operador \ --conta de serviço emart:couchbase-operador --espaço de nome emart saída: aglutinação de papéis.rbac.autorização.k8s.io/couchbase-operador criado |
Agora, antes de prosseguirmos, vamos nos certificar de que todas as funções e contas de serviço sejam criadas no namespace emart. Para isso, execute estas três verificações e certifique-se de que cada uma delas retorne algo:
|
1 2 3 |
Kubectl obter funções -n emart Kubectl obter vínculos de função -n emart Kubectl obter sa -n emart |
2.8. Implantar o Couchbase Operator
Agora temos todas as funções e privilégios para que nosso operador seja implementado. A implantação do operador é tão simples quanto executar o arquivo operator.yaml no diretório do Couchbase Autonomous Operator.
|
1 2 3 4 5 |
$ kubectl criar -f operador-implantação.yaml --espaço de nome emart saída: implantação.aplicativos/couchbase-operador criado |
O comando acima fará o download da imagem do Docker do Operator (especificada no arquivo operator.yaml) e criará uma implantação, que gerencia uma única instância do Operator. O Operator usa uma implantação para que possa reiniciar se o pod em que está sendo executado morrer.
Levaria menos de um minuto para o Kubernetes implantar o Operator e para que ele estivesse pronto para ser executado.
a) Verificar o status da implantação
Você pode usar o seguinte comando para verificar o status da implantação:
|
1 |
$ kubectl obter implantações --espaço de nome emart |
Se você executar esse comando imediatamente após a implantação do Operator, o resultado será parecido com o seguinte:
|
1 2 |
NOME DESEJADO ATUAL UP-PARA-DATA DISPONÍVEL IDADE couchbase-operador 1 1 1 0 10s |
Observação: a saída acima significa que o operador do Couchbase está implantado e você pode prosseguir com a implantação do cluster do Couchbase.
b) Verificar o status do operador
Você pode usar o seguinte comando para verificar se o Operator foi iniciado com êxito:
|
1 |
$ kubectl obter cápsulas -l aplicativo=couchbase-operador --espaço de nome emart |
Se o Operador estiver ativo e em execução, o comando retornará uma saída em que o campo READY mostra 1/1, como, por exemplo:
|
1 2 |
NOME PRONTO STATUS RESTARTS IDADE couchbase-operador-8c554cbc7-6vqgf 1/1 Em execução 0 57s |
Você também pode verificar os registros para confirmar que o Operador está em funcionamento. Procure a mensagem: CRD initialized, listening for events... module=controller.
|
1 2 3 4 5 6 7 8 9 10 11 |
$ kubectl registros couchbase-operador-8c554cbc7-6vqgf --espaço de nome emart --cauda 20 saída: tempo="2019-05-30T23:00:58Z" nível=informações mensagem="couchbase-operator v1.2.0 (versão)" módulo=principal tempo="2019-05-30T23:00:58Z" nível=informações mensagem="Obtenção de bloqueio de recurso" módulo=principal tempo="2019-05-30T23:00:58Z" nível=informações mensagem="Iniciando o registrador de eventos" módulo=principal tempo="2019-05-30T23:00:58Z" nível=informações mensagem="Tentando ser eleito o líder dos operadores de sofá" módulo=principal tempo="2019-05-30T23:00:58Z" nível=informações mensagem="Eu sou o líder, tente iniciar o operador" módulo=principal tempo="2019-05-30T23:00:58Z" nível=informações mensagem="Criação do controlador couchbase-operator" módulo=principal tempo="2019-05-30T23:00:58Z" nível=informações mensagem="Event(v1.ObjectReference{Kind:\"Endpoints\", Namespace:\"emart\", Name:\"couchbase-operator\", UID:\"c96ae600-832e-11e9-9cec-0e104d8254ae\", APIVersion:\"v1\", ResourceVersion:\"950158\", FieldPath:\"\"}): type: 'Normal' reason: 'LeaderElection' couchbase-operator-6cbc476d4d-2kps4 became leader" módulo=registrador de eventos |
3. Implantar o cluster do Couchbase usando volumes persistentes
Em um ambiente de produção em que o desempenho e o SLA do sistema são mais importantes, devemos sempre planejar a implantação do cluster do Couchbase usando volumes persistentes, pois isso ajuda:
- Recuperação de dados: Os volumes persistentes permitem que os dados associados aos pods sejam recuperados no caso de um pod ser encerrado. Isso ajuda a evitar a perda de dados e a construção demorada de índices ao usar os serviços de dados ou de índices.
- Realocação de cápsulas: O Kubernetes pode decidir expulsar pods que atingem limites de recursos, como limites de CPU e memória. Os pods que têm backup com Volumes persistentes podem ser encerrados e reiniciados em nós diferentes sem incorrer em tempo de inatividade ou perda de dados.
- Provisionamento dinâmico: O Operator criará Persistent Volumes sob demanda à medida que seu cluster for dimensionado, aliviando a necessidade de pré-provisionar o armazenamento do cluster antes da implementação.
- Integração com a nuvem: O Kubernetes se integra aos provisionadores de armazenamento nativos disponíveis nos principais fornecedores de nuvem, como AWS e GCE.
Na próxima seção, veremos como é possível definir classes de armazenamento em diferentes zonas de disponibilidade e criar um modelo de reivindicação de volume persistente, que será usado em couchbase-cluster-com-pv-1.2.yaml arquivo.
3.1. Criar segredo para o console de administração do Couchbase
A primeira coisa que precisamos fazer é criar uma credencial secreta que será usada pelo console administrativo da Web durante o login. Por conveniência, um exemplo de segredo é fornecido no pacote Operator. Quando você o envia para o cluster do Kubernetes, o segredo define o nome de usuário como Administrator e a senha como password.
Para enviar o segredo para seu cluster do Kubernetes, execute o seguinte comando:
|
1 2 3 4 5 |
$ kubectl criar -f segredo.yaml --espaço de nome emart Saída: Secreto/cb-exemplo-autenticação criado |
3.2 Criar classe de armazenamento do AWS para o cluster EKS
Agora, para usar o PersistentVolume para os serviços do Couchbase (dados, índice, pesquisa etc.), precisamos criar Classes de armazenamento (SC) primeiro em cada uma das Zonas de disponibilidade (AZ). Vamos começar verificando quais classes de armazenamento existem em nosso ambiente.
Vamos usar o comando kubectl para descobrir isso:
|
1 2 3 4 5 |
$ kubectl obter classe de armazenamento Saída: gp2 (padrão) kubernetes.io/aws-ebs 12m |
A saída acima significa que temos apenas a classe de armazenamento gp2 padrão e precisamos criar classes de armazenamento separadas em todas as AZs em que planejamos implantar nosso cluster do Couchbase.
1) Crie um arquivo de manifesto de classe de armazenamento do AWS. O exemplo abaixo define a estrutura da classe de armazenamento (sc-gp2.yaml), que usa o tipo de volume Amazon EBS gp2 (também conhecido como unidade SSD de uso geral). Esse armazenamento será usado posteriormente em nosso VolumeClaimTemplate.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Para mais informações sobre o opções disponível para AWS armazenamento aulas, ver [AWS](https://kubernetes.io/docs/concepts/storage/storage-classes/#aws) na documentação do Kubernetes. ``` Versão da API: armazenamento.k8s.io/v1 gentil: Classe de armazenamento metadados: rótulos: k8s-addon: armazenamento-aws.Complementos.k8s.io nome: gp2-multi-zona parâmetros: tipo: gp2 provisionador: kubernetes.io/aws-ebs reclaimPolicy: Excluir volumeBindingMode: WaitForFirstConsumer ``` Acima nós usado ```reclaimPolicy``` para _Delete_ que conta K8 para excluir o volumes de excluído Pods mas você pode mudança ele para _Retenção_ dependendo em seu necessidades ou se para solução de problemas finalidade você seria como para manter o volumes de excluído cápsulas. |
2) Agora, usaremos o comando kubectl para criar fisicamente uma classe de armazenamento a partir dos arquivos de manifesto que definimos acima.
|
1 2 3 4 5 6 7 |
``` $ kubectl criar -f sc-gp2.yaml Saída: classe de armazenamento.armazenamento.k8s.io/gp2-multi-zona criado ``` |
3) Verificar a nova classe de armazenamento
Depois de criar todas as classes de armazenamento, você pode verificá-las por meio do comando kubectl:
|
1 2 3 4 5 6 7 8 9 |
``` $ kubectl obter sc --espaço de nome emart saída: NOME PROVISOR IDADE gp2 (padrão) kubernetes.io/aws-ebs 16h gp2-multi-zona kubernetes.io/aws-ebs 96s ``` |
3.3. Conscientização de grupos de servidores
O Server Group Awareness oferece disponibilidade aprimorada, pois protege um cluster contra falhas de infraestrutura em grande escala, por meio da definição de grupos.
Os grupos devem ser definidos de acordo com a distribuição física dos nós do cluster. Por exemplo, um grupo deve incluir apenas os nós que estão em um único rack de servidor ou, no caso de implantações em nuvem, em uma única zona de disponibilidade. Assim, se o rack do servidor ou a zona de disponibilidade ficar indisponível devido a uma falha de energia ou de rede, o Group Failover, se ativado, permitirá o acesso contínuo aos dados afetados.
Portanto, colocamos os servidores Couchbase em spec.servers.serverGroupsque serão mapeados para nós EKS separados fisicamente e executados em três AZs diferentes (us-east-1a/b/c):
|
1 2 3 4 5 6 7 8 |
especificação: servidores: - nome: dados-leste-1a tamanho: 1 serviços: - dados Grupos de servidores: - nós-leste-1a |
3.4. Adicionar classe de armazenamento ao modelo de declaração de volume persistente
Com os grupos de servidores definidos e as classes de armazenamento disponíveis em todas as três AZs, vamos agora criar volumes de armazenamento dinâmico e montá-los em cada um dos servidores Couchbase que requerem dados persistentes. Para fazer isso, primeiro definiremos o Persistent Volume Claim Template em nosso couchbase-cluster.yaml (que pode ser encontrado na pasta do operador).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
Espécie: volumeClaimTemplates: - metadados: nome: pvc-padrão especificação: storageClassName: gp2-multi-zona recursos: solicitações: armazenamento: 1Gi - metadados: nome: pvc-dados especificação: storageClassName: gp2-multi-zona recursos: solicitações: armazenamento: 5Gi - metadados: nome: pvc-índice especificação: storageClassName: gp2-multi-zona recursos: solicitações: armazenamento: 3Gi |
Depois que o modelo de reivindicação for adicionado, a etapa final é emparelhar o modelo de reivindicação de volume com os grupos de servidores de acordo com cada uma das zonas. Por exemplo, os pods no grupo de servidores chamado data-east-1a devem usar o volumeClaimTemplate chamado dados pvc para armazenar dados e pvc-default para os binários e arquivos de registro do Couchbase.
Por exemplo, o seguinte mostra o emparelhamento de um Server Group e seu VolumeClaimTemplate associado:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
especificação: servidores: - nome: dados-leste-1a tamanho: 1 serviços: - dados Grupos de servidores: - nós-leste-1a cápsula: volumeMounts: padrão: pvc-padrão dados: pvc-dados - nome: dados-leste-1b tamanho: 1 serviços: - dados Grupos de servidores: - nós-leste-1b cápsula: volumeMounts: padrão: pvc-padrão dados: pvc-dados - nome: dados-leste-1c tamanho: 1 serviços: - dados Grupos de servidores: - nós-leste-1c cápsula: volumeMounts: padrão: pvc-padrão dados: pvc-dados |
Observe que criamos três grupos de servidores de dados separados (data-east-1a/-1b/-1c), cada um localizado em sua própria AZ, usando modelos de reivindicação de volume persistente dessa AZ. Agora, usando o mesmo conceito, adicionaremos o índice e os serviços de consulta e os alocaremos em grupos de servidores separados para que possam ser dimensionados independentemente dos nós de dados.
3.5. Implantar o cluster do Couchbase
A especificação completa para implantar o cluster do Couchbase em 3 zonas diferentes usando volumes persistentes pode ser vista na seção couchbase-cluster-com-pv-1.2.yaml arquivo. Esse arquivo, juntamente com outros arquivos yaml de amostra usados neste artigo, pode ser baixado deste repositório git.
Abra o arquivo yaml e observe que estamos implantando o serviço de dados em três AZs, mas implantando o serviço de índice e consulta somente em duas AZs. Você pode alterar a configuração para atender aos seus requisitos de produção.
Agora, use o kubectl para implantar o cluster.
|
1 |
$ kubectl criar -f couchbase-agrupamento-com-pv-1.2.yaml --salvar-configuração --espaço de nome emart |
Isso iniciará a implantação do cluster do Couchbase e, se tudo correr bem, teremos cinco pods do cluster do Couchbase hospedando os serviços de acordo com o arquivo de configuração acima. Para verificar o progresso, execute este comando, que observará (argumento -w) o progresso da criação dos pods:
|
1 2 3 4 5 6 7 8 9 10 11 |
$ kubectl obter cápsulas --espaço de nome emart -w saída: NOME PRONTO STATUS RESTARTS IDADE cb_eks_demo-0000 1/1 Em execução 0 2m cb_eks_demo-0001 1/1 Em execução 0 1m cb_eks_demo-0002 1/1 Em execução 0 1m cb_eks_demo-0003 1/1 Em execução 0 37s cb_eks_demo-0004 1/1 ContainerCreating (Criação de contêineres) 0 1s couchbase-operador-8c554cbc7-n8rhg 1/1 Em execução 0 19h |
Se, por algum motivo, houver uma exceção, você poderá encontrar os detalhes da exceção no arquivo de log do couchbase-operator. Para exibir as últimas 20 linhas do registro, copie o nome do pod do operador e execute o comando abaixo, substituindo o nome do operador pelo nome do seu ambiente.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ kubectl registros couchbase-operador-8c554cbc7-98dkl --espaço de nome emart --cauda 20 saída: tempo="2019-02-13T18:32:26Z" nível=informações mensagem="O cluster não existe, portanto o operador está tentando criá-lo" agrupamento-nome=cb-eks-demonstração módulo=agrupamento tempo="2019-02-13T18:32:26Z" nível=informações mensagem="Criação de serviço sem cabeça para nós de dados" agrupamento-nome=cb-eks-demonstração módulo=agrupamento tempo="2019-02-13T18:32:26Z" nível=informações mensagem="Criação do serviço de interface do usuário NodePort (cb-eks-demo-ui) para nós de dados" agrupamento-nome=cb-eks-demonstração módulo=agrupamento tempo="2019-02-13T18:32:26Z" nível=informações mensagem="Criando um pod (cb-eks-demo-0000) executando o Couchbase enterprise-5.5.3" agrupamento-nome=cb-eks-demonstração módulo=agrupamento tempo="2019-02-13T18:32:34Z" nível=aviso mensagem="node init: failed with error [Post http://cb-eks-demo-0000.cb-eks-demo.emart.svc:8091/node/controller/rename: dial tcp: lookup cb-eks-demo-0000.cb-eks-demo.emart.svc on 10.100.0.10:53: no such host] ...retrying" agrupamento-nome=cb-eks-demonstração módulo=agrupamento tempo="2019-02-13T18:32:39Z" nível=informações mensagem="O operador adicionou o membro (cb-eks-demo-0000) para gerenciar" agrupamento-nome=cb-eks-demonstração módulo=agrupamento tempo="2019-02-13T18:32:39Z" nível=informações mensagem="Inicialização do primeiro nó no cluster" agrupamento-nome=cb-eks-demonstração módulo=agrupamento tempo="2019-02-13T18:32:39Z" nível=informações mensagem="Comece a correr..." agrupamento-nome=cb-eks-demonstração módulo=agrupamento |
Quando todos os pods estiverem prontos, você poderá fazer o port forward de um dos pods do cluster do Couchbase para que possamos visualizar o status do cluster no console da Web. Execute este comando para fazer o encaminhamento de porta.
|
1 |
$ kubectl porto-avançar cb-eks-demonstração-0000 18091:18091 --espaço de nome emart |
Nesse ponto, você pode abrir um navegador e digitar https://localhost:18091, que exibirá o console da Web do Couchbase, no qual você poderá monitorar as estatísticas do servidor, criar buckets e executar consultas, tudo em um único lugar.
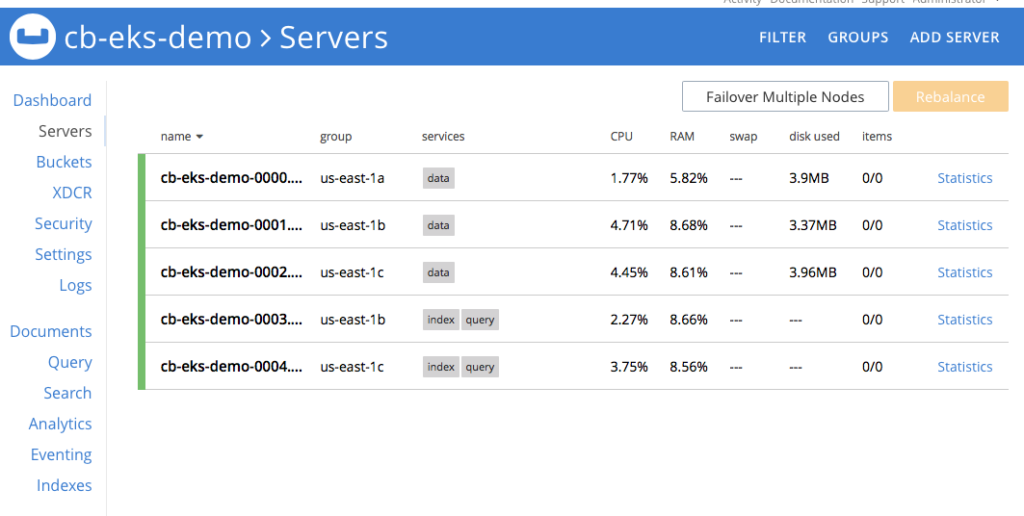
Figura 2: Cluster do Couchbase de cinco nós usando volumes persistentes.
Observação: Visite nossa repositório git para encontrar a versão mais recente do workshop acima.
Conclusão
O Couchbase Autonomous Operator torna o gerenciamento e a orquestração do Couchbase Cluster perfeitos na plataforma Kubernetes. O que torna esse operador único é sua capacidade de usar facilmente as classes de armazenamento oferecidas por diferentes fornecedores de nuvem (AWS, Azure, GCP, RedHat OpenShift etc.) para criar volumes persistentes, que são usados pelo cluster do banco de dados do Couchbase para armazenar os dados de forma persistente. Em caso de falha do pod ou do contêiner, o Kubernetes reinstancia um novo pod/contêiner automaticamente e simplesmente remonta os volumes persistentes, tornando a recuperação rápida. Isso também ajuda a manter o SLA do sistema durante a recuperação de falhas na infraestrutura, pois somente a recuperação delta é necessária, em vez da recuperação completa, se os volumes persistentes não estiverem sendo usados.
Neste artigo, explicamos passo a passo como configurar volumes persistentes no Amazon EKS, mas as mesmas etapas também serão aplicáveis se você estiver usando qualquer outro ambiente Kubernetes de código aberto (AKS, GKE, etc.). Esperamos que você experimente o Couchbase Autonomous Operator e nos conte sobre sua experiência.