Aprender SQL é fácil; implementar SQL, nem tanto.
O Halloween já passou. Mas os truques do problema do Dia das Bruxas vieram para ficar! Isso precisa ser resolvido pelos bancos de dados todos os dias. O SQL tornou o banco de dados relacional fácil, acessível e bem-sucedido. O SQL pode ser fácil de escrever, mas sua implementação esconde muita complexidade. Desde os dias de Sistema R para sistemas NoSQL, todos nós implementamos linguagens inspiradas em SQL e SQL, como N1QLA linguagem de consulta declarativa continua a ser uma linguagem de consulta declarativa. extraordinária eficácia e correção. Um desses problemas é O problema do Halloween. Descreverei o problema brevemente aqui. Recomendo fortemente a leitura de seu histórico no IEEE Annals of the history of computing - segundo link na seção de referências abaixo.
O problema:
Considere uma tabela e um índice simples:
|
1 2 |
CREATE TABLE t (empid int primary key, salary int); CREATE INDEX i1 ON t(salary); |
Imagine que você tenha carregado alguns dados e o índice i1 tenha a seguinte aparência. A entrada do índice tem o valor numérico do salário, seguido pelo rowid.

Agora, no espírito de dar mais às pessoas que têm, queremos aumentar o salário de todos os funcionários que têm (salário > 50).
UPDATE t SET salário = salário + 100 WHERE salário > 50;
Plano de consulta: Aqui está o plano geral para a execução da consulta. Nesse caso, presumiremos que o planejador de consultas usará o índice i1 para qualificar as linhas) para atualizar.
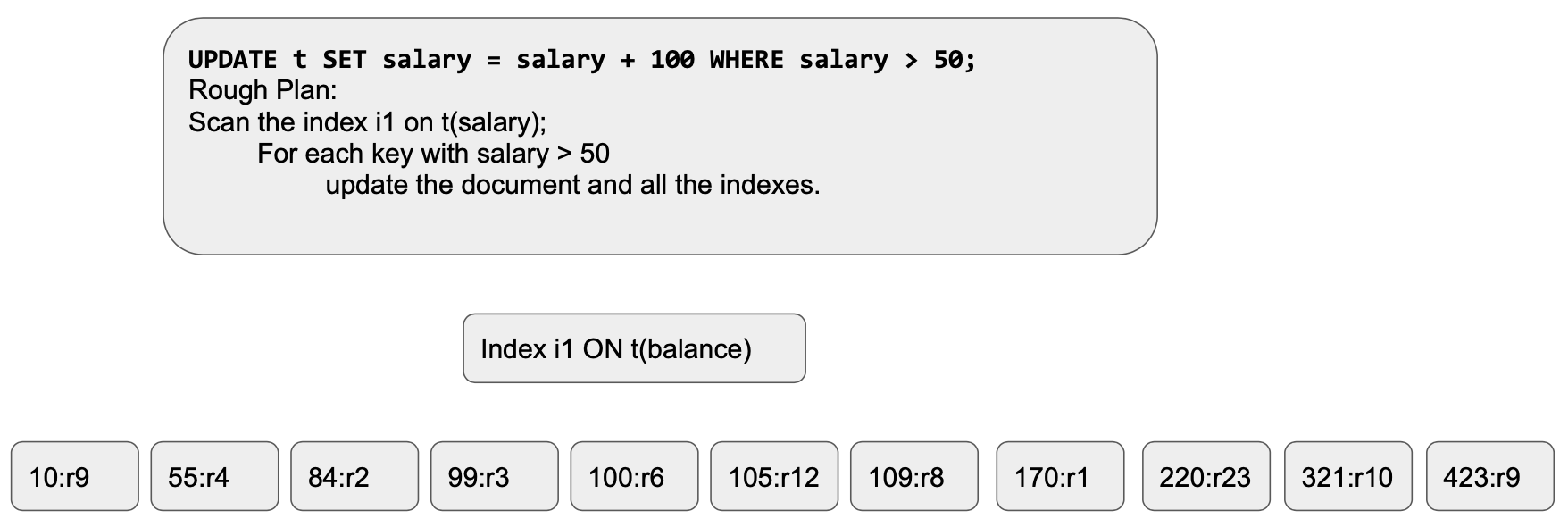
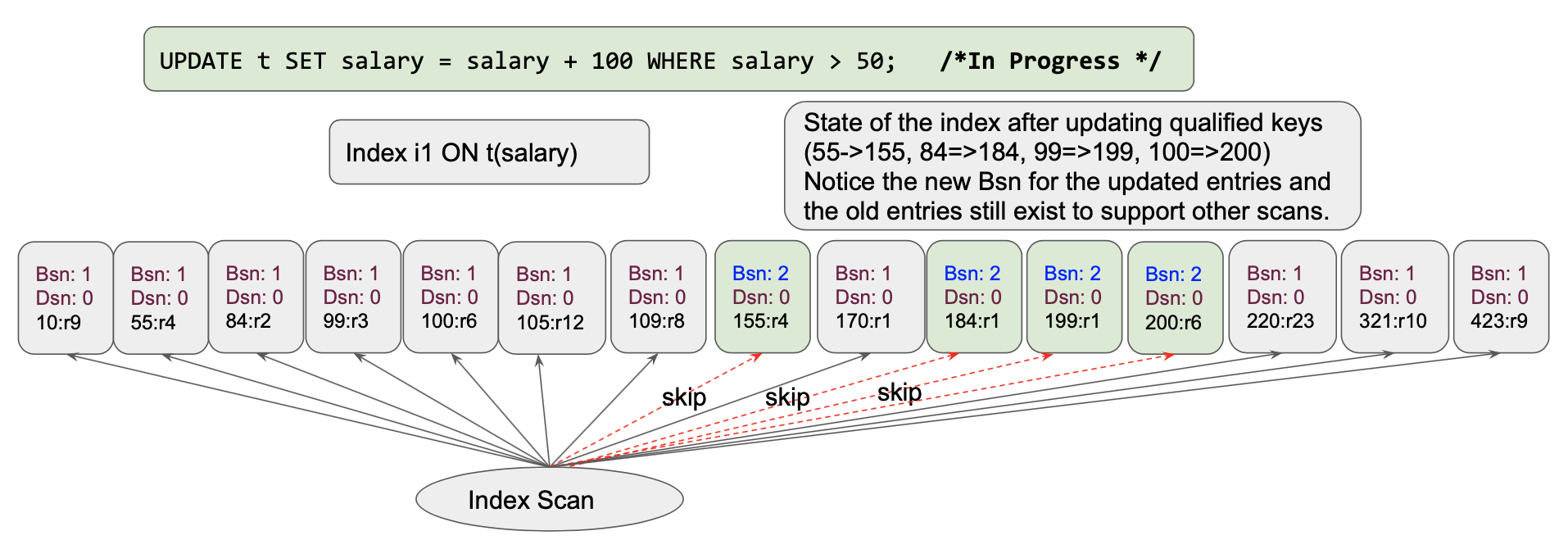
Execução de consultas: Quando isso começar a ser executado, as linhas de dados serão atualizadas e o índice será atualizado de forma síncrona. Cada chave qualificada é atualizada uma a uma [estamos fazendo a varredura da esquerda para a direita]. Aqui está o estado do índice após a atualização das quatro entradas iniciais: (55->155, 84=>184, 99=>199, 100=>200)

Vamos ver o que acontece depois de mais algumas alterações.
Quando passamos para o próximo item,[155,r2] é atualizado novamente para[255,r2]. Isso repetirá a atualização de várias chaves várias vezes. Isso viola as regras de manipulação de conjuntos em que a intenção é pegar o conjunto na tabela t e atualizar os salários qualificados em 100.

Uma manifestação adicional dos problemas do Halloween.
INSERT INTO t SELECT * FROM t WHERE balance > 0;
Solução:
Nos RDBMS tradicionais (por exemplo, Informix), a solução é bastante simples. Para cada uma das instruções DML que resultam em mutação, ele mantém uma lista ordenada de rowids atualizados dentro dessa instrução. Antes de atualizarmos uma linha, verificamos se essa linha já foi atualizada e a ignoramos. Para atualizações simples com varreduras de intervalo limitado, essa sobrecarga de leitura é quase imperceptível. Para atualizações maiores, a manutenção de uma lista grande na memória pode ser um problema. Normalmente, a lista é transferida para o disco quando se torna grande o suficiente.
Solução Couchbase N1QL e GSI:
O Couchbase é um banco de dados distribuído com vários serviços. O serviço de consulta cria o eplano de execução e o executa. Esta é a visão geral da solução.
Vamos dar uma olhada na consulta quando tivermos um índice: CREATE INDEX i1 ON t(salário)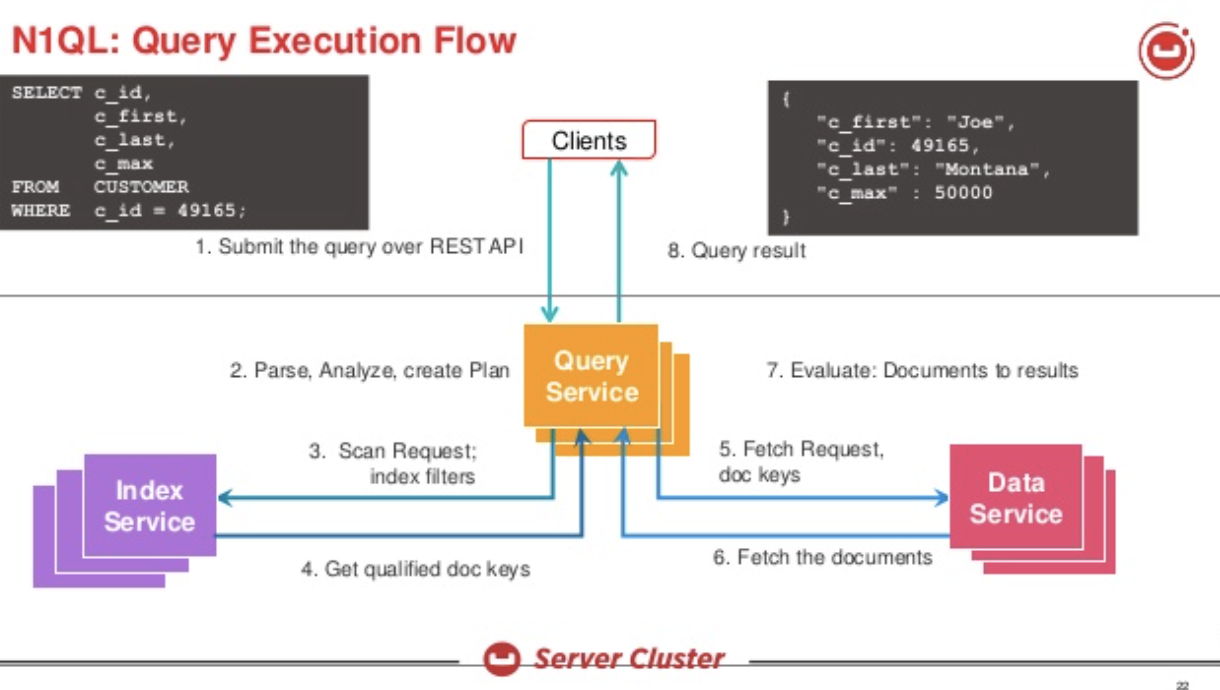 O N1QL criará um plano como este: Na instrução UPDATE, o plano usará a varredura de índice para identificar os documentos a serem atualizados, buscará o documento, o atualizará e o gravará de volta. É importante observar que essa atualização é feita nos documentos de forma síncrona. Essas alterações fluirão pelo DCP e as atualizações de índice ocorrerão de forma assíncrona. Mesmo assim, para atualizações maiores, a varredura do índice e as atualizações podem estar em andamento enquanto as atualizações são feitas no índice que está sendo varrido.
O N1QL criará um plano como este: Na instrução UPDATE, o plano usará a varredura de índice para identificar os documentos a serem atualizados, buscará o documento, o atualizará e o gravará de volta. É importante observar que essa atualização é feita nos documentos de forma síncrona. Essas alterações fluirão pelo DCP e as atualizações de índice ocorrerão de forma assíncrona. Mesmo assim, para atualizações maiores, a varredura do índice e as atualizações podem estar em andamento enquanto as atualizações são feitas no índice que está sendo varrido.
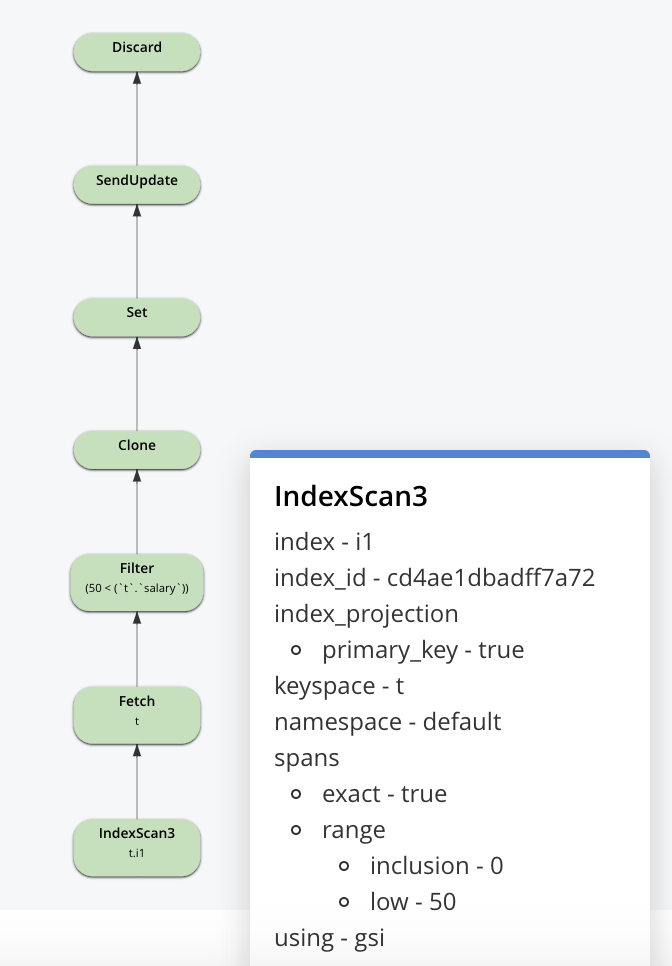
Agora, vamos dar uma olhada na própria varredura do índice. Os índices podem ser criados com base no Índice otimizado para memória (MOI) ou no Secundário padrão (usando o Plasma Storage Engine). Ambos têm o conceito de snapshot. Em vez de atualizar os valores no local, usamos o MVCC para fornecer a funcionalidade e o desempenho necessários.
Aqui estão algumas coisas do Nitro papel.
Instantâneos imutáveis: Os escritores simultâneos adicionam ou removem itens na lista de tarefas. Um instantâneo dos itens atuais pode ser criado para fornecer uma visão pontual da lista de itens. Isso é útil para fornecer varreduras estáveis e repetíveis. Os usuários podem criar e gerenciar vários instantâneos. Se um aplicativo precisar de atomicidade para um lote de operações de lista de esquí, ele poderá aplicar um lote de operações e criar um novo instantâneo. As alterações ficarão invisíveis até que um novo snapshot seja criado.
Instantâneos rápidos e com baixa sobrecarga: Os leitores do skiplist usam um identificador de snapshot para realizar todas as consultas de pesquisa e de intervalo. Um aplicativo indexador normalmente requer a criação de muitos instantâneos a cada segundo para atender às consultas de índice. Portanto, a sobrecarga de criação e manutenção de um instantâneo deve ser mínima para atender à alta taxa de geração de instantâneos. Os instantâneos Nitro são muito baratos e são uma operação O(1).
Para implementá-las, o índice usa duas coisas: A versão BornSnapshot e a versão DeadSnapshot. Vamos dar uma olhada no estado do índice inicial.
 Conforme as alterações, a mudança nos valores simplesmente adiciona novos nós na lista de esqui com valores atualizados, valores de bornSnapshot e deadSnapshot.
Conforme as alterações, a mudança nos valores simplesmente adiciona novos nós na lista de esqui com valores atualizados, valores de bornSnapshot e deadSnapshot.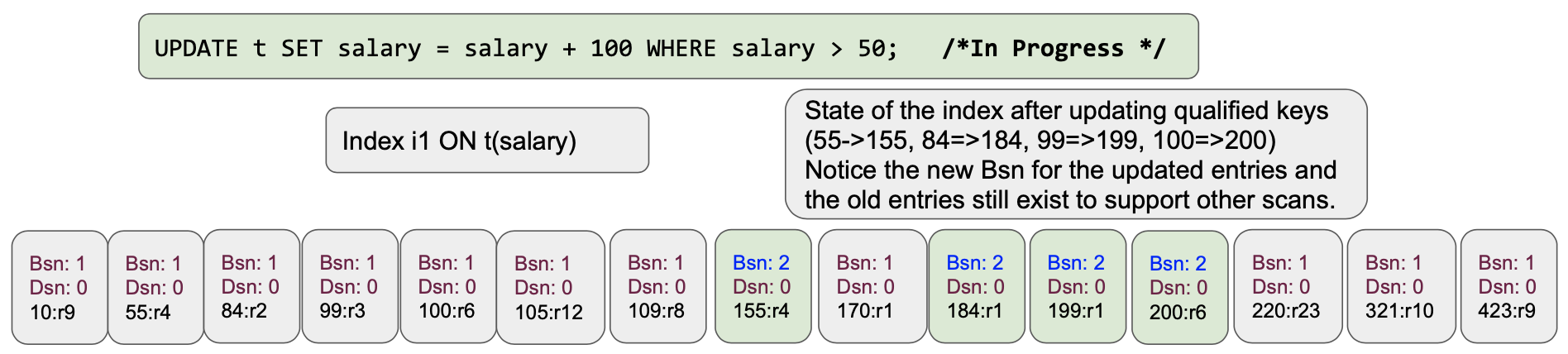
Usando as versões bornSnapshot e deadSnapshot nas entradas, o scanner de índice (também conhecido como iterador) simplesmente escolhe as entradas certas para qualificar as entradas de índice a serem lidas. É assim que ele cria um snapshot e não lê o valor atualizado anteriormente na mesma varredura. Isso não só proporciona varreduras estáveis, mas também evita completamente o problema do Halloween! Isso também elimina a necessidade de manutenção da lista updated-documentid no serviço de consulta. Uma boa engenharia resolveu o problema; uma ótima engenharia evita o problema completamente :-).
Finalmente, uma arte de Halloween de David HaikneyVP de suporte ao cliente do Couchbase! Assista ao vídeo completo!
Feliz Dia das Bruxas para todos@couchbase! 🎃 pic.twitter.com/vqwW7sk3v6
- David Haikney (@dhaikney) 31 de outubro de 2020
Referências
- Problema de Halloween
- Uma consulta bem-intencionada e o problema do Halloween, Los Alamos National Laboratory, Anecdotes, IEEE Annals of the History of Computing
- Índice secundário global do Couchbase
- Nitro: Um mecanismo de armazenamento em memória rápido e dimensionável para o índice secundário global NoSQL