Prelúdio: O que é indexação de banco de dados?
Indexação assíncrona: Os índices secundários globais em bancos de dados - Couchbase, por exemplo - podem ser criados, atualizados e excluídos sem afetar as leituras e gravações nos documentos JSON nos nós de dados. Isso significa que as inserções/atualizações/exclusões específicas do índice ocorrem de forma assíncrona e as cargas de trabalho são isoladas do restante do sistema.
Compreender os SLAs de consulta e criar índices de forma adequada: Os índices estão diretamente relacionados às consultas N1QL que são executadas. N1QL e GSI andam juntos. Os índices devem ser esteroides para consultas N1QL, reduzindo os custos de latência e aumentando a taxa de transferência. Os índices também exigem seu próprio armazenamento, mas o risco de perder negócios devido à lentidão (ou má qualidade) da experiência de envolvimento do cliente é maior do que o custo associado a eles. Além disso, na maioria dos casos, os índices vivem fora dos limites de um aplicativo, o que ajuda a gerenciar adequadamente seu ciclo de vida.
Vamos dar uma olhada em algumas práticas recomendadas de índice de banco de dados para proporcionar as melhores experiências aos clientes.
1. Executar o Index Service em seu próprio conjunto de nós
Embora todos os serviços - dados, consulta, índice, pesquisa etc. - no Couchbase possam ser executados em todos os nós, recomendamos que as cargas de trabalho individuais sejam executadas em seu próprio conjunto de nós. Isso permite o isolamento da carga de trabalho e o dimensionamento independente. Além disso, o hardware pode ser distribuído adequadamente com base na natureza da carga de trabalho. Por exemplo, os índices geralmente consomem muita memória e as consultas consomem muita CPU. Você pode ter diferentes hardwares para esses diferentes serviços. A escalabilidade independente para obter a melhor capacidade computacional por serviço é obtida por meio do recurso arquitetônico que o escalonamento multidimensional (MDS) nos oferece.
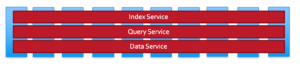
Quando todos os serviços são executados em todos os nós disponíveis
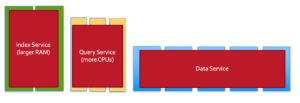
Quando os serviços individuais são executados em seus próprios nós dedicados
2. Entenda o MOI versus o GSI padrão:
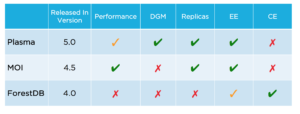
O Couchbase 5.0 introduziu o Plasma como um Novo mecanismo de armazenamento para GSI. O plasma é o mecanismo de armazenamento sublinhado quando "Standard Global Secondary" é escolhido no momento da configuração. Os dois tipos de armazenamento têm características diferentes. Quando o caso de uso exigir que todo o índice seja residente na memória (SLAs mais rígidos, latências mais baixas + taxas de transferência mais altas), escolha o MOI. O GSI padrão (Plasma) é extremamente útil quando todo o índice não pode ser residente na memória, o que chamamos de cenário Data-Greater-Than-Memory (DGM); também é útil quando os custos de memória são um fator na decisão do tipo de índice. Enquanto o MOI pode entrar em um modo de pausa quando a memória é totalmente utilizada (ou seja, as atualizações de índice são interrompidas, embora as consultas sejam atendidas), o Plasma transborda adequadamente para o disco e opera (e os índices nos bancos de dados são atualizados) com facilidade. No Couchbase 5.0, o Plasma funciona bem até cenários DGM 20% (ou seja, 20% dos dados do índice estão na memória); se a consulta acessar chaves na memória e no disco, haverá um impacto adequado no desempenho da consulta devido ao acesso óbvio ao disco durante a consulta.
Devido à natureza de ser totalmente residente na memória, o MOI é geralmente muito mais rápido do que o GSI padrão (especialmente o antigo ForestDB). Até o momento, não é possível ter os dois tipos de indexação no banco de dados residindo no mesmo cluster.
O esquema a seguir explica os diferentes mecanismos de armazenamento de índices disponíveis e seus recursos de alto nível
 3. Usar réplicas de índices : As réplicas no GSI são réplicas ativas, ou seja, elas servem ao duplo propósito de balancear a carga das consultas N1QL e também de receber o tráfego se a outra réplica de índice falhar.
3. Usar réplicas de índices : As réplicas no GSI são réplicas ativas, ou seja, elas servem ao duplo propósito de balancear a carga das consultas N1QL e também de receber o tráfego se a outra réplica de índice falhar.
|
1 |
create index idx on bucket(field1) with {“num_replica”: 2} |
(ou)
|
1 |
create index idx on bucket(field1) with {“nodes”:[“1.2.3.1:8091”, “1.2.3.2:8091”, “1.2.3.3:8091”]} |
As duas cópias do índice são atualizadas automaticamente de forma assíncrona, à medida que as atualizações dos documentos ocorrem nos nós de dados. Sempre tenha pelo menos uma réplica, o que, por sua vez, significa que deve haver no mínimo dois nós de índice para atender às consultas N1QL. Devido ao suporte do rebalanceamento de swap na versão 5.0, se um nó de índice cair e um novo nó for adicionado novamente, a topologia será mantida. Isso é extremamente útil para operações de aumento/diminuição de escala devido a sazonalidades nas consultas, quando você deseja alternar entre nós maiores e nós menores.
Se já estiver usando índices equivalentes, faça a transição para réplicas. Leia mais sobre esse processo aqui.
4. Variantes de índices
O GSI tem diferentes variantes com base em diferentes casos de uso. Essas diferentes variantes foram criadas especificamente para a natureza das consultas e, portanto, é extremamente importante entender o comportamento das consultas e aproveitar adequadamente essas variantes de índice.
| Índice primário | Índice funcional |
| Índice primário nomeado | Índice da matriz |
| Índice composto | Índice coberto |
| Índice parcial | Índice adaptativo |
Dê uma olhada em Este artigo da DZone e esta documentação para saber mais sobre o assunto acima.
Para um exemplo de índice de banco de dados, vamos dar uma olhada no Covered Index: essa variante contém predicados e todos os atributos que foram indexados na definição, o que evita saltos adicionais para os nós de dados. As latências de consulta são significativamente reduzidas.
Por exemplo, se tivermos o seguinte:
|
1 |
CREATE INDEX `idx_ts_type_iata` ON `travel-sample`(`type`,`iata`); |
E use a consulta:
|
1 |
select iata from `travel-sample` where type="airline" and iata = "TQ" |
Em seguida, o Explain Plan revelará que a consulta está sendo "coberta" pelo índice:
|
1 2 3 4 5 6 7 8 9 |
"~children": [ { "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`type`))", "cover ((`travel-sample`.`iata`))", "cover ((meta(`travel-sample`).`id`))" ], "index": "idx_ts_type_iata", |
E se tentarmos selecionar os atributos 'all' (usando 'select *'):
|
1 |
<span style="font-weight: 400">select * from `travel-sample` where type="airline" and iata = "TQ";</span> |
Em seguida, o EXPLAIN PLAN revela que a consulta não está coberta (falta o campo "covers"), pois o Query Service precisa ir até o Data Service para buscar todos os atributos:
|
1 2 3 4 5 6 7 8 |
"~children": [ { "#operator": "IndexScan2", "index": "idx_ts_type_iata", "index_id": "240cf64d8c6ddce3", "index_projection": { "primary_key": true }, |
Da mesma forma, os índices de matriz foram criados principalmente para ajudar nossos clientes a consultar dados JSON, nos quais as matrizes são muito comuns. Em breve, publicaremos um post detalhado sobre isso!
5. Evitar chaves primárias na produção
Varreduras primárias completas inesperadas são possíveis e qualquer possibilidade de tais ocorrências deve ser removida evitando-se totalmente os índices primários na produção. Por enquanto, o N1QL Index Selection é um sistema baseado em regras que verifica se há um possível índice que satisfaça a consulta e, se não houver nenhum, ele recorre ao uso do índice primário. O índice primário tem todas as chaves dos documentos - portanto, a consulta buscará todas as chaves do índice primário e, em seguida, saltará para o Data Service para buscar os documentos e aplicar filtros. Como você pode ver, essa é uma operação muito cara e deve ser evitada a todo custo.
Se não houver índices primários criados e a consulta não conseguir encontrar um índice correspondente para atender à consulta, o Query Service apresentará um erro com a seguinte mensagem, que deverá ajudá-lo a criar o índice secundário necessário:
"Não há índice disponível no espaço-chave travel-sample que corresponda à sua consulta. Use CREATE INDEX ou CREATE PRIMARY INDEX para criar um índice ou verifique se o índice esperado está on-line."
Além disso, como uma prática recomendada de indexação inerente, o particionamento de índices primários não é suportado pelo Couchbase. Diferentemente de muitos RDBMSs, as chaves primárias são opcionais no Couchbase.
6. Usar planos EXPLAIN
Para validar se a consulta N1QL está de fato usando os índices criados, verifique o EXPLICAR O PLANO resultados. No Console de administração do Couchbase, isso pode ser facilmente obtido colando a consulta no editor de código e clicando no botão "Explain" (Explicar). Fique atento ao ícone "#operador" e "índice" do resultado para confirmar o uso do índice. Link da documentação.
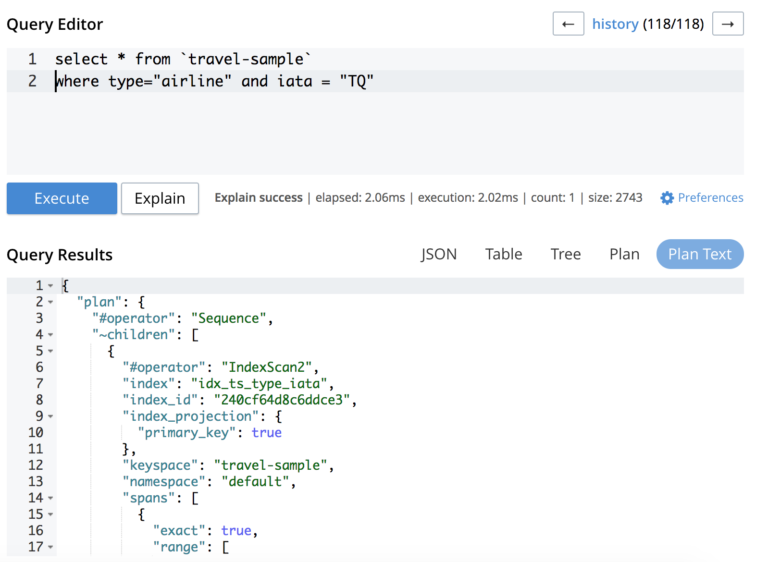 7. Índice por predicado
7. Índice por predicado
A cláusula WHERE em uma consulta é chamada de Predicado e os campos/atributos selecionados na cláusula SELECT são chamados de Projeção. Os índices devem sempre ser criados tendo em mente a cláusula Predicate. Isso se deve ao fato de a seleção do índice ocorrer com base na chave principal do índice presente no Predicate.
Por exemplo, se tivermos o seguinte índice em 4 atributos:
|
1 |
CREATE INDEX `idx_ts_type_iata_name_icao` ON `travel-sample`(`type`,`iata`, `name`,`icao`); |
E disparar a seguinte consulta que realmente ignora o atributo icao durante a consulta, o mecanismo de consulta é inteligente o suficiente para saber usar o índice acima para obter o melhor desempenho da consulta.
|
1 |
select name from `travel-sample` where icao="MLA" and type="airline"; |
O índice selecionado pode ser visto no plano de explicação abaixo. Observe que a consulta se torna uma consulta de cobertura, pois "name", apesar de não estar em Predicate, está em Projection, portanto, o salto para o Data Service é evitado.
|
1 2 3 4 5 6 7 8 9 10 11 |
"~children": [ { "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`type`))", "cover ((`travel-sample`.`iata`))", "cover ((`travel-sample`.`name`))", "cover ((`travel-sample`.`icao`))", "cover ((meta(`travel-sample`).`id`))" ], "index": "idx_ts_type_iata_name_icao", |
8. Usar uma chave principal para forçar a seleção do índice
Um índice não é selecionado automaticamente para uma consulta se o predicado usado na consulta não corresponder à chave principal do índice. Se você perceber que o EXPLAIN PLAN não força a seleção de nenhum índice, use a cláusula "IS NOT MISSING" ou "IS NOT NULL" para forçar a seleção do índice.
FoPor exemplo, qualquer uma das seguintes consultas:
|
1 2 |
select count(1) from `travel-sample` where type IS NOT NULL; select count(1) from `travel-sample` where type IS NOT MISSING; |
usará o seguinte índice, pois a chave principal do índice é 'type':
|
1 |
CREATE INDEX `idx_ts_type_iata` ON `travel-sample`(`type`,`iata`); |
Para escolher apenas um INDEX já criado, use a opção ÍNDICE DE USO como parte da consulta N1QL. Isso é útil nos casos em que você sabe que o índice mencionado em USE INDEX tem melhor seletividade do que o escolhido pelo N1QL Rule Based Optimizer:
|
1 |
select count(1) from `travel-sample` USE INDEX (idx_ts_type_iata) where type="airline"; |
9. Usar índices parciais
Às vezes, o predicado a ser indexado pode não caber em um nó devido a limitações de tamanho. Por enquanto, os GSI no Couchbase não são particionados automaticamente. Isso exige que o administrador crie índices parciais; as consultas N1QL são inteligentes o suficiente para escolher o índice apropriado com base no tipo de predicado usado na consulta quando os índices parciais estão presentes.
Por exemplo, criamos os dois índices a seguir com base no fato de o nome estar em dois intervalos diferentes:
|
1 2 |
CREATE INDEX `idx_ts_name_ak` ON `travel-sample`(`name`) WHERE name BETWEEN "A" AND "K"; CREATE INDEX `idx_ts_name_kz` ON `travel-sample`(`name`) WHERE name BETWEEN "K" AND "Z"; |
Agora, as consultas a seguir escolherão automaticamente o índice adequado, conforme evidenciado nos respectivos EXPLAIN PLANS:
|
1 2 3 4 5 6 7 |
select * from `travel-sample` where name="Astraeus"; EXPLAIN PLAN : "~children": [ { "#operator": "IndexScan2", "index": "idx_ts_name_ak", |
|
1 2 3 4 5 6 7 |
select * from `travel-sample` where name="Texas Wings"; EXPLAIN PLAN : "~children": [ { "#operator": "IndexScan2", "index": "idx_ts_name_kz", |
Os índices são escolhidos adequadamente ao usar a cláusula LIKE no predicado. Por exemplo, digamos que queremos obter todos os nomes que soam como um nome francês (começando com "L"):
|
1 2 3 4 5 6 |
select * from `travel-sample` where name like "L'%"; EXPLAIN PLAN : "~children": [ { "#operator": "IndexScan2", "index": "idx_ts_name_kz", |
10. Opções de consistência
Devido à sua natureza assíncrona, os GSI no Couchbase acabam sendo consistentes por padrão e, como já mencionado, são atualizados de forma assíncrona. Embora, usando feeds de alteração (DCP), atualizemos os índices o mais rápido possível, é bem possível que certas mutações de documentos não tenham sido atualizadas nos índices. Se a semântica da consulta exigir uma consistência de dados mais rígida, o Couchbase oferecerá modelos de consistência ajustáveis no momento da consulta.
As três opções de consistência disponíveis no Couchbase são:
- scan_consistency=not_bounded
- scan_consistency=at_plus
- scan_consistency=request_plus
Para saber mais: Link de documentação
Embora a semântica request_plus imponha a integridade dos dados, há um impacto sobre o desempenho à medida que as latências de consulta aumentam; a consulta aguarda que o índice relevante se atualize com as últimas mutações antes que os dados sejam retornados. 'not_bounded' (a opção de consistência padrão) é a mais rápida de todas as três opções de consistência.
11. Monitoramento do índice de recuperação
Geralmente, o serviço de índice recupera as mutações de documentos muito rapidamente, de modo a causar pouco ou nenhum impacto no usuário. Mas, como administrador, se você quiser ter certeza de que as mutações de documentos (a serem atualizadas no índice) sejam as mínimas possíveis e não continuem aumentando, observe a métrica "itens restantes" sob o nome do índice.
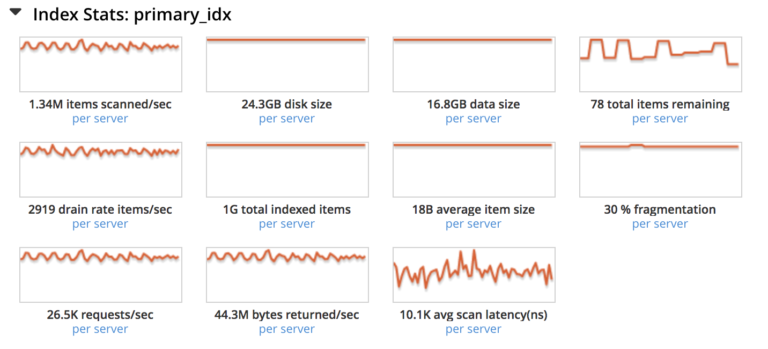
12. Usar compilações Defer
As compilações diferidas oferecem um processo de criação de índices em dois estágios. Recomenda-se que os Defer Builds sejam sempre utilizados da melhor forma possível, pois o mesmo feed de alterações é usado para criar índices em um nó. Se as compilações DEFER não forem usadas, o feed de alterações dos nós de dados precisará ser acessado várias vezes, o que resultará em mais transferência de dados pela rede e em uma carga ligeiramente maior nos nós de dados.
Exemplo:
|
1 2 |
CREATE INDEX `idx_ts_type_iata` ON `travel-sample`(`type`,`iata`) WITH { "defer_build":true }; BUILD INDEX ON `travel-sample`(`idx_ts_type_iata`); |
Para obter mais informações sobre a sintaxe CREATE INDEX, consulte a seção Documentação.
13. Evite chaves grandes para indexar
Antes da versão 5.0, havia uma limitação no tamanho da chave para índices (máximo de 4k). Essa limitação foi removida na versão 5.0. Observe que os índices são destinados a caminhos de acesso a dados, portanto, o modelo de dados e a consulta (com índices) devem ser estruturados para obter as informações necessárias no menor tempo possível. Embora os clientes possam ter qualquer número de campos em um índice composto, o tamanho da chave do índice também cresce proporcionalmente. Tamanhos de chave realmente grandes podem afetar o desempenho. Como regra geral, prefira ter 1kB como o tamanho combinado de todos os campos em um índice composto e, se isso não for possível, refatore as consultas adequadamente.
14. USE CHAVES, evite índices
Não é necessário que todas as consultas N1QL exijam índices. Se suas consultas N1QL puderem funcionar independentemente de índices, consultando diretamente os documentos usando chaves, a diretiva USE KEYS será útil.
Por exemplo:
|
1 |
SELECT * FROM `travel-sample` USE KEYS ["landmark_37588"]; |
O plano de explicação resultante mostrará um KeyScan sendo executado (sem qualquer menção a um IndexScan):
|
1 2 3 4 5 |
"~children": [ { "#operator": "KeyScan", "keys": "[\"landmark_37588\"]" } |
Isso é mais um conhecimento do que uma prática recomendada, pois o USE KEYS não usa índices para retornar resultados do serviço de consulta. Embora seja altamente improvável que os clientes possam ter apenas consultas que sempre usem USE KEYS, isso pode ser útil nos casos extremos que exigem esse comportamento.
Post longo!!! Mas espero que tenha sido útil para entender os bancos de dados e os índices e como a indexação nas práticas recomendadas do DBMS pode ajudá-lo a oferecer experiências superiores aos clientes :)
PS: Uma visão geral do GSI e as novidades do Couchbase Server 5.0 : https://www.youtube.com/watch?v=OrC2gkm2OFA