Esta é a Parte 3 de uma série que examina Estruturas de dados em bancos de dados NoSQL. Nesta postagem, usamos Pesquisa de texto completo consultas de linguagem natural em estruturas de dados no Couchbase.
- Parte 1: Estruturas de dados para aplicativos NoSQL usamos o acesso simplificado a dados JSON por meio de coleções nativas, mapas e muito mais.
- Parte 2: Estruturas de dados e consultas demonstramos a consulta de dados usando consultas N1QL/SQL.
O que é indexação de pesquisa de texto completo?
A indexação de pesquisa de texto completo analisa estruturas de dados de documentos baseadas em texto, registrando as palavras encontradas em cada documento. As consultas podem então usar o índice para encontrar com eficiência documentos que contenham esses termos de pesquisa quando solicitados. Os mecanismos de pesquisa de texto completo usam uma variedade de algoritmos de pesquisa para resolver diferentes tipos de problemas de pesquisa.
O Couchbase usa indexação de dados NoSQL e serviços de consulta baseados em SQL para recuperar informações de estruturas de dados ou documentos. Os índices de pesquisa de texto completo e as solicitações de pesquisa encontram correspondências de documentos de forma mais flexível.
Uma pesquisa de texto completo retorna uma lista de correspondências documentos. Por outro lado, as consultas N1QL retornam um conjunto de linhas. Os índices de texto são conhecidos como índices invertidos, ao contrário da indexação tabular, que se concentra em encontrar linhas/colunas com valores específicos.
A pesquisa de texto completo também pontua e ordena os resultados da pesquisa para que as correspondências de documentos mais relevantes sejam retornadas primeiro.
Depois que um índice de texto completo é criado, ele é atualizado à medida que novos dados entram no banco de dados. Os administradores de banco de dados podem otimizar a indexação para casos de uso específicos - por exemplo, gravações de alto volume versus consultas de alto volume etc.
As estruturas de dados básicas
Há várias estruturas de dados simples que o Couchbase expõe: mapas, listas, conjuntos e filas. Cada uma delas é representada por um tipo de dados JSON e armazenada como documentos NoSQL. Consulte as outras postagens para obter o acesso básico baseado em chave a esses dados.

Exemplos de estruturas de dados NoSQL primárias
Campos específicos nas estruturas podem ser indexados, dependendo da necessidade dos usuários/aplicativos. Quando uma pesquisa é solicitada, a string é comparada com os índices e uma lista de documentos correspondentes é retornada.
Somente as estruturas baseadas em mapas têm nomes de campos, enquanto as estruturas de contadores e listas não têm. Portanto, somente os mapas podem ser indexados. É possível que uma lista também tenha um mapa dentro dela, o que também funcionaria.
Criação de dados de amostra
Usando o Python SDK, criamos algumas estruturas específicas para os fins desta postagem. Ver post anterior Para obter instruções detalhadas, o código simples é mostrado aqui para fins de brevidade. A ideia aqui é que você esteja criando um perfil de usuário, adicionando mais informações à medida que elas se tornam disponíveis.
|
1 2 3 4 5 |
<extensão estilo="font-weight: 400">Mapa #</span> <extensão estilo="font-weight: 400">>>> db.map_add("tylerM","name" (nome),"Tyler", criar=Verdadeiro)</extensão> >>> db.map_add("tylerM","endereço",{"cidade": "kelowna", "país":"Canadá"}) >>> db.map_add("tylerM","top3",["galaga","tetris","dungeons" (masmorras)]) |
Estruturas de dados de pesquisa de texto completo
A pesquisa de texto do Couchbase é semelhante ao uso de estruturas de dados com N1QL, pois também requer um índice. Os índices de pesquisa variam significativamente em complexidade, dependendo dos documentos no banco de dados e do caso de uso. A interface de usuário da Web integrada Pesquisa facilita a criação de novos índices de pesquisa.
Veja Práticas recomendadas de indexação de pesquisa de texto completo para obter informações mais detalhadas.
Estruturas de dados de indexação
Aqui, criamos um índice para os campos específicos que sabemos que existem nos dados. Incluindo o padrão O mapeamento permite que novos campos sejam indexados à medida que ficam on-line. Talvez você queira desativar esse recurso ao otimizar para produção. Além disso, escolhi a opção loja para cada campo, que mostrará o texto correspondente e não apenas a lista de documentos durante a pesquisa.
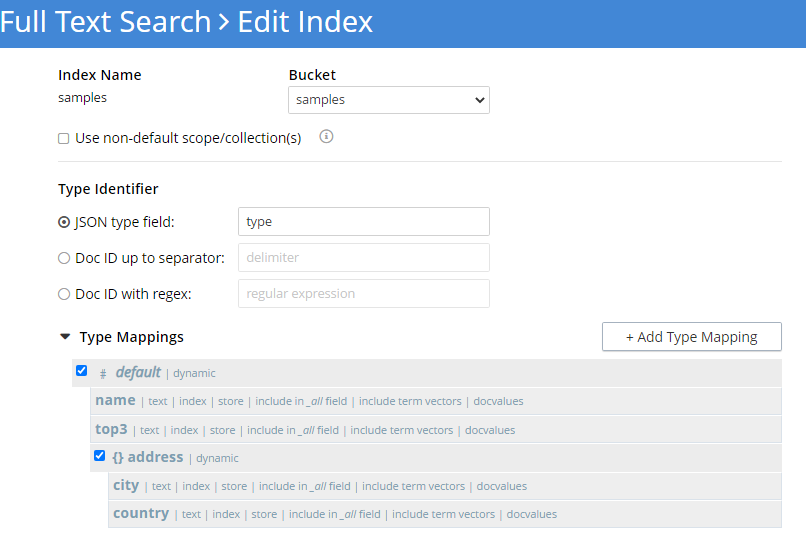
Pesquisa de texto completo do Couchbase criação de índices para entradas de mapa de dados.
Depois de criar o índice de pesquisa, uma barra de pesquisa é exibida para a inserção de texto básico. Consultas mais avançadas (correspondência difusa, correspondência de prefixo, geoespacial) pode ser feito usando a API REST ou o SDK do Couchbase.
Pesquisa de estruturas de dados
Usando a ferramenta de pesquisa integrada, podemos encontrar os objetos da estrutura de dados que correspondem ao texto de entrada. Atualize as estruturas de dados do mapa e os valores aqui serão alterados automaticamente, sem necessidade de indexação adicional.
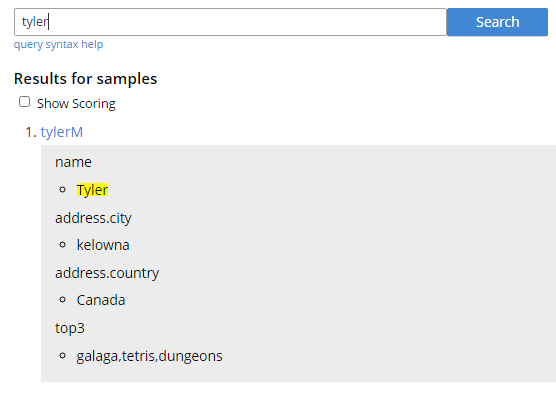
Pesquisa de uma estrutura de dados do Couchbase por meio da interface do usuário da Web
Neste exemplo, pesquisamos uma única palavra/termo e encontramos uma correspondência no nome campo. Se houvesse apenas documentos com esse termo, em qualquer campo, ele também os retornaria.
Um campo também pode ser especificado na caixa de pesquisa com um prefixo, incluindo um ponto para especificar itens filhos dentro de outro. Por exemplo: address.country:Canadá. Os intervalos numéricos também podem ser usados aqui, por exemplo, adicionei outro usuário ao meu banco de dados e adicionei um novo campo ao mapa. Como o campo tylerM não o incluiu, apenas o novo mapa jogador1 item é devolvido.
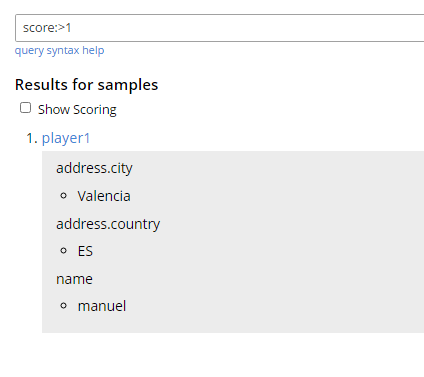
Escopo de campo com uma pesquisa de intervalo numérico.
Ele retornou o documento correspondente e os campos que eu havia indexado especificamente. Os pontuação não foi armazenado explicitamente no índice, embora tenha sido indexado para que você ainda possa encontrar documentos correspondentes.
SDK de pesquisa de texto completo (Python)
Os desenvolvedores usarão o Couchbase Search SDK para fazer chamadas diretas para o banco de dados a partir de seus aplicativos. O SDK retorna uma lista de documentos que correspondem ao texto, juntamente com seus valores de pontuação de relevância.
Para obter mais informações sobre o SDK para seu idioma, consulte Pesquisa de texto completo nos documentos aqui.
Todas as linguagens compatíveis com o SDK do Couchbase podem fazer pesquisas com métodos personalizados para cada tipo de consulta. Esse código Python inclui a conexão básica e o processo de pesquisa que replica os exemplos acima.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
de couchbase.agrupamento importação Aglomerado, ClusterOptions, Opções de consulta, PasswordAuthenticator importação couchbase.pesquisa como FT CONNSTR = "couchbase://localhost"; BUCKET = "amostras"; ÍNDICE = "amostras"; PESQUISA = "tyler" autenticador = PasswordAuthenticator("Administrador", "Administrador") agrupamento = Aglomerado(CONNSTR, ClusterOptions(autenticador)) static_bucket = agrupamento.balde(BUCKET) db = static_bucket.default_collection() qp = FT.QueryStringQuery(PESQUISA) q = agrupamento.consulta_de_pesquisa(ÍNDICE, qp, limite=100) resultados=[] para r em q.linhas(): impressão(PESQUISA, "Encontrado no documento:", r.id, "SCORE:", r.pontuação) |
Produz os detalhes do único documento que correspondeu:
|
1 |
tyler Encontrado em doc: tylerM PONTUAÇÃO: 0.11597946228887497 |
Escopos e coleções na pesquisa
Com o lançamento do Couchbase 7.0, agora é possível usar subconjuntos de documentos em escopos e coleções. Ao criar um índice usando o console da Web, há uma opção "usar escopos não padrão" a ser marcada. Você seleciona um escopo no menu suspenso e cria um novo mapeamento de tipo para especificar uma coleção específica.
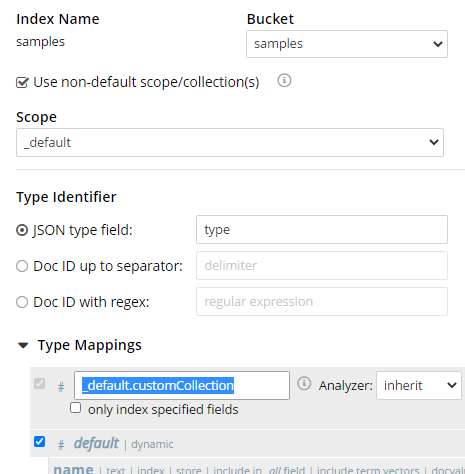
Seleção de um escopo e de uma coleção para o índice de pesquisa.
Não entraremos em detalhes aqui, mas a pesquisa no nível do escopo e da coleção com um SDK usa propriedades no nível da conexão.
|
1 |
dbscoped = agrupamento.balde('amostra de viagem').escopo('_default').coleção('customCollection' (coleção personalizada)) |
Reunindo tudo isso
A criação de documentos, mapas e outras estruturas de dados é muito simples com o uso de alguns SDKs básicos. Da mesma forma, por meio do uso estratégico de métodos de indexação de pesquisa de texto, há ainda mais maneiras de acessar os dados que seus aplicativos estão gerenciando.
Em termos práticos, matrizes JSON básicas, strings etc. podem ser mapeadas e indexadas para uso em outros métodos de acesso.
Como o Couchbase é uma plataforma completa, a arquitetura do seu sistema pode ser bastante simplificada. Os desenvolvedores podem começar a trabalhar imediatamente, sem muito trabalho pesado.
- Parte 1 Estruturas de dados e algoritmos para aplicativos NoSQL
- Parte 2 Estruturas de dados e consultas com o Couchbase N1QL (SQL para JSON)
- Práticas recomendadas de indexação de pesquisa de texto completo NoSQL
- API de estruturas de dados do Couchbase (Python SDK)
- Práticas recomendadas de indexação do sistema de banco de dados NoSQL