Introdução
Há três aspectos importantes nos sistemas de banco de dados: desempenho, desempenho, desempenho. Para os sistemas de banco de dados NoSQL, há três aspectos importantes: desempenho em escala, desempenho em escala, desempenho em escala.
Entender as opções de índice, criar o índice certo, com as chaves certas, a ordem certa e a expressão certa é fundamental para o desempenho da consulta e o desempenho em escala no Couchbase. Discutimos modelagem de dados para JSON e Consultas em JSON anteriormente. Neste artigo, discutiremos as opções de indexação para JSON no Couchbase.
O Couchbase 5.0 tem três tipos de categorias de índice. Cada cluster do Couchbase só pode ter uma categoria de índice, seja o índice secundário global padrão ou o índice secundário global otimizado para memória.
| Secundário padrão: versão 4.0 e superior |
|
| Índice otimizado para memória: 4,5 e superior |
|
| Padrão secundário: versão 5.0 |
|
O índice secundário padrão (de 4.0 a 4.6.x) armazena usa o mecanismo de armazenamento ForestDB para armazenar o índice B-Tree e mantém o conjunto de trabalho ideal de dados no buffer. Isso significa que o tamanho total do índice pode ser muito maior do que a quantidade de memória disponível em cada nó de índice.
Um índice otimizado para a memória usa uma nova lista de espera sem bloqueio para manter o índice e mantém 100% dos dados do índice na memória. Um índice otimizado para memória (MOI) tem melhor latência para varreduras de índice e também pode processar as mutações dos dados com muito mais rapidez.
O índice secundário padrão na versão 5.0 usa o mecanismo de armazenamento plasma em nossa edição corporativa, que usa a lista de saltos sem bloqueio como a MOI, mas suporta índices grandes que não cabem na memória.
Todos os três tipos de índices implementam o controle de simultaneidade de várias versões (MVCC) para fornecer resultados consistentes de varredura de índice e alto rendimento. Durante a instalação do cluster, escolha o tipo de índice.
O objetivo é fornecer uma visão geral dos vários índices que você cria em cada um desses serviços para que suas consultas possam ser executadas com eficiência. O objetivo deste artigo não é descrever ou comparar e contrastar esses dois tipos de serviços de índice. Ele não abrange o FTS (Full-Text Search Index), lançado no Couchbase 5.0.
Vamos pegar o amostra de viagem e testar esses índices.
No console da Web, vá para Configurações->Baldes de amostragem para instalar a amostra de viagem.
Aqui estão os vários índices que você pode criar.
- Índice primário
- Índice primário nomeado
- Índice secundário
- Índice secundário composto
- Índice funcional
- Índice da matriz
- ALL array
- ALL DISTINCT array
- Índice parcial
- Índice adaptativo
- Índices duplicados
- Índice de cobertura
Histórico
O Couchbase é um banco de dados distribuído. Ele oferece suporte a um modelo de dados flexível usando JSON. Cada documento em um bucket terá uma chave de documento exclusiva gerada pelo usuário. Essa exclusividade é imposta durante a inserção dos dados.
Aqui está um exemplo de documento.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECIONAR meta().id, viagens DE `viagem-amostra viagens ONDE tipo = "companhia aérea limite 1; [ { "id": "airline_10", "viagem": { "indicativo": "MILE-AIR", "país": "Estados Unidos", "iata": "Q5", "icao": "MLA", "id": 10, "name" (nome): "40 milhas aéreas", "tipo": "companhia aérea" } } ] |
Tipo de índices
1. Índice primário
cria o índice primário em 'amostra de viagem':
O índice primário é simplesmente o índice da chave do documento em todo o bucket. A camada de dados do Couchbase impõe a restrição de exclusividade na chave do documento. O índice primário, como qualquer outro índice no Couchbase, é mantido de forma assíncrona. Você define a recência dos dados configurando o parâmetro nível de consistência para sua consulta.
Aqui estão os metadados desse índice:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT * DE sistema:índices ONDE nome = '#primary"; "indexes" (índices): { "datastore_id": "https://127.0.0.1:8091", "id": "f6e3c75d6f396e7d", "index_key": [], "is_primary": verdadeiro, "keyspace_id": "amostra de viagem", "name" (nome): "#primary", "namespace_id": "default", "estado": "on-line", "usando": "gsi" } |
Os metadados fornecem informações adicionais sobre o índice: Onde o índice reside (datastore_id), seu estado (state) e o método de indexação (using).
O índice primário é usado para varreduras completas do bucket (varreduras primárias) quando a consulta não tem nenhum filtro (predicado) ou outro índice ou caminho de acesso pode ser usado. No Couchbase, você armazena vários espaços-chave (documentos de um tipo diferente, cliente, pedidos, estoque etc.) em um único bucket. Portanto, quando você fizer a varredura primária, a consulta usará o índice para obter as chaves do documento e buscará todos os documentos no bucket e, em seguida, aplicará o filtro. Isso é MUITO dispendioso.
O design da chave do documento é semelhante ao design da chave primária com várias partes.
Sobrenome:nome:ID do cliente
Exemplo: smith:john:X1A1849
No Couchbase, é uma prática recomendada prefixar a chave com o tipo de documento. Como esse é um documento de cliente, vamos prefixar com CX. Agora, a chave se torna:
|
1 |
Exemplo: CX:smith:john:X1A1849 |
Portanto, no mesmo balde, haverá outros tipos de documentos.
|
1 |
PEDIDOS tipo: OD:US:CA:294829 |
|
1 |
ITENS tipo: IT:KD93823 |
Essas são apenas as práticas recomendadas. Não há restrições quanto ao formato ou à estrutura da chave do documento no Couchbase, exceto o fato de que elas precisam ser exclusivas em um bucket.
Agora, se você tiver documentos com várias chaves e tiver um índice primário, poderá usar as seguintes consultas de forma eficiente.
Exemplo 1: Procurando uma chave de documento específica.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECIONAR * DE vendas ONDE META().id = "CX:smith:john:X1A1849"; { "#operator": "IndexScan2", "índice": "#primary", "index_id": "4c92ab0bcca9690a", "espaço-chave": "vendas", "namespace": "default", "vãos": [ { "exato": verdadeiro, "intervalo": [ { "alto": "\"CX:smith:john:X1A1849\"", "inclusão": 3, "baixo": "\"CX:smith:john:X1A1849\"" } ] } ], } |
Se você souber a chave completa do documento, poderá usar a instrução a seguir e evitar completamente o acesso ao índice.
SELECT * DE vendas USO CHAVES ["CX:ferreiro:joão:X1A1849"]
É possível obter mais de um documento em uma declaração.
|
1 |
SELECIONAR * DE vendas USO CHAVES ["CX:smith:john:X1A1849", "CX:smithjr:john:X2A1492"] |
Exemplo 2: Procure um padrão. Obtenha TODOS os documentos do cliente.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECIONAR * DE vendas ONDE META().id GOSTO "CX:%"; { "#operator": "IndexScan2", "índice": "#primary", "index_id": "4c92ab0bcca9690a", "espaço-chave": "vendas", "namespace": "default", "vãos": [ { "exato": verdadeiro, "intervalo": [ { "alto": "\"CX;\"", "inclusão": 1, "baixo": "\"CX:\"" }" ] } ], } |
Exemplo 3: Obtenha todos os clientes com "smith" como seu sobrenome.
A consulta a seguir usa o índice primário de forma eficiente, buscando apenas os clientes com um intervalo específico. Observação: Essa varredura diferencia maiúsculas de minúsculas. Para fazer uma varredura sem distinção entre maiúsculas e minúsculas, você pode criar um índice secundário com UPPER() ou LOWER() da chave do documento.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECIONAR * DE vendas ONDE META().id GOSTO "CX:smith%"; { "#operator": "IndexScan2", "índice": "#primary", "index_id": "4c92ab0bcca9690a", "espaço-chave": "vendas", "namespace": "default", "vãos": [ { "exato": verdadeiro, "intervalo": [ { "alto": "\"CX:smiti\"", "inclusão": 1, "baixo": "\"CX:smith\"" } ] } ], } |
Exemplo 4: É comum que alguns aplicativos usem um endereço de e-mail como parte do documento, pois são valores exclusivos. Nesse caso, você precisa descobrir todos os clientes com "@gmail.com". Se esse for um requisito típico, armazene o REVERSO do endereço de e-mail como a chave e simplesmente faça a verificação do padrão da cadeia de caracteres principal.
E-mail:johnsmith@gmail.com; chave: reverso("johnsmith@gmail.com") => moc.liamg@htimsnhoj
E-mail: janesnow@yahoo.com chave: reverso("janesnow@yahoo.com") => moc.oohay@wonsenaj
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECIONAR * DE vendas ONDE meta().id GOSTO (reverso("@yahoo.com") || "%"); { "#operator": "IndexScan2", "índice": "#primary", "index_id": "4c92ab0bcca9690a", "espaço-chave": "vendas", "namespace": "default", "vãos": [ { "intervalo": [ { "alto": "\"moc.oohayA\"", "inclusão": 1, "baixo": "\"moc.oohay@\"" } ] } ], } |
2. Índice primário nomeado
No Couchbase 5.0, você pode criar várias réplicas de qualquer índice com um simples parâmetro para CREATE INDEX. O exemplo a seguir criará 3 cópias do índice e deve haver um mínimo de 3 nós de índice no cluster.
|
1 2 |
CRIAR PRIMÁRIO ÍNDICE ON 'amostra de viagem' COM {"num_replica":2}; CRIAR PRIMÁRIO ÍNDICE `def_primary` ON `viagem-amostra ; |
Você também pode nomear o índice primário. O restante dos recursos do índice primário é o mesmo, exceto o nome do índice. Um bom efeito colateral disso é que você pode ter vários índices primários nas versões do Couchbase anteriores à 5.0 usando nomes diferentes. Os índices duplicados ajudam na alta disponibilidade, bem como na distribuição da carga de consulta entre eles. Isso é válido tanto para índices primários quanto para índices secundários.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECIONAR meta().id como chave de documentos, `viagem-amostra companhia aérea DE `viagem-amostra ONDE tipo = "companhia aérea limite 1; { "companhia aérea": { "indicativo": "MILE-AIR", "país": "Estados Unidos", "iata": "Q5", "icao": "MLA", "id": 10, "name" (nome): "40 milhas aéreas", "tipo": "companhia aérea" }, "documentkey": "airline_10" } |
3. Índice secundário
O índice secundário é um índice em qualquer chave-valor ou chave-documento. Esse índice pode ser qualquer chave dentro do documento. A chave pode ser de qualquer tipo: escalar, objeto ou matriz. A consulta deve usar o mesmo tipo de objeto para que o mecanismo de consulta possa explorar o índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
CRIAR ÍNDICE nome_da_viagem ON `viagem-sample`(name); nome é a simples escalar valor. { "name" (nome): "Air France" } CRIAR ÍNDICE viagem_geo em `viagem-sample`(geo); geo é e objeto incorporado dentro de o documento. Exemplo: "geo": { "alt": 12, "lat": 50.962097, "longo": 1.954764 } Criação de índices em chaves de aninhado objetos é direto. CRIAR ÍNDICE viagem_geo em `viagem-amostra`(geo.alt); CRIAR ÍNDICE viagem_geo em `viagem-sample`(geo.lat); |
O campo de programação é uma matriz de objetos com detalhes do voo. Isso indexa a matriz completa. Não é exatamente útil, a menos que você esteja procurando a matriz inteira.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
CRIAR ÍNDICE agenda_de_viagens ON `viagem-sample`(schedule); Exemplo: "agenda": [ { "dia": 0, "voo": "AF198", "utc": "10:13:00" }, { "dia": 0, "voo": "AF547", "utc": "19:14:00" }, { "dia": 0, "voo": "AF943", "utc": "01:31:00" }, { "dia": 1, "voo": "AF356", "utc": "12:40:00" }, { "dia": 1, "voo": "AF480", "utc": "08:58:00" }, { "dia": 1, "voo": "AF250", "utc": "12:59:00" } ] |
4. Índice secundário composto
É comum ter consultas com vários filtros (predicados). Portanto, você deseja que os índices tenham várias chaves para que possam retornar somente as chaves qualificadas do documento. Além disso, se uma consulta estiver referenciando apenas as chaves no índice, o mecanismo de consulta simplesmente responderá à consulta a partir do resultado da varredura do índice sem ir aos nós de dados. Essa é uma otimização de desempenho comumente explorada.
|
1 |
CRIAR ÍNDICE idx_stctln ON `viagens-amostra` (estado, cidade, nome.sobrenome) |
Cada uma das chaves pode ser um campo escalar simples, um objeto ou uma matriz. Para que a filtragem de índice seja explorada, os filtros precisam usar o respectivo tipo de objeto no filtro de consulta. As chaves dos índices secundários podem incluir chaves de documento (meta().id) explicitamente se você precisar filtrá-las no índice.
Vamos dar uma olhada nas consultas que exploram e não exploram o índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
1.SELECIONAR * DE `viagem-amostra ONDE estado = "CA; O predicado jogos o principal chave de o índice. Portanto, este consulta usos o índice para totalmente avaliar o predicado (estado = 'CA'). 2.SELECIONAR * DE `viagem-amostra ONDE estado = "CA E cidade = "Windsor; O predicados partida o principal dois chaves. Portanto este é bom ajuste como Bem. 3.SELECIONAR * DE `viagem-amostra ONDE estado = "CA E cidade = "Windsor E name.lastname = 'smith'; O três predicados em este consulta jogos o três índice chaves perfeitamente. Portanto, este é a bom partida. 4.SELECIONAR * DE `viagem-amostra ONDE cidade = "Windsor E name.lastname = 'smith'; Em este consulta, embora predicados partida dois de o índice chaves, o principal chave não é combinados. Portanto, o índice não pode e é não usado para este consulta planos. 5.SELECIONAR * DE `viagem-amostra ONDE name.lastname = 'smith'; Similar para anterior consulta, este consulta tem o predicado em o terceiro chave de o índice. Portanto, este índice não pode ser usado. 6.SELECIONAR * DE `viagem-amostra ONDE estado = "CA E name.lastname = 'smith'; Isso consulta tem predicado em primeiro e o terceiro chave. Enquanto este índice é e pode ser escolhido, nós não pode empurrar para baixo o predicado após pular e índice chave (segundo chave em este caso). Portanto, somente o primeiro predicado (estado = "CA") vontade ser empurrado para baixo para índice digitalização. "#operator": "IndexScan2", "índice": "idx_stctln", "index_id": "dadbb12da565ed28", "index_projection": { "primary_key": verdadeiro }, "espaço-chave": "amostra de viagem", "namespace": "default", "vãos": [ { "exato": verdadeiro, "intervalo": [ { "alto": "\"CA\"", "inclusão": 3, "baixo": "\"CA\"" } ] } 7.SELECIONAR * DE `viagem-amostra ONDE estado IS NÃO FALTANDO E cidade = "Windsor E name.lastname = 'smith'; Isso é a modificado versão de consulta 4 acima. Para uso este índice, o consulta necessidades para ter e adicionais predicado (estado IS NÃO FALTA) supondo que representa seu aplicativo requisito. |
5. Índice Funcional (Expressão)
É comum ter nomes no banco de dados com uma mistura de letras maiúsculas e minúsculas. Quando você precisa pesquisar "John", você quer que ele pesquise qualquer combinação de "John", "john" etc. Veja como fazer isso.
CRIAR ÍNDICE nome_do_cx de viagem ON `viagem-sample`(INFERIOR(nome));
Forneça a cadeia de caracteres de pesquisa em letras minúsculas e o índice pesquisará com eficiência os valores já em letras minúsculas no índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
EXPLICAR SELECIONAR * DE `viagem-amostra ONDE INFERIOR(nome) = "john"; { "#operator": "IndexScan", "índice": "travel_cxname", "index_id": "2f39d3b7aac6bbfe", "espaço-chave": "amostra de viagem", "namespace": "default", "vãos": [ { "Faixa": { "Alta": [ "\"john\"" ], "Inclusão": 3, "Baixa": [ "\"john\"" ] } } ] } |
Você pode usar expressões complexas nesse índice funcional.
CRIAR ÍNDICE viagem_cx1 ON `viagem-sample`(INFERIOR(nome), comprimento*largura, rodada(salário));
Você também verá que os índices de matriz podem ser criados em uma expressão que retorna uma matriz na próxima seção.
6. Índice da matriz
O JSON é hierárquico. No nível superior, ele pode ter campos escalares, objetos ou matrizes. Cada objeto pode aninhar outros objetos e matrizes. Cada array pode ter outros objetos e arrays. E assim por diante. O aninhamento continua.
Quando você tem essa estrutura rica, veja como indexar uma matriz específica ou um campo dentro do subobjeto.
Considere a matriz, a programação:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
programação: [ { "dia" : 0, "special_flights" (voos especiais) : [ { "voo" : "AI111", "utc" : "1:11:11" }, { "voo" : "AI222", "utc" : "2:22:22" } ] }, { "dia": 1, "voo": "AF552", "utc": "14:41:00" } ] CRIAR ÍNDICE agenda de viagens ON `viagem-amostra (TODOS DISTINTO ARRAY v.dia PARA v IN cronograma FIM) |
Essa chave de índice é uma expressão na matriz para referenciar claramente apenas os elementos que precisam ser indexados. schedule a matriz à qual estamos fazendo referência. v é a variável que declaramos implicitamente para referenciar cada elemento/objeto dentro da matriz: schedule v.day refere-se ao elemento dentro de cada objeto da matriz schedule.
A consulta abaixo explorará o índice da matriz.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
EXPLICAR SELECIONAR * DE `viagem-amostra ONDE QUALQUER v IN CALENDÁRIO SATISFAÇÕES v.dia = 2 FIM; { "#operator": "DistinctScan", "scan": { "#operator": "IndexScan", "índice": "travel_sched", "index_id": "db7018bff5f10f17", "espaço-chave": "amostra de viagem", "namespace": "default", "vãos": [ { "Faixa": { "Alta": [ "2" ], "Inclusão": 3, "Baixa": [ "2" ] } } ], "usando": "gsi" } |
Como a chave é uma expressão generalizada, você tem a flexibilidade de aplicar lógica e processamento adicionais aos dados antes da indexação. Por exemplo, você pode criar uma indexação funcional nos elementos de cada array. Como você está fazendo referência a campos individuais do objeto ou elemento dentro do array, a expressão criação de índicesO índice acima armazena apenas valores distintos em um array. O índice acima armazena apenas os valores distintos em uma matriz. Para armazenar todos os elementos de uma matriz em um índice, use o modificador DISTINCT na expressão.
CRIAR ÍNDICE agenda de viagens ON `viagem-sample` (TODOS DISTINTO ARRAY v.dia PARA v IN cronograma FIM)
O índice de matriz pode ser criado em valores estáticos (como acima) ou em uma expressão que retorna uma matriz. TOKENS() são uma dessas expressões, retornando uma matriz de tokens de um objeto. Você pode criar um índice nessa matriz e pesquisar usando o índice.
O Couchbase 5.0 simplifica a criação e a correspondência dos índices de matriz. Fornecer o prefixo ALL (ou ALL DISTINCT) à chave fará com que ela se torne uma chave de matriz.
|
1 2 3 4 5 6 7 8 9 |
CRIAR ÍNDICE idx_cx6 ON `viagem-sample`(TODOS TOKENS(public_likes)) ONDE tipo = 'hotel'; SELECIONAR t.name, t.country, t.public_likes DE `viagem-amostra t ONDE t.tipo = 'hotel' AND ANY p IN TOKENS(public_likes) SATISFAZ p = 'Vallie FIM; |
Os índices de matriz também podem ser criados em elementos dentro de matrizes de matrizes. Não há limite para o nível aninhado da expressão de matriz. A expressão de consulta precisa corresponder à expressão de índice.
7. Índice parcial
Até agora, os índices que criamos criarão índices em todo o bucket. Como o modelo de dados do Couchbase é JSON e o esquema JSON é flexível, um índice pode não conter entradas para documentos com chaves de índice ausentes. Isso é esperado. Diferentemente dos sistemas relacionais, em que cada tipo de linha está em uma tabela distinta, os buckets do Couchbase podem ter documentos de vários tipos. Normalmente, os clientes incluem um campo de tipo para diferenciar tipos distintos.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "companhia aérea": { "indicativo": "MILE-AIR", "país": "Estados Unidos", "iata": "Q5", "icao": "MLA", "id": 10, "name" (nome): "40 milhas aéreas", "tipo": "companhia aérea" }, "documentkey": "airline_10" } |
Quando você quiser criar um índice de documentos de companhias aéreas, basta adicionar o campo de tipo para a cláusula WHERE do índice.
CRIAR ÍNDICE informação_de_viagem ON `viagem-sample`(name, id, icoo, iata) ONDE tipo = "companhia aérea;
Isso criará um índice somente nos documentos que tenham (type = 'airline'). Em suas consultas, você precisará incluir o filtro (type = 'airline') além de outros filtros para que esse índice se qualifique.
Você pode usar predicados complexos na cláusula WHERE do índice. Vários casos de uso para explorar os índices parciais são:
- Partição de um índice grande em vários índices usando a função mod.
- Particionar um índice grande em vários índices e colocar cada índice em nós indexadores distintos.
- Particionar o índice com base em uma lista de valores. Por exemplo, você pode ter um índice para cada estado.
- Simular o particionamento do intervalo de índices por meio de um filtro de intervalo na cláusula WHERE. Um aspecto a ser lembrado é que as consultas N1QL do Couchbase usarão um índice particionado por bloco de consulta. Use UNION ALL para que uma consulta explore vários índices particionados em uma única consulta.
8. Índice adaptativo
Um índice adaptativo cria um único índice em todo o documento ou conjunto de campos em um documento. Esse é um índice de formulário ou matriz que usa o par {"key": value} como chave de índice único. O objetivo é evitar o problema de uma consulta ter que corresponder às chaves principais do índice em índices tradicionais.
Há duas vantagens com o índice adaptativo:
- Vários predicados no espaço-chave podem ser avaliados usando seções diferentes do mesmo índice.
- Evite criar vários índices apenas para reordenar as chaves do índice.
- Evite a ordem das chaves do índice.
Exemplo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CRIAR ÍNDICE `ai_self` ON `viagem-sample`(DISTINTO PAIRS(ai_self)) ONDE tipo = "aeroporto"; EXPLICAR SELECIONAR * DE `viagem-amostra ONDE faa = "SFO" E `tipo` = "aeroporto"; { "#operator": "IntersectScan", "varreduras": [ { "#operator": "IndexScan2", "índice": "ai_self", "index_id": "c564a55225d9244c", "index_projection": { "primary_key": verdadeiro }, "espaço-chave": "amostra de viagem", "namespace": "default", "vãos": [ { "exato": verdadeiro, "intervalo": [ { "alto": "[\"faa\", \"SFO\"]", "inclusão": 3, "baixo": "[\"faa\", \"SFO\"]" } ] } ], "usando": "gsi" } ... ] } |
O mesmo índice também pode ser usado para consultas com outros predicados. Isso reduz o número de índices que você precisa criar à medida que o documento cresce.
|
1 2 3 4 |
EXPLICAR SELECIONAR * DE `viagem-amostra ONDE cidade = "Seattle" E `tipo` = "aeroporto"; |
Considerações sobre o uso:
- Como cada campo de atributo tem uma entrada de índice, o tamanho dos índices pode ser enorme.
- O índice adaptativo é um índice de matriz. Ele é limitado pela restrição dos índices de matriz.
Consulte a documentação detalhada sobre índice adaptativo na documentação do Couchbase.
9. Índice duplicado
Esse não é realmente um tipo especial de índice, mas um recurso de indexação do Couchbase. Você pode criar índices duplicados com nomes distintos.
|
1 2 3 4 5 6 7 8 9 10 11 |
CRIAR ÍNDICE i1 ON `viagem-sample`(INFERIOR(nome),id, icoo) ONDE tipo = "companhia aérea"; CRIAR ÍNDICE i2 ON `viagem-sample`(INFERIOR(nome),id, icoo) ONDE tipo = "companhia aérea"; CRIAR ÍNDICE i3 ON `viagem-sample`(INFERIOR(nome),id, icoo) ONDE tipo = "companhia aérea"; |
Todos os três índices têm chaves idênticas, cláusula WHERE idêntica; a única diferença é o nome dos índices. Você pode escolher a localização física deles usando a cláusula WITH do CREATE INDEX. Durante a otimização da consulta, a consulta escolherá um dos nomes. Você verá isso em seu plano. Durante o tempo de execução da consulta, esses índices são usados de forma round-robin para distribuir a carga. Isso proporciona a você escalabilidade multidimensional, desempenho e alta disponibilidade. Nada mal!
O Couchbase 5.0 torna o índice duplicado MAIS SIMPLES. Em vez de criar vários índices com nomes distintos, você pode simplesmente especificar o número de índices de réplica necessários.
|
1 2 3 4 |
CRIAR ÍNDICE i1 ON `viagem-sample`(INFERIOR(nome),id, icoo) ONDE tipo = "companhia aérea COM {"num_replica" : 2 }; |
Isso criará duas cópias adicionais do índice, além do índice i1. Os recursos de balanceamento de carga e HA são os mesmos de um índice equivalente.
10. Índice de cobertura
A seleção do índice para uma consulta depende exclusivamente dos filtros na cláusula WHERE de sua consulta. Depois que a seleção do índice é feita, o mecanismo analisa a consulta para ver se ela pode ser respondida usando apenas os dados do índice. Se for possível, o mecanismo de consulta não recupera o documento inteiro. Essa é uma otimização de desempenho a ser considerada ao projetar os índices.
Todos juntos agora!
Vamos montar um índice de matriz funcional composta particionada agora!
|
1 2 3 4 5 6 7 8 9 10 |
CRIAR ÍNDICE viagens_todas ON `viagem-sample`( iata, INFERIOR(nome), SUPERIOR(indicativo), TODOS DISTINTO ARRAY p.model PARA p IN jatos FIM), TO_NUMBER(rating), meta().id ) ONDE INFERIOR(país) = "estados unidos" E tipo = "companhia aérea" COM {"num_replica" : 2} |
Regras para criar os índices.
Até agora, vimos os tipos de índices. Vamos agora ver como projetar os índices para sua carga de trabalho.
Regra #1: usar chaves
No Couchbase, cada documento em um bucket tem uma chave exclusiva gerada pelo usuário. Os documentos são distribuídos entre diferentes nós por meio do hash dessa chave (usamos hashing consistente). Quando você tem a chave do documento, pode buscar os documentos diretamente nos aplicativos (por meio de SDKs). Mesmo quando você tem as chaves do documento, talvez queira buscar e fazer algum pós-processamento via N1QL. É nesse momento que você usa o método USE KEYS.

Exemplo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
SELECIONAR nome, endereço DE `viagem-amostra h USO CHAVES [ "hotel_10025", "hotel_10026", "hotel_10063", "hotel_10064", "hotel_10138", "hotel_10142", "hotel_10158", "hotel_10159", "hotel_10160", "hotel_10161", "hotel_10180", "hotel_10289", "hotel_10290", "hotel_10291", "hotel_1072", "hotel_10848", "hotel_10849", "hotel_10850", "hotel_10851", "hotel_10904" ] ONDE h.país = "Reino Unido" E ARRAY_LENGTH(public_likes) > 3; |
O método de acesso USE KEYS pode ser usado mesmo quando você faz junções. Veja um exemplo:
SELECIONAR * DE PEDIDOS o USO CHAVES ["ord::382"] INNER JOIN CLIENTE c ON CHAVES o.id;
No Couchbsae 5.0, os índices são usados somente para processar o primeiro espaço-chave (bucket) de cada cláusula FROM. Os espaços-chave subsequentes são processados por meio da busca direta do documento.
SELECIONAR * DE PEDIDOS o INNER JOIN CLIENTE c ON CHAVES o.id ONDE o.state = "CA";
Nessa instrução, processamos o espaço-chave ORDERS por meio de um índice em (state) se ele estiver disponível. Caso contrário, usamos o índice primário para examinar ORDERS. Em seguida, buscamos os documentos CUSTOMER que correspondem ao ID no documento ORDERS.
Regra #2: USAR ÍNDICE DE COBERTURA
Discutimos os tipos de índice anteriormente neste artigo. O índice correto tem duas finalidades:
- Reduzir o conjunto de trabalho da consulta para acelerar o desempenho da consulta
- Armazenar e fornecer dados adicionais.
Quando uma consulta pode ser respondida completamente pelos dados armazenados no índice, diz-se que a consulta é coberto pelo índice de cobertura. Você deve tentar cobrir a maioria, se não todas, as suas consultas. Isso reduzirá a carga de processamento no serviço de consulta e reduzirá a busca adicional no serviço de dados.
A seleção do índice ainda é feita com base nos predicados da consulta. Depois que a seleção do índice for feita, o otimizador avaliará se o índice contém todos os atributos necessários para a consulta e criará um acesso coberto ao caminho do índice.
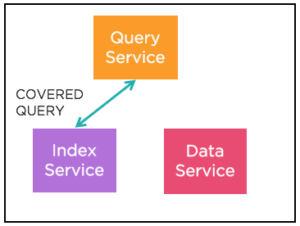
Exemplos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CRIAR ÍNDICE idx_cx3 ON CUSTOMER(state, cidade, name.lastname) ONDE status = 'premium'; /* A consulta abaixo não será coberta, pois você disse: SELECT * */ SELECIONAR * DE CLIENTE ONDE estado = "CA E status = 'prêmio'; /* O índice tem todos os três campos exigidos pela consulta. */ /* A consulta será coberta, conforme mostrado no plano de explicação. */ SELECT status, estado, cidade DE CLIENTE WHERE state = 'CA' E status = 'prêmio"; { "#operator": "IndexScan2", "coberturas": [ "cover ((`CUSTOMER`.`state`))", "cover ((`CUSTOMER`.`city`))", "cover (((`CUSTOMER`.`name`).`lastname`))", "cover ((meta(`CUSTOMER`).`id`))" ], "filter_covers": { "cobrir ((`CUSTOMER`.`status`))": "premium" }, "índice": "idx_cx3", "index_id": "18f8209144215971", "index_projection": { "entry_keys": [ 0, 1 ] } |
Observe que o campo status na cláusula WHERE do índice (status = 'premium') também está coberto. Sabemos que cada documento no índice tem um campo chamado status com o valor "premium". Podemos simplesmente projetar esse valor. O campo "Filter_covers" na explicação mostra essas informações.
Desde que o índice tenha o campo, uma consulta pode fazer filtragem, junções, agregação e paginação adicionais depois de buscar os dados do indexador sem buscar o documento completo.
Regra #3: USAR A REPLICAÇÃO DE ÍNDICE
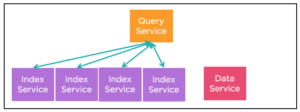
Em um cluster do Couchbase, você tem vários serviços de índice. Antes do Couchbase 5.0, você pode criar manualmente índices de réplica (equivalentes) para melhorar a taxa de transferência, o balanceamento de carga e a alta disponibilidade.
Antes da versão 5.0:
|
1 2 3 4 5 6 7 8 9 |
CRIAR ÍNDICE idx1 ON CUSTOMER(state, cidade, name.lastname) ONDE status = 'premium'; CRIAR ÍNDICE idx2 ON CUSTOMER(state, cidade, name.lastname) ONDE status = 'premium'; CRIAR ÍNDICE idx3 ON CUSTOMER(state, cidade, name.lastname) ONDE status = 'premium'; |
Reconhecemos a equivalência desses três índices porque as expressões-chave e a cláusula WHERE são exatamente o mesmo.
Durante a fase de otimização da consulta, o mecanismo N1QL seleciona um dos três índices para a varredura de índice (supondo que outros requisitos sejam atendidos) para criar o plano de consulta. Durante a execução da consulta, a consulta prepara o pacote de varredura e envia uma solicitação de varredura de índice. Durante esse processo, com base nas estatísticas de carga, enviamos a solicitação a um deles. A ideia é que, com o tempo, cada um deles terá uma carga semelhante.
Esse processo de criação de índices de réplica (índices equivalentes) é facilitado por um parâmetro simples.
|
1 2 3 4 |
CRIAR ÍNDICE idx1 ON CUSTOMER(state, cidade, name.lastname) ONDE status = 'premium' COM { "num_replica":2 }; |
Isso é o mesmo que criar três índices distintos, mas equivalentes.
Regra #4: INDEXAR POR WORKLOAD, NÃO POR BUCKET/KEYSPACE
Considere toda a carga de trabalho do aplicativo e os contratos de nível de serviço (SLAs) para cada uma das consultas. As consultas que têm requisitos de latência de milissegundos com alta taxa de transferência exigirão índices personalizados e réplicas, enquanto outras podem compartilhar índices.
Pode haver keyspaces nos quais você simplesmente realiza operações de set & get ou pode emitir consultas com USE KEYS. Esses espaços de chave não precisarão de nenhum índice.
Analise as consultas para encontrar os predicados comuns, projeções de um espaço-chave. Você pode otimizar o número de índices com base em predicados comuns. Se uma de suas consultas não tiver um predicado sobre a chave ou chaves principais, verifique se a adição de (field IS NOT MISSING) faz sentido para que o índice possa ser compartilhado.
Não há problema em ter um índice primário durante o desenvolvimento do aplicativo ou das consultas. Mas, antes de testar, crie os índices corretos e remova o índice primário do sistema, a menos que seu aplicativo use os casos descritos na seção "Índice primário". Se você tiver um índice primário em produção e as consultas acabarem fazendo uma varredura primária completa com uma extensão total no índice, você está pedindo para ter problemas. No Couchbase, o índice primário indexa todos os documentos no bucket.
Todo índice secundário no Couchbase deve ter uma cláusula WHERE, com pelo menos uma condição sobre o tipo de documento. Isso não é imposto pelo sistema, mas é um bom design.
|
1 2 3 |
CRIAR ÍNDICE def_route_src_dst ON `viagem-amostra (`sourceairport`, `destinationairport`) ONDE (`tipo` = "route" (rota)); |
Criar os índices corretos é uma das práticas recomendadas para a otimização do desempenho. Essa não é a única coisa que você precisa fazer para obter o melhor desempenho. A configuração do cluster, o ajuste, a configuração do SDK e o uso de instruções preparadas desempenham um papel importante.
Regra #5: INDEXE POR PREDICATO, NÃO POR PROJEÇÃO
Essa parece ser uma regra óbvia. Mas, de vez em quando, me deparo com pessoas que cometem esse erro.
Considere a consulta:
|
1 2 3 4 |
SELECIONAR cidade, Estado, status DE CLIENTE ONDE estado = "CA E status = 'premium'; |
Qualquer um dos índices a seguir pode ser usado pela consulta:
|
1 2 3 4 5 6 |
Criar índice i1 em CLIENTE(estado); Criar índice i2 em CLIENTE(status); Criar índice i3 em CUSTOMER(state, status); Criar índice i4 em CLIENTE(status, estado); Criar índice i5 em CLIENTE(estado) ONDE status = "premium"; Criar índice i6 em CLIENTE(status) ONDE status = "CA"; |
Para que o índice cubra completamente a consulta, basta adicionar o campo cidade ao índice 3-6.
No entanto, se você tiver um índice que tenha a cidade como chave principal, o otimizador não pegará o índice.
|
1 2 3 |
Criar índice i7 O ON CUSTOMER(cidade, estado) ONDE status = "premium"; |
Consulte o artigo detalhado sobre como a varredura de índice funciona em vários cenários para otimizar o índice: https://dzone.com/articles/understanding-index-scans-in-couchbase-50-n1ql-que
Regra #6: ADICIONE ÍNDICES PARA ATENDER AOS SLAs
Para os bancos de dados relacionais, três coisas eram mais importantes: desempenho, desempenho e desempenho.
Para os bancos de dados NoSQL, três coisas são mais importantes: desempenho em escala, desempenho em escala e desempenho em escala.
Uma coisa são as consultas que executam o teste de desempenho básico em seu laptop, outra coisa é executar as consultas de alta taxa de transferência e baixa latência no cluster. Felizmente, no Couchbase, é fácil identificar e dimensionar os recursos de gargalo de forma independente, graças ao dimensionamento multidimensional. Cada um dos serviços no Couchbase é abstraído em um serviço distinto: dados, índice, consulta. O console do Couchbase tem estatísticas sobre cada um dos serviços de forma independente.
Depois de criar índices para suas consultas e otimizá-los para a carga de trabalho, você pode adicionar índices de réplica adicionais (equivalentes) para melhorar a latência, pois fazemos o balanceamento de carga das varreduras entre os índices de réplica.
Regra #7: ÍNDICE PARA EVITAR A ORDENAÇÃO
O índice já tem os dados na ordem classificada das chaves do índice. Após a varredura, o índice retorna os resultados na ordem das chaves do índice.
|
1 2 3 |
CRIAR ÍNDICE idx3 ON `viagem-sample`(state, cidade, name.lastname) ONDE status = 'premium'; |
Os dados são armazenados e retornados na ordem: state, city, name.lastname. Portanto, se você tiver uma consulta que espera os dados na ordem de state, city, name.lastname, um índice o ajudará a evitar a classificação.
No exemplo abaixo, os resultados são ordenados por name.lastname, a terceira chave do índice. Portanto, é necessário classificar o conjunto de resultados em name.lastname. O Explain lhe dirá se o plano exige essa classificação.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
EXPLICAR SELECIONAR Estado, cidade, name.lastname DE `viagem-amostra ONDE status = 'premium' E estado = "CA E cidade GOSTO 'san%' ORDER BY nome.sobrenome; { "plano": { "#operator": "Sequência", "~crianças": [ { "#operator": "Sequência", "~crianças": [ { "#operator": "IndexScan2", "coberturas": [ "cover ((`travel-sample`.`state`))", "cover ((`travel-sample`.`city`))", "cover (((`travel-sample`.`name`).`lastname`))", "cover ((meta(`travel-sample`).`id`))" ], "filter_covers": { "cover ((`travel-sample`.`status`))": "premium" }, "índice": "idx3", "index_id": "19a5aed899d281fe", "index_projection": { "entry_keys": [ 0, 1, 2 ] }, "espaço-chave": "amostra de viagem", "namespace": "default", "vãos": [ { "exato": verdadeiro, "intervalo": [ { "alto": "\"CA\"", "inclusão": 3, "baixo": "\"CA\"" }, { "alto": "\"sao\"", "inclusão": 1, "baixo": "\"san\"" } ] } ], "usando": "gsi" }, { "#operator": "Paralelo", "~child": { "#operator": "Sequência", "~crianças": [ { "#operator": "Filtro", "condição": "((((cover ((`travel-sample`.`status`)) = \"premium\") e (cover ((`travel-sample`.`state`)) = \"CA\")) e (cover ((`travel-sample`.`city`)) like \"san%\"))" }, { "#operator": "InitialProject" (Projeto inicial), "result_terms": [ { "expr": "cover ((`travel-sample`.`state`))" }, { "expr": "cover ((`travel-sample`.`city`))" }, { "expr": "cover (((`travel-sample`.`name`).`lastname`))" } ] } ] } } ] }, { "#operator": "Ordem", "sort_terms": [ { "expr": "cover (((`travel-sample`.`name`).`lastname`))" } ] }, { "#operator": "FinalProject" (Projeto Final) } ] }, "texto": "SELECT state, city, name.lastname \nFROM `travel-sample`\nWHERE status = 'premium' AND state = 'CA' AND city LIKE 'san%'\nORDER BY name.lastname;" } |
A consulta abaixo tem a correspondência perfeita para as chaves do índice. Portanto, a classificação é desnecessária. Na saída da explicação, o operador de ordem está ausente.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
EXPLICAR SELECIONAR Estado, cidade, name.lastname DE `viagem-amostra ONDE status = 'premium' E estado = "CA E cidade GOSTO 'san%' ORDER BY Estado, cidade, nome.sobrenome; { "plano": { "#operator": "Sequência", "~crianças": [ { "#operator": "Sequência", "~crianças": [ { "#operator": "IndexScan2", "coberturas": [ "cover ((`travel-sample`.`state`))", "cover ((`travel-sample`.`city`))", "cover (((`travel-sample`.`name`).`lastname`))", "cover ((meta(`travel-sample`).`id`))" ], "filter_covers": { "cover ((`travel-sample`.`status`))": "premium" }, "índice": "idx3", "index_id": "19a5aed899d281fe", "index_projection": { "entry_keys": [ 0, 1, 2 ] }, "espaço-chave": "amostra de viagem", "namespace": "default", "vãos": [ { "exato": verdadeiro, "intervalo": [ { "alto": "\"CA\"", "inclusão": 3, "baixo": "\"CA\"" }, { "alto": "\"sao\"", "inclusão": 1, "baixo": "\"san\"" } ] } ], "usando": "gsi" }, { "#operator": "Paralelo", "maxParallelism": 1, "~child": { "#operator": "Sequência", "~crianças": [ { "#operator": "Filtro", "condição": "((((cover ((`travel-sample`.`status`)) = \"premium\") e (cover ((`travel-sample`.`state`)) = \"CA\")) e (cover ((`travel-sample`.`city`)) like \"san%\"))" }, { "#operator": "InitialProject" (Projeto inicial), "result_terms": [ { "expr": "cover ((`travel-sample`.`state`))" }, { "expr": "cover ((`travel-sample`.`city`))" }, { "expr": "cover (((`travel-sample`.`name`).`lastname`))" } ] }, { "#operator": "FinalProject" (Projeto Final) } ] } } ] } ] }, "texto": "SELECT state, city, name.lastname \nFROM `travel-sample`\nWHERE status = 'premium' AND state = 'CA' AND city LIKE 'san%'\nORDER BY state, city, name.lastname;" } |
A exploração da ordem de classificação do índice pode não parecer importante até que você veja o caso de uso da paginação. Quando a consulta tiver especificado OFFSET e LIMIT, um índice poderá ser usado para eliminar com eficiência os documentos que não interessam ou não são necessários ao aplicativo. Veja a artigo sobre paginação para obter detalhes sobre isso.
O otimizador N1QL primeiro seleciona o índice com base nos predicados da consulta (filtros) e, em seguida, verifica se o índice pode abranger todas as referências da consulta em projeção e ordem por. Depois disso, o otimizador tenta eliminar a classificação e decide sobre o OFFSET e o LIMIT pushdown. A explicação mostra se o OFFSET e o LIMIT foram empurrados para a varredura do índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
"espaço-chave": "amostra de viagem", "limite": "20", "namespace": "default", "offset": "100", "vãos": [ { "exato": verdadeiro, "intervalo": [ { "alto": "\"CA\"", "inclusão": 3, "baixo": "\"CA\"" }, { "alto": "\"sao\"", "inclusão": 1, "baixo": "\"san\"" } ] } ] |
Regra #8: Número de índices
Não há limite artificial para o número de índices que você pode ter no sistema. Se você estiver criando um grande número de índices em um bucket que tenha os dados, use a opção de criação diferida para que a transferência de dados entre o serviço de dados e o serviço de índice seja eficiente.
Regra #9: índice durante INSERT, DELETE, UPDATE
O índice é mantido de forma assíncrona. Suas atualizações de dados por meio da API de valor-chave ou de quaisquer instruções N1QL atualizam apenas os documentos no bucket. O índice recebe a notificação de alterações por meio do fluxo e aplica as alterações ao índice. Esta é a sequência de operações de um comando UPDATE. A instrução usa o índice para qualificar os documentos a serem atualizados; busca os documentos e os atualiza; em seguida, grava os documentos de volta e retorna todos os dados solicitados da instrução UPDATE.
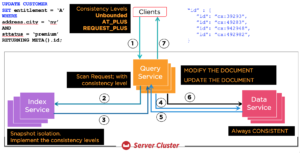
Regra #11: ORDEM DAS CHAVES DE ÍNDICE E TIPOS DE PREDICADO
Solicitações de varredura de índice criadas pelas primeiras N chaves consecutivas do índice dos usuários da consulta. Portanto, a ordem da chave do índice é importante.
Considere uma consulta com vários predicados:
|
1 2 3 4 5 |
SELECIONAR cid, endereço DE CLIENTE ONDE estado = "CA E tipo = 'premium' E código postal IN [29482, 29284, 29482, 28472] E salário < 50000 E idade > 45; |
Essas são regras gerais para a ordem das chaves no índice. As chaves podem ser atributos escalares mais simples ou expressões que retornam valores escalares: por exemplo, UPPER(name.lastname).
- A primeira prioridade são as chaves com predicados de igualdade. Nessa consulta, ela está no estado e no tipo. Quando houver vários predicados do mesmo tipo, escolha qualquer combinação.
- A segunda prioridade são as chaves com predicados IN. Nessa consulta, é o CEP.
- A terceira prioridade são os predicados de menor que (<). Nesse caso, ele está no salário.
- A quarta prioridade são os predicados entre. Essa consulta não tem um predicado between.
- A quinta prioridade é o predicado maior que (>). Nessa consulta, ele está relacionado à idade.
- A sexta prioridade são os predicados de matriz: ANY, ou EVERY AND ANY, predicados após UNNEST.
- Procure adicionar campos adicionais para que o índice cubra a consulta.
- Depois de fazer essa análise, procure quaisquer expressões que possam ser movidas para a cláusula WHERE. Por exemplo, nesse caso, type = "premium" pode ser movido porque o campo type é designado pelos usuários para identificar o tipo de clientes.
Com isso, chegamos ao seguinte índice.
|
1 2 3 4 5 |
CRIAR ÍNDICE idx_order ON CLIENTE ( Estado, CEP, salário, idade, endereço, cid ) ONDE tipo = "premium"; |
Regra #12: entender como ler EXPLAIN e PROFILING
Não importa quantas regras você siga, será necessário entender os planos e o perfil da consulta, monitorar o sistema sob carga e ajustá-lo. A capacidade de entender e analisar o plano de consulta e as informações de criação de perfil é a chave para ajustar uma consulta e uma carga de trabalho. Há dois excelentes artigos sobre esses tópicos. Leia e experimente os exemplos.
- https://dzone.com/articles/understanding-index-scans-in-couchbase-50-n1ql-que
- https://www.couchbase.com/blog/profiling-monitoring-update-2/
Referências
- Nitro: Um mecanismo de armazenamento em memória rápido e escalável para o índice secundário global NoSQL: https://vldb2016.persistent.com/industrial_track_papers.php
- Couchbase: https://www.couchbase.com
- Documentação do Couchbase: https://docs.couchbase.com
- N1QL: Um guia prático: https://www.couchbase.com/blog/n1ql-practical-guide-second-edition/
- Index Advisor: Regras para criação de índices: https://www.slideshare.net/journalofinformix/couchbase-n1ql-index-advisor
Oi Keshav,
Sou novo no CB, então, por favor, perdoe minha compreensão.
O seguinte é mencionado neste blog
"Portanto, quando você fizer a varredura primária, a consulta usará o índice para obter as chaves do documento e buscar todos os documentos no bucket e, em seguida, aplicar o filtro. Portanto, isso é MUITO CARO."
Li isso em vários lugares e foi o que me disseram, ou seja, que um índice primário deve ser evitado. Não consigo entender por quê? No Oracle ou em qualquer outro RDBMS, a pesquisa baseada em chave primária/única é a mais rápida/melhor. Entendo que, se a consulta N1QL não tiver nenhum predicado, ela fará a varredura de todo o bucket, ou seja, fará a varredura de todas as chaves usando o índice primário, o que seria caro. Mas se a chave for especificada no predicado, não seria a mais rápida?
No exemplo 1, a chave específica é mencionada no predicado. Portanto, isso deve ser quase tão bom quanto getid('key'), não é?
Agradecimentos
Olá pccb,
Se você tiver a chave do documento (essa é a chave exclusiva dentro do bucket), terá um método de acesso integrado, que é o mais eficiente do N1QL.
SELECT * FROM mybucket USE KEYS "cx:482:gn:284";
Você também pode usar o índice primário para isso, emitindo:
SELECT * FROM mybucket WHERE meta().id = "cx:482:gn:284";
Você pode fazer varreduras de intervalo inteligentes no meta().id usando o índice primário:
SELECT * FROM mybucket WHERE meta().id LIKE "cx:482:gn:%";
Aqui estão os aspectos dos quais você precisa estar ciente:
1. O bucket do Couchbase pode documentar todos os tipos diferentes: cliente, pedido, item etc. O índice primário estará em todos esses tipos de documentos.
2. Se o desenvolvedor/usuário construir cuidadosamente a consulta para executar uma varredura de igualdade ou de intervalo limitado, não há problema em usar o índice primário.
3. Mas, se alguém fizer uma consulta sem essas diretrizes ou fizer uma consulta sem nenhum outro índice qualificado em produção, acabaremos usando a varredura primária e a varredura e busca de todo o índice e de todos os documentos no bucket. Normalmente, isso é ruim na produção.
Olá,
Existe uma maneira de evitar um índice, ou seja, fazer com que o CB NÃO use o índice?
O que estamos tentando alcançar é o seguinte:
Haverá o índice primário, para que os desenvolvedores possam testar suas consultas. No entanto, depois de finalizarem as consultas, incluindo o índice necessário, gostaríamos que elas fossem executadas, certificando-se de que não estejam usando o índice primário. O motivo é que, mesmo depois de criar o índice secundário apropriado, pode ser que a consulta ainda esteja usando o índice primário e o desenvolvedor não tenha percebido isso. Portanto, se houver uma maneira de evitar o uso do índice primário, eles executariam a consulta usando essa opção.
Agradecimentos
Obrigado pelo feedback. Abri um aprimoramento para adicionar isso: https://issues.couchbase.com/browse/MB-32109
Há um erro de digitação ou estou perdendo alguma coisa:
CREATE INDEX travel_sched ON
amostra de viagem(ALL DISTINCT ARRAY v.day FOR v IN schedule END)
A sintaxe "ALL DISTINCT" é válida e o que ela significa? Não consegui encontrá-la na documentação!
Agradecimentos