Se você tem acompanhado as postagens anteriores no blog do Couchbase, já viu conteúdo sobre o Couchbase Shell última versão. Estou experimentando coisas diferentes e hoje quis ver o que poderia fazer com conjuntos de dados de séries temporais.
Ingerir dados de séries temporais
Navegando no Kaggle, encontrei dados de temperatura por cidade. Eu fiz o download. Ele tem cerca de 500 Mb e isso o torna difícil de manipular como um todo. Mas, é claro, é um arquivo de texto, portanto, podemos facilmente dar uma olhada na estrutura de dados da seguinte forma:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
> open GlobalLandTemperaturesByCity.csv | first 10 ╭───┬────────────┬────────────────────┬───────────────────────────────┬───────┬─────────┬──────────┬───────────╮ │ # │ dt │ AverageTemperature │ AverageTemperatureUncertainty │ City │ Country │ Latitude │ Longitude │ ├───┼────────────┼────────────────────┼───────────────────────────────┼───────┼─────────┼──────────┼───────────┤ │ 0 │ 1743-11-01 │ 6.07 │ 1.74 │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 1 │ 1743-12-01 │ │ │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 2 │ 1744-01-01 │ │ │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 3 │ 1744-02-01 │ │ │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 4 │ 1744-03-01 │ │ │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 5 │ 1744-04-01 │ 5.79 │ 3.62 │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 6 │ 1744-05-01 │ 10.64 │ 1.28 │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 7 │ 1744-06-01 │ 14.05 │ 1.35 │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 8 │ 1744-07-01 │ 16.08 │ 1.40 │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 9 │ 1744-08-01 │ │ │ Århus │ Denmark │ 57.05N │ 10.33E │ ╰───┴────────────┴────────────────────┴───────────────────────────────┴───────┴─────────┴──────────┴───────────╯ |
|
1 2 3 |
> open GlobalLandTemperaturesByCity.csv | length 8599212 |
8599212 linhas, serão 8599211 documentos. Meu objetivo final é ver um gráfico de temperatura de várias cidades ao longo dos anos. Para fazer isso, primeiro vou importar tudo para um bucket de importação e, em seguida, transformarei os dados em séries temporais.
Se eu importar isso de forma ingênua, terei um documento por cidade/grupo de meses. Portanto, a chave do meu documento será como Århus:1743-11-01. Digamos que eu queira fazer o upload apenas da primeira linha, ela deverá ter a seguinte aparência:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
> open GlobalLandTemperaturesByCity.csv | first 1 | wrap content | insert id { |x| $"($x.content.City):($x.content.dt)" } ╭───┬───────────────────┬──────────────────╮ │ # │ content │ id │ ├───┼───────────────────┼──────────────────┤ │ 0 │ {record 7 fields} │ Århus:1743-11-01 │ ╰───┴───────────────────┴──────────────────╯ > open GlobalLandTemperaturesByCity.csv | first 1 | wrap content | insert id { |x| $"($x.content.City):($x.content.dt)" } |doc upsert ╭───┬───────────┬─────────┬────────┬──────────┬─────────╮ │ # │ processed │ success │ failed │ failures │ cluster │ ├───┼───────────┼─────────┼────────┼──────────┼─────────┤ │ 0 │ 1 │ 1 │ 0 │ │ capella │ ╰───┴───────────┴─────────┴────────┴──────────┴─────────╯ |
E agora que eu sei que funciona, vamos pegar tudo e fazer um lote:
|
1 |
open GlobalLandTemperaturesByCity.csv | par-each -t 5 {|x| wrap content | insert id {$"($x.City):($x.dt)" } } | doc upsert |
Eu criei um série na qual importo o resultado de uma coleção SELECIONAR agregação, obtendo todas as datas como registros de data e hora e todas as Temperatura média como valor:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
query ' INSERT INTO series(KEY _k, VALUE _v) SELECT a.City _k, {"City": a.City , "ts_start" : MIN(STR_TO_MILLIS(a.dt)), "ts_end" : MAX(STR_TO_MILLIS(a.dt)), "ts_data" : ARRAY_AGG([STR_TO_MILLIS(a.dt), a.AverageTemperature]) } _v FROM import a WHERE a.dt BETWEEN "1700-01-01" AND "2020-12-31" GROUP BY a.City; ' INSERT INTO series(KEY _k, VALUE _v) SELECT a.City _k, {"City": a.City , "ts_start" : MIN(STR_TO_MILLIS(a.dt)), "ts_end" : MAX(STR_TO_MILLIS(a.dt)), "ts_data" : ARRAY_AGG([STR_TO_MILLIS(a.dt), a.AverageTemperature]) } _v FROM import a WHERE SUBSTR(a.City,0,1) = "Z" AND a.dt BETWEEN "2010-01-01" AND "2020-12-31" GROUP BY a.City; |
E agora todos os dados estão disponíveis como séries temporais. Digamos que eu queira os dados de Paris, posso usar o comando _timeseries função como esta:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
> let ts_ranges = [946684800000,1375315200000]; query $"SELECT t._t time, t._v0 `value` FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t WHERE d.city = \"Paris\" AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \);" | reject cluster | to csv time,value 946684800000,3.845 949363200000,6.587000000000001 951868800000,7.872000000000001 954547200000,10.067 957139200000,15.451 959817600000,17.666 962409600000,16.954 965088000000,19.512 967766400000,16.548000000000002 970358400000,11.675999999999998 .... |
Para acelerar o processo, você pode criar o seguinte índice: CREATE INDEX ix1 ON series(City, ts_end, ts_start);
Observe o uso da palavra ts_ranges no início. Você pode reutilizar facilmente esses valores em um modelo Cordas. Eles começam com um $ e as variáveis devem estar entre parênteses, como ($my_variable). Isso também significa que agora você precisa escapar do caractere de parêntese, bem como das aspas duplas.
Plotar séries temporais
Há uma variedade de bibliotecas de plotagem de terminal, aqui estou usando youplot:
|
1 |
> let ts_ranges = [946684800000,1375315200000]; query $"SELECT t._t date, t._v0 `value` FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t WHERE d.city = \"Paris\" AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \);" | reject cluster | to csv | uplot line -d, --xlim 946684800000,1375315200000 --ylim -20,35 --title "global temperature in Paris" --xlabel date --ylabel temperature` |
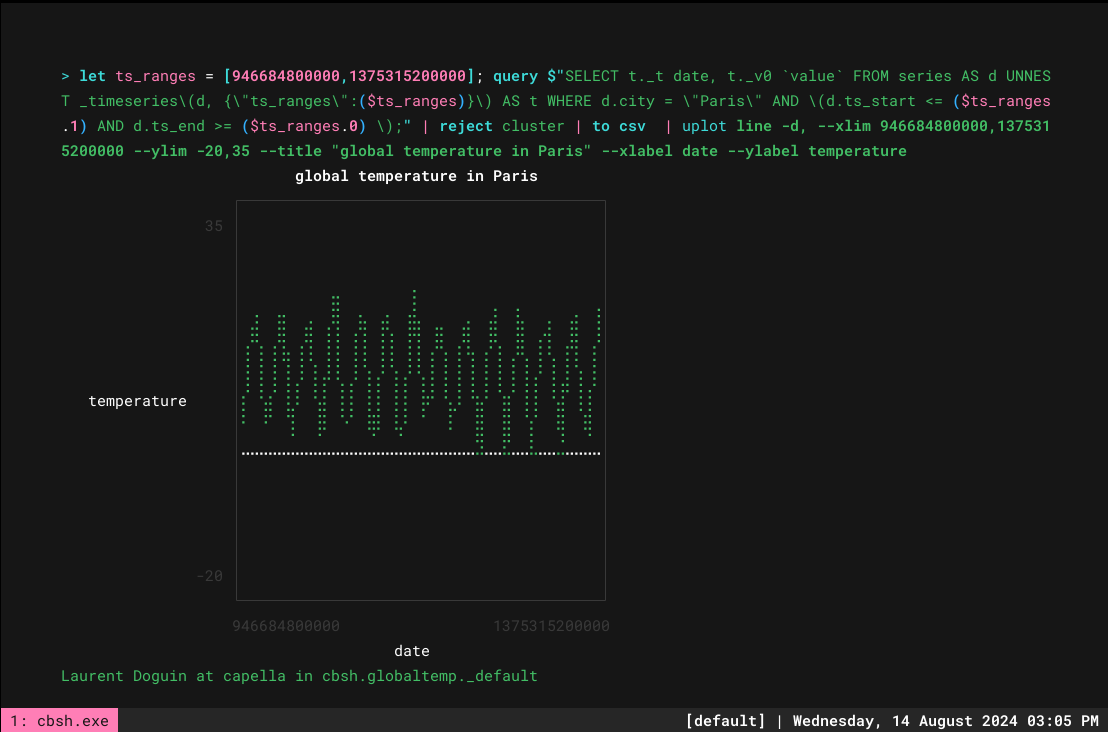
Tudo isso é ótimo, mas o ideal é que eu queira ter várias cidades para compará-las. Todas as colunas CSV adicionais são coletadas automaticamente, desde que você execute linhas do youplot. Fazendo as coisas gradualmente, vamos começar com o suporte de várias cidades na consulta. Portanto, algumas alterações aqui:
-
- agrupamento dos dados por tempo
- adicionando d.city IN ($city) na cláusula where. Isso funciona porque a matriz de cidades é um literal String de uma matriz JSON. Vamos dar uma olhada na resposta como um documento JSON:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
> let ts_ranges = [946684800000,1375315200000]; let city = ['"Aba"','"Berlin"','"London"','"Paris"']; query $"SELECT t._t date, \( ARRAY_AGG\({\"city\": d.city, \"temp\":t._v0}\) \) FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t WHERE d.city IN ($city) AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \) GROUP BY t._t ORDER BY t._t;" | reject cluster | first |to json [ { "date": "2000-01-01", "$1": [ { "city": "Aba", "temp": 26.985000000000007 }, { "city": "Berlin", "temp": 1.3239999999999998 }, { "city": "London", "temp": 4.6930000000000005 }, { "city": "Paris", "temp": 3.845 } ] } ] |
Mas isso não pode se transformar em um CSV, mesmo que você achate tudo dessa forma:
|
1 2 3 4 5 6 7 |
> let ts_ranges = [946684800000,1375315200000]; let city = ['"Aba"','"Berlin"','"London"','"Paris"']; query $"SELECT t._t date, \( ARRAY_AGG\({\"city\": d.city, \"temp\":t._v0}\) \) FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t WHERE d.city IN ($city) AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \) GROUP BY t._t ORDER BY t._t;" |reject cluster | first |flatten|flatten|to csv date,city,temp 2000-01-01,Aba,26.985000000000007 2000-01-01,Berlin,1.3239999999999998 2000-01-01,London,4.6930000000000005 2000-01-01,Paris,3.845 |
Portanto, podemos transformá-lo em um objeto da seguinte forma: Objeto v.city : v.temp FOR v IN ARRAY_AGG({"city": d.city, "temp":t._v0}) when v IS NOT MISSING END
|
1 2 3 4 5 6 7 8 9 10 11 12 |
> let ts_ranges = [946684800000,1375315200000]; let city = ['"Aba"','"Berlin"','"London"','"Paris"']; query $"SELECT t._t date, \( Object v.city : v.temp FOR v IN ARRAY_AGG\({\"city\": d.city, \"temp\":t._v0}\) when v IS NOT MISSING END\) FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t WHERE d.city IN ($city) AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \) GROUP BY t._t ORDER BY t._t;" |reject cluster | first | to json { "date": "2000-01-01", "$1": { "Aba": 26.985000000000007, "Berlin": 1.3239999999999998, "London": 4.6930000000000005, "Paris": 3.845 } } |
Que agora pode ser transformado em um CSV:
|
1 2 3 4 5 |
> let ts_ranges = [946684800000,1375315200000]; let city = ['"Aba"','"Berlin"','"London"','"Paris"']; query $"SELECT t._t date, \( Object v.city : v.temp FOR v IN ARRAY_AGG\({\"city\": d.city, \"temp\":t._v0}\) when v IS NOT MISSING END\) FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t WHERE d.city IN ($city) AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \) GROUP BY t._t ORDER BY t._t;" |reject cluster | first | flatten| to csv date,Aba,Berlin,London,Paris 2000-01-01,26.985000000000007,1.3239999999999998,4.6930000000000005,3.845 |
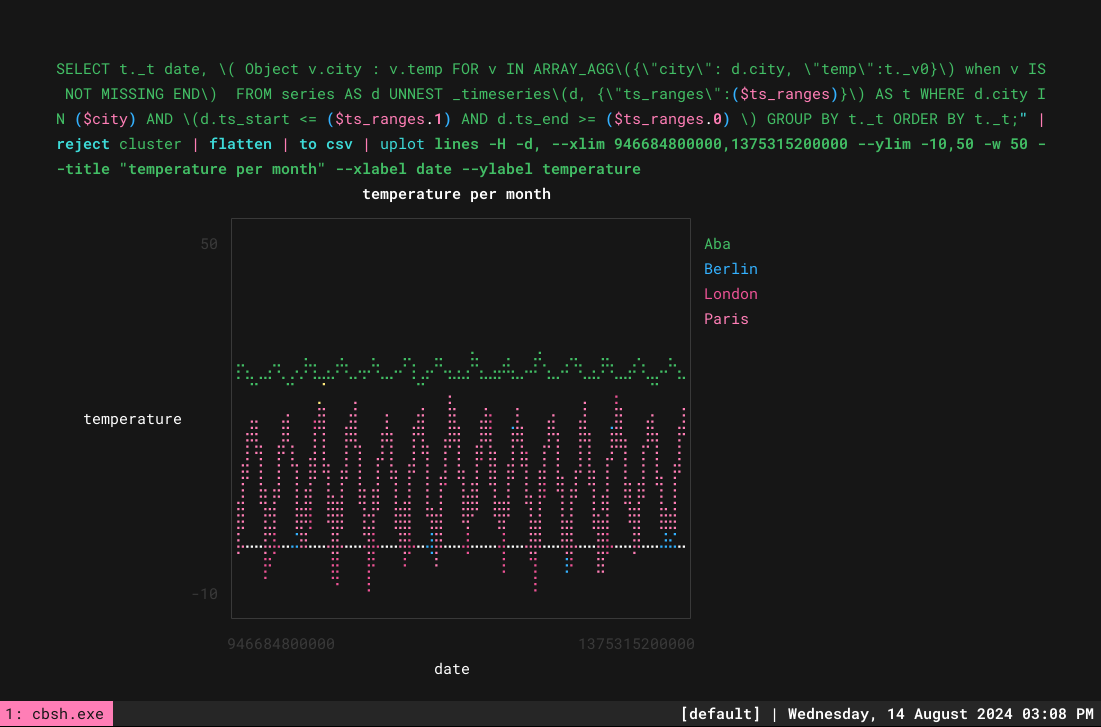
E, com isso, estamos prontos para traçar várias linhas:
|
1 |
> let ts_ranges = [946684800000,1375315200000]; let city = ['"Aba"','"Berlin"','"London"','"Paris"']; query $"SELECT t._t date, \( Object v.city : v.temp FOR v IN ARRAY_AGG\({\"city\": d.city, \"temp\":t._v0}\) when v IS NOT MISSING END\) FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t WHERE d.city IN ($city) AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \) GROUP BY t._t ORDER BY t._t;" |reject cluster | flatten | to csv | uplot lines -H -d, --xlim 946684800000,1375315200000 --ylim -10,50 -w 50 --title "temperature per month" --xlabel date --ylabel temperature |
Para facilitar isso, você pode usar funções. Criar uma .nu arquivo, como temp.nucom o seguinte conteúdo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def tempGraph [$ts_ranges, $cities] { cb-env bucket cbsh cb-env scope globaltemp cb-env collection series let query = ($"SELECT t._t date, \( Object v.city : v.temp FOR v IN ARRAY_AGG\({\"city\": d.city, \"temp\":t._v0}\) when v IS NOT MISSING END\)" + $" FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t " + $" WHERE d.city IN ($city) " + $" AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \)" + $" GROUP BY t._t ORDER BY t._t;" ) let csv = query $query |reject cluster | flatten | to csv $csv | uplot lines -H -d, --xlim 946684800000,1375315200000 --ylim -10,50 -w 50 --title "temperature per month" --xlabel date --ylabel temperature } |
Então, se você o adquirir, ele se tornará muito mais fácil de usar:
|
1 2 3 |
> source ./testingcbshell/temp.nu > tempGraph [946684800000,1375315200000] ['"Aba"','"Berlin"','"London"','"Paris"'] |
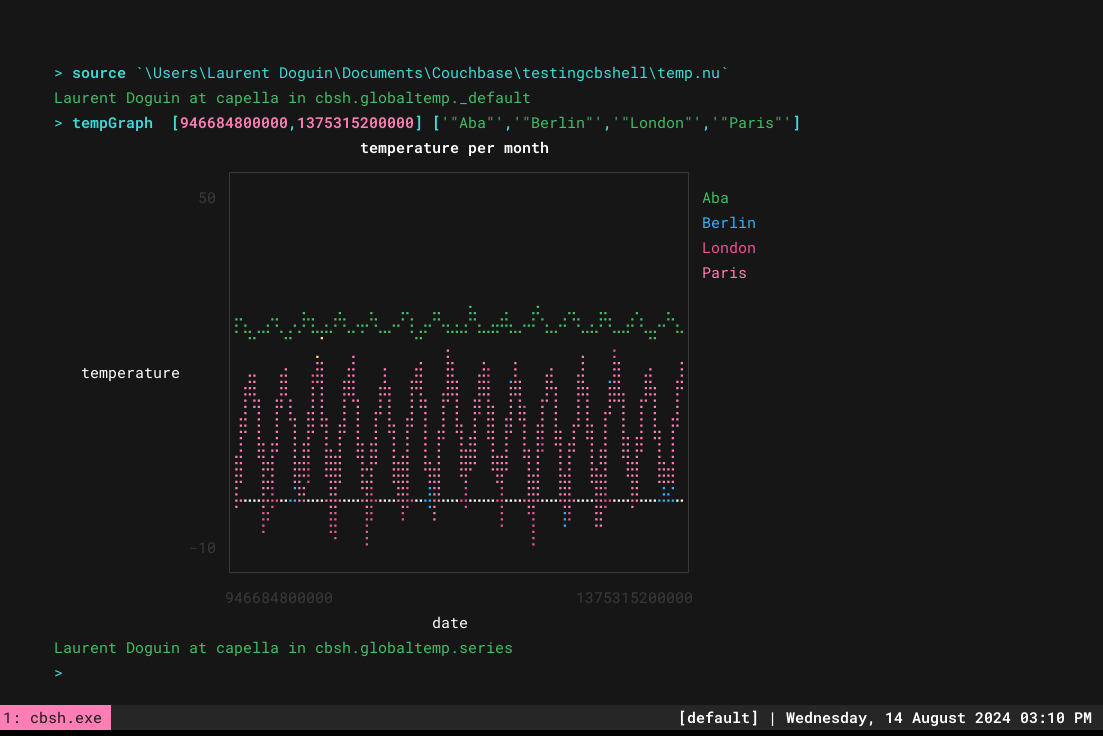
Espero que isso tenha lhe dado uma rápida visão geral do suporte a séries temporais do Couchbase, da manipulação de dados do Couchbase Shell e de como você pode usar outros comandos do shell, como youplot para tornar as coisas mais integradas e interessantes. Você poderia facilmente gerar um relatório completo em vários formatos a partir de um Ações do GitHub por exemplo, infinitas possibilidades!
-
- Leia mais postagens sobre Shell do Couchbase.