O Couchbase é uma plataforma de dados corporativos que permite o desempenho em escala, combinando uma arquitetura exclusiva que prioriza a memória com o N1QL - que combina a agilidade do SQL com o poder do JSON - entre outros recursos incorporados, como pesquisa de texto completo, eventos, análise e indexação secundária global.
As empresas que visam proporcionar uma experiência de usuário moderna, confiável e personalizada em suas ofertas de tecnologia geralmente provisionam vários clusters de nós do Couchbase. Esses diferentes clusters oferecem o mesmo desempenho em escala em diferentes verticais, casos de uso e sistemas de missão crítica, além de simplesmente ter clusters adicionais que servem como mecanismos de backup/recuperação de desastres. Embora a interface de usuário intuitiva do Couchbase permita o gerenciamento fácil e contínuo dos clusters e dos buckets de dados, oferecendo vários recursos de um clique para as diversas tarefas de manutenção e administração (ou seja, reequilíbrio, adição de um nó, failover etc.), está se tornando cada vez mais importante ter uma visão holística de todo o ecossistema do Couchbase. Isso é especialmente verdadeiro nos casos em que uma determinada organização implanta vários clusters para geolocalização de dados ou para oferecer suporte a vários microsserviços que abrangem diferentes segmentos, centros de custo ou verticais.
Primeiros passos: Exportação de métricas de desempenho
Usando Exportador do Couchbase (que foi desenvolvido por nosso parceiro comunitário Laboratórios TOTVS) em combinação com Prometeue GrafanaAgora é possível exportar as principais métricas de desempenho de um ou mais clusters e visualizar seus vários aspectos de desempenho por meio de um painel gráfico. O instantâneo a seguir ilustra um exemplo de painel de monitoramento para 2 clusters do Couchbase:
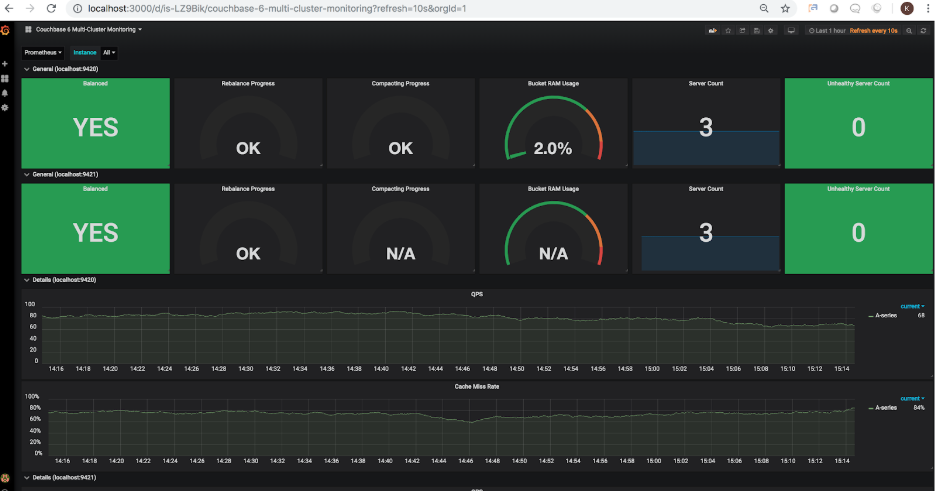
Abaixo estão as instruções detalhadas sobre como instalar e configurar o Couchbase Exporter, o Prometheus e o Grafana:
Primeiro, vamos começar instalando os componentes de código aberto necessários para que tudo isso funcione.
Exportador do Couchbase
Instale o Couchbase Exporter clonando o repositório do GitHub https://github.com/totvslabs/couchbase-exporter e construindo a partir do código-fonte, ou baixando o binário da versão mais recente de https://github.com/totvslabs/couchbase-exporter/releases - Depois de instalado, um processo separado do Couchbase Exporter precisa ser executado para cada cluster do Couchbase Server a ser monitorado usando a seguinte sintaxe:
|
1 |
./couchbase-exportador --couchbase.nome de usuário Administrador --couchbase.senha senha --web.ouvir-endereço=":9420" --couchbase.url="http://52.38.xx.xx:8091" |
Por padrão, o Couchbase Exporter será executado na porta 9420 e tentará se conectar ao Servidor Couchbase em execução em http://localhost:8091No entanto, para a maioria dos usuários, é melhor especificar um número de porta livre, bem como o cluster do Couchbase em questão explicitamente (o endereço IP de qualquer nó de um cluster existente será suficiente). Para os fins deste tutorial, executarei duas instâncias do Couchbase Exporter em dois clusters do AWS EC2 Demo localizados, no momento da redação deste artigo, em 52.38.xx.xx e 52.40.xx.xx. A segunda instância do Couchbase Exporter é iniciada usando o seguinte:
|
1 |
$ ./couchbase-exportador --couchbase.nome de usuário Administrador --couchbase.senha senha --web.ouvir-endereço=":9421" --couchbase.url="http://52.40.xx.xx:8091" |
Aqui estão as capturas de tela da execução dessas duas instâncias do Couchbase Exporter. Observação essas instâncias agora estão sendo executadas em http://localhost:9420 e http://localhost:9421, respectivamente. Esses dois URLs serão usados posteriormente para configurar o Prometheus.


Prometeu
Instale o Prometheus com o método de instalação de sua preferência, seguindo as etapas descritas em https://prometheus.io/docs/prometheus/latest/installation/ - Depois de instalado, agora você pode editar o arquivo prometheus.yml que está disponível no mesmo diretório do binário do Prometheus. Esse arquivo YAML precisa ser modificado para especificar os destinos do Couchbase Exporter que foram configurados na etapa 1. Neste exemplo, modificaremos a seção scrape_configs do arquivo YAML da seguinte forma:
|
1 2 3 4 5 6 7 8 9 |
scrape_configs: # O nome do trabalho é adicionado como um rótulo `job=` a qualquer série temporal extraída dessa configuração. - nome_do_emprego: 'couchbase' # metrics_path tem como padrão '/metrics' O padrão do esquema # é "http". static_configs: - alvos: ['localhost:9420', 'localhost:9421'] |
Depois que a seção scrape_configs for modificada para apontar para as instâncias do Couchbase Exporter, poderemos iniciar o Prometheus da seguinte forma:
|
1 |
$. /prometeu --configuração.arquivo=prometeu.yml |
Agora o Prometheus deve ser iniciado e acessível pela porta 9090 (ou seja http://localhost:9090)
Grafana
Instale o Grafana com o método de instalação de sua preferência, seguindo as etapas descritas em http://docs.grafana.org/installation/ - Depois de instalado, você deve ser capaz de iniciar o Grafana (ou seja $ sudo serviço grafana-servidor iniciar ) e acessá-lo na porta 3000 (ou seja http://localhost:3000) - O nome de usuário e a senha padrão são admin/administradorNo entanto, é altamente recomendável definir essas credenciais de acordo com a política de segurança de sua organização.
Agora que o Grafana foi instalado e iniciado, vamos adicionar e configurar a fonte de dados do Prometheus da seguinte forma:
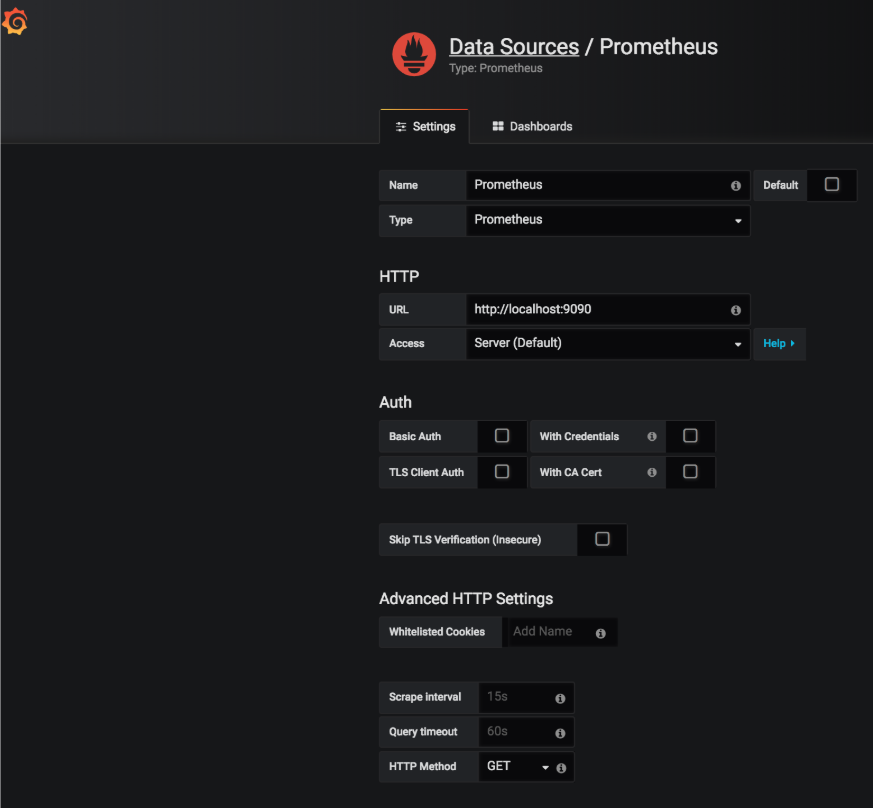
Visualizando as métricas de desempenho:
Agora que o Couchbase Exporter, o Prometheus e o Grafana foram instalados e configurados corretamente, vamos importar um exemplo de painel do Grafana usando o este exemplo de JSON. Este é um exemplo de painel apenas para fins ilustrativos e não constitui uma recomendação sobre quais métricas devem ser monitoradas para o seu caso de uso específico. É provável que sua organização precise de um painel personalizado com métricas específicas do Couchbase relevantes para o seu caso de uso individual e, portanto, este exemplo não se encaixa necessariamente nessa finalidade específica.
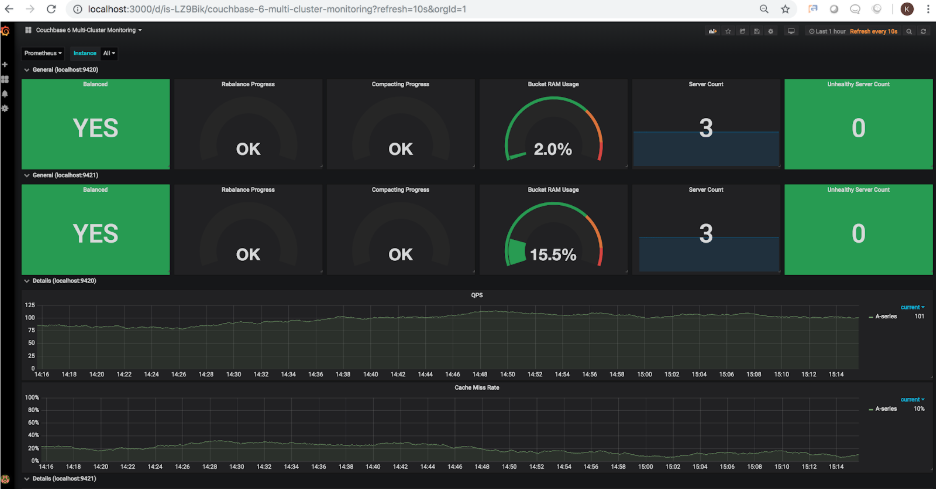
Depois que o painel for importado, você poderá carregá-lo no Grafana. A captura de tela a seguir mostra o estado dos dois clusters configurados na etapa 1.
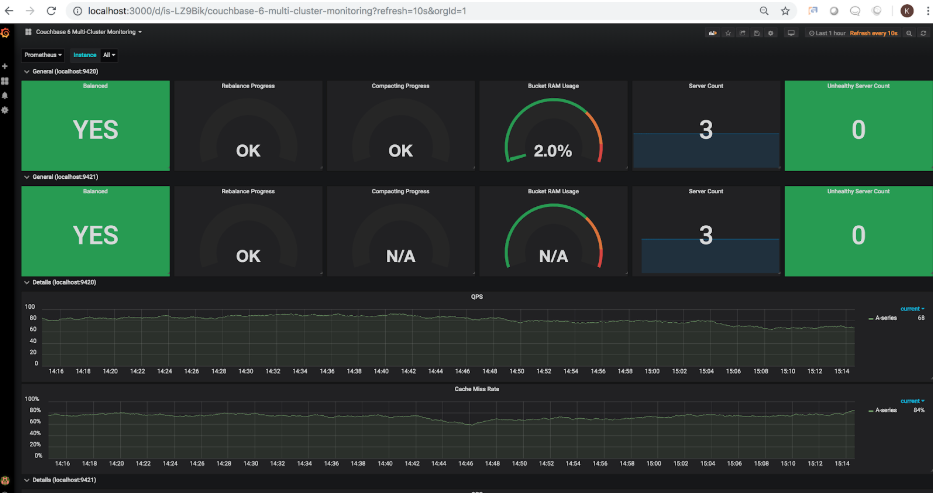
Você deve ter notado que o uso de RAM do bucket para o segundo cluster está mostrando N/A. Isso reflete corretamente o fato de que o segundo cluster não tem nenhum bucket no momento. Vamos adicionar exemplos de buckets a esse cluster. Uma vez adicionados, o painel é atualizado para mostrar o uso atualizado da RAM do bucket em 15,5% (essa porcentagem varia de acordo com a RAM alocada ao cluster):
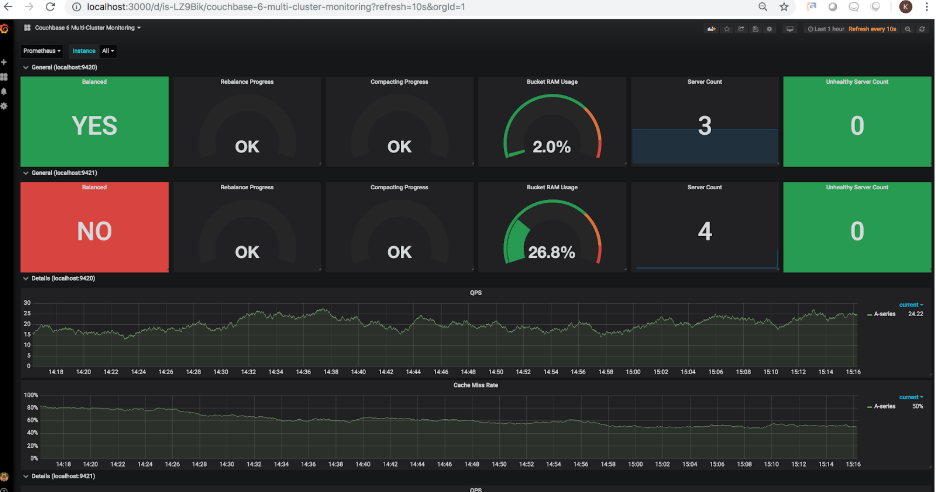
Cada cluster foi inicialmente configurado para ter 3 nós. Vamos adicionar um quarto nó ao segundo cluster. Quando um nó for adicionado, o painel atualizado mostrará o seguinte:
Como o quarto nó foi adicionado e o cluster não foi rebalanceado, o servidor A contagem foi atualizada para mostrar 4 nós no total, no entanto, o status do rebalanceamento é mostrando corretamente que o rebalanceamento não foi concluído. Vamos em frente e acionar um rebalanceamento. Quando o rebalanceamento é acionado por meio da interface do usuário do Couchbase, o O painel mostrará o seguinte:
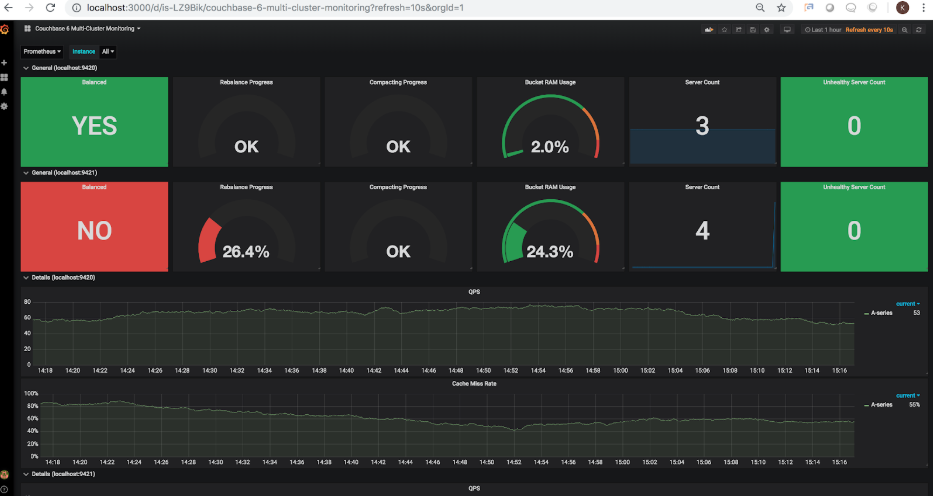
Como você pode ver, o indicador de rebalanceamento agora está mostrando o progresso de 26,4%. Quando o o rebalanceamento estiver concluído, o painel atualizado mostrará o seguinte:
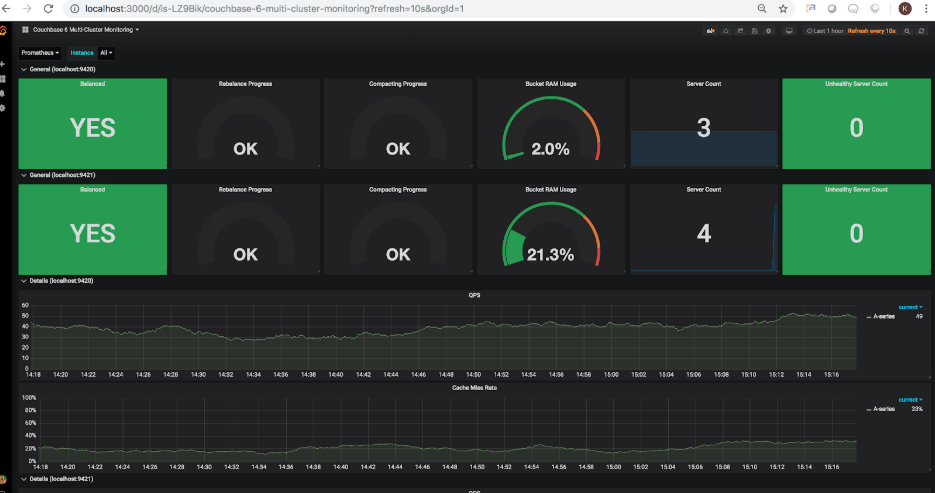
O rebalanceamento está concluído e você pode notar agora que o uso de RAM do bucket mostra 21,3%, para refletir a capacidade do nó adicional que está sendo adicionada ao cluster, reduzindo, portanto, o uso geral real dos 3 buckets de amostras.
Recapitulação:
Neste blog, instalamos o Prometheus, o Grafana e o Couchbase Exporter para monitorar vários clusters do Couchbase. O painel do Grafana permite monitorar visualmente as principais métricas e indicadores de desempenho dos clusters do Couchbase Server em um local central. Além disso, o Prometheus permite a configuração de regras de alerta que enviam notificações a um usuário ou a uma lista de e-mails sobre determinadas condições quando uma determinada métrica cai ou ultrapassa um determinado limite.
Abaixo estão os recursos usados neste blog:
- Fonte do exportador do Couchbase
- Binários do exportador do Couchbase
- Prometeu
- Grafana
- Exemplo de regras do Couchbase para o Prometheus
Ótimo artigo, obrigado!
Também escrevi um exportador para o Couchbase que acho que pode ser do seu interesse. Ele extrai todas as métricas da API do Couchbase, até mesmo o XDCR, e adicionei a configuração de amostra do Prometheus e do Grafana.
O exportador ainda precisa de alguns pequenos aprimoramentos, mas está pronto para ser usado:
https://github.com/leansys-team/couchbase_exporter
E a versão do Docker:
https://hub.docker.com/r/blakelead/couchbase-exporter
Por favor, dê uma olhada, acho que vale seu tempo (e o meu, eu adoraria receber feedback :))
Ótimo artigo para começar a monitorar com o Prometheus. Obrigado por compartilhar!
Este artigo cobriu muito bem a parte da integração, mas deixou de lado a escalabilidade, a alta disponibilidade, a recuperação de falhas, as personalizações e o escopo de automação dessa integração, que são aspectos importantes da criação de soluções de ferramentas de monitoramento.
Tentamos discutir todos eles no artigo mencionado a seguir.
http://medium.com/@ashishrana160796/dissecting-the-couchbase-monitoring-integration-with-prometheus-and-grafana-55f7d460f37
Por favor, dê uma olhada. Espero que valha a pena seu tempo. Além disso, adoraria receber seu feedback sobre as soluções desenvolvidas.
#automação #couchbase #prometheus #grafana #monitoramento #alerting #escalabilidade #opensourcedevelopment
Link atualizado para o artigo e nossa análise dessa ferramenta de integração: https://hackernoon.com/dissecting-the-couchbase-monitoring-integration-with-prometheus-and-grafana-ge1v6263t
A retransmissão do artigo ajuda a obter mais detalhes sobre o que está acontecendo no cluster.
Configurei isso em meu cluster. Temos um cluster de 3 nós
1 (Índice) Nó
2 (Dados, consulta e pesquisa) Nó.
Quais métricas devo verificar por nó e quais métricas devem ser verificadas em todo o cluster???