O conceito de consolidação é simples, e a aplicação de seus princípios pode trazer imensos benefícios para qualquer organização. Mas o que significa consolidação no contexto da tecnologia de banco de dados?
O Google define consolidação como "a ação ou o processo de combinar várias coisas em um único conjunto mais eficaz ou coerente".
Quando aplicada a bancos de dados, a consolidação pode significar algumas coisas para uma determinada organização:
-
- Reduzir o número de tecnologias diferentes que gerenciam dados.
- Reduzir a redundância desnecessária de dados, ou seja, várias cópias dos mesmos dados.
Um exemplo simples do problema pode ser uma empresa que armazena exatamente os mesmos dados de clientes em três bancos de dados diferentes. Por exemplo, um operacional banco de dados para gerenciamento de vendas, um análises banco de dados para inteligência de negócios e um armazenamento em cache para logins mais rápidos de clientes em um aplicativo da Web corporativo. Em cada um desses bancos de dados, há replicação de dados para failover e recuperação de desastres, exacerbando a inflação geral de dados.
Os líderes técnicos da organização sabem que estão criando redundâncias que tornam as coisas mais complicadas, mas optam por conviver com essa complexidade e esse custo porque acreditam que não há um único banco de dados que possa atender a essas três finalidades. À medida que essas concessões são feitas repetidamente para mais aplicativos, a pegada de dados aumenta até o ponto em que muitas organizações se veem pagando taxas de armazenamento exorbitantes e perdendo o controle da quantidade de dados que possuem. Bem-vindo ao desagradável mundo do dispersão de dados!
A dor da dispersão de dados
A proliferação de dados cria um ambiente complicado de sistemas pouco integrados que consomem tempo para serem gerenciados, incorrem em altos custos de armazenamento, aumentam os riscos de segurança e causam uma perda geral de eficiência, levando muitas organizações a tornar sua eliminação uma prioridade.
De fato, o Google apresenta o seguinte como um uso adequado da palavra consolidação em uma frase: "uma consolidação de dados em uma empresa". É digno de nota o fato de o Google ter optado por usar "consolidação de dados" como exemplo, enfatizando que essa é uma meta comum a muitas organizações. Por que é uma meta atraente? Porque há benefícios claros na consolidação do banco de dados. Ao reduzir as diferentes camadas de tecnologia de banco de dados em sua pilha, você reduz a complexidade, pois há menos coisas para gerenciar, e reduz os custos, pois o espaço ocupado pelos dados é menor.
Porém, com todos os diferentes sistemas, formatos de dados e padrões de acesso implementados para alimentar os aplicativos corporativos, como uma organização pode reduzir a dispersão de dados e, ao mesmo tempo, fornecer as funcionalidades específicas que seus aplicativos exigem? Vamos explorar isso com mais detalhes!
Bem, como chegamos até aqui?
Há muitas coisas que causam uma proliferação insustentável de tecnologias de banco de dados em uma organização: fusões e aquisições, requisitos de retenção de dados legados, falta de padrões formais de tecnologia corporativa e uma melhor da raça cultura tecnológica que promove o uso apenas das ferramentas mais personalizadas para um determinado requisito, em vez de um conjunto consolidado de ferramentas multiuso.
Essas condições existem em muitas organizações, algumas planejadas, outras não, mas todas contribuem para uma pilha confusa de bancos de dados de finalidade única e cópias intermináveis dos mesmos dados, o que aumenta os custos e, em última análise, atrasa os negócios.
Vamos examinar alguns dos tipos de bancos de dados e suas funcionalidades específicas, que normalmente são necessários para alimentar os aplicativos modernos de uma empresa.
Tipos de bancos de dados
Bancos de dados relacionais
Os bancos de dados relacionais suportam nativamente o SQL com junções, agregações e Transações ACIDOs bancos de dados são os principais pilares dos aplicativos e sistemas operacionais. Eles são excelentes para armazenar dados altamente estruturados e fornecer consistência forte, mas essas características trazem rigidez porque o modelo de dados é fixo e definido por um esquema estático. Portanto, para alterar o modelo de dados, os desenvolvedores precisam modificar o esquema, o que pode retardar o desenvolvimento. Além disso, os bancos de dados relacionais não foram criados para escala maciça e, portanto, o desempenho tende a se degradar à medida que os aplicativos crescem. Devido à sua onipresença em aplicativos operacionais legados, as organizações geralmente têm muitos bancos de dados relacionais em seu ecossistema para atender a funções como o processamento de transações.
Bancos de dados de documentos NoSQL
Os bancos de dados de documentos NoSQL não têm esquema e armazenam dados como documentos JSON em vez de tabelas de linhas e colunas. Os bancos de dados de documentos NoSQL também são projetados para o processamento de dados distribuídosem que um único banco de dados abrange vários nós para formar um cluster de processamento de dados. Isso torna os bancos de dados NoSQL inerentemente escalonáveis, permitindo que os dados sejam processados em uma arquitetura distribuída - se um nó ficar inoperante, os outros o substituirão.
Além disso, o JSON é o padrão de fato para o consumo e a produção de dados para aplicativos móveis, o que o torna ideal para o desenvolvimento sem rigidez relacional, porque o JSON deixa a cargo dos aplicativos e serviços e, portanto, dos desenvolvedores a forma como os dados devem ser modelados. Se o desenvolvimento do seu aplicativo segue o modelo de domínio e você deseja ter flexibilidade para desenvolver aplicativos sem a sobrecarga da rigidez relacional, um banco de dados de documentos JSON NoSQL é uma ótima opção. Muitas organizações adotam bancos de dados de documentos NoSQL como um meio de dimensionar seus aplicativos.
Isso artigo fornece mais detalhes sobre as diferenças entre os bancos de dados relacionais e NoSQL.
Bancos de dados de chave-valor / na memória
Um banco de dados de valores-chave armazena dados como uma coleção de pares de valores-chave em que cada chave exclusiva está associada a um valor de dados específico. O formato dos dados é simples para facilitar a velocidade, e muitos bancos de dados de valor-chave também são executados em cache na memória para maximizar o desempenho. A velocidade e a eficiência dos bancos de dados de valor-chave os tornam uma boa opção para necessidades simples de armazenamento e recuperação de dados quando o foco está no alto desempenho, e muitas organizações adicionam um banco de dados de valor-chave à sua pilha de tecnologia de aplicativos para proporcionar uma experiência mais rápida aos usuários.
Bancos de dados de pesquisa de texto completo
Um banco de dados de pesquisa de texto completo usa um índice de pesquisa para examinar todo o texto em documentos armazenados para corresponder aos critérios de pesquisa (ou seja, texto especificado por um usuário). A pesquisa de texto completo geralmente se concentra em campos de texto longos em documentos, como descrições, resumos ou comentários, usando índices pré-organizados para tornar a recuperação mais rápida do que a varredura tradicional de bancos de dados baseada em campos. Muitas organizações adicionam um banco de dados de pesquisa de texto completo à sua pilha de tecnologia de aplicativos para fornecer recursos e funcionalidades de pesquisa.
Bancos de dados de pesquisa de vetores
Os bancos de dados de pesquisa vetorial utilizam algoritmos de vizinho mais próximo para recuperar os registros que mais se aproximam de um determinado critério de pesquisa. Em um banco de dados de pesquisa vetorial, texto, imagens, áudio e vídeo são convertidos em representações matemáticas chamadas vetores, que são indexadas e usadas para pesquisas semânticas. Dessa forma, um pesquisa vetorial encontra informações relacionadas com base no significado da consulta de pesquisa, não apenas nas palavras e frases inseridas, o que o torna a melhor opção para apresentar informações relevantes que se conectam com os usuários.
A pesquisa vetorial também torna os resultados da IA generativa mais precisos e pessoais, permitindo a RAG (Retrieval Augmented Generation, geração aumentada de recuperação), em que dados suplementares são transmitidos junto com prompts para fornecer melhor precisão e contexto para as respostas do LLM. Devido à expectativa de recursos de IA nos aplicativos modernos, muitas organizações adicionam um banco de dados de pesquisa vetorial à sua pilha de tecnologia de aplicativos para potencializar a pesquisa semântica e os recursos e a funcionalidade baseados em IA generativa.
Bancos de dados analíticos colunares
Um banco de dados analítico colunar é projetado para acelerar a recuperação de resultados de consultas analíticas complexas. Diferentemente dos bancos de dados tradicionais baseados em linhas, que armazenam e recuperam dados em linhas, os bancos de dados colunares organizam os dados verticalmente, agrupando e armazenando os valores de cada coluna juntos. Essa arquitetura aprimora a compactação de dados e minimiza as operações de E/S, resultando em um desempenho de consulta mais rápido e em uma análise de dados aprimorada. Os bancos de dados colunares são especialmente adequados para cargas de trabalho analíticas que envolvem consultas e agregações complexas em grandes conjuntos de dados. Eles são excelentes em cenários em que as operações de leitura pesada, como relatórios e análise de dados, são mais frequentes do que as operações de gravação. Muitas organizações adicionam um banco de dados analítico colunar à sua pilha de tecnologia de aplicativos para potencializar os aplicativos de business intelligence e análise de dados.
Bancos de dados de séries temporais
Um banco de dados de séries temporais armazena e processa dados em pares associados de tempo e valor. Os dados de séries temporais são comuns em aplicativos de IoT, em que sensores e medidores registram leituras em intervalos de tempo regulares e enviam as informações para o banco de dados. A complexidade dos dados de séries temporais está no processamento adequado dos dados, mesmo quando as leituras podem não vir em uma sequência linear baseada no tempo. Por exemplo, em ambientes distribuídos com muitos dispositivos de IoT em operação, as leituras podem ser gravadas no banco de dados fora da ordem cronológica, e a funcionalidade de série temporal do banco de dados reconcilia isso para manter a consistência e a precisão dos dados. Muitas organizações adicionam um banco de dados de séries temporais à sua pilha de tecnologia de aplicativos para habilitar os aplicativos de IoT.
Bancos de dados gráficos
Um banco de dados de gráficos é criado para armazenar e gerenciar dados interconectados, representando dados como nós (entidades) e bordas (relacionamentos), formando uma estrutura de gráficos. Cada nó armazena atributos, enquanto as bordas definem conexões e propriedades entre os nós. Esse design torna os bancos de dados de gráficos ideais para lidar com relacionamentos complexos que envolvem conexões, como redes sociais, sistemas de recomendação e gráficos de conhecimento. Diferentemente dos bancos de dados relacionais tradicionais, os bancos de dados de gráficos são excelentes para percorrer relacionamentos, permitindo consultas mais rápidas e intuitivas e resultados mais precisos. Além disso, os bancos de dados de grafos são ideais para o Retrieval Augmented Generation (RAG), em que as relações de dados podem ser transmitidas com prompts para fornecer melhor precisão e contexto para respostas generativas de IA/LLM. Muitas organizações adicionam um banco de dados de gráficos à sua pilha de tecnologia de aplicativos para ajudar a potencializar os recursos de IA em seus aplicativos.
Bancos de dados incorporados
Um banco de dados incorporado é um sistema de banco de dados autônomo integrado diretamente em uma base de código de aplicativo, eliminando a necessidade de um servidor de banco de dados separado. O processamento de dados incorporado oferece acesso mais rápido aos dados e elimina a dependência da Internet para o acesso aos dados. Os bancos de dados incorporados são comumente usados em aplicativos móveis e de IoT em que se espera uma falta intermitente ou prolongada de conectividade de rede, como em serviços de campo ou outros casos de uso que operam regularmente fora do alcance das redes. Um componente essencial de um banco de dados incorporado é a capacidade de sincronizar dados com bancos de dados centralizados, bem como com outros clientes de bancos de dados incorporados, o que é importante para manter a integridade e a consistência dos dados.
A persistência poliglota não é a abordagem adequada
Observando a lista de diferentes tipos de bancos de dados e os padrões de acesso específicos que eles permitem, é fácil ver como uma organização adotaria vários bancos de dados.
Suponha que uma empresa tenha um aplicativo da Web de comércio eletrônico. Para gerenciar os estoques e alimentar as transações, ela pode começar com um banco de dados relacional. Mas como os bancos de dados relacionais não podem ser dimensionados, eles podem adicionar um banco de dados de cache de valor-chave na memória para acelerar o desempenho. À medida que o aplicativo cresce, talvez eles queiram implantar uma arquitetura distribuída na nuvem para aumentar a escala e, assim, adicionar um banco de dados de documentos NoSQL. Em seguida, para potencializar a pesquisa no aplicativo, eles podem adicionar um banco de dados de pesquisa. E, à medida que procuram aproveitar a IA para fazer ofertas e recomendações atraentes para os usuários do aplicativo, podem adotar um banco de dados de pesquisa de vetores e um banco de dados de gráficos. Em seguida, ao lançar a versão móvel do aplicativo, poderá adotar um banco de dados incorporado. E, por fim, para analisar os dados dos clientes, pode adicionar um banco de dados analítico colunar. Essa abordagem é conhecida como persistência poliglota que a TechTarget define como:
... um termo conceitual que se refere ao uso de diferentes abordagens e tecnologias de armazenamento de dados para dar suporte aos requisitos exclusivos de armazenamento de vários tipos de dados que residem nos aplicativos corporativos.
Embora a abordagem faça sentido no papel - use a melhor ferramenta para o trabalho - quando você considera as várias camadas de processamento de dados e a replicação para failover e DR inerentes a cada banco de dados, é possível ver como a pegada de dados cresce exponencialmente com cada sistema adicionado.
O ambiente resultante é caro e difícil de manter, e pode sair rapidamente do controle se não for tratado adequadamente.
Os benefícios da consolidação do banco de dados
Embora as desvantagens da proliferação de bancos de dados e da dispersão de dados se tornem óbvias ao serem examinadas, os benefícios da consolidação desse ambiente se tornam igualmente evidentes.
Quando você reduz camadas diferentes de tecnologia de banco de dados em sua pilha, você:
-
- Reduzir a complexidade porque há menos coisas para gerenciar.
- Reduzir os custos porque sua pegada de dados é menor.
- Aumente a eficiência, pois um número menor de fontes de dados facilita o desenvolvimento e a evolução mais rápida dos aplicativos.
Mas como consolidar seus bancos de dados sem perder sua funcionalidade essencial? Com o banco de dados certo.
Couchbase Capella: o banco de dados multiuso
Couchbase Capella é um DBaaS NoSQL moderno e totalmente gerenciado que oferece flexibilidade de documentos JSON, desempenho na memória, recursos de nível empresarial e recursos comprovados de IoT e móveis off-line, tudo isso com o menor custo total de propriedade.
O Capella é multifuncional e, portanto, adequado para substituir arquiteturas de persistência poliglotas, graças à sua ampla variedade de serviços e recursos que fornecem todos os recursos de bancos de dados de finalidade única, combinados em uma única plataforma.
O Couchbase Capella fornece:
-
- Armazenamento distribuído de documentos JSON - O Capella distribui automaticamente os dados entre os nós e clusters para escala e armazena os dados como documentos JSON para flexibilidade de desenvolvimento. Saiba mais sobre a arquitetura distribuída do Capella neste artigo.
- Recursos relacionais - O Capella suporta SQL, incluindo junções e agregações, transações ACID e taxonomias de esquema por meio de escopos e coleções. Leia sobre o suporte a SQL no Capella aqui.
- Valor-chave, em cache de memória - O Capella armazena em cache os dados de valor-chave na memória para obter uma velocidade incrível. Saiba mais sobre os recursos de valor-chave do Capella na seção documentos.
- Pesquisa de texto completo - A Capella fornece recursos de pesquisa de texto completo prontos para uso para potencializar os recursos de pesquisa para aplicativos. Leia sobre os recursos de pesquisa de texto completo da Capella neste artigo.
- Pesquisa vetorial - O Capella inclui a pesquisa vetorial para permitir a pesquisa semântica e o RAG para IA. Leia mais sobre a pesquisa vetorial no Capella aqui.
- Análise colunar - A Capella fornece um armazenamento colunar e uma ampla integração de dados com o Capella DBaaS e outros bancos de dados via Kafka, permitindo análises operacionais em tempo real sem ETL. Saiba mais sobre o serviço Couchbase Analytics neste blog.
- Séries temporais - A Capella oferece suporte a dados de séries temporais para aplicativos de IoT. Para saber mais sobre o suporte a séries temporais da Capella, leia isto blog.
- Travessia de gráficos - Suporte à análise de gráficos para entender as relações entre entidades e fornecer mais contexto para os avisos de IA. Esse blog fornece detalhes sobre os recursos de travessia de gráficos do Couchbase.
- Banco de dados móvel incorporado - O Capella App Services inclui um banco de dados incorporado para aplicativos móveis e de IoT que é executado no dispositivo, eliminando as dependências da Internet. A sincronização integrada com o Capella DBaaS garante que os dados permaneçam consistentes e precisos. Leia mais sobre o Capella App Services aqui.
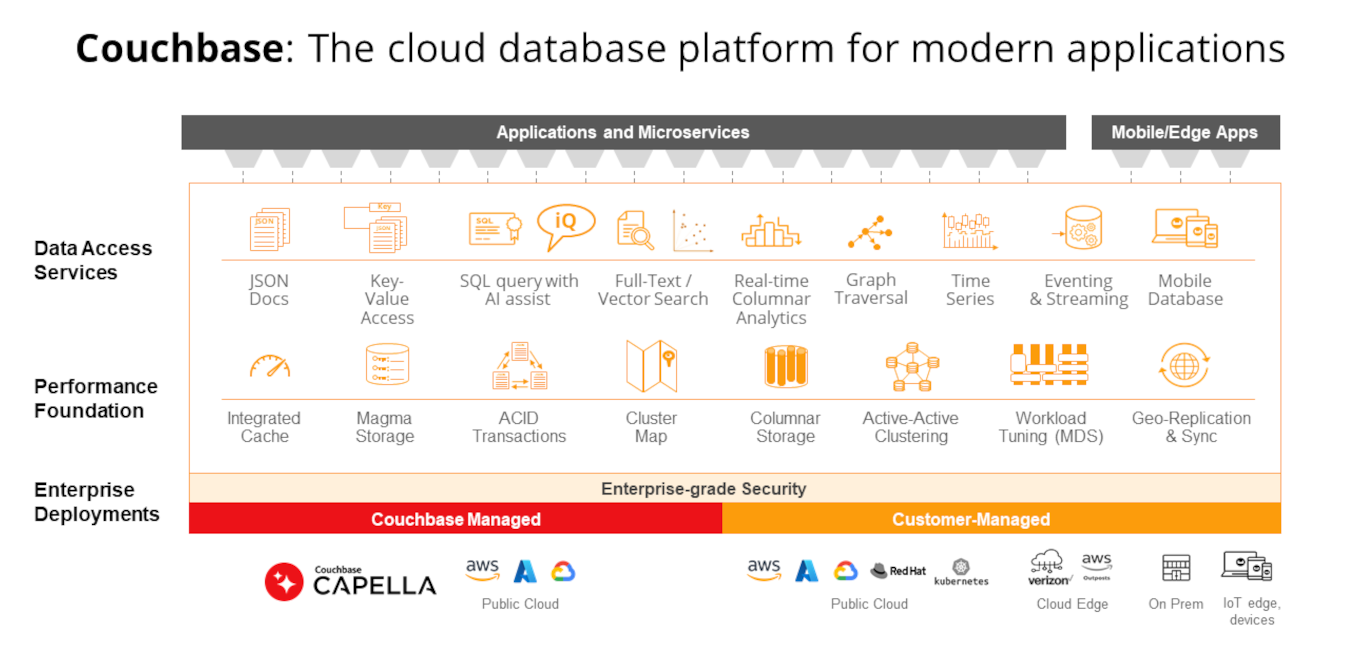
Consolidar no Couchbase Capella
Ao fornecer todos esses recursos em uma única tecnologia de banco de dados, o Couchbase elimina a necessidade de vários bancos de dados específicos de funções, permitindo reduzir drasticamente a pilha de bancos de dados e o espaço total ocupado pelos dados, economizando tempo, armazenamento, esforço e dinheiro.
Viber: benefícios reais da consolidação do banco de dados
Viber fornece chamadas de áudio e vídeo, mensagens e outros serviços de comunicação por meio de seu aplicativo extremamente popular, e eles estão crescendo rapidamente. O Viber usa o Couchbase para processar até 15 bilhões de eventos de chamadas e mensagens por dia. O Couchbase atualiza os perfis de usuário quase em tempo real, proporcionando uma experiência de usuário responsiva. Ao substituir o MongoDB™ (um Banco de dados de documentos NoSQL) e Redis (um banco de dados de valores-chave na memória) Com um Couchbase, o Viber reduziu o número de servidores necessários para alimentar seus aplicativos de 300 para 120 - um Redução 60% com economia maciça de custos.
Consolide sua pilha de bancos de dados com o Couchbase e comece a perceber os benefícios em sua própria organização! Registre-se para receber seu teste gratuito do Couchbase Capella aqui.
