Nesta postagem do blog, daremos uma olhada na API de visualização para pesquisa de texto completo em Couchbase 4.5. Observe que essa API, lançada na versão mais recente do Java SDK (2.2.4), ainda é @Experimental.
Abordaremos o assunto:
- Pesquisa de texto completo no Couchbase?
- A API Java
- Vários tipos de consultas
- Obtendo explicações sobre os acertos
- Conclusão
Essa API experimental pode ser usada com o Couchbase Server 4.5 Developer Preview, desde que você use a API 2.2.4 cliente Java SDK, que você pode obter por meio do Maven. Adicione a seguinte dependência ao seu pom.xml:
|
1 2 3 4 5 |
com.couchbase.cliente java-cliente 2.2.4 |
Pesquisa de texto completo no Couchbase?
Sim! O próximo 4.5 (codinome Watson) incluirá um indexador de texto completo (FTS, também conhecido como CBFT) baseado no software livre Bleve projeto. O Bleve trata de pesquisa de texto completo e indexação em Go (grito para o nosso próprio Marty Schoch por ter iniciado esse projeto).
A ideia é aproveitar o Bleve para fornecer uma pesquisa de texto completo pronta para uso no Couchbase Server, sem a necessidade de usar conectores para software externo (que é executado em seu próprio cluster). Se essa solução pronta para uso não atender totalmente às suas necessidades, é claro que você ainda poderá usar estes conectoresmas, para necessidades mais simples, você pode optar por uma única solução.
O FTS oferece uma série de recursos que são fornecidos pelo Bleve: Analisadores de texto, Tokenizers e filtros de token de pós-processamento que estão além do escopo desta postagem, bem como os vários tipos de consultas que você pode executar nos índices resultantes. Vamos ver quais são esses tipos e como você pode esperar usá-los no contexto do Java SDK.
No restante desta postagem do blog, usaremos três índices que você poderá criar por meio do console administrativo da Web no próximo 4.5 Developer Preview:

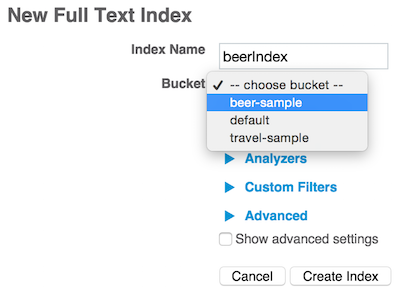
Aqui está a lista de índices na interface do usuário:
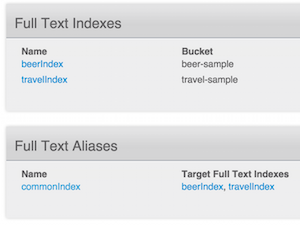
Nós temos:
- a
índice de cervejaque indexa todo o conteúdo de cada documento noamostra de cerveja - a
travelIndexque indexa todo o conteúdo de cada documento noamostra de viagem - um índice de alias,
commonIndexque é uma união dos dois índices acima.
A API Java
O ponto de entrada do recurso de pesquisa de texto completo no Java SDK está no Balde, usando o consulta(SearchQuery ftq) método. Isso é consistente com os métodos de consulta existentes já presentes na API para executar um Consulta ou um N1qlQuery.
A API para pesquisa de texto completo segue o padrão construtor padrão. Identifique o tipo de consulta que você deseja e use o construtor correspondente para construí-la, obtenha o Pesquisa usando construir() e executá-lo usando bucket.query(searchQuery).
Vamos dar um exemplo (muito simples) e ver como ele pode ser consumido:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
//usaremos esse Cluster e Bucket no restante dos exemplos Aglomerado agrupamento = CouchbaseCluster.criar("127.0.0.1"); Balde balde = agrupamento.openBucket("amostra de cerveja"); //usamos uma forma simples de consulta: Pesquisa ftq = MatchQuery.em("beerIndex").partida("nacional").limite(3).construir(); //disparamos a consulta e observamos os resultados Resultado da pesquisa resultado = balde.consulta(ftq); Sistema.fora.println("totalHits: " + resultado.totalHits()); para (SearchQueryRow fila : resultado) { Sistema.fora.println(fila); } |
Se analisarmos cada seção individualmente, veremos o que aconteceu:
- Criamos um
MatchQueryem um único período. - Ele é executado na amostra de cerveja (
.on(beerIndex), procura por ocorrências textuais da palavra "national" (.query("national")) ou termos próximos. - Uma configuração adicional é feita para limitar o número de resultados a 3 (
limite(3)) e a consulta real é criada nesse ponto (.build()). - A consulta é executada (
bucket.query(ftq)) e retorna umResultado da pesquisa. - Emitimos o resultado
totalHits()e linhas individuais (também acessíveis como uma lista por meio dehits()).
A execução desse código gera resultados:
|
1 2 3 4 |
totalHits: 31 Busca de acerto{id='dc_brau', pontuação=0.09068310490562362, fragmentos={}} Busca de acerto{id='brouwerij_nacional_balashi', pontuação=0.12085760187148556, fragmentos={}} Busca de acerto{id='cervecera_nacional', pontuação=0.09863195902067363, fragmentos={}} |
Vemos que o total de acessos nos dá o número real de acessos antes de o limite ser aplicado. O hits() O método retorna 3 SearchQueryRow objetos, conforme solicitado.
Cada acerto contém a chave do documento associado no Couchbase (id()), bem como mais informações sobre a correspondência, por exemplo, uma pontuação para a correspondência (pontuação())... Se quiser, você pode recuperar o documento associado usando bucket.get(row.id()):
|
1 2 3 4 5 6 |
resultado = balde.consulta(ftq); Sistema.fora.println("totalHits: " + resultado.totalHits()); para (SearchQueryRow fila : resultado) { Sistema.fora.println(fila); Sistema.fora.println(balde.obter(fila.id()).conteúdo()); } |
Isso nos dá, para o primeiro acerto:
|
1 2 3 |
Busca de acerto{id='dc_brau', pontuação=0.09068310490562362, fragmentos={}} {"país":"Estados Unidos","website":"https://www.dcbrau.com/","código":"20018","endereço":["3178-B Bladensburg Rd. NE"],"cidade":"Washington","telefone":"","name" (nome):"DC Brau", "description" (descrição):"A primeira cervejaria a ser aberta na capital do país desde a Lei Seca.","estado":"DC","tipo":"cervejaria","atualizado":"2011-08-08 19:02:40"} |
Se observarmos atentamente o JSON do documento, perceberemos onde o documento provavelmente correspondeu. Na seção "descrição" do documento, há esta frase:
A primeira cervejaria a ser aberta na naçãodesde a Lei Seca.
Observe também que a consulta de texto procurou a palavra solicitada e palavras derivadas que têm a mesma raiz. Na verdade, ela aplicou uma imprecisão de 2 (consulte a próxima seção).
Esse padrão também pode ser aplicado a outros tipos de consultas, portanto, vamos dar uma olhada em mais algumas e ver que tipo de pesquisa pode ser realizada.
Vários tipos de consultas
Consulta Fuzzy
As consultas difusas podem ser realizadas com o MatchQuery, especificando um Distância de Levenshtein como o máximo fuzziness() para permitir o termo:
|
1 2 3 4 5 6 7 8 9 10 11 |
resultado = balde.consulta(MatchQuery.em("beerIndex") .partida("sammar") .campo("name" (nome)) .imprecisão(2) //na verdade, o padrão .construir()); Sistema.fora.println("Consulta de correspondência nFuzzy"); Sistema.fora.println("totalHits (fuzziness = 2): " + resultado.totalHits()); para (SearchQueryRow fila : resultado) { Sistema.fora.println(balde.obter(fila.id()).conteúdo().obter("name" (nome))); } |
Em uma imprecisão de 2Isso corresponde a palavras como "hammer" (martelo), "mamma" (mamãe) ou "summer" (verão):
|
1 2 3 4 5 |
Difuso Jogo Consulta totalHits (imprecisão = 2): 45 Mamãe Mia! Pizza Cerveja Redhook Longo Martelo IPA Verão Trigo |
Em uma imprecisão de 1não foi encontrada nenhuma correspondência:
|
1 2 |
Difuso Jogo Consulta totalHits (imprecisão = 1): 0 |
Um tipo de consulta dedicada à imprecisão e que não aplica nenhum analisador também é fornecido no FuzzyQuery.
Vários termos: MatchPhrase
Como vimos, MatchQuery é uma consulta baseada em termos que permite especificar opcionalmente a imprecisão e também aplica o mesmo filtro ao termo pesquisado que pode ter sido aplicado ao campo (por exemplo, stemming, etc.):
|
1 2 3 4 |
MatchQuery.em("beerIndex") .partida("sesonal") .imprecisão(2) .campo("description" (descrição)).construir(); |
Você pode pesquisar vários termos em uma única consulta usando um Combinar frase consulta. Os termos são analisados e a imprecisão pode ser ativada opcionalmente:
|
1 |
MatchPhraseQuery.em("beerIndex").matchPhrase("sazonal de verão").campo("description" (descrição)); |
Consulta Regexp
A RegexpQuery não faz apenas a correspondência literal, mas permite a correspondência usando uma expressão regular. Veja este exemplo:
|
1 2 3 4 5 6 7 8 9 10 |
resultado = balde.consulta(RegexpQuery.em("beerIndex") .regexp("[tp]ale") .campo("name" (nome)) .construir()); Sistema.fora.println("Consulta nRegexp"); Sistema.fora.println("totalHits: " + resultado.totalHits()); para (SearchQueryRow fila : resultado) { Sistema.fora.println(balde.obter(fila.id()).conteúdo().obter("name" (nome))); } |
Observe que essa consulta visa um campo específico no json (campo("nome")). Queremos todos os nomes que contenham "tale" ou "pale". Aqui estão alguns nomes que correspondem a essa consulta:
|
1 2 3 4 5 |
Regexp Consulta totalHits: 408 Alto Conto Pálido Ale Bardo's Conto Cerveja Empresa Pálido Ale |
Consulta de prefixo
A PrefixQuery procura ocorrências de palavras que começam com a cadeia de caracteres fornecida:
|
1 2 3 4 5 6 7 8 9 10 |
resultado = balde.consulta(PrefixQuery.em("beerIndex") .prefixo("weiss") .campo("name" (nome)) .construir()); Sistema.fora.println("Consulta nPrefix"); Sistema.fora.println("totalHits: " + resultado.totalHits()); para (SearchQueryRow fila : resultado) { Sistema.fora.println(balde.obter(fila.id()).conteúdo().obter("name" (nome))); } |
Mais uma vez, olhamos apenas para o interior do nome desta vez para palavras que começam com "weiss":
|
1 2 3 4 5 6 |
Prefixo Consulta totalHits: 74 Bávaro-Weissbier Hefeweisse / Weisser Hirsch Münchner Tipo Weissbier / Münchner Weisse Franziskaner Café-Weissbier Inferno / Franziskaner Clube-Weiss Weissenheimer Trigo |
Consultas de intervalo e data
FTS também é bom com dados não textuais. Por exemplo, o NumericRangeQuery permite que você procure valores numéricos dentro de um intervalo fornecido:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
resultado = balde.consulta(NumericRangeQuery.em("beerIndex") .min(3) .máximo(4) .campo("abv") .campos("name" (nome), "abv") .construir()); Sistema.fora.println("Consulta de intervalo nNumérico"); Sistema.fora.println("totalHits: " + resultado.totalHits()); para (SearchQueryRow fila : resultado) { JsonDocument doc = balde.obter(fila.id()); Sistema.fora.println(""" + doc.content().get("nome") + "", abv: " + doc.conteúdo().obter("abv")); } |
Quais são as saídas:
|
1 2 3 4 5 |
Numérico Faixa Consulta totalHits: 62 "Stud Service Stout" (cerveja de serviço), abv: 3.1 "Loira", abv: 3.0 "Luz da Montanha Locke", abv: 3.7 |
As datas também são cobertas com o DateRangeQuery:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
Calendário calendário = Calendário.getInstance(); calendário.definir(2011, Calendário.MARÇO, 1); Data iniciar = calendário.getTime(); calendário.definir(2011, Calendário.ABRIL, 1); Data final = calendário.getTime(); resultado = balde.consulta(DateRangeQuery.em("beerIndex") .iniciar(iniciar) .final(final) .campo("atualizado") .campos("name" (nome), "atualizado") .construir()); Sistema.fora.println("Consulta de intervalo de datas nDate"); Sistema.fora.println("totalHits: " + resultado.totalHits()); para (SearchQueryRow fila : resultado) { JsonDocument doc = balde.obter(fila.id()); Sistema.fora.println(""" + doc.content().get("nome") + "", atualizado: " + doc.conteúdo().obter("atualizado")); } |
Quais são as saídas:
|
1 2 3 4 5 6 |
Data Faixa Consulta totalHits: 4 "Úmido", atualizado: 2011-03-16 09:06:54 "Oso", atualizado: 2011-03-16 09:05:15 "Dentes de verão", atualizado: 2011-03-08 12:22:14 "Columbus Brewing Company", atualizado: 2011-03-08 12:19:07 |
Consulta genérica
FTS também oferecem uma forma mais genérica de consulta que combina frases, termos e muito mais usando o Sintaxe de consulta de cadeia de caracteres. Isso pode ser acessado na API por meio do Consulta de cadeia de caracteres.
Combinação
Além disso, você pode combinar critérios simples como MatchQuery usando consultas combinadas. Usando essas duas consultas de termos simples:
|
1 2 |
MatchQuery bitterQuery = MatchQuery.em("beerIndex").partida("amargo").campo("description" (descrição)).construir(); MatchQuery maltyQuery = MatchQuery.em("beerIndex").partida("maltado").campo("description" (descrição)).construir(); |
Você pode combiná-los de diferentes maneiras:
- a
conjunçãoprocura por todos os termos
|
1 |
ConjunctionQuery.em("beerIndex").Conjuntos(bitterQuery, maltyQuery) |
- a
disjunçãoprocura pelo menos um termo
|
1 |
DisjunctionQuery.em("beerIndex").disjuntos(bitterQuery, maltyQuery) |
- a
consulta booleanapermite que você combine as duas abordagens
|
1 |
BooleanQuery.em("beerIndex").deve(bitterQuery).mustNot(maltyQuery) |
Obtendo explicações sobre os acertos
Se você quiser obter insights sobre a pontuação e a correspondência de uma determinada SearchQueryRowvocê pode criar sua consulta usando o .explain(true) e obter detalhes do índice no parâmetro explicação() campo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
{"mensagem":"soma de:","crianças":[{"mensagem":"produto de:","crianças":[{"mensagem":"soma de:","crianças":[{"mensagem":"produto de:","crianças":[{"mensagem":"soma de:","crianças":[ { "mensagem": "weight(_all:national^1.000000 in penn_brewery-penn_marzen), product of:", "crianças": [ { "mensagem": "queryWeight(_all:national^1.000000), product of:", "crianças": [ { "mensagem": "boost", "valor": 1 }, { "mensagem": "idf(docFreq=17, maxDocs=7303)", "valor": 7.005668743723945 }, { "mensagem": "queryNorm", "valor": 0.1427415478209491 } ], "valor": 0.9999999999999999 }, { "mensagem": "fieldWeight(_all:national in penn_brewery-penn_marzen), product of:", "crianças": [ { "mensagem": "tf(termFreq(_all:national)=1", "valor": 1 }, { "mensagem": "fieldNorm(field=_all, doc=penn_brewery-penn_marzen)", "valor": 0.10000000149011612 }, { "mensagem": "idf(docFreq=17, maxDocs=7303)", "valor": 7.005668743723945 } ], "valor": 0.7005668848116544 } ], "valor": 0.7005668848116543 } ],"valor":0.7005668848116543},{"mensagem":"coord(1/1)","valor":1}],"valor":0.7005668848116543}],"valor":0.7005668848116543},{"mensagem":"coord(1/1)","valor":1}],"valor":0.7005668848116543}],"valor":0.7005668848116543} |
Conclusão
Esperamos que essa prévia da API tenha despertado seu interesse!
Vá em frente e faça o download do primeiro Visualização do Couchbase 4.5 para desenvolvedores com o serviço de pesquisa de texto completo incorporado. Esperamos que você possa começar a pesquisar rapidamente usando o serviço associado API do Java SDK.
E até lá... Boa codificação!
– A equipe do Java SDK