Os microsserviços exigem um conjunto de componentes escalável e sustentável. Esta postagem apresenta como criar microsserviços usando Python e Couchbase para fornecer uma solução totalmente escalável.
Os aplicativos monolíticos apresentam muitos desafios. Eles nasceram em uma época em que tudo era executado em um único sistema, geralmente um mainframe ou minicomputador. Arquitetura orientada a serviços liberou os aplicativos, permitindo que eles usassem coleções de servidores de commodities compartilhados e sem escala. Isso permitiu que partes de um cenário de aplicativos fossem dimensionadas discretamente, conforme necessário. Hoje, temos padrões semelhantes, exceto pelo fato de os servidores terem sido substituídos por máquinas virtuais ou instâncias de nuvem.
Algumas arquiteturas orientadas a serviços são coleções de aplicativos de pequeno a grande porte que precisam interoperar. Isso permite alguma desagregação e dimensionamento horizontal, mas não resolve todos os desafios de alcançar a escalabilidade global da nuvem, pois cada serviço costuma ser um aplicativo monolítico. Aplicativos grandes não são apenas difíceis de dimensionar, mas também um desafio para desenvolver. Eles exigem muita codificação e manutenção. Atualizações simples de código podem exigir testes de regressão completos, o que requer um esforço considerável.
Digite o Arquitetura de microsserviços. Esse padrão arquitetônico divide cada componente do aplicativo em pequenas partes que podem ser dimensionadas de forma independente. Geralmente, eles não têm estado, de modo que podem ser ativados e desativados conforme necessário. O principal desafio é a latência da rede, mas isso geralmente não é um problema, pois as redes de alta velocidade são onipresentes atualmente.
Projeto de microsserviço
Um bom microsserviço deve ser leve e sem estado. O objetivo de um Arquitetura de microsserviços é dividir a funcionalidade do aplicativo em componentes discretos e de operação independente. Cada microsserviço deve atender a uma área funcional do aplicativo geral. O mais importante é que cada microsserviço seja capaz de evoluir independentemente do restante do cenário do aplicativo. Isso funciona bem com um Metodologia de desenvolvimento ágilpermitindo que as equipes forneçam rapidamente novas funcionalidades sem afetar o aplicativo geral.
Já foi dito que os microsserviços devem ser projetados para falhas. Isso pode parecer estranho a princípio, mas faz todo o sentido se você considerar a natureza e o ciclo de vida de um microsserviço. Um bom microsserviço deve ser efêmero. Como eles não têm estado, você deve ser capaz de adicionar e remover instâncias de microsserviços sem afetar o aplicativo.
Como os microsserviços estarão em fluxo perpétuo, toda a interação com eles deve ser feita por meio de um estilo de API que funcione bem nesse ambiente. Assim sendo, Interfaces RESTful são uma boa opção para o design da API. As chamadas REST são efêmeras e funcionam bem por trás de um balanceador de carga de rede (que é um método para tornar os microsserviços baseados em REST altamente disponíveis e dimensionáveis).
Por fim, eles devem ser fáceis de implantar e automatizar com as ferramentas populares de DevOps. Cada serviço deve ser capaz de ser executado em um sistema com outros serviços ou em um contêiner. O Kubernetes, uma tecnologia de orquestração de contêineres, foi essencialmente criado para microsserviços.
Criação de um microsserviço de perfil de usuário
É difícil criar um aplicativo inteiro a partir de microsserviços. A lógica comercial principal geralmente precisa ser fornecida por algum aplicativo que simplesmente não pode ser reescrito com microsserviços. Por exemplo, talvez você precise interagir com uma pilha de aplicativos ERP ou CRM prontos para uso. Mas para aplicativos da Web e móveis, é um padrão comum fazer o front-end desses grandes sistemas com microsserviços para controlar a experiência do usuário final.
Os consumidores de tecnologia querem uma experiência rápida e personalizada quando interagem com um aplicativo da Web ou móvel. Com os microsserviços, é possível distribuir globalmente os elementos da camada de apresentação usados com mais frequência para que fiquem geograficamente próximos do usuário final. Você também pode dimensionar esses componentes de forma independente com base nos padrões de uso.
Um componente frequente de um aplicativo móvel ou da Web é o conceito de perfis de usuário. Geralmente, esse é o ícone da "silhueta de uma pessoa" na parte superior direita de uma interface de usuário. Os perfis de usuário podem ser simplistas, com informações demográficas básicas, ou altamente detalhados, com informações ricas sobre preferências e histórico, para promover alterações personalizadas na experiência do usuário.
Esta série de postagens de blog discute o uso do Python para fornecer uma interface RESTful para dados de perfil de usuário hospedados em um banco de dados Couchbase. Usaremos um exemplo simples com um esquema básico para fins ilustrativos. No entanto, você pode aprimorar esse exemplo o quanto for necessário para um aplicativo do "mundo real".
Por que usar o Couchbase para microsserviços?
O Couchbase combina vários elementos de processamento de dados em uma plataforma de dados unificada. O Couchbase inclui um mecanismo de valor-chave, suporte a esquemas relacionais, um mecanismo de consulta SQL completo, um mecanismo de pesquisa de texto completo, um mecanismo de eventos e um mecanismo de análise. Ele oferece tempos de resposta de microssegundos e elimina a necessidade de as organizações escolherem sistemas diferentes para cargas de trabalho diferentes.
Um serviço de perfil de usuário é normalmente um serviço acessado com frequência. No mínimo, junto com a autorização e a autenticação, ele é acessado sempre que um usuário faz login em um aplicativo. No entanto, o cenário mais provável é que ele precise ser acessado muitas vezes enquanto alguém interage com um aplicativo. Dessa forma, o desempenho e a latência serão características essenciais do projeto.
A arquitetura memory-first do Couchbase permite que ele ofereça um desempenho incrivelmente rápido. O desempenho do Couchbase é quase linear com sua arquitetura scale-out e shared-nothing, que permite manter a taxa de transferência e as latências à medida que o cluster é dimensionado. O Couchbase pode ser dimensionado em conjunto com os elementos de microsserviço porque a arquitetura de microsserviço também é dimensionada para fora e não compartilhada.
O Couchbase foi projetado para eliminar muitas tarefas administrativas tradicionais. O Couchbase aproveita um modelo dinâmico de contenção de dados com armazenamento e rebalanceamento automáticos de dados e separa o gerenciamento de índices do gerenciamento de dados. Com o Oferta do Capella Couchbase Cloudou no local com ferramentas como Terraform ou Kubernetes e o Operador autônomo do CouchbaseCom o uso da tecnologia de nuvem, as alterações no banco de dados e no microsserviço podem ser automatizadas e orquestradas em nuvens públicas e privadas.
Por que Python?
Essa pode ser a maior dúvida em sua mente ao ler este post. Algo como Node.js pode ser a primeira linguagem que lhe vem à mente. De fato, por Berkeley JavaScript é a linguagem mais procurada, mas Python é a segunda. O Python é muito acessível, pois faz parte da distribuição de software para Linux e macOS, e você pode instalá-lo facilmente no Windows. Você pode ter várias versões da linguagem instaladas, e o recurso de ambiente virtual facilita a criação de vários ambientes personalizados usando diferentes versões da linguagem. Embora o Python ofereça suporte a multithreading, seus threads não são tão eficientes quanto os de uma linguagem como Java. Ainda assim, o Python é leve e, por isso, é bem dimensionado para o multiprocessamento e tem pacotes que facilitam o envio de threads ou processos. A melhor parte do Python é que ele é fácil de aprender e de codificar.
Exemplo de passo a passo do aplicativo
Para demonstrar o conceito, criei um exemplo de microsserviço Python (O código está no GitHub) que fornece uma interface RESTful muito simples para acessar as informações do perfil do usuário. O Couchbase é compatível com os tipos de documento JSON, UTF-8 (string) ou binário (raw). O formato JSON é considerado o formato nativo e permite muitos recursos avançados na plataforma, portanto, esse é o formato de documento que usaremos.
Nosso perfil de usuário muito simples contém o nome do usuário e outros detalhes básicos relacionados à sua conta. O perfil inclui uma imagem que faz referência a um registro separado que contém o arquivo de imagem codificado em Base64. Poderíamos ter usado o tipo de documento RAW, mas colocamos a imagem em um valor JSON para este exemplo.
Também aproveitamos o recurso de escopos e coleções que foi introduzido no Couchbase Server 7. Os documentos de perfil de usuário são armazenados no dados_do_usuário e as imagens são armazenadas no user_images como ilustrado aqui:
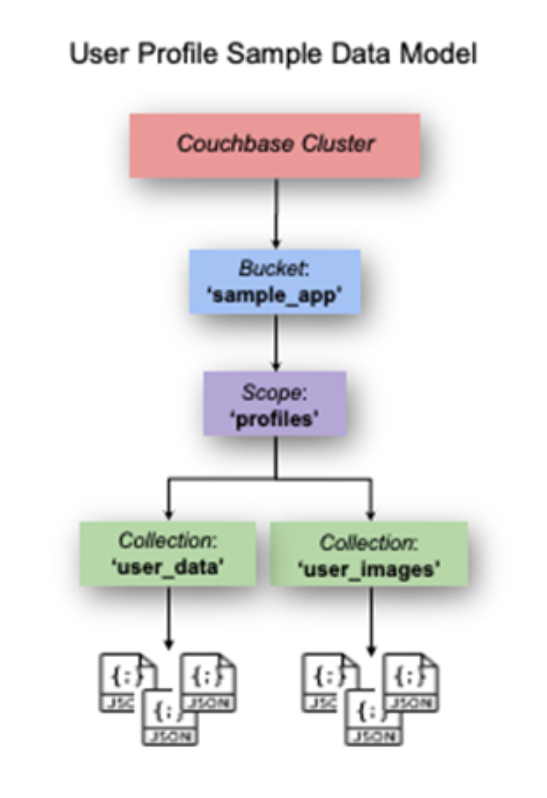
Formato de documento de perfil de usuário:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "record_id": "1", "name": "Jessica Lopez", "nickname": "jlopez", "picture": "1", "user_id": "jessicalopez9483", "email": "jessica.lopez@example.com", "email_verified": "False", "first_name": "Jessica", "last_name": "Lopez", "address": "6699 West Road", "city": "Weirton", "state": "OR", "zip_code": "21243", "phone": "306-402-6984", "date_of_birth": "03/05/1961" } |
Formato de documento de imagem do usuário:
|
1 2 3 4 5 |
{ "record_id": "1", "type": "jpeg", "image": " AAAADGpQICANC…=" } |
O microsserviço Python tem a opção de ser executado em primeiro plano, onde a saída é ecoada na tela (terminal), ou em segundo plano como um "daemon", onde a saída é enviada para um arquivo de registro. O código usa o recurso de classe orientada a objetos do Python para fazer a maior parte do trabalho.
O dbConnection foi projetada para manter ponteiros para objetos relacionados à conexão com o banco de dados Couchbase. Isso facilita a transmissão desses objetos para outras classes e funções.
O couchbaseDriver trata da interação com o banco de dados. A classe conectar inicia uma conexão com o cluster do Couchbase. Ela cria objetos para acessar o bucket, o escopo e as coleções passadas para a função. Ela armazena esses objetos em um dbConnection que está armazenado na classe. O objeto obter faz uma recuperação de valor-chave da chave passada para a função a partir da coleção referenciada, aproveitando a conexão estabelecida. A função consulta faz uma função SQL SELECIONAR no campo JSON da coleção referenciada, procurando uma chave JSON que seja igual ao valor especificado.
O restServer é uma classe de manipulador projetada para ser passada para a classe Python http.server módulo. Ele implementa a interface RESTful. Existem OBTER para localizar dados de perfil de usuário com base no apelido, nome de usuário ou ID. Ele também tem pontos de extremidade para obter imagens de perfil, seja recuperando o documento JSON ou retornando a própria imagem. Isso é vantajoso em relação a outras estruturas de desenvolvimento REST que geralmente só suportam a resposta a pontos de extremidade REST com conteúdo JSON.
Por fim, o microServiço inicia e interrompe o servidor HTTP. Ela é chamada a partir de principal que usa o couchbaseDriver para se conectar ao banco de dados e iniciar o microsserviço. O microsserviço inteiro tem apenas algumas centenas de linhas de código e pode ser facilmente implantado em qualquer lugar e anexado a qualquer cluster do Couchbase.
A seguir
Na próxima parte desta série, falaremos sobre a geração de dados de teste aleatórios para o esquema de microsserviço e o teste de desempenho.
Consulte esses recursos à medida que você pesquisar mais sobre esses tópicos:
