A replicação tem sido uma parte essencial dos sistemas de banco de dados há décadas para fornecer disponibilidade e recuperação de desastres. Nos últimos tempos, com a evolução dos bancos de dados distribuídos para atender à necessidade de implantações altamente disponíveis, dimensionáveis e distribuídas globalmente que operam entre dispositivos, a função da replicação evoluiu e se tornou mais importante do que nunca. Os sistemas de banco de dados estão desenvolvendo soluções de replicação abrangentes para atender aos requisitos em diferentes níveis, como intra-cluster, inter-cluster e da borda ao núcleo etc., o que também engloba casos de uso de nuvem, dispositivos móveis e outros casos de uso de IoT.
Alguns dos mais populares Banco de dados NoSQL Os sistemas com soluções de replicação versáteis são o Couchbase e o MongoDB. Vamos dar uma olhada mais profunda em cada uma dessas soluções e em como elas atendem a essas necessidades. Para simplificar a comparação, vamos nos concentrar na replicação para alta disponibilidade e implementações globais em vários DCs.
Replicação no MongoDB para implantação global
Arquitetura mestre-escravo
A arquitetura de replicação do Mongo é baseada em um conjunto de réplicas, que consiste em apenas um primário que captura todas as alterações de dados e confirma as gravações. Os secundários copiam os dados dos primários, que normalmente são somente leitura, a menos que sejam eleitos como primários. Cada conjunto de réplicas pode consistir em até 50 secundárias. Os membros do conjunto de réplicas também podem ser implantados em vários data centers para proteção contra falhas do data center e aplicativos distribuídos geograficamente. Os dados são replicados para os secundários de forma assíncrona.
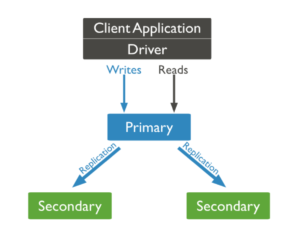
Fig. Modelo de replicação do Mongo
O tempo médio para o failover automático do primário para o secundário é de aproximadamente 12 segundos, o que pode ser maior quando os secundários são implantados em DCs diferentes devido à latência da rede. Isso se torna uma possibilidade de um único ponto de falha, pois os secundários não podem receber gravações.
Embora as leituras sejam padrão a partir do primário, os usuários podem especificar a preferência de leitura para ocorrer a partir do secundário para minimizar a latência. No entanto, como as replicações são assíncronas, elas podem arriscar a possibilidade de ler dados obsoletos, especialmente em aplicativos distribuídos geograficamente.
Implementação em vários centros e configuração do tipo ativo-ativo
Para implantações em vários centros, embora os secundários de um conjunto de réplicas possam ser implantados em um data center diferente, é insuficiente até que todos os data centers possam receber gravações. As implementações ativo-ativas com a capacidade de receber gravações simultaneamente de vários data centers são essenciais para aplicativos distribuídos geograficamente. Como o Mongo só pode receber gravações no primário, eles recomendam a abordagem mencionada abaixo para tratar de casos de uso ativo-ativo.
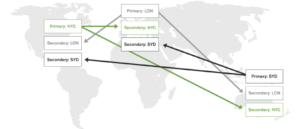
Fig. Configuração do tipo ativo-ativo usando o MongoDB
A fragmento no MongoDB é uma unidade de armazenamento lógico que contém um subconjunto de todo o conjunto de dados do cluster fragmentado. Para habilitar uma configuração do tipo ativo-ativo, o Mongo defende a implantação de um primário em cada fragmento. Como cada shard contém um subconjunto distinto de dados, o aplicativo só pode modificar diferentes subconjuntos de dados simultaneamente. Portanto, ele não é totalmente ativo-ativo, em que o mesmo conjunto de dados pode ser modificado em diferentes sites.
Um fragmento é totalmente transparente para o aplicativo e um roteador de consultas é implantado para encaminhar as consultas do aplicativo para os respectivos fragmentos. O roteamento de consultas também acrescenta uma sobrecarga adicional.
A implementação por meio dessa configuração pode se tornar extremamente complicada à medida que se expande porque, além de cada fragmento precisar ter um primário, para cada primário de fragmento, os secundários precisam estar localizados em outros fragmentos para alta disponibilidade, e o primário continua a ser um ponto único de falha. Para cada fragmento, o número de réplicas será igual ao número de fragmentos * número de datacenters. Também precisaríamos manter um quorum capaz de eleger o primário a qualquer momento para cada conjunto de réplicas. Aprenda mais.
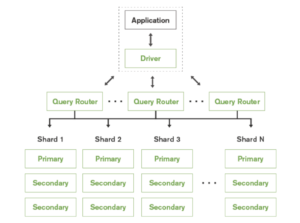
Essa configuração também é muito restritiva em termos de topologia; as implementações precisam aderir ao modelo de hub e spoke, pois o primário é um gargalo.
Implantações de nuvem - cluster global
O Mongo Atlas oferece o Global Cluster para aprimorar os casos de uso de replicação geográfica. A implementação usando o Global Cluster é semelhante à configuração do tipo ativo-ativo, em que você tem um shard primário em cada zona e região em que o fornecedor da nuvem oferece suporte.
Por meio do Global Cluster, o Mongo é capaz de oferecer roteamento com reconhecimento de local usando os metadados de local obtidos dos provedores de nuvem. Isso permite que o Mongo roteie as consultas para o data center mais próximo do ponto de origem e ofereça a menor latência de rede. Isso é vantajoso na maioria dos casos em que as atualizações são locais. Nos casos em que as gravações não são locais, há uma latência de rede adicional, pois somente o primário pode fazer gravações.
O maior benefício dos Global Clusters é que as complexidades operacionais e de implementação envolvidas na configuração e na capacidade de gerenciamento são tratadas pela Mongo, pois o Atlas é um serviço totalmente gerenciado. Mais uma vez, isso será restrito à implementação de um único fornecedor de nuvem. O Global Cluster não pode se estender por vários fornecedores de nuvem e regiões para dar suporte a implementações híbridas, pois é um único cluster. Mais informações sobre clusters globais aqui.
Replicação no Couchbase para implantação global
Arquitetura ponto a ponto
O Couchbase adotou esquemas de replicação distintos para replicação dentro de um cluster para falhas em nível de nó e replicação entre clusters para falhas em nível de datacenter e regional. A replicação entre clusters ou entre datacenters será o foco desta discussão, pois estamos interessados em implementações globais.
O Couchbase segue uma arquitetura ponto a ponto e isso também se reflete em sua solução de replicação entre datacenters. Com o Couchbase, você pode criar vários clusters independentes e configurar fluxos de replicação unidirecionais ou bidirecionais entre eles. Esses clusters independentes podem ser co-localizados no mesmo data center ou podem existir em regiões geográficas completamente diferentes. Essa arquitetura de ter clusters independentes ponto a ponto oferece vários benefícios, como isolamento da carga de trabalho, capacidade de definir políticas diferentes, suporte a diversas topologias, dimensionamento heterogêneo e também permite a implementação híbrida.
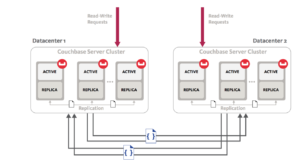
A solução do Couchbase também é considerada de alto desempenho, pois a replicação ocorre de memória para memória e é altamente paralela. O paralelismo é personalizável de acordo com os requisitos de desempenho. Eles também têm a capacidade de priorizar os fluxos de replicação existentes em relação aos novos ou vice-versa. Eles também se recuperam automaticamente após qualquer interrupção na rede.
Outro grande benefício é a topologia flexível: os clusters podem ser adicionados ou removidos da topologia a qualquer momento, sem nenhum impacto sobre o restante do sistema. Isso proporciona uma utilização extremamente boa dos recursos. Por exemplo, em uma topologia de anel bidirecional, os clusters podem atuar como uma solução de recuperação de desastres e também receber tráfego ativo.
Configuração multicêntrica e ativa-ativa
A solução de replicação Cross Datacenter pode ser implantada em qualquer lugar do mundo, onde quer que o cliente tenha um data center. São necessários apenas alguns cliques para criar um novo cluster e configurar a replicação entre eles.
O XDCR do Couchbase oferece suporte à verdadeira configuração ativo-ativo por meio da replicação bidirecional, em que usuários de todo o mundo podem modificar os mesmos dados simultaneamente em vários locais. Ele oferece suporte a dois modos de resolução de conflitos: a maioria das atualizações vence e a última gravação vence para resolver quaisquer conflitos que surjam durante uma configuração ativo-ativo.
Neste momento, o Couchbase não fornece nenhum roteamento com reconhecimento de local, mas como é uma arquitetura mestre-mestre, as leituras e gravações são sempre locais. Os clientes podem implantar os dados em qualquer lugar em qualquer data center para garantir a localidade dos dados. Os clientes também podem atender aos requisitos de residência de dados e de delimitação geográfica usando a filtragem avançada para replicar apenas os dados relevantes para a região.
Implantações na nuvem
O Couchbase está disponível em todas as principais nuvens: AWS, Azure, GCP e Oracle Cloud.
Os clusters do Couchbase podem ser implantados em qualquer nuvem, e os fluxos de replicação podem ser configurados entre eles. Isso inclui implementações de várias nuvens e nuvens híbridas, em que os clusters podem ser implementados em diversas nuvens, como privada e pública, ou em duas ou mais nuvens públicas.
A implementação e a administração dos sistemas de replicação são extremamente simples e intuitivas.
O Couchbase ainda não tem uma solução DBaaS, mas espera-se que ela seja lançada em breve. No entanto, o suporte para implantação automatizada é fornecido atualmente por meio do Operador autônomo do Couchbase.
Resumo das características de replicação no Couchbase e no Mongo DB
| Recursos | Couchbase | MongoDB |
| Arquitetura | Cluster totalmente independente, que pode ser dimensionado e gerenciado sem nenhuma dependência | Extensão do intra-cluster, não um sistema independente |
| Desempenho | Memória-memória, replicação baseada em fluxo e altamente paralelizada. O número de fluxos de replicação por nó pode ser (2-100) | Os secundários replicam os dados do oplog do primário ou de qualquer outro oplog do secundário. É paralelo, mas os fluxos são 1-1 (primário-secundário) |
| Escrever preocupações | Qualquer cluster pode ser configurado para aceitar gravações | Somente o primário pode receber gravações, o que afeta a disponibilidade de gravações, e as gravações não locais são muito caras |
| Leia as preocupações | Sempre local | O primário padrão, que pode ser caro, pode ser configurado para ler a partir dos secundários |
| Autofailover | O failover automático entre clusters pode ser ativado no nível do SDK | Cluster único, automático |
| Flexibilidade de replicação | Muito flexível - nível de balde, técnicas avançadas de otimização para personalizar | Não é possível fazer o ajuste, escolher a velocidade e a largura de banda |
| Técnicas de otimização de largura de banda | Filtragem avançada, compactação de dados, limite de largura de banda da rede, qualidade de serviço para priorizar a replicação. | Compressão de dados |
| Topologia | Suporte para topologias complexas - bidirecional, estrela, malha, cadeia, anel, etc. | Sem suporte para topologia complexa -Unidirecional, em estrela. O primário é um gargalo. |
| Ativo-Ativo | Com suporte | Sem suporte real (mestre único) |
| Resolução de conflitos | Sim - a maior gravação vence, a última gravação vence (LWW) | Sem resolução de conflitos. Somente um primário é suportado. |
| Instalação e configuração | Fácil configuração com UI intuitiva e CLI com apenas alguns cliques. | A distribuição de conjuntos de réplicas é complicada e pode ser dolorosa à medida que os conjuntos de réplicas aumentam. |
| Filtragem para replicar subconjuntos | Filtragem avançada para replicar subconjuntos de dados usando IDs de chave de documento, valores ou metadados. | Não há suporte para filtragem |
| Priorização da replicação | Capacidade de priorizar a replicação em andamento em comparação com a nova replicação ou vice-versa. | Não há suporte para priorização de replicação. |