"Nada é certo, exceto a morte e os impostos."
Esse não é um conjunto de dados criado com um canteiro de rosas ou grama verde bem cuidada. Um pouco mais sério. Vamos ver se podemos aprender algo rapidamente aqui. O conjunto de dados é o seguinte.
"name" : "NCHS - Principais causas de morte: Estados Unidos",
"attribution" : "National Center for Health Statistics" (Centro Nacional de Estatísticas de Saúde),
O público dataset está disponível em https://data.cdc.gov/api/views/bi63-dtpu/rows.json?accessType=DOWNLOAD
Etapa 1: Faça o download do arquivo em um arquivo local (por exemplo, health.json). Carregue esse arquivo em um dos nós do cluster do Couchbase.
Etapa 2Importar os dados para um compartimento chamado causa. Depois de criar o bucket, crie o índice primário. Você precisará dele para fazer consultas.
/opt/couchbase/bin/cbimport json -c couchbase://127.0.0.1 -u Administrator -p password -b cause -d file://health.json -g cause:0 -f sample
> CREATE PRIMARY INDEX ON cause;
Etapa 3. Inspecione a estrutura dos dados.
Todos os dados são fornecidos em um ÚNICO documento JSON. Por esse motivo, o INFER não ajuda. Você terá que inspecionar e entender a estrutura manualmente. Esses dados são um conjunto de dados típico do governo, com muitos dados em matrizes simples, com o significado de cada entidade fornecido nos metadados.
Matriz simples:
|
1 |
<strong>select data from cause ;</strong> |
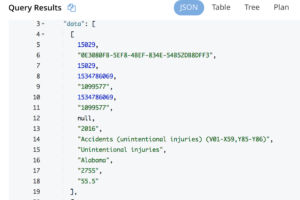
Ele simplesmente contém uma matriz de dados sem o esquema. Para os conjuntos de dados públicos, o esquema está no campo meta.
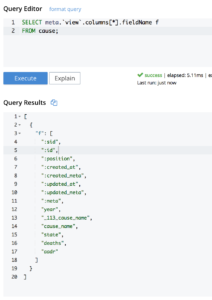
Vamos transformar a estrutura em pares simples de valores-chave JSON para que possamos lidar com esses bits de forma mais eficaz. Você pode saber mais sobre como essa mágica aconteceu neste artigo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
WITH cs AS ( SELECT meta.`view`.columns [*].fieldName f, data FROM cause ) SELECT o FROM cs UNNEST cs.data AS d1 LET o = OBJECT p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END; |
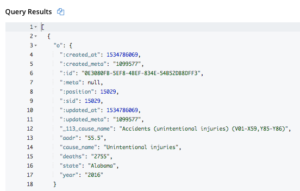
Tarefa 1: Descubra a causa da maioria das mortes em um estado, por ano.
A expressão de tabela comum (CTE) na cláusula WITH (csdata) transforma os dados json complexos em JSON simples. Você pode fazer isso dinamicamente ou fazer isso uma vez e INSERTAR de volta em um bucket, como discuti no artigo sobre Nomes de bebês de Nova York. Neste artigo, eu uso CTEs.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
WITH csdata as ( WITH cs AS ( SELECT meta.`view`.columns [*].fieldName f, data FROM cause ) SELECT o FROM cs UNNEST cs.data AS d1 LET o = OBJECT p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END ) SELECT c.o.state, c.o.year, c.o.cause_name, COUNT(c.o.cause_name), SUM(TONUMBER(c.o.deaths)) totdeaths FROM csdata as c WHERE c.o.state <> "United States" and c.o.cause_name <> "All causes" GROUP BY c.o.state, c.o.year, c.o.cause_name ORDER BY totdeaths DESC, c.o.state, c.o.year |
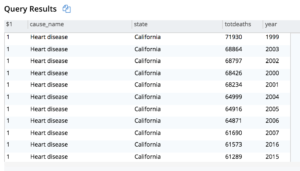
Nesse caso, todas as mortes na Califórnia estão no topo, principalmente devido à sua população.
Tarefa 2. Descubra as principais causas de morte em cada estado no ano de 2016.
Consulta 2: Use o conjunto de resultados da consulta anterior e, em seguida, use a função de janela FIRST_VALUE() para determinar a causa principal. O particionamento por estado (na cláusula OVER BY) lhe dará as partições por estado e ORDER BY dx.totdeaths dentro da cláusula OVER BY lhe dará a causa principal em cada estado.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
WITH csdata as ( WITH cs AS ( SELECT meta.`view`.columns [*].fieldName f, data FROM cause ) SELECT o FROM cs UNNEST cs.data AS d1 LET o = OBJECT p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END ), d2 as( SELECT c.o.state, c.o.year, c.o.cause_name, SUM(TONUMBER(c.o.deaths)) totdeaths FROM csdata as c WHERE c.o.state <> "United States" and c.o.cause_name <> "All causes" and c.o.year = "2016" GROUP BY c.o.state, c.o.year, c.o.cause_name), d3 as ( SELECT dx.state, dx.cause_name, dx.totdeaths, FIRST_VALUE(dx.cause_name) OVER(PARTITION BY dx.state ORDER BY dx.totdeaths DESC) topreason, FIRST_VALUE(dx.totdeaths) OVER(PARTITION BY dx.state ORDER BY dx.totdeaths DESC) topcount FROM d2 dx) SELECT d3 FROM d3 WHERE d3.topcount = d3.totdeaths order by d3.state |
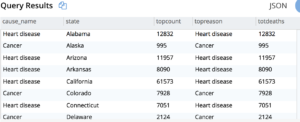
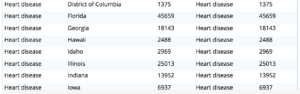
Tarefa 3. Descubra como o principal motivo mudou ao longo do ano, de 1999 a 2016, por estado.
Consulta 3: Basta gerar o relatório para todos os anos (199-2016) e, em seguida, determinar o motivo principal e, finalmente, obter o motivo mais alto agrupando por estado, ano e obtendo MAX(topcount) para a causa do motivo principal.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
WITH csdata as ( WITH cs AS ( SELECT meta.`view`.columns [*].fieldName f, data FROM cause ) SELECT o FROM cs UNNEST cs.data AS d1 LET o = OBJECT p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END ), d2 as( SELECT c.o.state, c.o.year, c.o.cause_name, SUM(TONUMBER(c.o.deaths)) totdeaths FROM csdata as c WHERE c.o.state <> "United States" and c.o.cause_name <> "All causes" GROUP BY c.o.state, c.o.year, c.o.cause_name), d3 as ( SELECT dx.state, dx.year, FIRST_VALUE(dx.cause_name) OVER(PARTITION BY dx.state, dx.year ORDER BY dx.totdeaths DESC ) topreason, FIRST_VALUE(dx.totdeaths) OVER(PARTITION BY dx.state, dx.year ORDER BY dx.totdeaths DESC) topcount FROM d2 dx) SELECT d3.state , d3.year , d3.topreason, max(d3.topcount) topcount FROM d3 GROUP BY d3.state, d3.year, d3.topreason order by d3.state, d3.year |
Aqui está o resultado parcial.
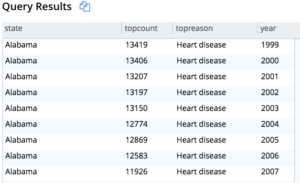
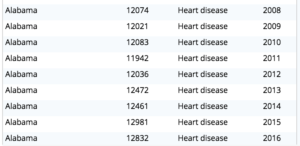
A visualização disso nos dá o seguinte histograma.
