Há um mês, o Kubernetes lançou uma versão beta para Volumes persistentes locais. Em resumo, isso significa que, se um pod que usa um disco local for eliminado, nenhum dado será perdido (vamos ignorar os casos extremos aqui). O segredo é que um novo pod será reprogramado para ser executado no mesmo nó, aproveitando o disco que já existe lá.
É claro que a desvantagem é que estamos vinculando nosso POD a um nó específico, mas se considerarmos o tempo e o esforço gastos para carregar uma cópia dos dados em outro lugar, poder aproveitar o mesmo disco se torna uma grande vantagem.
Os bancos de dados nativos da nuvem, como o Couchbase, são projetados para lidar graciosamente com falhas de nós ou Pods. Normalmente, esses nós são configurados para ter pelo menos três réplicas dos dados. Portanto, mesmo que você perca um deles, outro assumirá o controle, e o gerenciador de cluster ou um DBA acionará um processo de rebalanceamento para garantir que ele ainda tenha as mesmas 3 cópias.
Quando montamos o Padrão de reparo automático Com a combinação do Kubernetes, dos Volumes Persistentes Locais e do processo de recuperação de bancos de dados nativos da nuvem, temos um mecanismo de autocorreção muito consistente. Essa combinação é ideal para casos de uso que exigem alta disponibilidade, e é por isso que a execução de bancos de dados no Kubernetes está se tornando um tema tão importante atualmente. Eu mencionei em um postagem anterior do blog algumas de suas vantagens, mas hoje eu gostaria de demonstrá-la em ação para mostrar a você por que ela é uma das próximas grandes novidades.
Vamos ver como é fácil implantar, recuperar de falhas de pod e escalar para cima e para baixo um banco de dados para o Kubernetes:
Transcrição de vídeo
Configuração de seu cluster do Kubernetes
Vamos começar configurando seu cluster do Kubernetes. Para esta demonstração, eu faço não recomendamos o uso do MiniKube. Se você não tiver um cluster para testes, poderá criar um rapidamente usando ferramentas como Ponto de pilha.
Arquivos YAML
Todos os arquivos usados no vídeo estão disponíveis aqui:
|
1 |
https://github.com/deniswsrosa/microservices-on-kubernetes/tree/master/kubernetes |
Implantação do operador Kubernetes do Couchbase
Um Operator no Kubernetes, a partir de uma visão geral de 10000 pés, é um conjunto de controladores personalizados para uma determinada finalidade. Nesta demonstração, o Operator é responsável por unir novos nós ao cluster, acionar o rebalanceamento de dados e dimensionar corretamente o banco de dados no Kubernetes:
- Configuração de permissões:
|
1 |
./rbac/create_role.sh |
- Implementação do operador:
|
1 |
kubeclt create -f operator.yaml |

Você pode consultar a documentação oficial aqui.
Implantação de um banco de dados no Kubernetes
- Vamos criar o nome de usuário e a senha que usaremos para fazer login no console da Web:
|
1 |
kubeclt create -f secret.yaml |
- Por fim, vamos implantar nosso banco de dados no Kubernetes simplesmente executando o seguinte comando:
|
1 |
kubeclt create -f couchbase-cluster.yaml |
Após alguns minutos, você perceberá que seu banco de dados com 3 nós está em funcionamento:
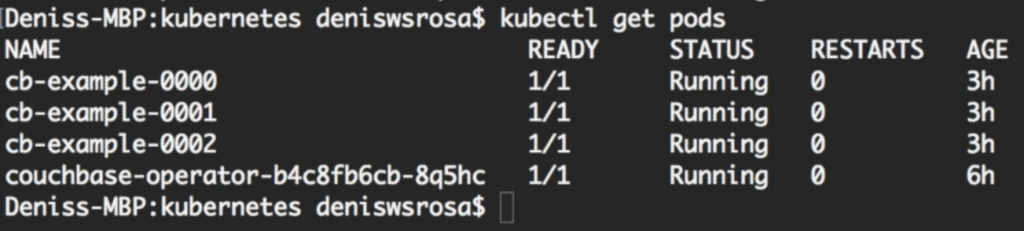
Não vou entrar em muitos detalhes sobre como couchbase-cluster.yaml obras (documento oficial) aqui). Mas eu gostaria de destacar duas sessões importantes nesse arquivo:
- A sessão a seguir especifica o nome do bucket e o número de réplicas dos dados:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... buckets: - name: couchbase-sample type: couchbase memoryQuota: 128 replicas: 3 ioPriority: high evictionPolicy: fullEviction conflictResolution: seqno enableFlush: true enableIndexReplica: false ... |
- A sessão abaixo especifica o número de servidores (3) e quais serviços devem ser executados em cada nó.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... servers: - size: 3 name: all_services services: - data - index - query - search dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data ... |
Acesso ao seu banco de dados no Kubernetes
Há muitas maneiras de expor o console da Web ao mundo externo. Ingressopor exemplo, é um deles. No entanto, para fins desta demonstração, vamos simplesmente encaminhar a porta 8091 do pod cb-example-0000 para nossa máquina local
|
1 |
kubectl port-forward cb-example-0000 8091:8091 |
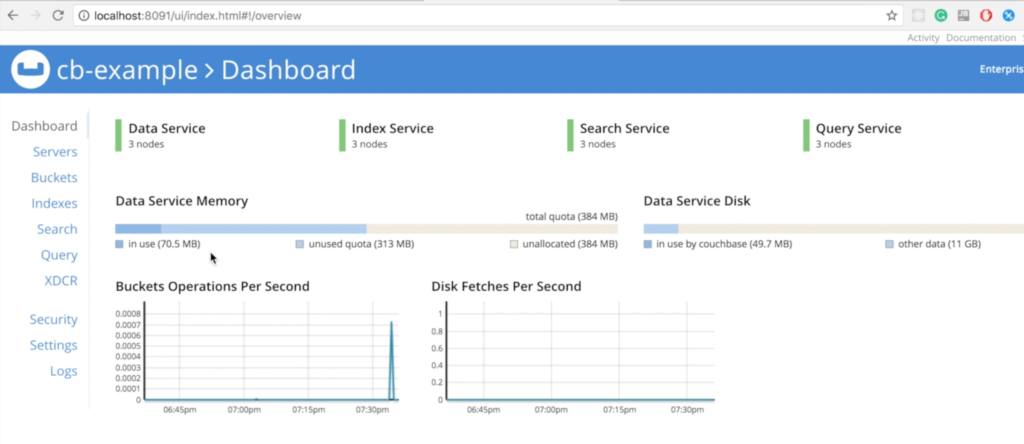
Agora, você deve conseguir acessar o Console da Web do Couchbase em sua máquina local em https://localhost:8091:
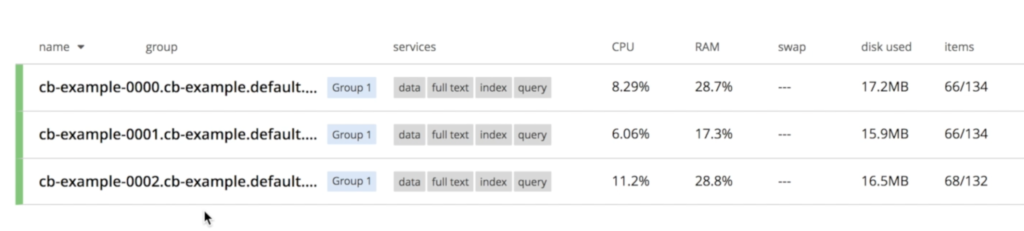
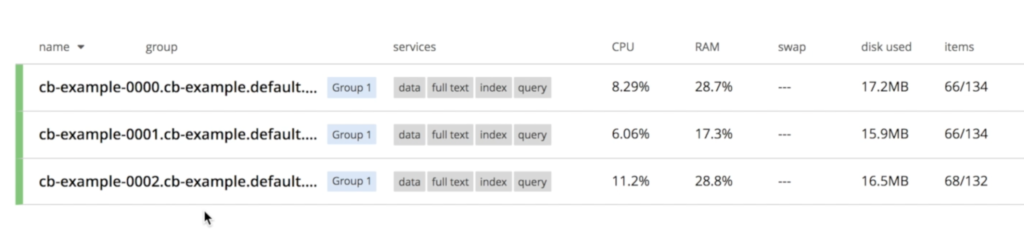
Observe que os três nós já estão conversando entre si:
Recuperação de uma falha de nó de banco de dados no Kubernetes
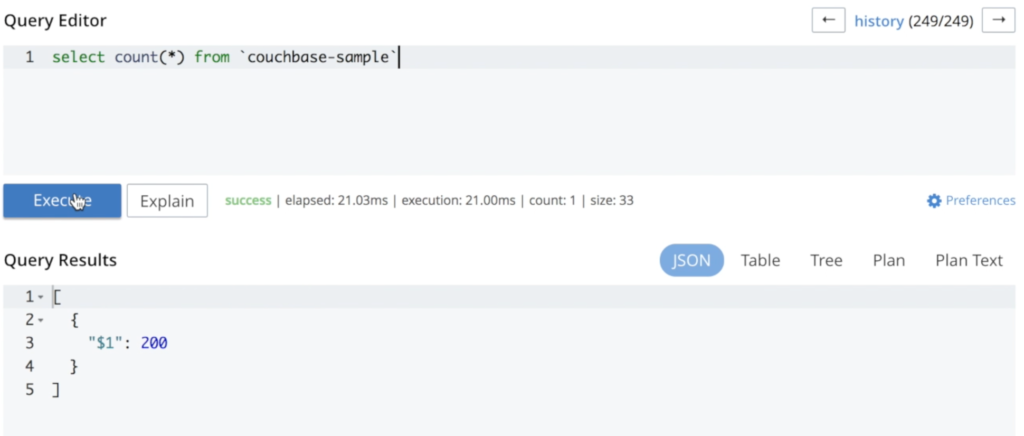
Adicionei alguns dados para ilustrar que nada é perdido durante todo o processo:
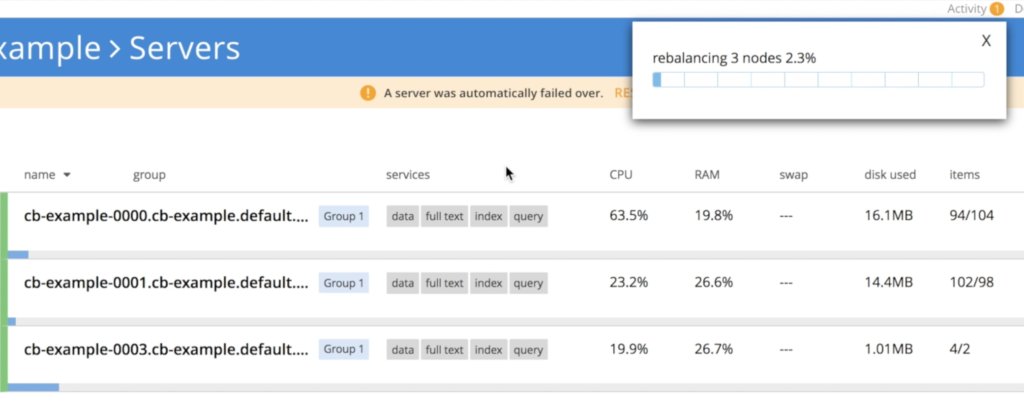
Agora, podemos excluir um pod para ver como o cluster se comporta:
|
1 |
kubectl delete pod cb-example-0002 |

O Couchbase perceberá imediatamente que um nó "desapareceu" e o processo de recuperação será iniciado. Conforme especificamos em couchbase-cluster.yaml que sempre queremos 3 servidores em execução, o Kubernetes iniciará uma nova instância chamado cb-exemplo-0003:
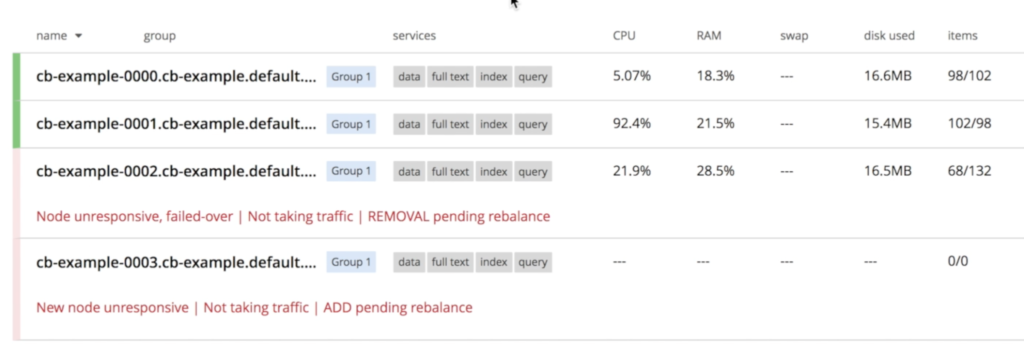
Uma vez cb-example-003 está ativo, o operador entra em ação para unir o nó recém-criado ao cluster e, em seguida, aciona o rebalanceamento de dados
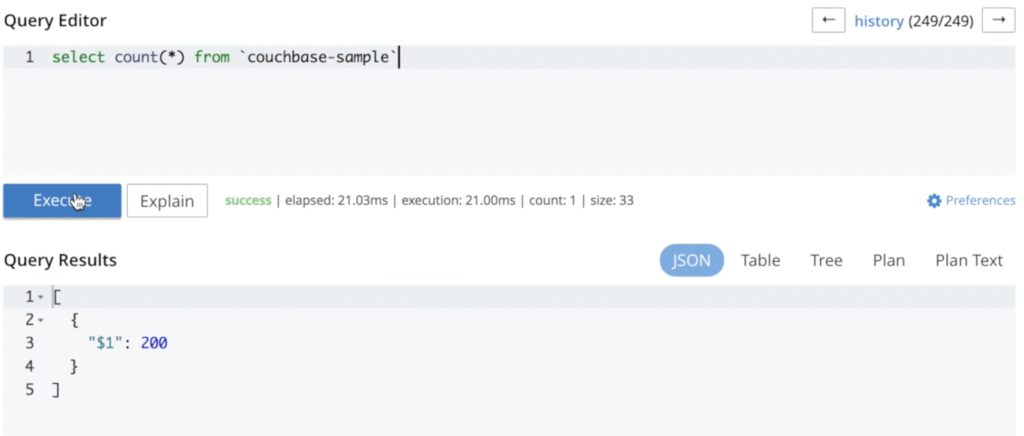
Como você pode ver, nenhum dado foi perdido durante esse processo. A reexecução da mesma consulta resulta no mesmo número de documentos:
Dimensionamento de um banco de dados no Kubernetes
Vamos aumentar a escala de 3 para 6 nós; tudo o que precisamos fazer é alterar o tamanho parâmetro em couchbase-cluster.yaml:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... servers: - size: 6 name: all_services services: - data - index - query - search dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data ... |
Em seguida, atualizamos nossa configuração executando:
|
1 |
kubectl replace -f couchbase-cluster.yaml |
Após alguns minutos, você verá que todos os três nós extras foram criados:
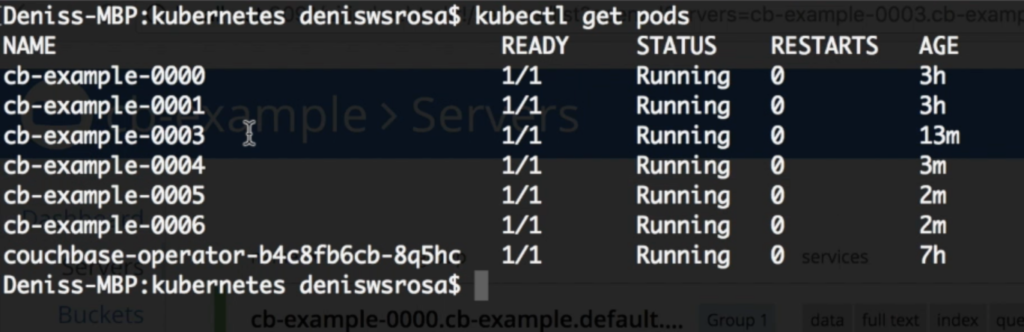
E, novamente, o operador reequilibrará automaticamente os dados:
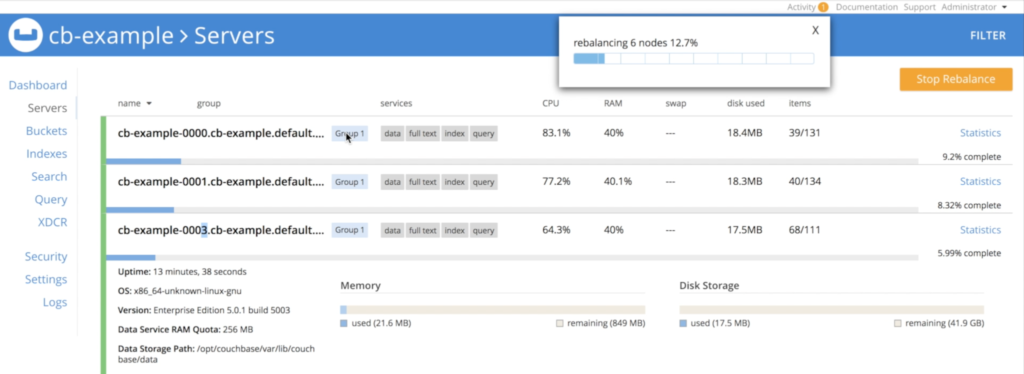
Dimensionamento de um banco de dados no Kubernetes
O processo de redução de escala é muito semelhante ao de aumento de escala. Tudo o que precisamos fazer é alterar o tamanho de 6 para 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... servers: - size: 3 name: all_services services: - data - index - query - search dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data ... |
Em seguida, executamos o comando replace novamente para atualizar a configuração:
|
1 |
kubectl replace -f couchbase-cluster.yaml |
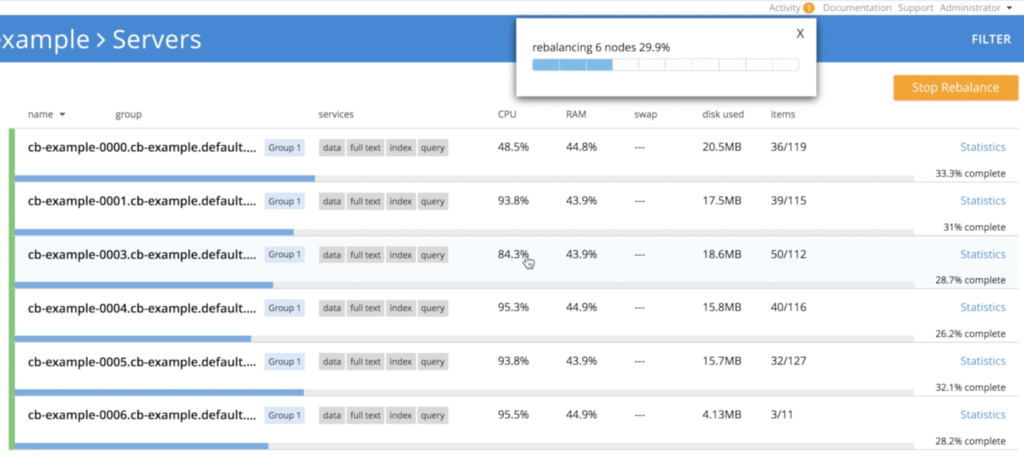
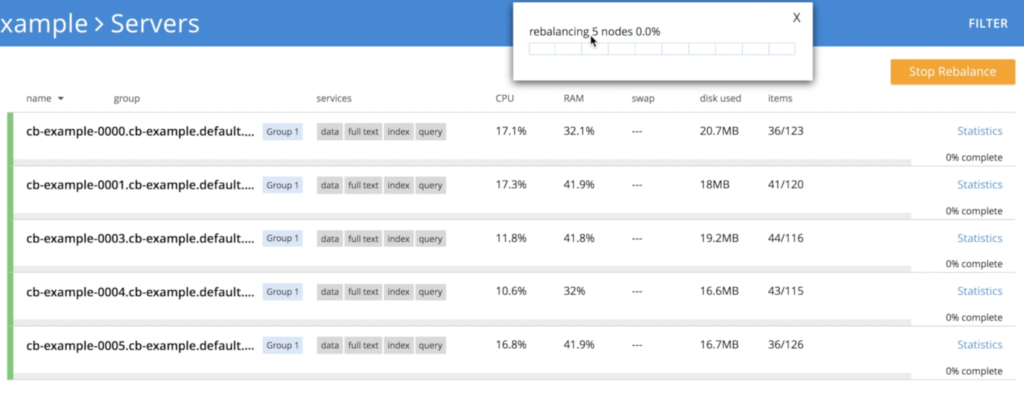
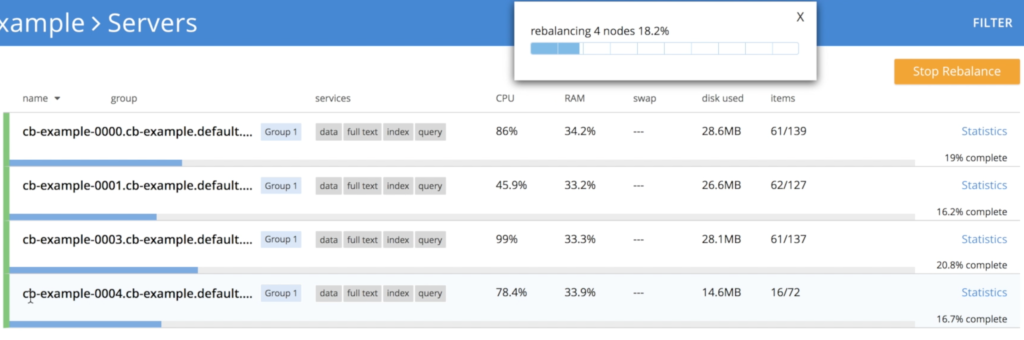
No entanto, há um pequeno detalhe aqui, pois não podemos simplesmente eliminar 3 nós ao mesmo tempo sem algum risco de perda de dados. Para evitar esse problema, o operador reduz o cluster gradualmente, uma única instância de cada vez, acionando o rebalanceamento para garantir que todas as três réplicas dos dados sejam preservadas:
- Operador desligando o nó cb-example-0006:
- Operador desligando o nó cb-example-0005
- Desligamento do nó cb-example-0004
- Finalmente, voltamos a ter 3 nós novamente
Escala multidimensional
Você também pode aproveitar escalonamento multidimensional especificando os serviços que você deseja executar em cada nó:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
... servers: - size: 3 name: data_and_index services: - data - index dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data - size: 2 name: query_and_search services: - query - search ... |
E quanto a outros bancos de dados no Kubernetes?
Sim! Você já pode executar alguns deles no Kubernetes, como MySQL e Postgres, como exemplos notáveis. Eles também estão tentando automatizar a maioria das operações de infraestrutura que discutimos aqui. Infelizmente, eles ainda não têm suporte oficial, portanto, implantá-los pode não ser tão simples quanto isso.
Se você quiser saber mais sobre isso, consulte essas duas palestras incríveis no Kubecon:
Conclusão
Atualmente, os bancos de dados estão usando Local Ephemeral Storages para armazenar seus dados (inclusive o Couchbase). A razão para isso é simples: Essa é a opção que oferece o melhor desempenho. Alguns bancos de dados também estão oferecendo suporte a armazenamentos persistentes remotos, apesar do enorme impacto na latência. Estamos ansiosos para que o Local Persistent Storage se torne GA, pois ele resolverá a maioria dos receios dos desenvolvedores com essa nova tendência.
Até agora, os bancos de dados totalmente gerenciados eram a única opção que você tinha se quisesse se livrar do ônus de gerenciar seu banco de dados. O preço dessa liberdade, é claro, vem na forma de alguns zeros a mais na sua conta e um controle de desempenho/arquitetura muito limitado. O aproveitamento do Kubernetes para dimensionamento e autogerenciamento do banco de dados está surgindo como uma terceira opção, entre gerenciar tudo sozinho e confiar em alguém para fazer isso por você.
Se você tiver alguma dúvida, deixe-a nos comentários ou envie um tweet para @deniswsrosa. Escreverei a parte 2 deste artigo para responder a todas elas.
Postagem absolutamente fantástica. Obrigado por isso, Denis.
Oi Denis,
Como podemos expor o serviço de dados ao executar isso no aws? Posso acessar o console de administração usando o DNS público do nó. Abri todas as portas necessárias no grupo de segurança do aws. Mas a amostra baseada no Java SDK não consegue se conectar. Há um aplicativo da Web de amostra rápida disponível como contêiner que eu possa usar para testar no cluster do Kubernetes?
Prezado Denis,
Você pode me ajudar a entender o que fiz de errado com a configuração do MDS na versão CB 6.0 EE com o Kubernetes?
servidores:
- tamanho: 3
nome: dataservices
serviços:
- dados
pod:
recursos:
limites:
cpu: "10"
memória: 30Gi
solicitações:
cpu: "5"
Memória: 20Gi
volumeMounts:
dados: couchbase
padrão: couchbase
- tamanho: 1
nome: indexservices
serviços:
- índice
pod:
recursos:
limites:
cpu: "40"
Memória: 75Gi
solicitações:
cpu: "30"
memória: 50Gi
volumeMounts:
dados: couchbase
padrão: couchbase
- tamanho: 1
nome: queryservices
serviços:
- consulta
pod:
recursos:
limites:
cpu: "10"
Memória: 10Gi
solicitações:
cpu: "5"
memória: 5Gi
volumeMounts:
dados: couchbase
padrão: couchbase
- tamanho: 2
nome: otherservices
serviços:
- pesquisa
- eventos
- análises
pod:
recursos:
limites:
cpu: "5"
Memória: 10Gi
solicitações:
cpu: "2"
memória: 5Gi
volumeMounts:
dados: couchbase
padrão: couchbase
Ele apenas apresenta o problema abaixo dos modelos:
Aviso: Mesclando o mapa de destino para o gráfico 'couchbase-cluster'. Não é possível substituir o item de tabela 'servers', com valor que não é de tabela: map[all_services:map[pod:map serverGroups: services:[data index query search eventing analytics] size:5]]
REVISÃO: 1
Quando quero continuar a instalação, ele apresenta o erro abaixo:
Erro: falha na liberação do beetle preenchido: o webhook de admissão "couchbase-admission-controller-couchbase-admission-controller.default.svc" negou a solicitação: lista de falhas de validação:
os dados em spec.servers[1].services são necessários
os dados em spec.servers[2].services são necessários
os dados em spec.servers[3].services são necessários
Tenho certeza de que estou perdendo em algum lugar a condição de loop em ...\templates\couchbase-cluster.yaml, pois ela não está aceitando várias entradas para o MDS:
E esta seção parece ser a culpada:
servidores:
{{- range $server, $config := .Values.couchbaseCluster.servers }}
nome: {{ $server }}
{{ toYaml $config | indent 4 }}
{{- end }}
{{- if .Values.couchbaseTLS.create }}
Alguma pista do que está faltando para que minha instalação do MDS seja bem-sucedida?
Obrigado por sua ajuda.