한 달 전, 쿠버네티스는 다음을 위한 베타 버전을 출시했습니다. 로컬 영구 볼륨. 요약하면, 로컬 디스크를 사용하는 파드가 죽어도 데이터가 손실되지 않는다는 뜻이다(여기서는 에지 케이스는 무시하기로 하자). 비밀은 이미 존재하는 디스크를 활용하여 동일한 노드에서 실행되도록 새 파드가 다시 스케줄링된다는 것입니다.
물론 파드를 특정 노드에 묶어둔다는 단점이 있지만, 다른 곳에 데이터 사본을 로드하는 데 드는 시간과 노력을 고려하면 동일한 디스크를 활용할 수 있다는 것은 큰 이점이 됩니다.
Couchbase와 같은 클라우드 네이티브 데이터베이스는 노드 또는 파드 장애를 원활하게 처리하도록 설계되었습니다. 일반적으로 이러한 노드는 데이터의 복제본을 3개 이상 갖도록 구성됩니다. 따라서 한 노드가 손실되더라도 다른 노드가 이를 대신하며, 클러스터 관리자나 DBA가 리밸런싱 프로세스를 트리거하여 여전히 동일한 3개의 사본을 보유하도록 보장합니다.
우리가 자동 복구 패턴 의 로컬 영구 볼륨과 클라우드 네이티브 데이터베이스의 복구 프로세스를 결합하면 매우 일관된 자가 복구 메커니즘을 갖게 됩니다. 이 조합은 고가용성이 요구되는 사용 사례에 이상적이며, 이것이 바로 요즘 Kubernetes에서 데이터베이스를 실행하는 것이 화제가 되고 있는 이유입니다. 저는 이전 블로그 게시물 의 장점 몇 가지를 소개해 드렸는데, 오늘은 실제로 시연을 통해 왜 이 제품이 차세대 대세 중 하나인지 보여드리고자 합니다.
배포, 파드 장애 복구, Kubernetes용 데이터베이스 확장 및 축소가 얼마나 쉬운지 알아보세요:
비디오 트랜스크립션
쿠버네티스 클러스터 구성하기
먼저 쿠버네티스 클러스터를 구성해 보겠습니다. 이 데모에서는 다음을 수행합니다. not 미니큐브 사용을 권장합니다. 테스트할 클러스터가 없는 경우 다음과 같은 도구를 사용하여 빠르게 클러스터를 만들 수 있습니다. 스택포인트.
YAML 파일
동영상에 사용된 모든 파일은 여기에서 확인할 수 있습니다:
|
1 |
https://github.com/deniswsrosa/microservices-on-kubernetes/tree/master/kubernetes |
카우치베이스의 쿠버네티스 오퍼레이터 배포하기
10000피트 개요에서 Kubernetes의 오퍼레이터는 주어진 목적을 위한 사용자 정의 컨트롤러 집합입니다. 이 데모에서 Operator는 클러스터에 새 노드를 조인하고, 데이터 리밸런싱을 트리거하고, Kubernetes에서 데이터베이스를 올바르게 확장 및 축소하는 역할을 담당합니다:
- 권한 구성하기:
|
1 |
./rbac/create_role.sh |
- 운영자 배포하기:
|
1 |
kubeclt create -f operator.yaml |

공식 문서를 확인할 수 있습니다. 여기.
쿠버네티스에 데이터베이스 배포하기
- 웹 콘솔에 로그인할 때 사용할 사용자 아이디와 비밀번호를 만들어 보겠습니다:
|
1 |
kubeclt create -f secret.yaml |
- 마지막으로, 다음 명령을 실행하여 Kubernetes에 데이터베이스를 배포해 보겠습니다:
|
1 |
kubeclt create -f couchbase-cluster.yaml |
몇 분이 지나면 노드 3개가 있는 데이터베이스가 실행되고 있음을 확인할 수 있습니다:
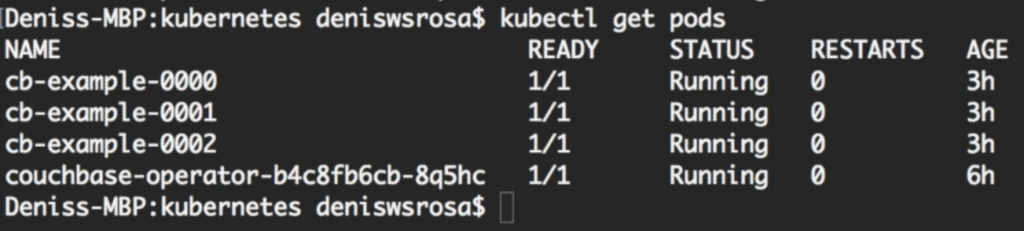
자세한 방법은 자세히 설명하지 않겠습니다. couchbase-cluster.yaml 작품 (공식 문서 여기). 하지만 이 파일에서 두 가지 중요한 세션을 강조하고 싶습니다:
- 다음 세션에서는 버킷 이름과 데이터 복제본 수를 지정합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... buckets: - name: couchbase-sample type: couchbase memoryQuota: 128 replicas: 3 ioPriority: high evictionPolicy: fullEviction conflictResolution: seqno enableFlush: true enableIndexReplica: false ... |
- 아래 세션에서는 서버 수(3개)와 각 노드에서 실행해야 하는 서비스를 지정합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... servers: - size: 3 name: all_services services: - data - index - query - search dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data ... |
쿠버네티스에서 데이터베이스에 액세스하기
웹 콘솔을 외부에 노출할 수 있는 방법은 여러 가지가 있습니다. 인그레스가 그 중 하나입니다. 그러나 이 데모의 목적상, 간단히 포드 cb-example-0000의 포트 8091을 로컬 머신으로 전달해 보겠습니다.
|
1 |
kubectl port-forward cb-example-0000 8091:8091 |
이제 로컬 컴퓨터의 다음 위치에서 Couchbase의 웹 콘솔에 액세스할 수 있습니다. https://localhost:8091:
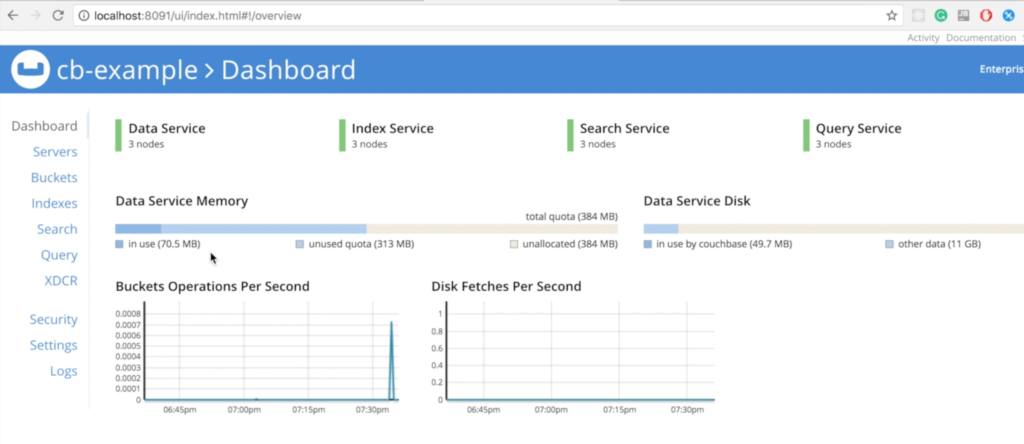
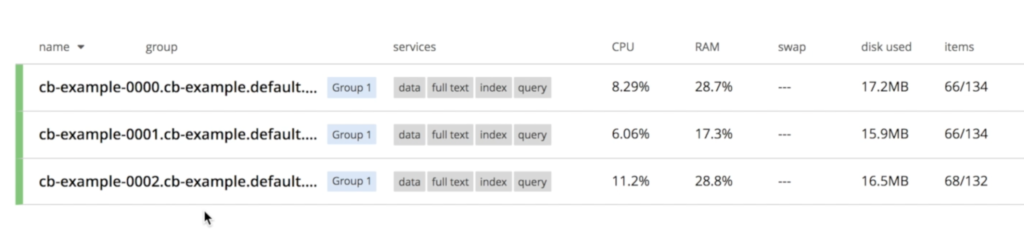
세 노드 모두 이미 서로 대화하고 있는 것을 확인할 수 있습니다:
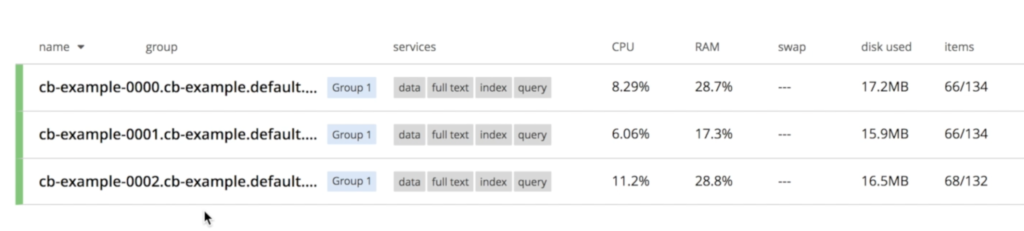
쿠버네티스의 데이터베이스 노드 장애에서 복구하기
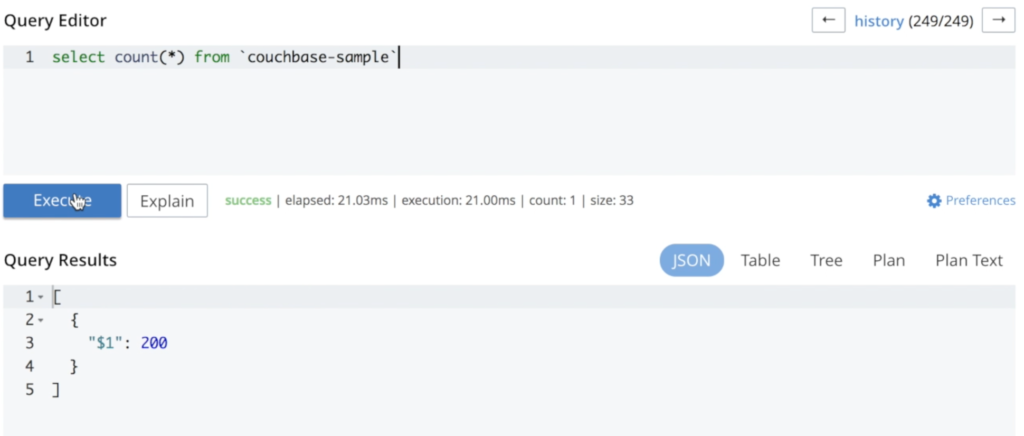
전체 프로세스 중에 손실되는 것이 없다는 것을 설명하기 위해 몇 가지 데이터를 추가했습니다:
이제 파드를 삭제하여 클러스터가 어떻게 작동하는지 확인할 수 있습니다:
|
1 |
kubectl delete pod cb-example-0002 |

카우치베이스는 즉시 노드 "사라짐'를 클릭하면 복구 프로세스가 시작됩니다. 에서 지정한 대로 couchbase-cluster.yaml 항상 3개의 서버를 실행하도록 설정하면 쿠버네티스는 새 인스턴스를 시작합니다. 호출 cb-예시-0003:
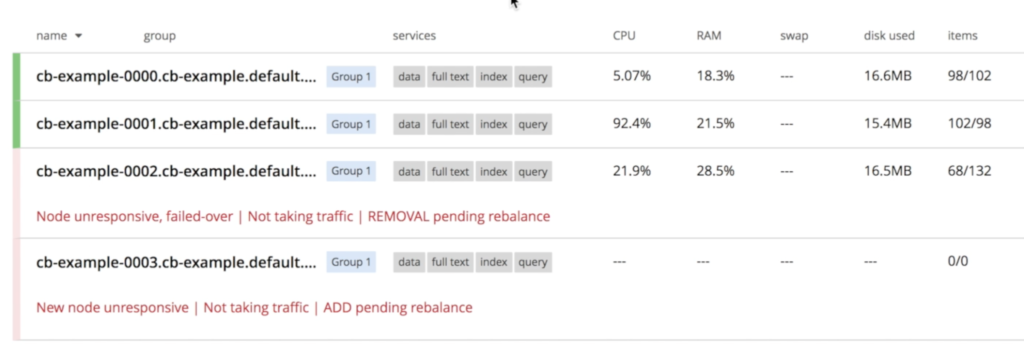
한 번 cb-example-003 가 올라가면 운영자는 새로 생성된 노드를 클러스터에 조인한 다음 데이터 리밸런싱을 트리거합니다.
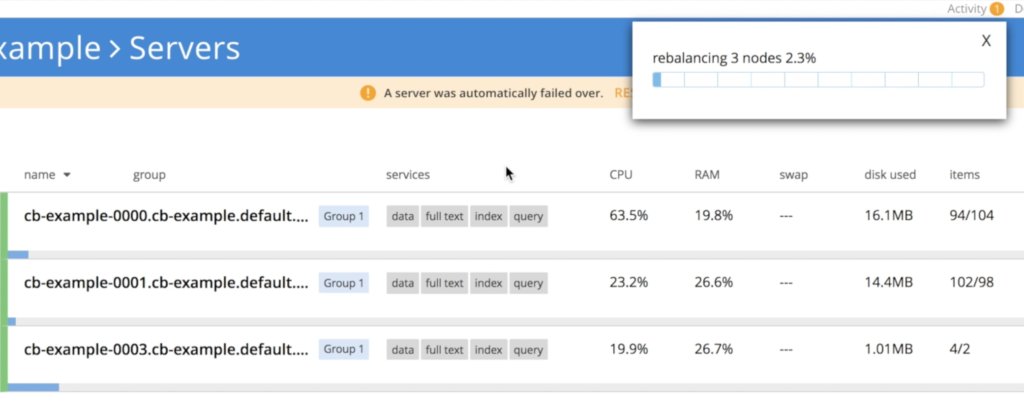
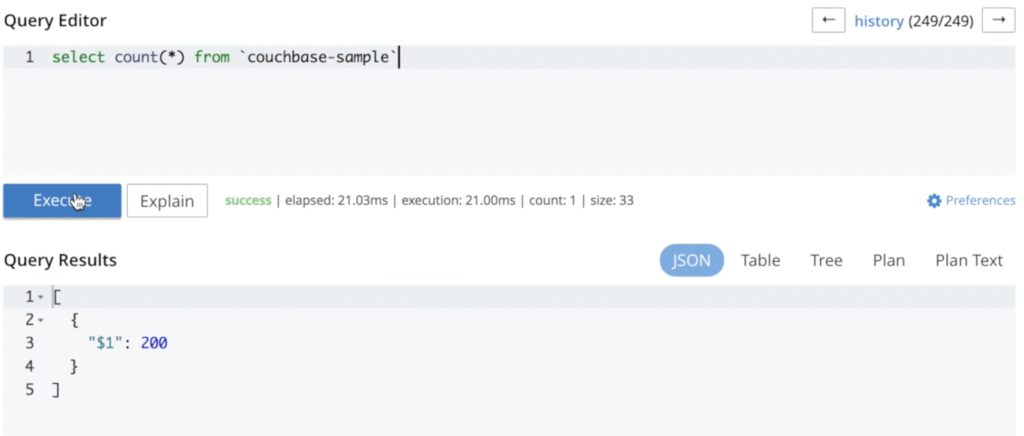
보시다시피 이 과정에서 데이터는 손실되지 않았습니다. 동일한 쿼리를 다시 실행하면 동일한 수의 문서가 생성됩니다:
쿠버네티스에서 데이터베이스 확장하기
3노드에서 6노드로 확장해 보겠습니다. 크기 매개변수를 couchbase-cluster.yaml:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... servers: - size: 6 name: all_services services: - data - index - query - search dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data ... |
그런 다음 실행하여 구성을 업데이트합니다:
|
1 |
kubectl replace -f couchbase-cluster.yaml |
몇 분 후에 3개의 추가 노드가 모두 생성된 것을 확인할 수 있습니다:
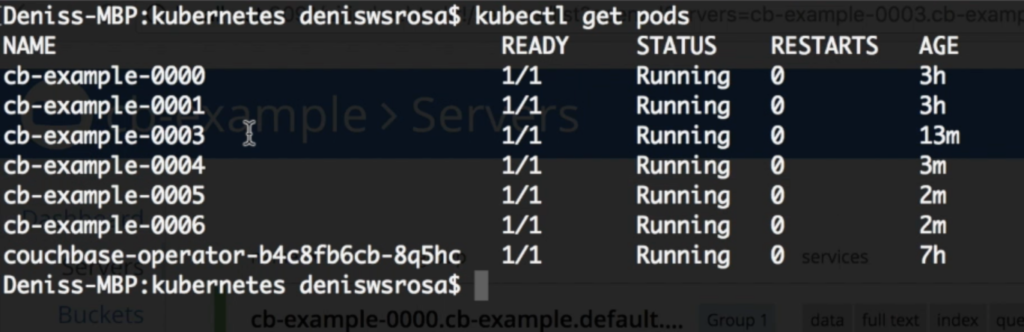
그리고 운영자가 자동으로 데이터를 재조정합니다:
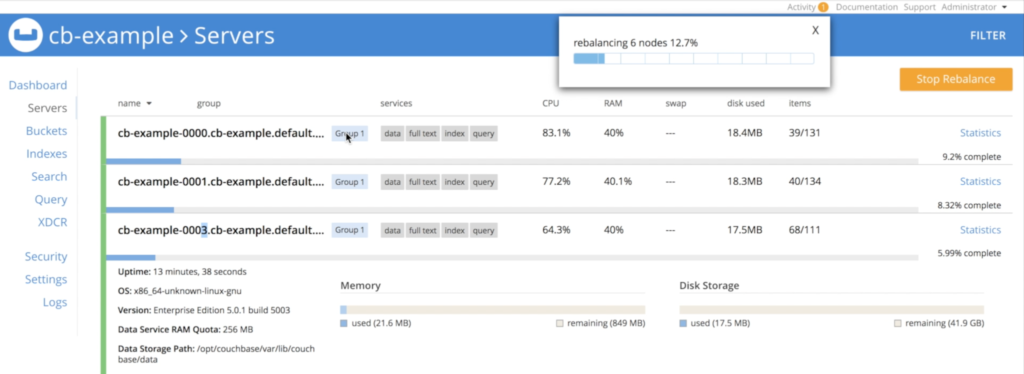
쿠버네티스에서 데이터베이스 규모 축소하기
스케일링 다운 프로세스는 스케일링 업 프로세스와 매우 유사합니다. 우리가 해야 할 일은 크기 매개 변수를 6에서 3으로 변경합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... servers: - size: 3 name: all_services services: - data - index - query - search dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data ... |
그런 다음 바꾸기 명령을 다시 실행하여 구성을 업데이트합니다:
|
1 |
kubectl replace -f couchbase-cluster.yaml |
그러나 데이터 손실의 위험 없이 동시에 3개의 노드를 죽일 수는 없기 때문에 여기에는 작은 세부 사항이 있습니다. 이 문제를 방지하기 위해 운영자는 클러스터를 한 번에 하나의 인스턴스씩 점진적으로 축소하여 데이터의 복제본 3개가 모두 보존되도록 리밸런싱을 트리거합니다:
- 노드를 종료하는 운영자 cb-example-0006:
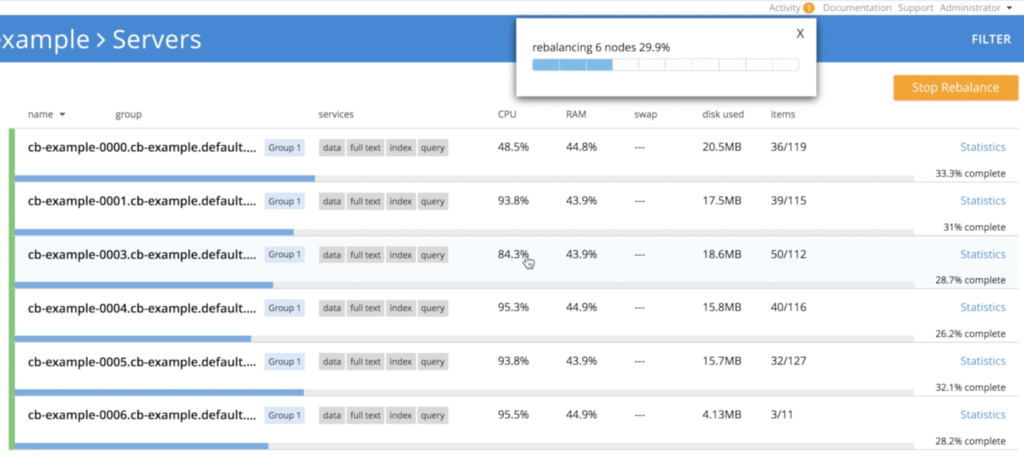
- 노드를 종료하는 운영자 cb-example-0005
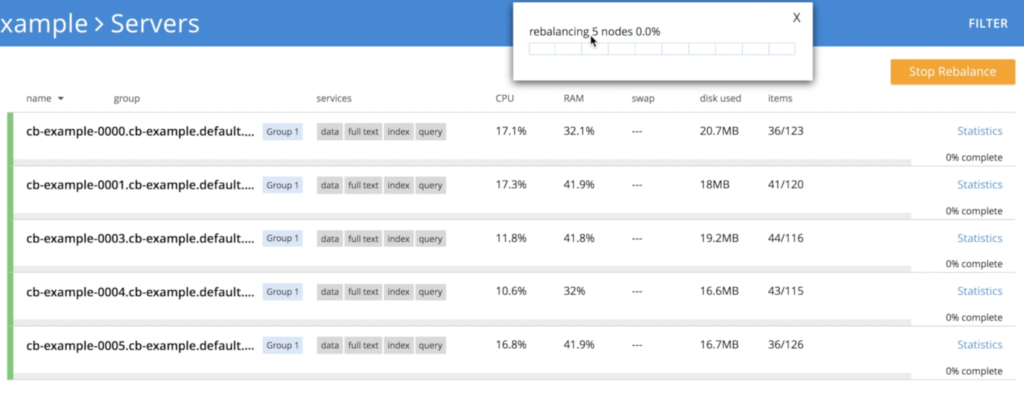
- 노드 종료하기 cb-example-0004
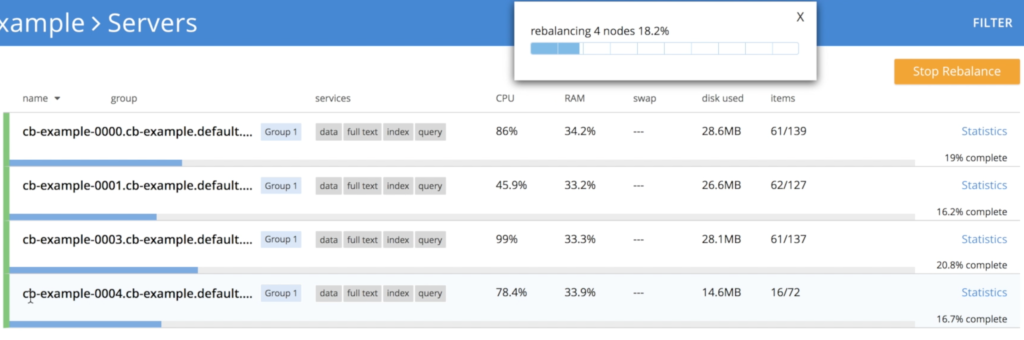
- 마지막으로 다시 3개의 노드로 돌아갑니다.
다차원 스케일링
또한 다음을 활용할 수도 있습니다. 다차원 스케일링 각 노드에서 실행할 서비스를 지정하면 됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
... servers: - size: 3 name: data_and_index services: - data - index dataPath: /opt/couchbase/var/lib/couchbase/data indexPath: /opt/couchbase/var/lib/couchbase/data - size: 2 name: query_and_search services: - query - search ... |
쿠버네티스의 다른 데이터베이스는 어떤가요?
예! 주목할 만한 예로 MySQL 및 Postgres와 같은 몇 가지를 이미 Kubernetes에서 실행할 수 있습니다. 또한 여기서 설명한 대부분의 인프라 운영을 자동화하려고 시도하고 있습니다. 안타깝게도 아직 공식적으로 지원되지 않기 때문에 배포가 간단하지 않을 수 있습니다.
이에 대해 더 자세히 알고 싶으시다면 Kubecon의 두 가지 멋진 강연을 참조하세요:
결론
현재 데이터베이스는 데이터를 저장하기 위해 로컬 임시 저장소를 사용하고 있습니다(카우치베이스 포함). 그 이유는 간단합니다: 최고의 성능을 제공하는 옵션이기 때문입니다. 일부 데이터베이스는 엄청난 지연 시간에도 불구하고 원격 영구 저장소에 대한 지원을 제공하고 있습니다. 로컬 영구 저장소가 GA로 전환되면 개발자들이 이 새로운 트렌드에 대해 우려하는 대부분의 문제를 해결할 수 있을 것으로 기대합니다.
지금까지는 데이터베이스 관리의 부담을 없애고 싶다면 완전 관리형 데이터베이스가 유일한 옵션이었습니다. 물론 이러한 자유의 대가는 요금 청구서에 0이 추가되고 성능/아키텍처 제어가 매우 제한되는 형태로 나타납니다. 데이터베이스 확장 및 자체 관리를 위해 Kubernetes를 활용하는 것은 모든 것을 직접 관리하는 것과 다른 사람에게 의존하는 것 사이에 있는 세 번째 옵션으로 떠오르고 있습니다.
질문이 있으시면 댓글로 남겨 주시거나 다음 주소로 트윗해 주세요. @deniswsrosa. 이 글의 2부에서 이 모든 질문에 대한 답변을 드리겠습니다.
정말 환상적인 게시물입니다. 데니스 감사합니다...
안녕하세요 데니스,
AWS에서 실행할 때 데이터 서비스를 노출하려면 어떻게 해야 하나요? 노드의 공용 DNS를 사용하여 관리자 콘솔에 액세스할 수 있습니다. aws 보안 그룹에서 필요한 모든 포트를 열었습니다. 하지만 Java SDK 기반 샘플은 연결할 수 없습니다. 쿠버네티스 클러스터 내에서 테스트하는 데 사용할 수 있는 컨테이너로 사용할 수 있는 빠른 샘플 웹 앱이 있나요?
데니스에게 ,
Kubernetes를 사용하는 CB 6.0 EE 버전에서 MDS 설정에서 제가 무엇을 잘못했는지 도와 주시겠습니까?
서버:
- 크기: 3
이름: 데이터 서비스
서비스:
- 데이터
포드:
리소스:
제한:
CPU: "10"
메모리: 30Gi
요청:
CPU: "5"
메모리: 20Gi
볼륨 마운트:
데이터: 카우치베이스
기본값: 카우치베이스
- 크기: 1
이름: 인덱스 서비스
서비스:
- 색인
포드:
리소스:
제한:
CPU: "40"
메모리: 75Gi
요청:
CPU: "30"
메모리: 50Gi
볼륨 마운트:
데이터: 카우치베이스
기본값: 카우치베이스
- 크기: 1
이름: 쿼리 서비스
서비스:
- 쿼리
포드:
리소스:
제한:
CPU: "10"
메모리: 10기가
요청:
CPU: "5"
메모리: 5Gi
볼륨 마운트:
데이터: 카우치베이스
기본값: 카우치베이스
- 크기: 2
이름: 기타 서비스
서비스:
- 검색
- 이벤트
- 분석
포드:
리소스:
제한:
CPU: "5"
메모리: 10기가
요청:
CPU: "2"
메모리: 5Gi
볼륨 마운트:
데이터: 카우치베이스
기본값: 카우치베이스
템플릿에서 아래 문제를 던집니다 :
경고: 'couchbase-cluster' 차트에 대한 대상 맵 병합 중입니다. 테이블 값이 아닌 테이블 항목 'servers'를 덮어쓸 수 없습니다: map[all_services:map[pod:map serverGroups: services:[데이터 인덱스 쿼리 검색 이벤트 분석] size:5]]
개정: 1
설치를 계속하려면 아래 오류가 발생합니다 :
오류: 릴리스 채워진 딱정벌레 실패: 입학 웹훅 "couchbase-admission-controller-couchbase-admission-controller.default.svc"가 요청을 거부했습니다: 유효성 검사 실패 목록입니다:
spec.servers[1].services의 데이터가 필요합니다.
spec.servers[2].services의 데이터가 필요합니다.
spec.servers[3].services의 데이터가 필요합니다.
MDS에 대한 여러 항목을 좋아하지 않기 때문에 ...\templates\couchbase-cluster.yaml의 루프 조건이 어딘가에서 누락되었다고 확신합니다:
그리고 이 섹션이 범인인 것 같습니다 :
서버:
{{- 범위 $server, $config := .Values.couchbaseCluster.servers }}
이름: {{ $server }}
{{ toYaml $config | 들여쓰기 4 }}
{{- 끝 }}
{{- if .couchbaseTLS.create }}
MDS 설치가 잘 진행되기 위해 내가 놓치고 있는 것이 무엇인가요?
도와주셔서 감사합니다.