Como fazer "algo" no N1QL?
Em primeiro lugar, Se você não estiver familiarizado com o N1QL, recomendo que dedique alguns minutos ao nosso treinamento gratuito sobre N1QL aquiou simplesmente brincar com ele aqui.
Em segundo lugar, como se trata de uma pergunta ampla, vamos analisar alguns cenários comuns:
Selecione o ID de um documento e todos os seus atributos:
|
1 |
Select meta(t).id as id, t.* from `myBucket` t where type = 'someType' |
Como escrever um JOIN:
Vamos consultar quais empresas voam do aeroporto de São Francisco (SFO) para qualquer lugar do mundo usando o exemplo de viagem:
|
1 2 3 4 5 6 7 |
SELECT airline.name, airline.callsign, route.destinationairport, route.stops, route.airline FROM `travel-sample` route JOIN `travel-sample` airline ON KEYS route.airlineid WHERE route.type = "route" AND airline.type = "airline" AND route.sourceairport = "SFO" AND route.stops = 0 ORDER BY airline.name |
O JUNTAR se parece com um SQL JOIN padrão, a única diferença aqui é a cláusula SOBRE AS CHAVES palavra-chave, para ler mais sobre ela Confira este artigo que explica visualmente os JOINs N1QL. O Couchbase 5.5 também adicionará suporte a ANSI JOINs
Como selecionar itens de uma matriz:
Documentos fornecidos como:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ type: “person”, name: “John”, children: [ { “name”: “Pedro”, “age”: 8 }, { “name”: “George”, “age”: 11 } ] } |
Se quisermos selecionar todas as crianças com mais de 10 anos de idade, podemos usar o comando INÚTIL palavra-chave:
|
1 |
SELECT c.* FROM tutorial t UNNEST t.children c WHERE c.age > 10 |
Por que minha consulta está lenta?
Provavelmente, sua consulta não está atingindo nenhum índice. Você pode verificar isso executando a consulta com a opção explicar da seguinte forma:
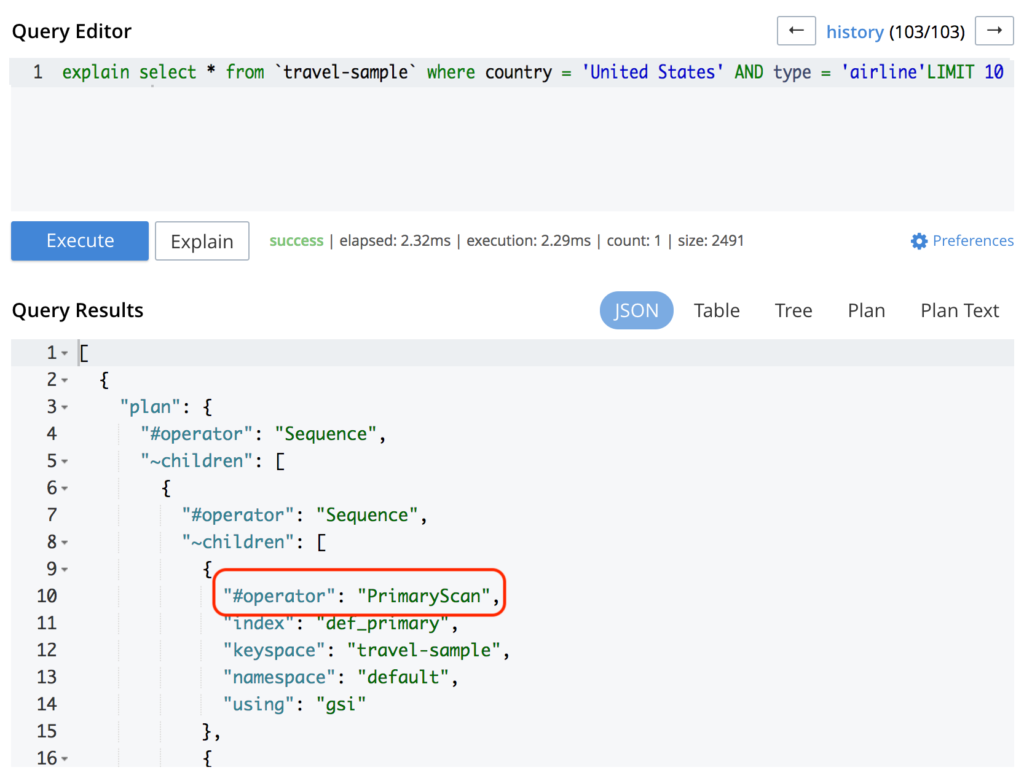
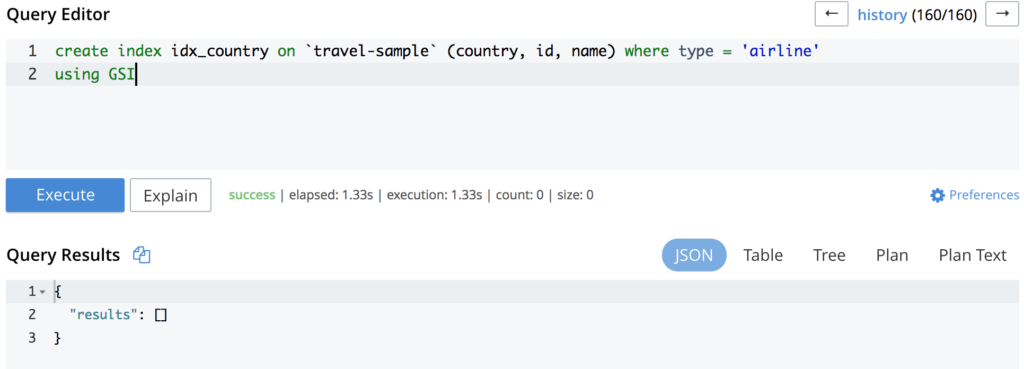
Como você pode ver na imagem acima, a consulta está atingindo o PrimaryScan o que significa que ele está usando o índice primário. A criação de um índice secundário para ele possivelmente resolverá seu problema:
Ao executar a mesma consulta novamente, o resultado será algo como:
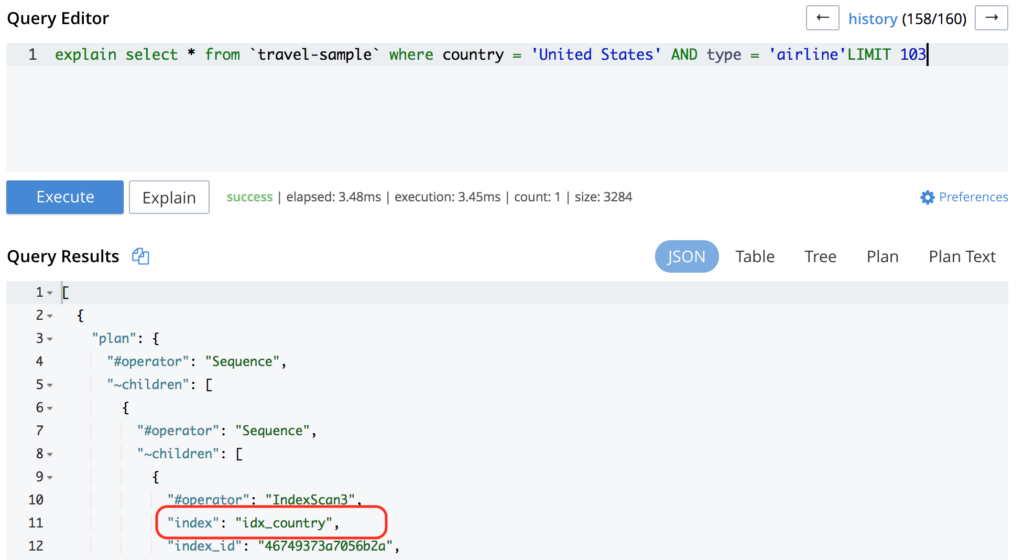
Se a sua consulta já estiver atingindo um índice, mas ainda tiver um desempenho ruim, talvez seja melhor adicionar um índice mais otimizado (como neste exemplo). Se você não estiver familiarizado com como criar um índice, dê uma olhada nesta postagem do blog
Como paginar os resultados no N1QL?
Você pode usar LIMITE e DESLOCAMENTO:
|
1 |
select * from `travel-sample` where country = 'United States' OFFSET 10 LIMIT 10 |
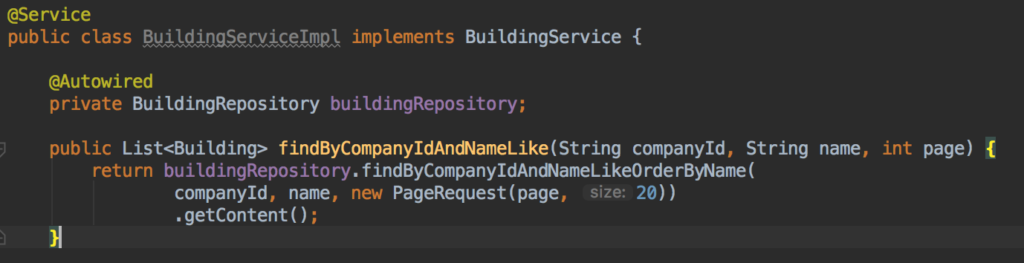
Confira este tutorial para ler mais sobre o assunto. Além disso, se você estiver usando o Spring Data, poderá adicionar um Paginável ao final da definição de seu método:

E então, em seu serviço, você pode usar o Solicitação de página objeto:
Minha consulta tem resultados ausentes/errados
Por padrão, o Couchbase suporta leitura após a escrita sempre que você obtém um documento por sua chave, mas seus índices e exibições são atualizados de forma assíncrona por meio do Data Change Protocol (DCP). Portanto, se você estiver executando uma consulta logo após uma gravação, ela poderá ser executada antes que as exibições/índices tenham a chance de ser atualizados.
O Couchbase tem tudo a ver com velocidade, e ninguém tem tempo para esperar até que todos os índices e exibições sejam atualizados para enviar a resposta de volta ao cliente de que uma gravação foi executada com êxito.
Mas há poucos cenários em que a consistência forte entre as gravações e as consultas é realmente necessária. Nesses casos, você pode especificar por meio do SDK que deseja esperar até que o índice/visualização que está usando seja atualizado:

Para saber mais sobre consistência de varredura, consulte a seção documentação oficial.
Em minha experiência pessoal, o único cenário em que preciso de consistência entre gravações e consultas é durante o testes de integração que é quando você realmente insere os dados e os consulta logo em seguida.
Como criar/usar índices de matriz.
Esse é um tópico interessante, pois indexação de matriz pode acelerar significativamente seu desempenho. Então, digamos que temos a seguinte estrutura de documento:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
{ "address": "Capstone Road, ME7 3JE", "alias": null, "city": "Medway", "country": "United Kingdom", "description": "40 bed summer hostel about 3 miles from Gillingham, housed in a districtive converted Oast House in a semi-rural setting.", "directions": null, "email": null, "fax": null, … "id": 10025, "name": "Medway Youth Hostel", "pets_ok": true, "phone": "+44 870 770 5964", "price": null, "reviews": [ { "author": "Ozella Sipes", "content": "Some review here…”, "date": "2013-06-22 18:33:50 +0300", "ratings": { "Cleanliness": 5, "Location": 4, "Overall": 4, "Rooms": 3, "Service": 5, "Value": 4 } } ] } |
Agora, se precisarmos consultar as avaliações de hotéis, podemos fazer algo como:
|
1 |
SELECT c.* FROM `travel-sample` t UNNEST t.reviews c where t.type == "hotel" limit 100 |
Portanto, o índice mais simples para o revisões matriz vontade se parece com o seguinte:
|
1 |
CREATE INDEX idx ON `travel-sample` (reviews) WHERE type = "hotel"; |
E então, quando executamos a consulta, voilà:
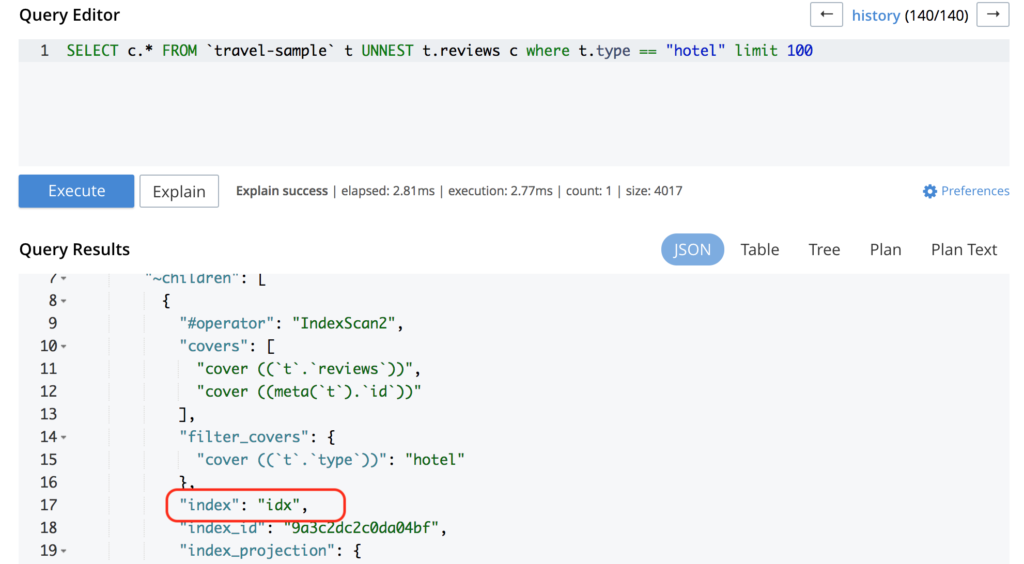
Ele está usando o índice criado recentemente.
Para obter mais exemplos, consulte o documentação oficial ou leia este excelente artigo sobre como otimizar os índices de matriz.