벡터 임베딩은 텍스트나 이미지와 같은 '고차원' 정보를 구조화된 벡터 공간으로 변환하는 머신 러닝의 핵심 구성 요소입니다. 이 프로세스를 통해 관련 데이터를 숫자 벡터로 표현함으로써 보다 효과적으로 처리하고 식별할 수 있습니다. 이 글에서는 벡터 임베딩을 만드는 방법과 그 유형, 다양한 사용 사례에 임베딩을 배포하는 방법에 대해 알아봅니다.
벡터 임베딩 설명
벡터 임베딩은 우리가 이해하는 정보를 컴퓨터가 이해할 수 있는 정보로 변환하는 것과 같습니다. 컴퓨터에게 '발렌타인데이'라는 개념을 설명하려고 한다고 상상해 보세요. 컴퓨터는 휴일, 연애, 문화적 맥락과 같은 개념을 우리처럼 이해하지 못하기 때문에 컴퓨터가 이해할 수 있는 숫자로 변환해야 합니다. 이것이 바로 벡터 임베딩이 하는 일입니다. 벡터 임베딩은 단어, 그림 또는 모든 종류의 데이터를 해당 단어나 이미지의 의미를 나타내는 숫자 목록으로 표현합니다.
예를 들어, 단어의 경우 '고양이'와 '새끼 고양이'가 비슷하다면 (대규모) 언어 모델을 통해 처리할 때 그 숫자 목록(즉, 벡터)은 서로 매우 비슷해집니다. 하지만 단어뿐만이 아닙니다. 사진이나 다른 유형의 미디어에서도 동일한 작업을 수행할 수 있습니다. 따라서 반려동물 사진이 여러 장 있는 경우 벡터 임베딩을 사용하면 컴퓨터가 고양이가 무엇인지 '알지 못하더라도' 어떤 고양이가 비슷한지 알 수 있습니다.
"발렌타인데이"라는 단어를 벡터로 변환한다고 가정해 보겠습니다. "발렌타인데이"라는 문자열은 일반적으로 어떤 모델에 주어질 것입니다. LLM(대규모 언어 모델)를 입력하면 단어와 함께 저장할 숫자 배열이 생성됩니다.
|
1 2 3 4 |
{ "word": "Valentine's Day", "vector": [0.12, 0.75, -0.33, 0.85, 0.21, ...etc...] } |
벡터는 매우 길고 복잡합니다. 예를 들어 OpenAI의 벡터 크기 는 일반적으로 1536이며, 이는 각 임베딩이 1536개의 부동 소수점 숫자 배열임을 의미합니다.
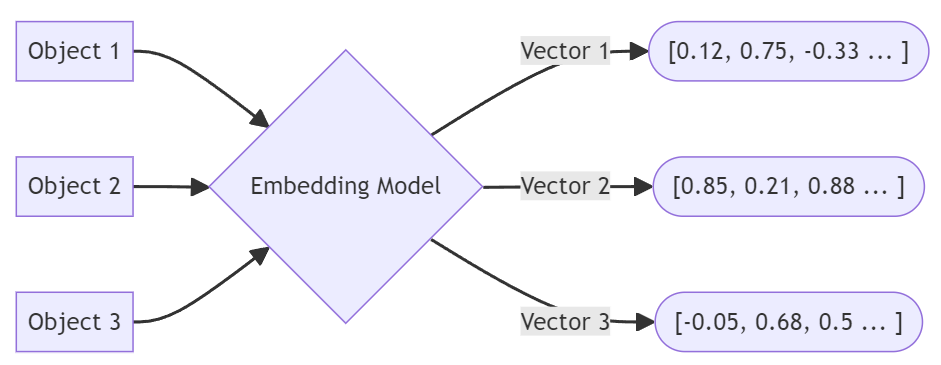
이 데이터는 그 자체로는 큰 의미가 없으며, 다음과 같은 다른 임베딩을 찾는 것이 중요합니다. 닫기.
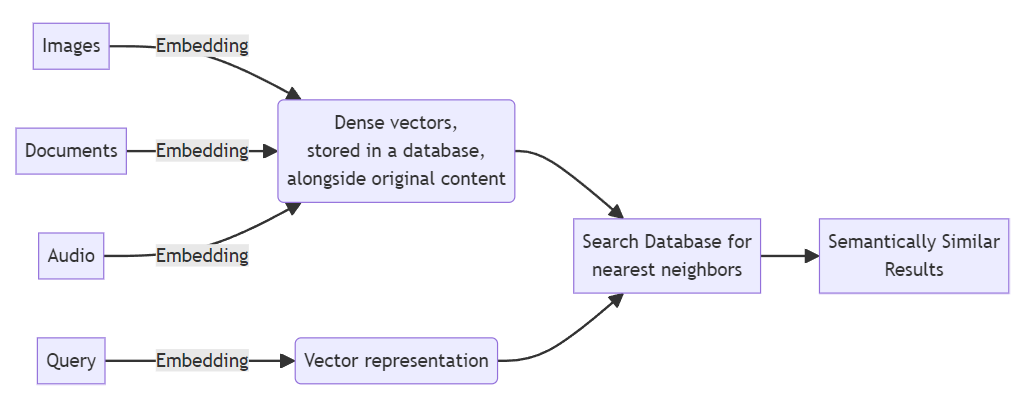
이 다이어그램에서 가장 가까운 이웃 알고리즘은 벡터를 사용하여 데이터를 찾을 수 있습니다. 닫기 를 벡터화된 쿼리에 추가합니다. 이러한 결과는 목록으로 반환됩니다(근접한 순서대로 정렬됨).
벡터 임베딩의 유형
임베딩에는 여러 가지 유형이 있으며, 각 유형마다 데이터를 이해하고 표현하는 고유한 방식이 있습니다. 다음은 여러분이 접할 수 있는 주요 유형에 대한 요약입니다:
단어 임베딩: 단어 임베딩은 단일 단어를 벡터로 변환하여 그 의미의 본질을 포착합니다. 이러한 임베딩을 만드는 데는 Word2Vec, GloVe, FastText와 같은 인기 있는 모델이 사용됩니다. "왕"과 "여왕"이 "남자"와 "여자"와 같은 방식으로 관련되어 있음을 이해하는 것과 같이 단어 간의 관계를 보여주는 데 도움이 될 수 있습니다.
다음은 Word2Vec의 실제 사용 예시입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from gensim.models import Word2Vec sentences = [ "Couchbase is a distributed NoSQL database.", "Couchbase Capella provides flexibility and scalability.", "Couchbase supports SQL++ for querying JSON documents.", "Couchbase Mobile extends the database to the edge.", "Couchbase has a built-in Full Text Search Engine" ] # Preprocess the sentences: tokenize and lower case processed_sentences = [sentence.lower().split() for sentence in sentences] # Train the Word2Vec model model = Word2Vec(sentences=processed_sentences, vector_size=100, window=5, min_count=1, workers=4) # Get the vector for a word word_vector = model.wv['couchbase'] # Print the vector print(word_vector) This Python code would output something like: [-0.00053675, 0.000236998, 0.00510486, 0.00900848, ..., 0.000901757, 0.00639282] |
문장 및 문서 임베딩: 문장 및 문서 임베딩은 단일 단어를 넘어 더 큰 텍스트 조각을 나타냅니다. 이러한 임베딩은 개별 단어뿐만 아니라 전체 문장이나 문서의 문맥을 파악할 수 있습니다. BERT와 Doc2Vec 같은 모델이 좋은 예입니다. 이러한 모델은 텍스트의 전체적인 메시지, 정서 또는 주제를 이해해야 하는 작업에 사용됩니다.
이미지 임베딩: 이미지를 벡터로 변환하여 모양, 색상, 질감과 같은 시각적 특징을 캡처합니다. 이미지 임베딩은 딥러닝 모델( CNN: 컨볼루션 신경망). 이미지 임베딩은 이미지 인식, 분류, 유사도 검색과 같은 작업을 가능하게 합니다. 예를 들어, 이미지 임베딩은 컴퓨터가 특정 사진이 핫도그인지 아닌지를 인식하는 데 도움이 될 수 있습니다.
그래프 임베딩: 그래프 임베딩은 소셜 네트워크, 조직도 또는 생물학적 경로와 같은 관계와 구조를 표현하는 데 사용됩니다. 그래프의 노드와 가장자리를 벡터로 변환하여 항목이 어떻게 연결되어 있는지를 포착합니다. 이는 추천, 클러스터링, 네트워크 내 커뮤니티(군집)를 감지하는 데 유용합니다.
오디오 임베딩: 이미지 임베딩과 마찬가지로 오디오 임베딩은 소리를 벡터로 변환하여 피치, 톤, 리듬과 같은 특징을 포착합니다. 이는 음성 인식, 음악 분석, 사운드 분류 작업에 사용됩니다.
동영상 임베딩: 동영상 임베딩은 동영상의 시각적 및 시간적 역동성을 모두 포착합니다. 동영상 검색, 분류, 영상 내 장면이나 활동 이해와 같은 활동에 사용됩니다.
벡터 임베딩을 만드는 방법
일반적으로 4단계로 나뉩니다:
-
- 벡터 임베딩 모델 선택: 필요에 따라 모델 유형을 결정하세요. 단어 임베딩에는 Word2Vec, GloVe, FastText가 많이 사용되며, 문장 및 문서 임베딩 등에는 BERT와 GPT-4가 사용됩니다.
- 데이터 준비: 데이터를 정리하고 전처리합니다. 텍스트의 경우 토큰화, '중지어' 제거, 문자화(단어를 기본 형태로 축소하는 작업) 등이 포함될 수 있습니다. 이미지의 경우 크기 조정, 픽셀 값 정규화 등이 포함될 수 있습니다.
- 사전 학습된 모델 훈련 또는 사용: 데이터 세트에서 모델을 학습시키거나 미리 학습된 모델을 사용할 수 있습니다. 처음부터 학습하려면 상당한 양의 데이터, 시간 및 컴퓨팅 리소스가 필요합니다. 사전 학습된 모델은 빠르게 시작할 수 있는 방법이며 특정 데이터 세트에 맞게 미세 조정(또는 보강)할 수 있습니다.
- 임베딩 생성: 모델이 준비되면 SDK, REST 등을 통해 데이터를 입력하여 임베딩을 생성합니다. 각 항목은 시맨틱 의미를 나타내는 벡터로 변환됩니다. 일반적으로 임베딩은 데이터베이스에 저장되며, 때로는 원본 데이터와 함께 저장되기도 합니다.
벡터 임베딩의 응용
그렇다면 벡터의 큰 문제점은 무엇일까요? 어떤 문제를 해결할 수 있을까요? 다음은 벡터 임베딩을 사용하여 의미적으로 유사한 항목을 찾을 수 있는 몇 가지 사용 사례입니다(즉, "벡터 검색"):
자연어 처리(NLP)
-
- 시맨틱 검색: 기존의 텍스트 기반 검색을 넘어 검색어 뒤에 숨겨진 의미를 더 잘 활용하여 검색 관련성과 사용자 경험을 개선합니다.
- 감정 분석: 고객 피드백, 소셜 미디어 게시물 및 리뷰를 분석하여 감정(긍정, 부정 또는 중립)을 측정합니다.
- 언어 번역: 소스 언어의 의미를 이해하고 대상 언어로 적절한 텍스트를 생성합니다.
추천 시스템
-
- 전자상거래: 검색 및 구매 내역을 기반으로 개인화된 상품 추천.
- 콘텐츠 플랫폼: 사용자의 관심사와 과거 상호 작용을 기반으로 사용자에게 콘텐츠를 추천합니다.
컴퓨터 비전
-
- 이미지 인식 및 분류: 감시, 사진 태그 지정, 부품 식별 등과 같은 애플리케이션을 위해 이미지에서 물체, 사람 또는 장면을 식별합니다.
- 시각적 검색: 사용자가 텍스트 쿼리 대신 이미지로 검색할 수 있도록 지원합니다.
헬스케어
-
- 신약 개발: 상호 작용을 식별하는 데 도움이 됩니다.
- 의료 이미지 분석: 엑스레이, MRI, CT 스캔과 같은 의료 이미지를 분석하여 질병을 진단합니다.
금융
-
- 사기 탐지: 거래 패턴을 분석하여 사기 행위를 식별하고 방지합니다.
- 신용 점수: 재무 내역 및 행동 분석.
검색 증강 세대(RAG)
검색 증강 세대 의 강점을 결합한 접근 방식입니다. 생성적 언어 모델 (예: GPT-4)에 정보 검색 기능(예: 벡터 검색)을 추가하여 응답 생성을 개선할 수 있습니다.
RAG는 최신의 관련 도메인 정보로 GPT-4와 같은 LLM에 대한 쿼리를 보강할 수 있습니다. 두 단계가 있습니다:
-
- 관련 문서를 조회합니다.
벡터 검색은 특히 관련 데이터를 식별하는 데 효과적이지만, 다음과 같은 분석 쿼리를 포함한 모든 쿼리가 가능합니다. 카우치베이스 컬럼형 를 사용하면 가능합니다. - 쿼리 결과를 쿼리 자체와 함께 생성 모델에 컨텍스트로 전달합니다.
- 관련 문서를 조회합니다.
이 접근 방식을 통해 모델은 보다 유익하고 정확하며 맥락에 맞는 답변을 생성할 수 있습니다.
RAG의 사용 사례는 다음과 같습니다:
-
- 질문 답변: 고정된 데이터 집합에 의존하는 폐쇄형 도메인 시스템과 달리 RAG는 지식 소스에서 최신 정보에 액세스할 수 있습니다.
- 콘텐츠 제작: RAG는 관련 사실과 수치로 콘텐츠를 보강하여 더 나은 정확성을 보장합니다.
- 챗봇/어시스턴트: 다음과 같은 봇 카우치베이스 카펠라 iQ 는 다양한 주제에 걸쳐 보다 상세하고 유익한 답변을 제공할 수 있습니다.
- 교육 도구: RAG는 사용자의 질의에 맞춰 다양한 주제에 대한 자세한 설명이나 보충 정보를 제공할 수 있습니다.
- 추천 시스템: RAG는 사용자의 관심사 또는 쿼리 컨텍스트와 일치하는 관련 정보를 검색하여 맞춤화된 설명이나 추천 이유를 생성할 수 있습니다.
벡터 임베딩 및 카우치베이스
Couchbase는 JSON 데이터 관리에 탁월한 다목적 데이터베이스입니다. 이러한 유연성은 벡터 임베딩에도 적용되는데, Couchbase의 스키마 없는 특성 덕분에 기존 JSON 문서와 함께 복잡한 다차원 벡터 데이터를 효율적으로 저장하고 검색할 수 있습니다(이 블로그 게시물의 앞부분에 나와 있음).
|
1 2 3 4 |
{ "word": "Valentine's Day", "vector": [0.12, 0.75, -0.33, 0.85, 0.21, ...etc...] } |
Couchbase의 강점은 단일 플랫폼 내에서 다양한 데이터 유형과 사용 사례를 처리할 수 있다는 점으로, 단일 목적의 전문화된 솔루션과는 대조적입니다. 벡터 데이터베이스 (Pinecone과 같은)는 벡터 검색과 유사성에만 초점을 맞췄습니다. Couchbase의 접근 방식의 장점은 다음과 같습니다:
하이브리드 쿼리: Couchbase를 사용하면 SQL++, 키/값, 위치 기반 정보, 전체 텍스트 검색을 단일 쿼리로 결합하여 쿼리 후 처리를 줄이고 다양한 애플리케이션 기능을 더 빠르게 구축할 수 있습니다.
다용도성: Couchbase는 키-값, 문서, 전체 텍스트 검색은 물론 실시간 분석과 이벤트까지 모두 동일한 플랫폼 내에서 지원합니다. 이러한 다목적성 덕분에 개발자는 별도의 시스템 없이도 고급 검색 및 추천 기능을 위해 벡터 임베딩을 사용할 수 있습니다.
확장성 및 성능: 고성능 및 확장성을 위해 설계된 Couchbase는 벡터 임베딩을 사용하는 애플리케이션이 증가하는 데이터 및 트래픽 수요에 맞춰 효율적으로 확장할 수 있도록 보장합니다.
통합 개발 환경: 데이터 사용 사례를 Couchbase로 통합하면 개발 프로세스가 간소화됩니다. 팀은 여러 데이터베이스, 통합 및 데이터 파이프라인을 관리하는 대신 기능 구축에 집중할 수 있습니다.
다음 단계
Give 카우치베이스 카펠라 를 사용해 보고 다목적 데이터베이스가 어떻게 강력하고 적응력이 뛰어난 애플리케이션을 구축하는 데 도움이 되는지 알아보세요. 또한 다운로드 벡터 검색 통합 기능을 갖춘 온프레미스 서버 버전의 Couchbase Server 7.6을 출시했습니다.
무료 체험판(신용카드 필요 없음)으로 몇 분 안에 시작하고 실행할 수 있습니다. Capella iQ의 제너레이티브 AI 가 내장되어 있어 첫 쿼리 작성을 시작하는 데 도움이 될 수 있습니다.
벡터 임베딩 FAQ
텍스트 벡터화와 임베딩의 차이점은 무엇인가요?
텍스트 벡터화는 문서에서 단어의 발생 횟수를 계산하는 방법입니다. 임베딩은 단어의 의미론적 의미와 문맥을 나타냅니다.
인덱싱과 임베딩의 차이점은 무엇인가요?
임베딩은 벡터를 생성하는 과정입니다. 인덱싱은 벡터와 그 이웃을 검색할 수 있도록 하는 프로세스입니다.
임베드할 수 있는 콘텐츠 유형에는 어떤 것이 있나요?
단어, 텍스트, 이미지, 문서, 오디오, 비디오, 그래프, 네트워크 등을 포함합니다.
벡터 임베딩은 제너레이티브 AI를 어떻게 지원하나요?
벡터 임베딩을 사용하여 응답 생성을 강화하기 위한 컨텍스트를 찾을 수 있습니다. RAG에 대한 위의 섹션을 참조하세요.
머신러닝에서 임베딩이란 무엇인가요?
데이터를 간결하게 표현하고 데이터 간의 유사성을 찾는 데 사용되는 데이터의 수학적 표현입니다.