오늘 저희는 카우치베이스의 출시를 발표하게 되어 매우 기쁘게 생각합니다. Unstructured.io 커넥터를 사용하면 Couchbase 위에 벡터 저장소로 구축된 RAG 파이프라인으로 비정형 데이터를 수집하는 프로세스를 간소화할 수 있습니다. 이 커넥터를 사용하면 이제 몇 줄의 코드만으로 벡터 임베딩을 생성하여 비정형 및 느슨한 구조의 문서를 JSON 파일로 변환하고 RAG 애플리케이션에서 사용할 수 있도록 준비할 수 있습니다.
개발자에게 비정형 데이터 수집이 중요한 이유는 무엇인가요?
기업 데이터의 압도적인 양이 비정형 데이터이며, 이는 가까운 미래에도 변하지 않을 것입니다. 비정형 형식의 데이터는 개발자에게 시간과 비용 이상의 영향을 미칩니다. 즉, 기업의 의사 결정은 모든 데이터가 아니라 제한된 양의 소모성 정형 데이터를 기반으로 이루어집니다. 또한 다양한 기업 워크플로(내부 및 고객 대면)에 수동 개입이 필요하기 때문에 비용이 더 많이 들고, 속도가 느리며, 오류가 발생하기 쉽다는 것을 의미합니다. 이 문제는 엔터프라이즈 데이터 풋프린트가 증가함에 따라 더욱 심각해질 가능성이 높습니다.
개발자는 비정형 데이터를 어떻게 활용하나요?
비정형 데이터를 활용하는 가장 효과적인 방법 중 하나는 RAG 파이프라인으로 데이터를 수집하여 다음을 통해 검색할 수 있도록 만드는 것입니다. 벡터 검색. 이는 다양한 산업 분야에서 광범위하게 활용되고 있습니다. RAG 애플리케이션을 활용하면 더 많은 관련 문서에 더 쉽게 액세스할 수 있어 해결 시간을 단축하고 비용을 절감하여 운영 효율성을 높일 수 있습니다. 해결 가능한 몇 가지 사용 사례는 다음과 같습니다:
-
- 업계 전반의 고객 지원 팀이 관련 문제 해결 문서를 찾을 수 있도록 지원
- 의료 전문가가 문서 데이터베이스에 저장된 관련 논문과 환자 기록을 추출하여 진단 및 치료 계획을 지원할 수 있도록 지원합니다.
- 고객 데이터를 활용하여 가장 적합한 상품을 제안하는 추천 시스템
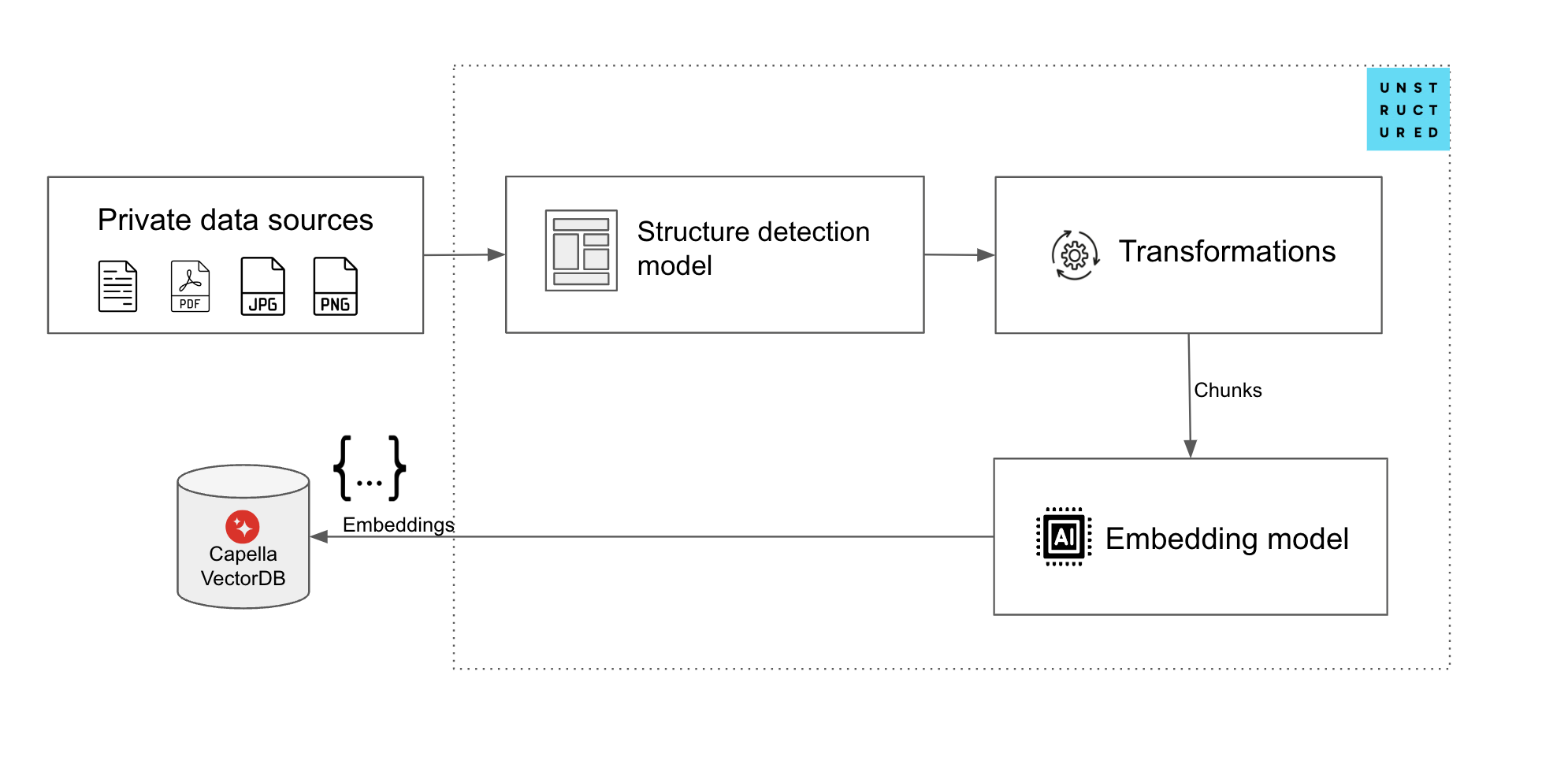
그림 1. 불구조화.io 및 Capella VectorDB를 사용한 비정형 데이터 수집 파이프라인
현재 비정형 데이터를 처리하는 방식은 무엇인가요?
현재 CouchBase Capella로 이 작업(RAG 애플리케이션을 위한 비정형 데이터 수집)을 수행하려면 개발자가 애플리케이션을 작성하여 비정형 데이터 추출기에 연결하고, 그 출력을 파싱하여 청크한 다음, 벡터 생성을 위한 임베딩 모델로 보내야 하며, 그 다음에는 CouchBase Capella의 벡터 DB로 보내야 합니다.
커넥터는 현재 비정형 데이터를 수집하는 방식을 어떻게 개선하나요?
불구조화된.io - Couchbase 커넥터는 앞서 언급한 수집 파이프라인의 두 가지 주요 요소를 연결하는 프로세스를 간소화하여 더 쉽게 만들 수 있습니다:
-
- 비정형 텍스트 데이터를 정형 JSON 문서로 변환하기
- 해당 벡터를 생성합니다.
- 카우치베이스 카펠라에 삽입하기
그리고 소스 커넥터 는 카우치베이스 카펠라에서 데이터를 청크(선택적으로 벡터화)하기 전에 가져오는 데 도움이 되고 대상 커넥터 는 불구조화된.io에서 처리된 데이터를 Couchbase Capella로 수집하는 데 도움이 됩니다.
Capella는 벡터 데이터베이스를 신속하게 설정, 색인, 쿼리할 수 있는 고성능 벡터 데이터베이스입니다. 커넥터를 활용하여 몇 줄의 코드만으로 문서 처리를 시작하는 방법은 다음과 같습니다.
1단계: 전제 조건
커넥터를 사용하기 전에 몇 가지 전제 조건을 충족해야 합니다. 다음이 필요합니다:
-
- An unstructured.io의 API 키 불구조화된.io 계정을 생성하여 얻을 수 있습니다.
- 클러스터 및 데이터베이스가 설정되어 있고 데이터베이스 내에 범위 및 컬렉션이 정의된 활성 Capella 계정입니다.
- IP 주소를 사용하도록 클러스터를 구성하려면 다음과 같이 하세요.
- 데이터베이스 자격 증명을 구성하려면 다음과 같이 하세요.
2단계: 비정형 데이터의 원본과 대상 정의하기
전제 조건이 갖춰지면 처리할 문서의 소스를 정의하고 프로덕션 RAG 파이프라인의 입력으로 사용할 수 있습니다. 커넥터는 다양한 소스에서 수집을 지원합니다: 카우치베이스, 로컬 디렉터리, S3 버킷 및 기타 스토리지 서비스. Unstructured.io 다양한 비정형 문서 포맷 지원 PDF, 이미지 파일(JPEG, PNG), 텍스트 문서(DOCX, DOC), 이메일, 스프레드시트, 프레젠테이션 파일 형식(PPT) 등 다양한 형식의 파일을 저장할 수 있습니다.
마찬가지로, 텍스트가 벡터화되기 전에 불구조화된.io에서 생성된 출력을 저장하는 데 사용할 중간 위치를 정의합니다. 이 위치는 성능이 뛰어나고 확장 가능한 Couchbase의 데이터베이스나 현재 사용 중인 다른 스토리지 서비스의 컬렉션이 될 수 있습니다. 그런 다음 원본 텍스트, 메타데이터 및 해당 임베딩 벡터가 포함된 JSON 문서가 저장될 Couchbase에서 벡터 데이터베이스 컬렉션을 정의할 수 있습니다.
3단계: 청킹 전략을 정의하고 벡터 임베딩 생성을 위한 임베딩 모델을 선택합니다.
입력 및 출력 위치가 정의되면 다음을 수행할 수 있습니다. 청크 전략 중 하나를 선택합니다. 에서 지원되는 불구조화된.io 및 임베딩 모델 선택 를 선택할 수 있습니다. Unstructured.io는 Huggingface, OpenAI, Bedrock 등 여러 제공업체의 임베딩 모델을 지원합니다.
4단계: 애플리케이션 실행!
애플리케이션을 테스트합니다. 불구조화.io를 통해 모든 처리 단계를 실행한 후 Capella 컬렉션에 삽입된 새로운 구조화된 JSON 문서를 볼 수 있어야 합니다. 아래는 PDF를 JSON으로 변환하여 Couchbase Capella 컬렉션에 수집한 파일의 예시입니다. 이 작업을 수행하는 방법에 대한 코드와 함께 단계별 가이드를 보려면 전체 튜토리얼은 여기. 노트북을 사용하여 따라할 수도 있습니다.
비정형 문서 예시:

불구조화된.io의 출력:

Capella로 수집된 문서:
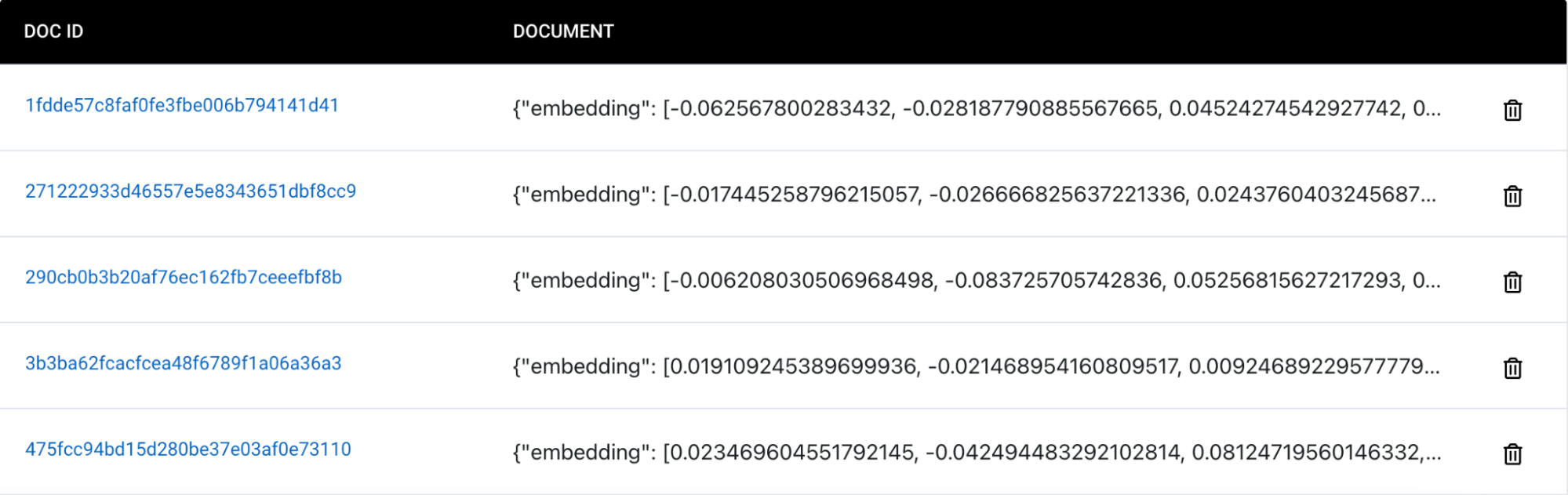
이제 애플리케이션을 실행하여 비정형 텍스트 문서를 처리하고, 구성 요소를 식별하고, JSON 문서로 추출하고, 벡터 임베딩을 생성한 후 Capella 컬렉션에 삽입할 수 있습니다.
리소스

