그래서 우리는 이미 Couchbase에서 고객 360 솔루션을 구축하는 데 무엇이 포함되는지 자세히 살펴봤습니다. 여기.
맞아요, 많은 고민이 필요했죠.
죄송합니다.
생각해보면, 무의미한 대중 중 하나가 될 수는 없습니다...
이제 제가 생각의 위협으로 여러분을 쫓아내지 않았다고 가정하고 몇 가지 세부 사항을 살펴 보겠습니다.
특히 가장 먼저 고려해야 할 부분은 데이터를 Couchbase로 가져오는 것입니다.
전체 시스템 다이어그램을 다시 한 번 살펴봅시다.
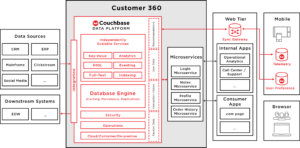
왼쪽을 보면 '데이터 소스'라고 표시된 상자에 시스템 모음이 있습니다.
CRM
ERP
메인프레임
(메인프레임? 아직도 메인프레임이 남아 있나요? 그냥 물을 끄고 추하고 부자연스럽게 죽게 내버려두면 안 돼요? 안돼?!?!? 으...)
재미있는 상식: 메인프레임은 수냉식이었다는 사실!
네, 엔지니어들은 이 짐승들이 얼마나 뜨거워질지 깨달았을 때 "자동차 엔진에 물을 흘려보내면 과열을 방지할 수 있을 것 같다고 생각했습니다. 이 아기에게도 똑같이 해보자!"라고 생각했습니다.
재미있는 상식 #2, 90년대에 일 년 중 11개월 반 동안 눈이 내리는 미네소타에 위치한 크레이 컴퓨터 회사는 새 건물로 이전하기로 결정했지만, 이전 본사 건물을 매각하는 데 어려움을 겪었습니다.
히터가 없는 것 같았어요. 컴퓨터에서 발생하는 열을 온통 배관으로 내보내고 있었어요!
토스트!
하지만 본론으로 돌아가서...
따라서 기본적으로 각각 고유한 데이터 모델을 가진 모든 시스템에서 데이터를 추출하여 Couchbase로 수집해야 합니다.
추출
만약 이것이 제 일이었다면 저는 간단한 길을 택했을 것입니다.
게으르기 때문이 아니라...
게으름에 대한 정의에 따라 다를 수도 있겠죠...
하지만 그렇다고 해서 쉬운 길을 택하는 것은 아닙니다.
저는 이 일을 오래 해왔습니다.
그리고 제가 본 바로는 솔루션이 간단할수록 구현하기가 더 쉽습니다...
유지 관리가 쉬울수록...
덜 깨질수록...
그리고 밤에 잠을 잘 수 있습니다.
제가 꽤 좋아하는 기능입니다.
그래서 쉽다는 표현은 적절하지 않을 수도 있습니다...
단순하다는 표현이 더 어울립니다.
따라서 간단하게 하기 위해 이러한 소스 시스템에서 필요한 데이터를 추출하고 JSON 형식으로 포맷한 다음 Couchbase에 삽입하겠습니다.
이보다 더 간단한 것이 있을까요?
양쪽 끝을 Kafka 스트림에 연결하여 소스에서 Couchbase로 직접 데이터를 파이핑하는 것처럼 간단할 수 있습니다.
양쪽 끝에서 약간의 구성만 하면 짜잔! Couchbase 버킷에 고객 데이터가 들어왔습니다!
오직...
모든 것이 단절되고 연결되지 않습니다...
여기서 내 목표를 정확히 달성하지는 못했지만...
젠장! 그리고 여기서 나는 이것에 대해 생각할 필요없이 지나갈 수 있다고 생각했습니다 ...
흠...
변환
자, 제 Couchbase 버킷에 다양한 소스 시스템의 분산된 데이터가 있는데, 이를 어떻게든 의미 있는 데이터 모델로 결합해야 합니다.
처리해야 할 까다로운 세부 사항은 항상 있습니다...
하지만 이러한 기존 문서가 언제 소스 시스템에서 업데이트될지 알 수 없습니다.
그냥 무작위로, 무작위로, 무작위로 들어오는 것을 기대하면 됩니다.
어떻게 하면...
알겠습니다! 카우치베이스 이벤트 시스템을 사용하여 업데이트가 있을 때 알려드리겠습니다...
새 문서가 무엇인지 살펴볼게요...
해당 고객에 대해 결합해야 하는 다른 데이터가 있는지 주변을 둘러보세요...
그리고 고객 데이터를 결합하여 새 문서를 만듭니다.
예를 들면...
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
함수 온업데이트(doc, 메타) { // 좋아요, 업데이트가 있습니다. // 문서와 결합해야 하나요? 만약 기타 문서(doc) { // 필요한 다른 문서가 있습니다. // 결합하여 새 고객 360 생성 cust360Doc = 결합고객문서(doc); // 결합된 문서를 고객 360 버킷에 저장합니다. tgt[cust360Doc.id] = cust360Doc; } } |
우후! 꽤 간단하지 않나요?
물론 제가 호출하는 두 함수는 여전히 구체화해야 합니다...
털이 너무 많지 않기를...
로드
자, 소스 시스템에서 데이터를 추출하여 결합된 데이터 모델로 변환한 다음 대상 Couchbase 버킷에 로드하고...
잠깐만요...
추출...변환...로드...
ETL?!?!?
여기선 더러운 단어 아닌가요?
우리는 카우치베이스입니다!
우리는 ETL 없는 분석에 대해 설교하러 다닙니다!
카우치베이스 버킷의 데이터 변경 사항은 자동으로 분석 서비스에 표시됩니다...
...카우치베이스 버킷의 변경 사항...
우리...나...우리...나...어...
흠...
"ETL 없음" 항목은 데이터를 Couchbase에 가져온 후에만 적용된다고 생각하세요...
네, 이 경우에는 피할 방법이 없는 것 같습니다.
하지만 이 경우에는 일종의 실시간이 될 수 있습니다.
원본 시스템에서 추출을 실행하는 일정에 따라 다릅니다.
일괄 작업으로 야간에 실행되는 경우, 이는 일상적인 야간 ETL일 뿐입니다.
하지만 CRM 또는 ERP 데이터베이스에 트리거가 있어 해당 시스템에서 고객 레코드가 업데이트되는 순간 업데이트를 Kafka 대기열에 넣는다면, 이는 상당히 실시간적인 ETL 프로세스입니다.
우리가 여기서 설교하는 것에 더 가까이 다가가기...
참고: 실제로 이를 실행에 옮기는 방법에 대해 자세히 알아보고 싶은 분들을 위해 저희 웹사이트에 매우 훌륭하고 상세한 튜토리얼이 준비되어 있습니다. 여기에서 찾을 수 있습니다. 여기.
그렇다면 왜 다시 카우치베이스일까요?
스키마가 없는 데이터베이스를 사용하면 모든 고객 데이터가 포함된 하나의 방대한 우버 문서를 만들 수 있습니다. 왜 저희를 사용해야 할까요?
이미 인프라에 있는 것(Kafka)을 사용해 소스 시스템에서 데이터를 가져와 Couchbase 버킷에 삽입한 다음, Eventing 서비스를 사용해 실시간 기능을 트리거하여 해당 데이터를 ETL할 수 있다는 편리함 외에도요?
물론 큰 돈을 주고 마법의 ETL 소프트웨어를 구입해 이런 무거운 작업을 대신 해줄 수도 있겠지만...
그런 다음 캐싱 솔루션을 연결하여 필요한 속도와 성능을 얻을 수 있습니다...
그리고 사용자가 원하는 정보를 찾을 수 있도록 전체 텍스트 검색 제품을 추가하세요...
그런 다음 모바일 애플리케이션에서 데이터에 액세스할 수 있도록 REST API를 빌드하세요...
다른 ETL 시스템을 추가하여 데이터를 가져와 데이터 레이크 분석 시스템에 던져 넣습니다...
그리고 여러분이 만든 루브 골드버그 머신에 약간의 문제가 발생하면, 모든 것이 계속 작동하도록 패치하기 위해 달려가세요...
그리고 잠을 자는 취미는 포기하세요...
또는 간단한 방법을 택하여 이 모든 작업에 Couchbase를 사용할 수도 있습니다.
앞서 말했듯이 저는 간단한 솔루션을 선호합니다.